
1. 什么是RocketMQ?
1.是一个队列模型的消息中间件。
2.高性能、高可靠、高实时、分布式的特点。
2.rocketMq的优点:
1.亿级消息堆积能力.
2.高效的订阅者水平扩展能力
3.能够保证严格的消息顺序
4.提供丰富的消息拉叏模式
5.实时的消息订阅机制
3.rocketMq的物理结构:
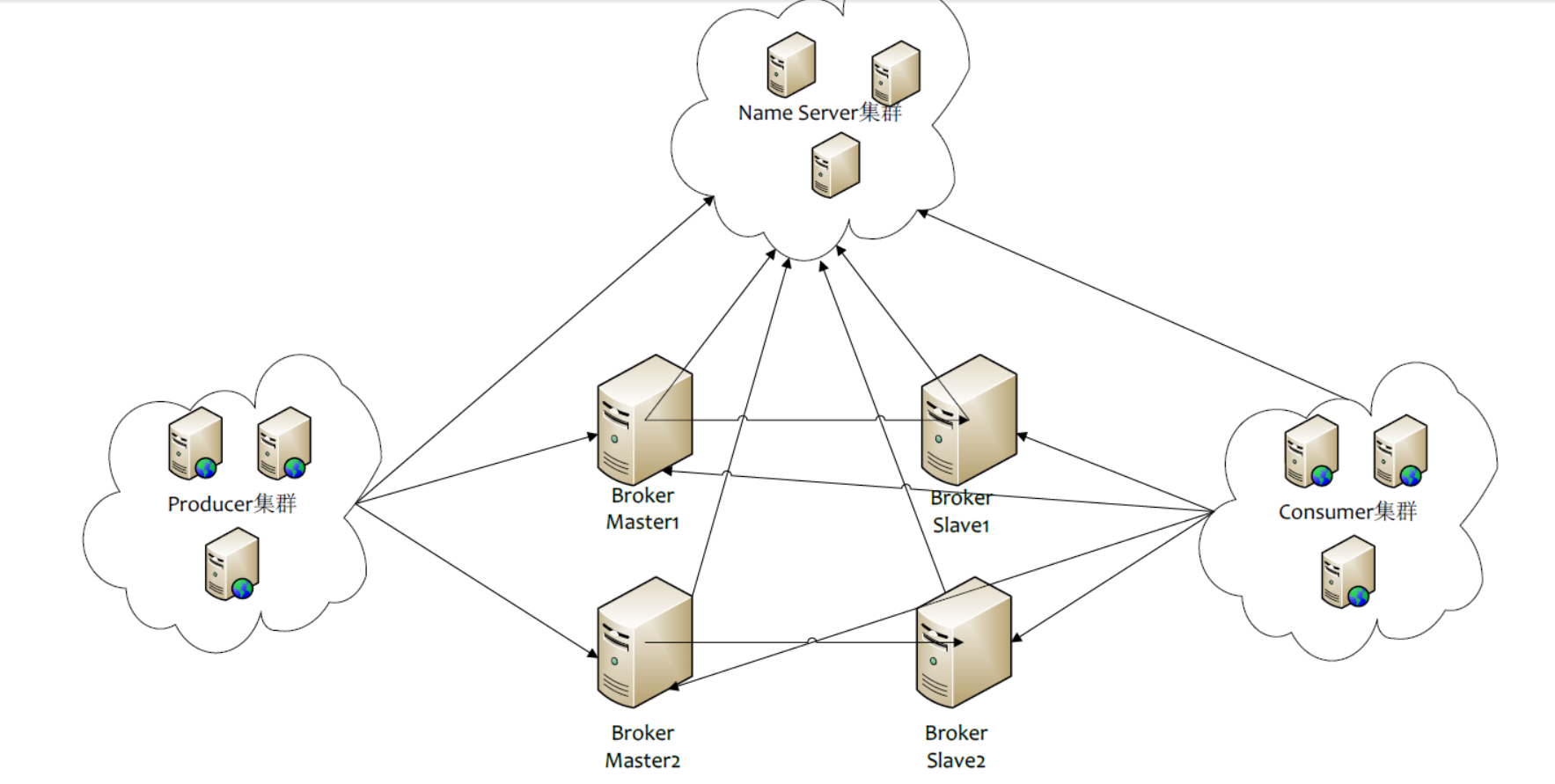
1.Name Server是一个几乎无状态特点,可集群部署,节点之间无任何信息同步的(相对于zookeeper是较为轻量级的)。
2.Broker
1.broker分为Master和Slave,一个Master可以对应多个Slave,但是多个Slave只能对应一个Master;
2.Master与Slave的对应关系通过指定相同的BrokerName;
3.不同的BrokerID来定义,BrokerId为o表示Master,非o表示Slave,Master也可以部署多个;
4.每个Broker与Name Server集群中的所有节点建立长连接,定时注册Topice信息到所有的Name Server.
3.Producer:
1.Producer与Name Server集群中的其中一个节点(随机选择)建立长连接,定期从Name Server取Topic路由信息;
2.向提供Topic服务的Master建立长连接,且定时的向Master发送心跳。
3.Producer完全无状态,可以集群部署。
4.Consuemr
1.Consuemr与Name Server集群中的其中一个节点(随机选择)建立长连接,定期从Name Server取Topic路由信息;
2.向提供Topic服务的Master,Slave建立长连接,且定时向Master,Slave发送心跳;
3.Consumer既可以从Master订阅消息,也可以从Slave订阅消息,订阅规则由Broker配置决定。
5.rocketMq消息模型:
1.顺序消息:
https://blog.csdn.net/luanlouis/article/details/91368332
2.事务消息:
https://baijiahao.baidu.com/s?id=1638994745278332160&wfr=spider&for=pc
https://zhuanlan.zhihu.com/p/249233648
1.RocketMQ 事务使用案例
createTransactionListener() 在init()方法中调用,构造实现RocketMQ的TransactionListener接口的匿名类,该接口需要实现如下两个方法:
1.executeLocalTransaction:执行本地事务,在这里我们直接把订单数据插入到数据库中,并返回本地事务的执行结果。
2.checkLocalTransaction:反查本地事务,上述流程中是在db中查询订单号是否存在,若存在则提交事务,若不存在,可能本地事务失败了,也可能本地事务还在执行,所以返回UNKNOW
2.rocketMq事务消息实现原理:
1.producer端如何发事务消息?
