
python-函数
函数基础
1.函数的语法:
def 函数名(参数1,参数2,参数3,...)
'''注释'''
函数体
return 返回的值
说明:
return也可以返回多个值,以逗号分割,返回的值为元祖
例子:
def test(x): x = x + 1 return x print(test(4))
def test(x,y): x = x + 1 y=y*2 return x,y print(test(4,5)) #输出结果:(5, 10)
2.函数的位置参数:必须一一对应,缺一行少一行都不行
def test(x,y): x = x + 1 y=y*2 return x,y print(test(4,5))
3.函数的关键字参数:无须一一对应,缺一行少一行也不行
def test(x,y): x = x + 1 y=y*2 return x,y print(test(y=5,x=4))
4.位置参数必须在关键字参数的左边
def test(x,y,z): x = x + 1 y=y*2 z=z return x,y,z print(test(4,5,z=9))
5.函数的参数可以是列表、字典
def test(x,*arg,**kwargs): print(x) print(arg) #打印结果为元祖 print(kwargs) #打印结果为字典 test(1,2,3,4,(5,6),[7,8],t=3,f=9) #输出结果: # 1 # (2, 3, 4, (5, 6), [7, 8]) # {'f': 9, 't': 3} test(1,*[7,8],**{'t':3,'f':9}) #输出结果: # 1 # (7, 8) # {'f': 9, 't': 3} test(1,2,3,4,(5,6),[7,8],{'t':3,'f':9},**{'t':3,'f':9}) #输出结果: # 1 # (2, 3, 4, (5, 6), [7, 8], {'t': 3, 'f': 9}) # {'t': 3, 'f': 9}
6.函数无return,返回结果为None
def food():
haha=('i like milk')
v=food()
print(v)
#输出结果:None
7.函数返回值为函数,实际返回的是函数的内存地址
def food(): haha=('i like milk') return food v=food() print(v) #输出结果:<function food at 0x000002C9380F8E18>
8.全局变量和局部变量
编码规范:
全局变量大写
局部变量小写
优先读取局部变量,能读取全局变量,无法对全局变量重新赋值,但是对于可变类型,可以对内部元素进行操作。
name=['lili','hanmeimei','lucy'] def foo(): name.append('mike') print('新增成员:mike') foo() print('name=',name) #输出结果: #新增成员:mike #name= ['lili', 'hanmeimei', 'lucy', 'mike']
如果函数中有global关键字,变量本质上就是全局的那个变量,可读取可赋值
globla:定义全局变量
haha='1234' def food(): global haha haha=('i like milk') return haha v=food() print(v) #输出结果:i like milk
nonlocal:指定上一级变量
haha='1234' def food(): haha='i like milk' def tar(): nonlocal haha print(haha) return tar v=food()() #food()返回结果为tar的内存地址,food()()调用tar函数 print(v) #输出结果: # i like milk #print(haha)的结果 # None
9.风湿理论:函数既变量
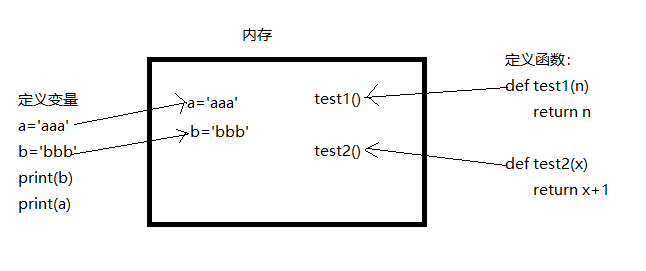
定义变量或者函数,都是先在内存中加载,加载完成后,后续调用时,无关定义的先后顺序
10.递归函数
1.python中的递归效率低,需要在进入下一次递归时保留当前的状态
2.必须有一个明确的结束条件
3.每次进入更深一层递归时,问题规模相比上次递归都应有所减少
4.递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
5.递归调用应该包含两个明确的阶段:回溯,递推
回溯就是从外向里一层一层递归调用下去,回溯阶段必须要有一个明确地结束条件,每进入下一次递归时,问题的规模都应该有所减少(否则,单纯地重复调用自身是毫无意义的)
递推就是从里向外一层一层结束递归
例如:
def calc(n): if int(n / 2) == 0: return n res=calc(int(n / 2)) print('res=',res) return res print(calc(10))
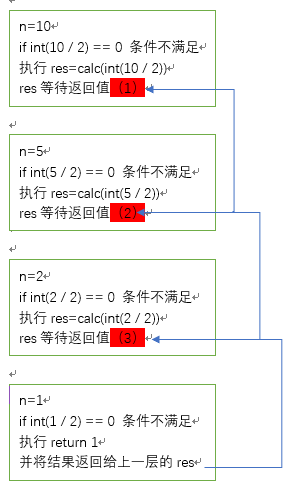
输出结果:
res= 1 -->第3层的res返回值
res= 1 -->第2层的res返回值
res= 1 -->第1层的res返回值