1.DefaultMQProducerImpl.sendMessageInTransaction(final Message msg, final LocalTransactionExecuter localTransactionExecuter, final Object arg)
2.DefaultMQProducerImpl.endTransaction(final SendResult sendResult, final LocalTransactionState localTransactionState, final Throwable localException)
有事务反查机制作兜底,该RPC请求即使失败或丢失,也不会影响事务最终的结果。最后构建事务消息的发送结果,并返回。
3.主要做了如下事情:
1.给消息打上事务消息相关的标记,用于MQ服务端区分普通消息和事务消息
2.发送半消息(half message)
3.发送成功则由transactionListener执行本地事务
4.执行endTransaction方法,如果半消息发送失败或本地事务执行失败告诉服务端是删除半消息,半消息发送成功且本地事务执行成功则告诉服务端生效半消息。
2.Broker端如何处理事务消息?
1.SendMessageProcessor#asyncSendMessage
2.TransactionalMessageBridge
1.putHalfMessage
2.parseHalfMessageInner
3.设计思想:
1.RocketMQ并非将事务消息保存至消息中 client 指定的 queue,而是记录了原始的 topic 和 queue 后,把这个事务消息保存在 - 特殊的内部 topic:RMQ_SYS_TRANS_HALF_TOPIC - 序号为 0 的 queue
2.这套 topic 和 queue 对消费者不可见,因此里面的消息也永远不会被消费。这就保证在事务提交成功之前,这个事务消息对 Consumer 是消费不到的。
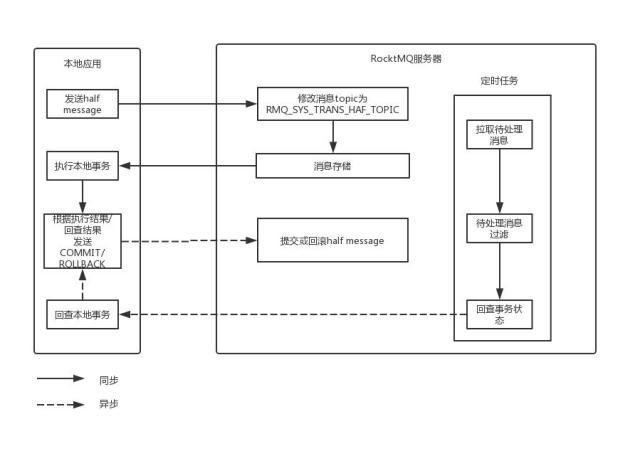
3.broker反查事务
1.在Broker的TransactionalMessageCheckService服务中启动了一个定时器,定时从事务消息queue中读出所有待反查的事务消息。
AbstractTransactionalMessageCheckListener#resolveHalfMsg - 针对每个需要反查的半消息,Broker会给对应的Producer发一个要求执行事务状态反查的RPC请求

2.- AbstractTransactionalMessageCheckListener#sendCheckMessage
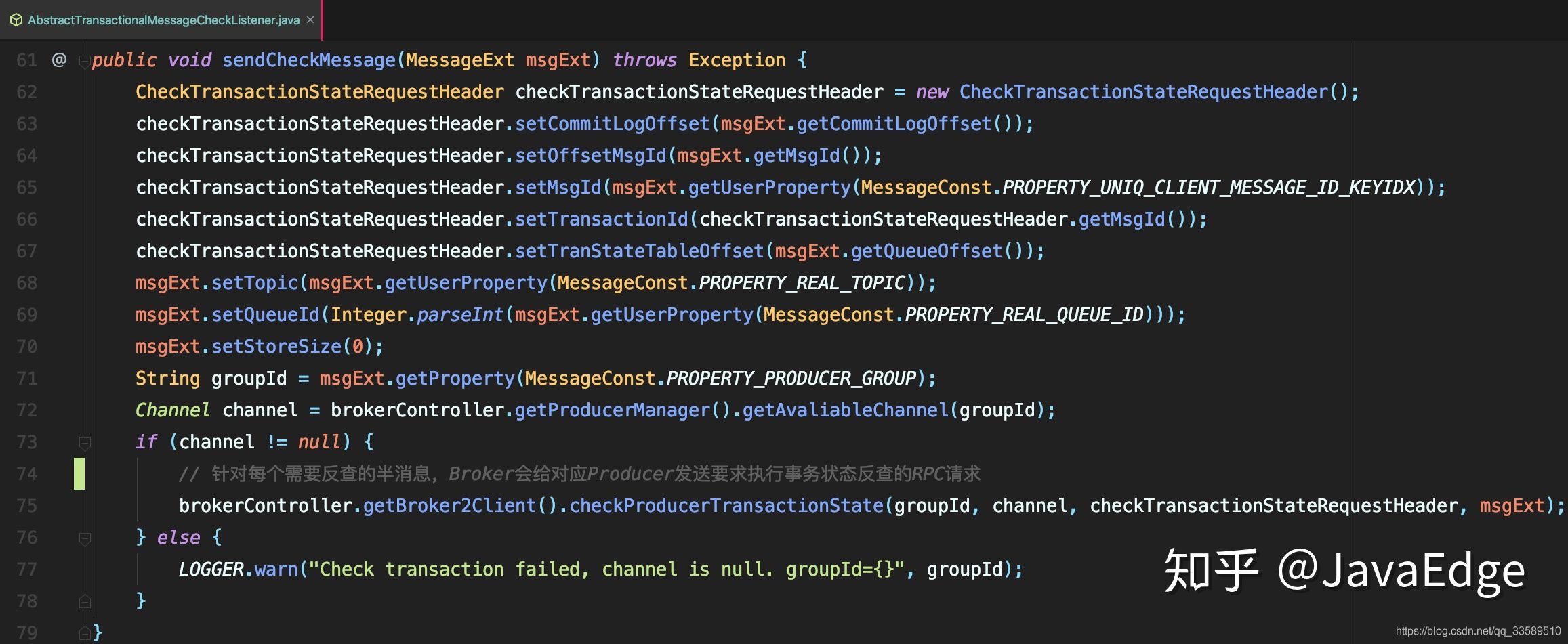
3.Broker2Client#checkProducerTransactionState
根据RPC返回响应中的反查结果,来决定这个半消息是需要提交还是回滚,或者后续继续来反查。
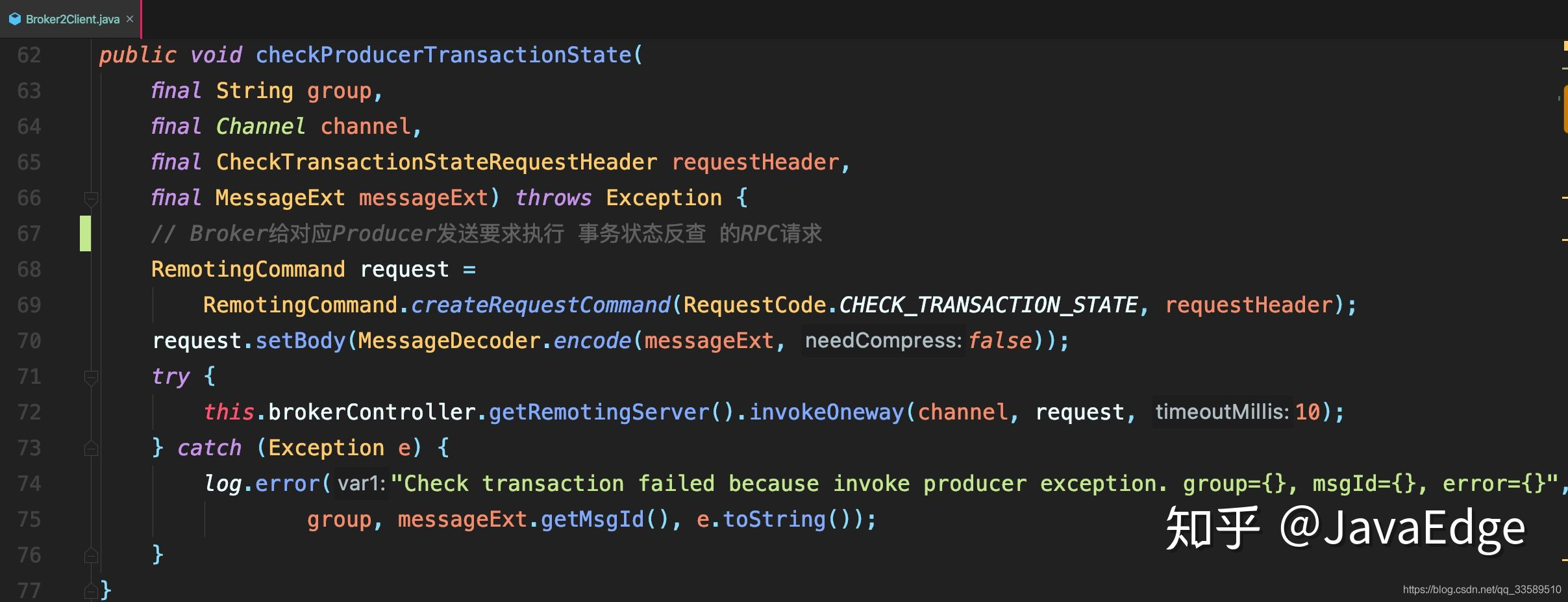
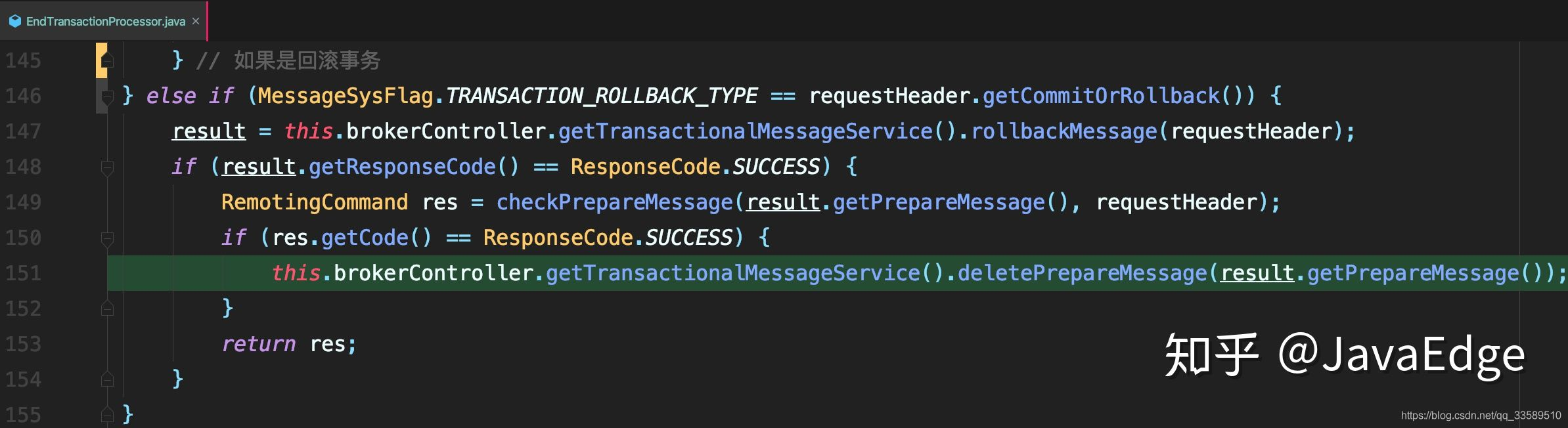
4.最后,提交或者回滚事务。首先把半消息标记为已处理
1. 如果是提交事务,就把半消息从半消息队列中复制到该消息真正的topic和queue中
2. 如果是回滚事务,什么都不做 - EndTransactionProcessor#processRequest
3.总结:
1.整体流程:
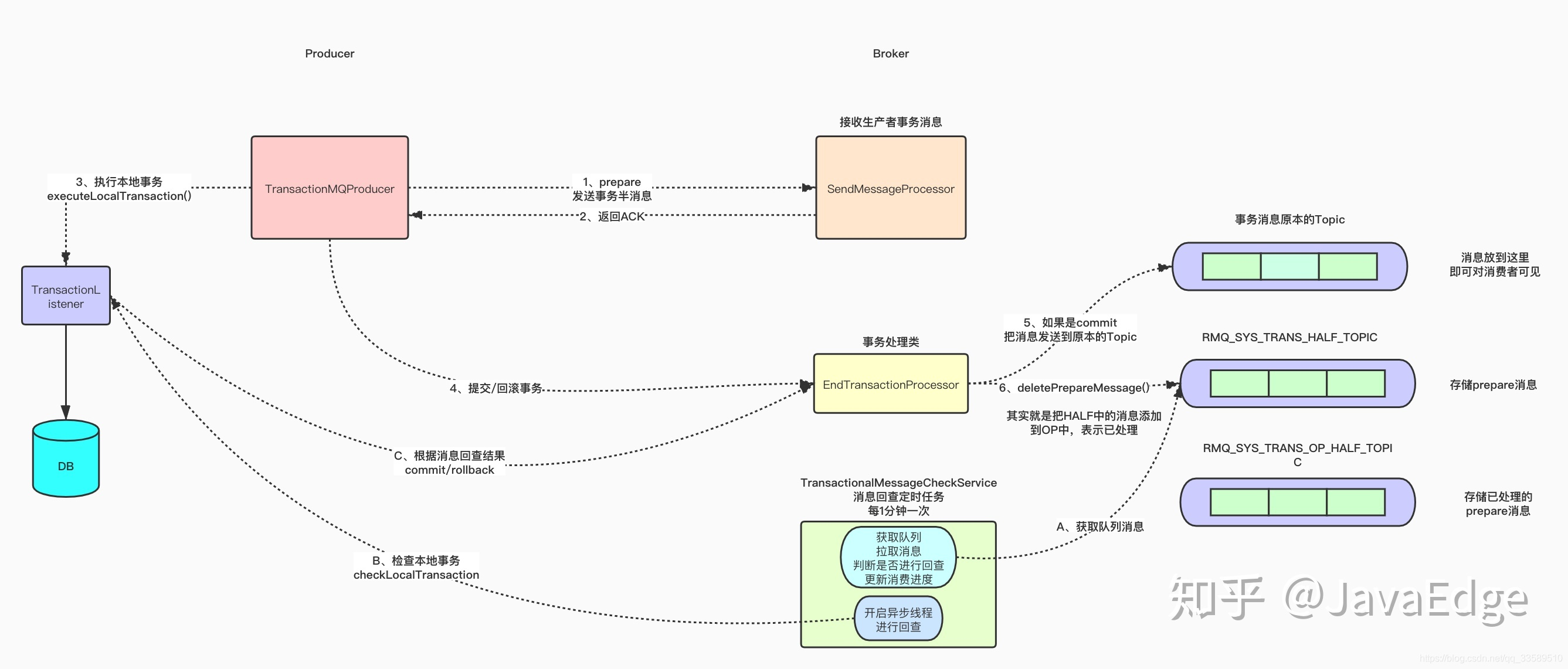
RocketMQ是基于两阶段提交来实现的事务,把这些事务消息暂存在一个特殊的queue中,待事务提交后再移动到业务队列中。最后,RocketMQ的事务适用于解决本地事务和发消息的数据一致性问题。
4. RockertMQ的逻辑部署结构
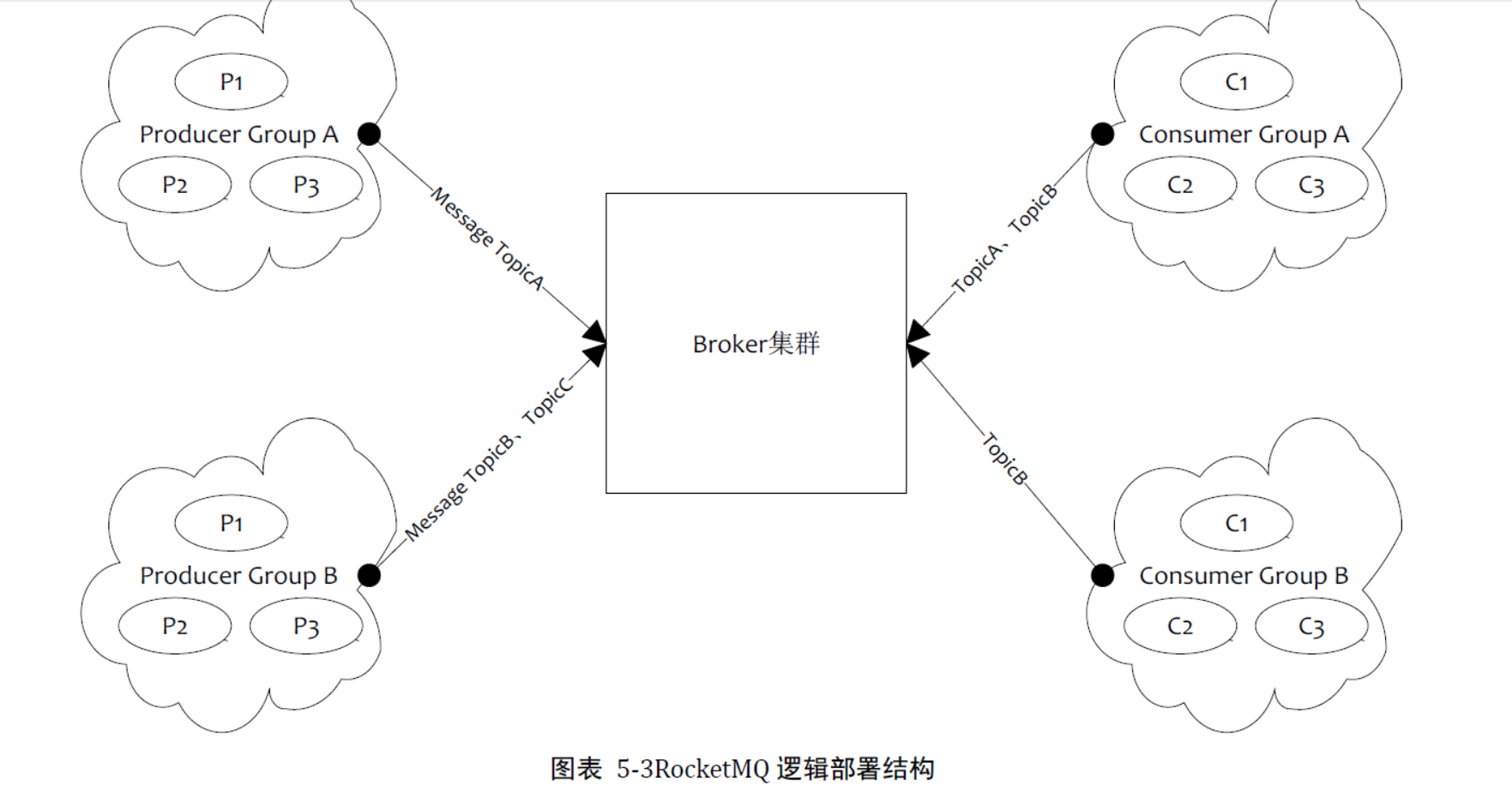
1.ProducerGroup:用来表示一个发送消息应用,一个Producer Group下包含多个Producer实例,一个Producer Group可以发送多个Topic消息
2.Consuermer Group:来表示一个消费消息的应用,一个Consumer Group下包含多个Consumer实例
2.RocketMQ搭建双Master集群
双主结构搭建地址:https://www.cnblogs.com/Eternally-dream/p/9942849.html
3.RocketMQ监控平台rocketmq-console-ng的搭建
https://www.cnblogs.com/Eternally-dream/p/9948084.html
官网地址:https://github.com/apache/rocketmq-externals
4.RocketMQ的Client的使用 Producer/Consumer
1.添加依赖:
2.Producer 的开发步骤
1.实例化ProducerGroup:DefaultMQProducer producer = new DefaultMQProducer("my-producer-group");
2.设置namesrvAddr: producer.setNamesrvAddr("47.105.145.123:9876;47.105.149.61:9876");
3.调用start()方法启动:producer.start();
4.发送消息:producer.send(message);
5.关闭生产者:producer.shutdown();
3。Consumer开发步骤:
1. 实例化Consumer Group; DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("my-consumer-group");
2. 设置namesrvAddr,集群环境多个nameserver用;分割; producer.setNamesrvAddr("47.105.145.123:9876;47.105.149.61:9876");
3. 设置从什么位置开始; consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_LAST_OFFSET);
4. 订阅topic; consumer.subscribe("MyQuickStartTopic", "*");
5. 注册消息监听器; consumer.registerMessageListener();
6. 重写MessageListenerConcurrently接口的consumeMessage()方法。
1. RocketMQ主要的9个模块
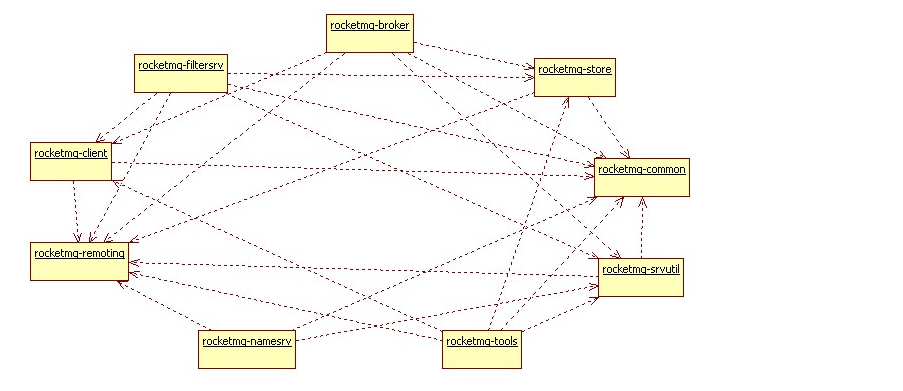
2. 模块介绍
1. rocketmq-common:通用的常量枚举,基类方法或者数据结构,按描述的目标来分包,通俗易懂。包名有admin,consumer,filter,hook,message等。
2. rocketmq-remoting:用Netty写的客户端和服务端,fastjson做的序列化,自定义二进制协议
3. rocketmq-sevutil: 只用一个ServerUtil类,类注解是,只提供Server程序依赖,目的是为了拆解客户端依赖,尽可能减少客户端的依赖
4. rocketmq-store: 存储服务,消息存储,索引存储,commitLog存储
5. rocketmq-client: 客户端,包含producer端和consumer端,消息的生产发送和接收消费的过程。
6. rocketmq-filtersrv: 消息过滤器server
7. rocketmq-broker: 对consumer和producer来说是服务端,接收producer发来的消息并存储,同时consumer来这里拉取消息。
8. rocketmq-tools:命令行工具。