1 -->return n
11.匿名函数
1.与函数有相同的作用域,但是匿名意味着引用计数为0,使用一次就释放(一次性使用,随时随时定义)
2.有名函数:循环使用,保存了名字,通过名字就可以重复引用函数功能
# def test1(x,): # return x+1 # print(test1(1)) func = lambda x: x + 1 print(func(1)) # 输出结果:2 # def test2(x,y): # return x+1,y+2 # print(test2(1,2)) func = lambda x, y: (x + 1, y + 2) print(func(1, 2)) # 输出结果:(2, 4)
12.函数式编程
1.函数接收的参数是一个函数名
2.返回值中包含函数
(高阶函数:同时满足以上两个条件)
def tar(): print('tar') return 'tar1' def foo(n): #函数接收的参数是一个函数名 return n n=foo(tar()) print(n)
def tar(): print('tar') def foo(): # 函数式编程,返回值中包含函数 return tar
3.尾调用优化
在函数的最后一步调用另一个函数(最后一行不一定是最后一步)
尾调用由于是函数的最后一步,所以不需要保留外层函数的调用记录,因为调用位置、内存变量等信息都不会再用到了,只要直接调用内层函数的调用记录,取代外层函数的调用记录就可以了。所以,尾调用,内存里永远只保留一个调用记录。
def foo(): print('foo') def too(): print('too') foo() #函数最后一步进入另一个函数
13.map函数(内置函数中的一种)
1.map的使用:map(func,array) func:函数(处理方法),array:可迭代对象
2.map 处理结果为一个可迭代类型
num_l = [1, 2, 10, 5, 3, 7] print(map(lambda x: x + 1, num_l)) # 输出结果:<map object at 0x034AC350>
num_l = [1, 2, 10, 5, 3, 7] res = map(lambda x: x + 1, num_l) for i in res: # 通过for循环打印可迭代类型 print(i) # 输出结果: # 2 # 3 # 11 # 6 # 4 # 8
num_l = [1, 2, 10, 5, 3, 7] res = map(lambda x: x + 1, num_l) print(list(res)) # 通过list()方法获取 # 输出结果:[2, 3, 11, 6, 4, 8]
3.map处理结果为一个迭代器,只能被迭代一次
num_l = [1, 2, 10, 5, 3, 7] res = map(lambda x: x + 1, num_l) for i in res: # 通过for循环打印可迭代类型 print(i) print(list(res)) # 通过list()方法获取 # 输出结果: # 2 # 3 # 11 # 6 # 4 # 8 # [] #前面已经被迭代,所以列表为空
4.map中的处理方法可以是匿名函数或者有名函数
# map处理方法为匿名函数 num_l = [1, 2, 10, 5, 3, 7] print(list(map(lambda x: x + 1, num_l))) # 输出结果:[2, 3, 11, 6, 4, 8]
# map处理方法为有名函数 num_l = [1, 2, 10, 5, 3, 7] def reduce_one(x): return x-1 print(list(map(reduce_one, num_l))) # 输出结果:[0, 1, 9, 4, 2, 6]
14.filter函数(内置函数的一种)
1.filter的使用 filter(func,array),func:函数(处理方法),array:可迭代对象(与map函数处理过程类似)
func得到的是一个布尔值,如果是True,结果保留下来
函数可以是匿名函数或者是有名函数
movie_people = ['sb_alex', 'sb_lili', 'alice', 'sb_sherly'] print(list(filter(lambda n: n.startswith('sb'), movie_people))) print(list(filter(lambda n: not n.startswith('sb'), movie_people))) # 输出结果: # ['sb_alex', 'sb_lili', 'sb_sherly'] # ['alice']
movie_people = ['sb_alex', 'sb_lili', 'alice', 'sb_sherly'] def sb_show(n): return n.startswith('sb') print(list(filter(sb_show, movie_people))) # 输出结果:['sb_alex', 'sb_lili', 'sb_sherly']
15.reduce函数(内置函数的一种)
1.reduce的使用 filter(func,array,init),func:函数(处理方法),array:可迭代对象(与map函数处理过程类似),init:初始值
函数可以是匿名函数或者是有名函数
from functools import reduce num_l=[1,2,3,100] print(reduce(lambda x,y:x+y,num_l,2)) #在2的基础上将所有列表元素相加 2+1+2+3+100=108 #输出结果:108 print(reduce(lambda x,y:x+y,num_l)) #无初始值,所有列表元素相加 1+2+3+100=106 #输出结果:106
from functools import reduce num_l=[1,2,3,100] def add(x,y): return x+y print(reduce(add,num_l,2)) #在2的基础上将所有列表元素相加 2+1+2+3+100=108
16.map()、filter()、reduce()的区别
1.相同点
map()、filter() 、reduce()中的函数都可以匿名函数或者有名函数,处理的都是可迭代对象
2.不同点
map() 装一个列表,将列表的元素逐一处理,最终得到一个列表,且跟原来的列表的顺序一模一样
filter() 将列表当中所有的值都筛选一遍,最终得到一个列表
reduce() 将一个完整的序列合并到一起,得到一个值
17.内置函数
1.abs() 求绝对值
print(abs(-2)) #输出结果:2
2.all() 将序列中的每一个值做布尔运算
布尔运算: 0,空,None:假 其他:真
可迭代对象中,只要有一个为假,返回假
如果可迭代对象为空,返回真
print(all([1,None,'ab'])) print(all('hello')) print(all('')) #输出结果: # False # True # True
3.any() 与all()用法相反
可迭代对象中,只要有一个为真,返回真
如果可迭代对象为空,返回假
4.bool() #布尔值运算
0,空,None:假 其他:真
print(bool(0)) #False print(bool()) #False print(bool(None)) #False print(bool(1)) #True
5.bytes()将字符串转换为字节的形式
utf-8 规定1个英文字符用1个字节表示,1个中文字符用3个字节表示
gbk 是中文的字符编码,用2个字节代表一个字符
name1='hello' print(bytes(name1,encoding='utf-8')) #b'hello' name2='你好' print(bytes(name2,encoding='utf-8')) #b'\xe4\xbd\xa0\xe5\xa5\xbd' print(bytes(name2,encoding='gbk')) #b'\xc4\xe3\xba\xc3' #解码 decode后面最好写上编码,不写,python3默认编码utf-8 print(bytes(name2,encoding='utf-8').decode('utf-8')) #你好 print(bytes(name2,encoding='gbk').decode('gbk')) #你
6.chr()、ord()根据ascii码表的对应顺序进行转换
print(chr(97)) # a print(chr(66)) # B
print(ord('a')) #97 print(ord('B')) #66
7.dir() 打印某一个对象下面都有哪些方法
print(dir(all))
8.divmod(10,3) 分页功能 10/3 得到商和余数
print(divmod(10,3)) #(3, 1)
9.eval() 将字符串中的数据结构提取出来
dic={'name':'alice','age':18}
dic_str=str(dic)
d1=eval(dic_str) #将字符串中的数据结构提取出来
print(d1['name'])
express='1+2*3-9'
print(eval(express)) #将字符串中的表达式进行运算
10.bin() 、hex()、oct() 十进制转换
print(bin(3)) #0b11
print(bin(3)) #十进制转换成二进制 print(hex(12)) #十进制转换成十六进制 print(oct(12)) #十进制转换成八进制
11.hash() 可hash的数据类型既不可变数据类型,不可hash的数据类型既可变数据类型
name='alex' #同一个程序中,hash值相同 print(hash(name)) #-1871333864911787381 print(hash(name)) #-1871333864911787381 print(hash(name)) #-1871333864911787381 name='sss' #模拟软件被篡改 hash值改变 print(hash(name)) #-1376081792992900314
12.isinstance() 判断元素的数据类型
print(isinstance(1,int)) #True print(isinstance('sss',str)) print(isinstance([],list)) print(isinstance({},dict)) print(isinstance({1,2},set))