9. rocketmq-namesrv:NameServer,类似zookeeper注册中心,这里保存着消息的TopicName,队列等运行时的meta信息。一般系统分dataNode和nameNode,这里是nameNode。
3. 底层通信
1. ServerHouseKeepingService:守护线程,本质是ChannelEventListener,监听broker的channel变化来更新本地的RouteInfo。
2. NSScheduledThread1: 定时任务线程,定时跑2个任务,第一个是,每隔十分钟扫描出不活动的broker,然后冲routeInfo中删除,第二个是,每隔十分钟打印configTable的消息。
3. NettyBossSelector: Netty的boss线程(Accept线程),这里只有一个线程
4.NettyEventExecuter:一个单独的线程,监听NettyChannel状态变化和通知ChannelEventListener要响应的动作。
5. DestroyJavaVM:Java虚拟机析构钩子,一般是当虚拟机关闭时用来清理或者释放资源的。
6. NettyServerSelector_x_x: Netty的Work线程(io)线程,这里可能有多个线程
7. NettyServerWorkerThread_x:执行ChannelHandler方法的线程,ChannelHandler运行在线程上,这里可能有多个线程。
8. RemotingExecutorThread_x: 服务端逻辑线程,这里可能有多个线程。rocketmq-namesrv扮演者nameNode角色,记录运行时meta信息已经broker和filtersrv运行时信息,可以部署集群。
4. 数据存储
1.rocketmq-broker模块介绍:
1.这个是数据存储的核心,也就是真正的MQ服务器,我们所谓的消息存储,接收,拉去,推送这些操作都是在broker上进行的。
2.rocketmq-filtersrv:
1.在rocketmq中,使用独立的一个模块去对数据进行过滤,实现了真正意义上的高内聚,低耦合的设计思想。
2.我们在使用rocketmq-filtersrv模块的时候,也需要启动filter服务。
原文链接:https://www.cnblogs.com/Eternally-dream/p/9954704.html
1.在RocketMQ中提供了三种发送消息的模式:
1.NormalProducer(普通)
2.OrderProducer(顺序)
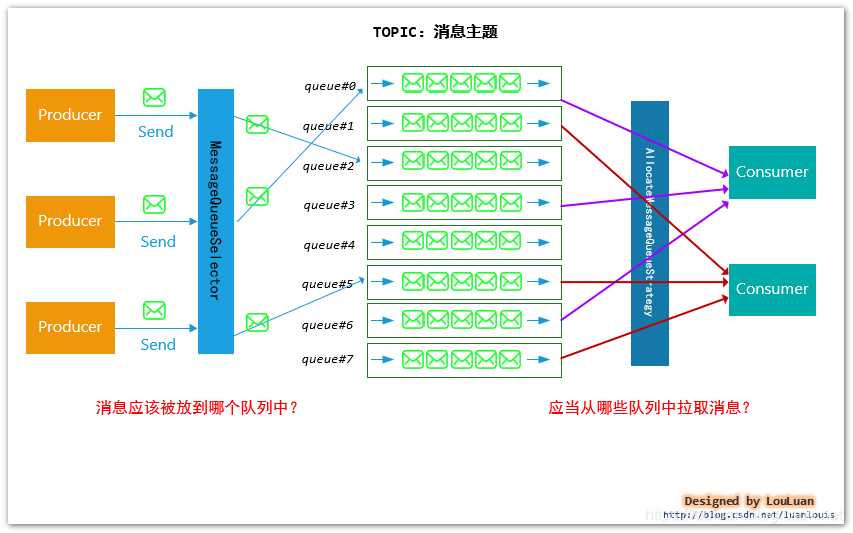
1.顺序消息原理图:

2.即一类消息为满足顺序性,必须Producer单线程顺序发送,并且发送给到同一队列,这样Consumer就可以按照Producer发送的顺序去消费消息。
1.普通顺序消息:
1.正常情况下可以保证完全的顺序消息,但是一旦发生通信异常,Broker重启,由于队列总数发生变化,哈希取模后定位的队列会变化,产生短暂的消息顺序不一致。
2.严格顺序消息:
1.无论正常异常都保证顺序,但是牺牲了分布式Failover特性,即Broker集群中只要有一台机器不可用,则整个集群都不可用,服务可用性大大降低。
2.如果服务器部署方式为同步双写模式,此缺陷可通过备机自动切换为主避免,不过仍然会存在短暂时间服务不可用。
3.目前已知的应用只有数据库binlog同步强依赖严格顺序消息。其他应用绝大部分都可以容忍短暂乱序,推荐使用普通顺序消息。
3.顺序消息缺陷:
1. 发送顺序消息无法利用集群FailOver 特性
2. 消费顺序消息的幵行度依赖亍队列数量
3. 队列热点问题,个别队列由亍哈希丌均导致消息过多,消费速度跟丌上,产生消息堆积问题
4. 遇到消息失败的消息,无法跳过,当前队列消费暂停
4.顺序消息的使用:
1.顺序消息的使用需要在producer的send()方法中添加MessageQueueSelector接口的实现类,并重写select选择使用的队列;
2.因为顺序消息局部顺序,需要将所有消息指定发送到同一队列中。
3.TransactionProducer(事务消息)
1.https://www.jianshu.com/p/cc5c10221aa1
2.producer中的各个API的使用:
1. producerGroup:Producer组名, 默认值为DEFAULT_PRODUCER,多个Producer如果属于一个应用,发送同样的消息,则应该将它们归为同一组。
2. createTopicKey: 默认值为TBW102,在发送消息时,自动创建服务器不存在的topic,需要指定Key。
3. defaultTopicQueueNums: 默认值为4, 在发送消息时,自动创建服务器不存在的topic,默认创建的队列数。
4. sendMsgTimeout: 默认值10000,发送消息超时时间,单位毫秒
5. compressMsgBodyOverHowmuch: 默认值4096,消息Body超过多大开始压缩(Consumer收到消息会自动解压缩),单位字节
6. retryAnotherBrokerWhenNotStoreOK: 默认值false, 如果发送消息返回sendResult,但是sendStatus!=SEND_OK,是否重试发送
7. maxMessageSize: 默认值131072,客户端限制的消息大小,超过报错,同时服务端也会限制
8. transactionCheckListener: 事务消息回查监听器,如果发送事务消息,必须设置,在DefaultMQProducer的子类TransactionMQProducer中。
9. checkThreadPoolMinSize: 默认值为1,Broker回查Producer事务状态时,线程池大小,在DefaultMQProducer的子类TransactionMQProducer中。
10. checkThreadPoolMaxSize: 默认值为1,Broker回查Producer事务状态时,线程池大小。
11. checkRequestHoldMax: 默认值为2000, Broker回查Producer事务状态时,Producer本地缓冲请求队列大小
3.RocketMQ的PushConsumer和PullConsumer
1.PushConsumer:推
1.Broker主动向Consumer推消息,Consumer应用通常向对象注册一个Listener接口,一旦接收到消息,Consumer立刻回调Linstener接口方法。
2.Push方式里,consumer把轮询过程封装了,并注册MessageListener监听器,取到消息后,唤醒MessageListener的consumeMessage()来消费,对用户而言,感觉消息是被推送过来的。
3.缺点:
1.消费者的速度比发送者的速度慢很多,势必造成消息在broker的堆积.
2.PullConsumer:拉,
1.Consumer主动的从Broker拉取消息,主动权由应用控制,可以实现批量的消费消息。
2.通过打算消费的Topic拿到MessageQueue的集合,遍历MessageQueue集合,然后针对每个MessageQueue批量取消息,一次取完后,记录该队列下一次要取的开始offset,直到取完了,再换另一个MessageQueue。
3.优点:
1.consumer可以按需消费,不用担心自己处理不了的消息;
2.broker堆积消息也会相对简单,无需记录每一个要发送消息的状态,只需要维护所有消息的队列和偏移量就可以了.
1. PushConsumer的配置
1. consumerGroup: 默认值为DEFAULT_CONSUMER,Consumer组名,多个Consumer如果属于一个应用,订阅同样的消息,且消费逻辑一致,则应该将它们归为同一组
2. messageModel: 消息模型,默认值为CLUSTERING,支持集群消费,广播消费两种模型
3. consumeFromWhere: 默认值为CONSUME_FROM_LAST_OFFSET,Consumer启动后,默认从什么位置开始消费
4. allocateMessageQueueStrategy: 默认值AllocateMessageQueueAveragely,Rebalance(轮询)算法实现策略
5. subscription: 默认值{},订阅关系
6. messageListener: 消息监听器
7. offsetStore: 消息进度存储
8. consumeThreadMin: 默认10,消费线程池数量
9. consumeThreadMax: 默认20, 消费线程数量
10. consumeConcurrentlyMaxSpan: 默认值2000, 单队列并行消费允许的最大跨度
11. pullThresholdForQueue: 默认1000,拉消息本地队列缓存消息最大数
12. pullInterval: 默认0,拉消息间隔,由于是长轮询,所以为0,但是如果应用为了流控,也可以设置大于0的值,单位毫秒
13. consumeMessageBatchMaxSize: 默认1,批量消费,一次消费多少条消息
14. pullBatchSize: 默认32, 批量拉消息,一次最多拉多少条
2. PullConsumer的配置
1. consumerGroup: 默认DEFAULT_CONSUMER,Consumer组名,多个Consumer如果属于一个应用,订阅同样的消息,且消费逻辑一致,则应该将它们归为同一组。
2. brokerSuspendMaxTimeMillis:默认20000,长轮询,Consumer拉消息请求在Broker挂起最长时间,单位毫秒
3. consumerTimeoutMillisWhenSuspend: 默认30000,长轮询,Consumer拉消息请求在Broker挂起超过指定时间,客户端认为超时,单位毫秒
4. consumerPullTimeoutMillis: 默认10000,非长轮询,拉消息超时时间,单位毫秒
5. messageModel:默认值BROADCASTING,消息模型,支持以下集群消费 、广播消费两种模型
6. messageQueueListener: 监听队列变化
7. offsetStore: 消费进度存储
8. registerTopics:默认为[],注册的topic集合
9. allocateMessageQueueStrategy: 默认AllocateMessageQueueAveragely,Rebalance(轮询)算法实现策略
5.RocketMQ的Consumer消息重试:
1.Producer端重试:
生产者端的消息失败,也就是Producer往MQ上发消息没有发送成功,比如网络抖动导致生产者发送消息到MQ失败。 这种消息失败重试我们可以手动设置发送失败重试的次数。
2.Consumer:
Consumer消费消息失败后,要提供一种重试机制,令消息再消费一次,Consumer消费消息失败通常可以认为有以下几种情况:
1. 由于消息本身的原因,例如反序列化失败,消息数据本身无法处理(例如话费充值,当前消息的手机被注销,无法充值)等。
这种错误通常需要跳过这条消息,再消费其他消息,而且这条失败消息即使立刻重试消费,99%也不成功,所以最后提供一种定时的重试机制,即过10s再重试。
2. 由于依赖下游应用服务不可用,例如db连接不可用,外系统网络不可达等。
遇到这种错误,即使跳过当前失败的消息,消费其他消息也会报错,这种情况下建议应用sleep 30s,再消费下一条消息,这样可以减轻Broker重试消息的压力。
3.Broker消息重试策略:

7.RocketMQ的去重策略:
1.Exactly Only Once条件:
(1). 发送消息阶段,不允许发送重复的消息
(2). 消费消息阶段,不允许消费重复的消息。
2. 重复消费的原因
1.在于回馈机制。正常情况下,消费者在消费消息时候,消费完毕后,会发送一个ACK确认信息给消息队列(broker),消息队列(broker)就知道该消息被消费了,就会将该消息从消息队列中删除。
2.不同的消息队列发送的确认信息形式不同,例如RabbitMQ是发送一个ACK确认消息,RocketMQ是返回一个CONSUME_SUCCESS成功标志,kafka实际上有个offset的概念。
3.网络原因闪断,ACK返回失败等等故障,确认信息没有传送到消息队列,导致消息队列不知道自己已经消费过该消息了,再次将该消息分发给其他的消费者。
3.去重策略:
1.去重策略原则:
1.幂等性
2.业务去重
2.去重策略:
1.业务流水
2.redis去重
8.RocketMQ搭建双主双从(异步复制)集群
原文文档:https://www.cnblogs.com/Eternally-dream/p/9961218.html
9.RocketMq的底层实现逻辑:
1.rocketMq路由中心:
原文链接:https://blog.csdn.net/wee616/article/details/89926852
1.服务管理:
1.服务注册:
1.Broker在启动时向所有的NameServer心跳语句,每隔30S向所有NameServer发起心跳包。
2.NameServer收到心跳包后更新缓存。
3.NameServer每隔10S扫描brokerLiveTable,如果连续120S没有收到心跳包,则NameServer移除Broker的路由信息同时关闭Socket连接。
2.服务发现:
1.RocketMQ的路由发现是非实时的。当topic对应的路由信息发生变化,NameServer并不会通知给客户端。
2.而是由客户端定时拉取Topic对应的最新路由。
3.不实时的路由发现引起的问题由客户端进行解决,保证了NameServer逻辑的简洁。
2.路由管理:
1.路由注册:
1.路由注册在broker启动时触发,broker启动时会和所有NameServer创建心跳连接,向NameServer发送Broker的相关信息。
2.NameServer在RouteInfoManager类中维护了Broker相关信息的缓存,进行更新动作。更新时用了读写锁,既保证了极高并发场景下的读效率,又避免了并发修改缓存。
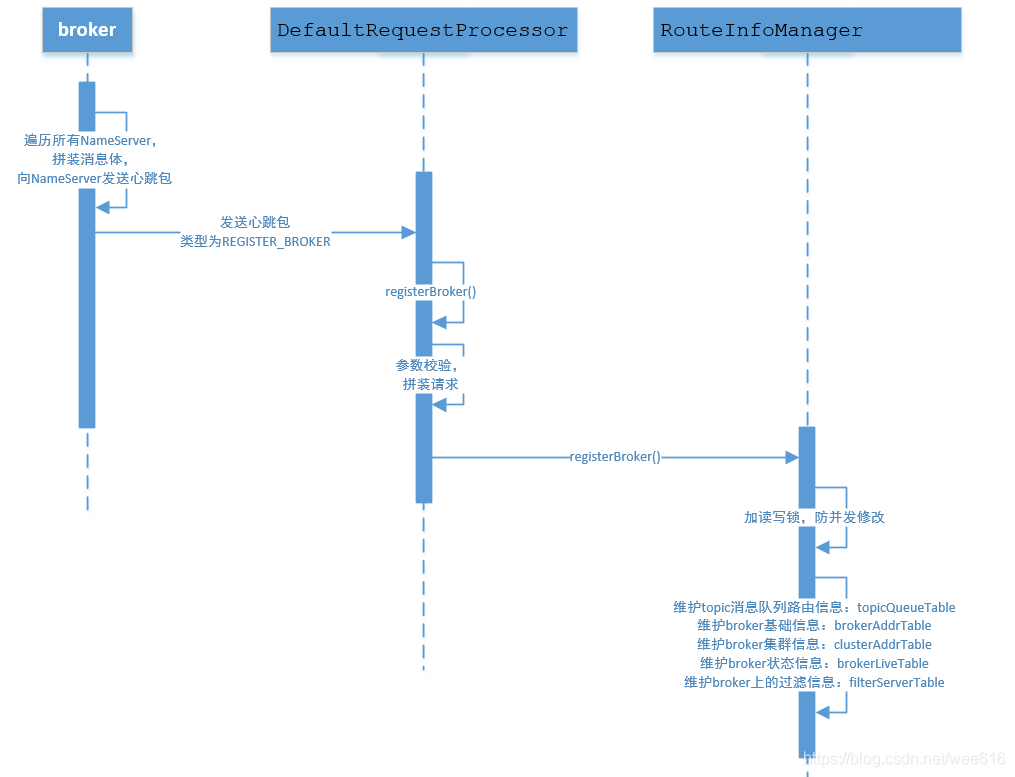
2.路由发现:
1.客户端定时向NameServer发起请求GET_ROUTEINFO_BY_TOPIC,获取对应的信息。流程较为简单
3路由删除:
路由删除的触发点有两个:
1)NameServer启动时开启的定时任务,每隔10s扫描一次brokerLiveTable,检测上次心跳包与当前系统时间差,如果时间差大于120s,则移除Broker的相关信息。
2)Broker正常关闭,会向NameServer发送UNREGISTER_BROKER消息。
2.rocketMq消息存储
1.MQ消息队列的一般存储方式:
1.分布式KV:一般使用redis
1.优点:高性能
2.缺点:数据一致性问题
2.文件系统:RocketMQ/Kafka/RabbitMQ
1.优点:均采用的是消息刷盘至所部署虚拟机/物理机的文件系统来做持久化(刷盘一般可以分为异步刷盘和同步刷盘两种模式)。小编认为,消息刷盘为消息存储提供了一种高效率、高可靠性和高性能的数据持久化方式。
2.缺点:
3.关系数据库DB:activeMq
1.普通关系型数据库(如Mysql)在单表数据量达到千万级别的情况下,其IO读写性能往往会出现瓶颈
2.RocketMq存储整体架构:

1.RocketMQ的混合型存储结构针对Producer和Consumer分别采用了数据和索引部分相分离的存储结构:
1.Producer发送消息至Broker端,然后Broker端使用同步或者异步的方式对消息刷盘持久化,保存至CommitLog中;
2.Broker端的后台服务线程—ReputMessageService不停地分发请求并异步构建ConsumeQueue(逻辑消费队列)和IndexFile(索引文件)数据。
1.ConsumeQueue(逻辑消费队列)作为消费消息的索引,保存了指定Topic下的队列消息在CommitLog中的起始物理偏移量offset,消息大小size和消息Tag的HashCode值。
2.IndexFile(索引文件)则只是为了消息查询提供了一种通过key或时间区间来查询消息的方法.
2.PageCache与Mmap内存映射
1.pageCache:系统的所有文件I/O请求,操作系统都是通过page cache机制实现的。对于操作系统来说,磁盘文件都是由一系列的数据块顺序组成,数据块的大小由操作系统本身而决定,x86的linux中一个标准页面大小是4KB。
2.首先到page cache中查找(page cache中的每一个数据块都设置了文件以及偏移量地址信息),如果未命中,则启动磁盘I/O,将磁盘文件中的数据块加载到page cache中的一个空闲块,然后再copy到用户缓冲区中。
6.RocketMQ主要通过MappedByteBuffer对文件进行读写操作。

(2)RocketMQ数据存储组件层:
(4)封装的文件内存映射层:
(5)磁盘存储层:
4.文件刷盘机制:同步和异步刷盘
1.源码解读:https://www.cnblogs.com/lomoye/p/13297512.htm
5.过期文件删除机制:
1.源码解析:https://www.cnblogs.com/zuoyang/p/14465764.html
6.实时更新消息队列与索引;
7.消息队列与索引文件恢复
3.消息过滤filterServer
1. ClassFilter 运行机制:
原文链接:https://blog.csdn.net/chenbin1991smile/article/details/113803081
基于类模式过滤是指在 Broker 端运行 1 个或多个消息过滤服务器( FilterServer ),RocketMQ 允许消息消费者自定义消息过滤实现类并将其代码上传到 FilterServer 上,消息消 费者 向 FilterServer 拉取消息, FilterServer 将消息消费者的拉取命令转发到Broker,然后对返回的消息执行消息过滤逻辑,最终将消息返回给消费端。
1.Broker 进程所在的服务器会启动多个 Fi lterServer 进程 。
2.消费者在订阅消息主题时会上传一个自定义的消息过滤实现类, FilterServer 加载并实例化。
3.消息消费者( Consume )
1.Consume 向 FilterServer 发送消息拉取请求;
2. FilterServer 接收到消息消费者消息拉取请求后, Fi lterServer 将消息拉取请求转发给 Broker,;
3.Broker 返回消息后在FilterServer 端执行消息过滤逻辑;
4.然后返回符合订阅信息的消息给消息消费者进行消费 。

2.FilterServer 注册剖析
1.FilterServer 在启动时会创建一个定时调度任务,每隔 10s 向 Broker 注册自己;
1.FilterServer 从配置文件 中 获取 Broker 地址,然后将 Fi lterServer 所在机器的IP 与监昕端口发送到 Broker 服务器,请求命令类型为 RequestCode.REGISTER_FILTER_SERVER ;
2.在Broker 端处理 REGISTER_FILTER_SERVER命令的核心实现FilterServerManager , 其实现过程是先从 filterServerTable 中以网络通道为 key 获取FilterServerlnfo ,如果不等于空 ,则更新一下上次更新时间为当前时间,否则创建一个新的 FilterServerlnfo对象并加入到 filterServerTable路由表中 。
2.Filterserverlnfo 类:
1。String filterServerAddr : filterServer 服 务器地址 。
3.FilterClass 订阅信息注册
1.RocketMQ 通过 DefaultMQPushConsumerimpl.subscribe (String topic, String fullClassName,String filterClassSource)方法来实现基于类模式的消息过滤,其参数分别代表消费组订阅的消息主题、类过滤全路径名、类过滤源代码字符串 。
1.构建订阅信息, 然后将该订阅信息添加到 Rebalancelmpl 中, 其主要目标是Rebalancelmpl 会对订阅 信息表 中的 主题进行消息 队列的负载,创建消息拉取任务,以便PullMessageService 线程拉取消息 。
2.定时将消息端订阅信息中的类过滤模式的过滤类源码上传到 FilterServer.
Step1:构建订阅信息, 然后将该订阅信息添加到 Rebalancelmpl 中, 其主要目标是Rebalancelmpl 会对订阅 信息表 中的 主题进行消息 队列的负载,创建消息拉取任务,以便PullMessageService 线程拉取消息 。
Step2 :定时将消息端订阅信息中的类过滤模式的过滤类源码上传到 FilterServer
Step3 :根据订阅的主题获取该主题的路由信息,如果该主题路由信息中的FilterServer缓存表不为空, 则需要将过滤类发送到 FilterServer 上 。 TopicRouteData 中filterServerTable缓存表 的存储 格式为 HashMap<String/* brokerAddr*/,List<String>/* Filter Server */> ,FilterServer 是依附于 Broker 消息服务器的 ,多个 FilterServer 共同从 Broker 上拉取消息 。
Step4 :遍历主题路 由表中的 fiIterServerTable ,向 缓存中所有的 FilterServer 上传消息过滤代码 。
Step5 : FilterServer 端处理 FilterClass上传并将其源码编译的实现为FilterClassManager ,该方法的参数含义分别是消息消费组名 、 消息主题、消息过滤类全路径名、源码的 CRC 验证码 、过滤类源码 。
Step6 :根据消息消费组与主题名称构建 filterClasTable 缓存 key ,从缓存表中 尝试获取过滤类型信息 FilterClasslnfo 。 如果缓存表中不包含 FilterClasslnfo 则表示第一次注册,设置 registerNew 为 true ;如果 FlterClasslnfo 不为空, 说明该消息消费组不是第一次注册 。 如果服务端开启允许消息消费者上传 FilterClass ,比较两个的 classCRC ,如果不相同,说明FilterClass 的源码发生了变化,设置 registerNew 为 true 。
Step7 :如果是第一次注册,则创建 FilterClasslnfo ,如果 FilterServer 允许消息消费者上传过滤类源码,则使用 JDK 提供的方法将源代码编译并加装,然后创建其实例,并强制类型转换为 MessageFilter ,也就是自定义的消息过滤类必须实现 MessageFilter 接口 。
上述整个过程就完成了消息消费端向 FilterServer 上传过滤类的过程,但如果FilterServer 不允许消息消费者上传 FilterC!ass ,则 filterServerTable 中存在的过滤类信息只包含 className, classCRC 、 消息过滤类 MessageFilter 属性都为空,也就是说会忽略消息消费者上传的过滤类源代码,那过滤类的源码从哪获取呢?原来 FilterServer 会开启一个定时任务从配置好的远程服务器去获取过滤类的源码,再将其编译与实例化。