13.globals() 打印全局变量(包括系统中的全局变量),locals() 打印全局变量
name='1111111111111111111111111111111111111111111111111' def test(): age='22222222222222222222222222222' print(globals()) # 打印全局变量 print(locals()) # 打印局部变量 test()
打印结果:
{'__cached__': None, '__doc__': None, '__file__': 'C:/Users/ddd/PycharmProjects/untitled/mypython/函数.py', '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000001DC7885A828>, '__name__': '__main__', '__builtins__': <module 'builtins' (built-in)>, 'test': <function test at 0x000001DC78CC8E18>, 'name': '1111111111111111111111111111111111111111111111111', '__spec__': None, '__package__': None}
{'age': '22222222222222222222222222222'}
14.max() 取最大值,min() 取最小值
max函数处理的是可迭代对象,相当于一个for循环取出每个元素进行比较,注意,不同类型之间不能进行比较
每个元素间进行比较,是从每个元素的第一个位置依次比较,如果第一位分出大小,后面的都不需要比较了,直接得出这俩元素的大小
l=[1,3,100,-1,2] print(max(l)) #100 print(min(l)) #-1
age_dic={'age1':18,'age2':20,'age3':100,'age4':30}
print(max(list(zip(age_dic.values(),age_dic.keys()))))
#--> (100, 'age3')
dic=[ {'name':'egon','age':18}, {'name':'alex','age':38}, {'name':'wupeiqi','age':100}, {'name':'yuanhao','age':28} ] print(max(dic,key=lambda di:di['age'])) #取出年纪最大的成员信息 ##key=lambda di:di['age'] # ret=[] # for item in dic: # ret.append(item['age']) # print(ret) # print(max(ret))
15.zip将两个可迭代序列,一一对应组合
print(list(zip(('hello'),('12345')))) #---->[('h', '1'), ('e', '2'), ('l', '3'), ('l', '4'), ('o', '5')] p={'name':'Sherly','age':18} print(list(zip(p.values(), p.keys()))) # #--->[('Sherly', 'a'), (18, 'n')]
16.round() 四舍五入
print(round(3.78)) #4 print(round(3.24)) #3
17.pow() n次方运算
print(pow(3,3)) #3的3次方 3**3=27 print(pow(3,3,2)) #3的3次方除以2 ,取余 3**3%2
18.reversed()将列表顺序反转(临时反转,不改变原有列表顺序)
l=[2,4,6,1,9] print(list(reversed(l))) #-->[9, 1, 6, 4, 2] print(l) #-->[2,4,6,1,9]
19.slice() 切片范围
l='hello' s1=slice(3,5) #切片 print(l[s1]) #lo print(l[3:5]) #lo
l='1234567890' s1=slice(2,6,2) #切片 起始位置、结束位置、步长 print(l[s1]) #lo print(s1.start) #2 print(s1.stop) #6 print(s1.step) #2
20.sorted() 从小到大排序,不同类型之间不可以比较大小
l=[2,5,9,1,5,8,3] print(sorted(l)) #[1, 2, 3, 5, 5, 8, 9] 临时排序 print(l) #[2, 5, 9, 1, 5, 8, 3]
name_dic={ 'name4':18, 'name1':30, 'name3':25 } print(sorted(name_dic)) #-->['name1', 'name3', 'name4'] 默认排序字典的key print(sorted(name_dic,key=lambda key:name_dic[key])) #['name4', 'name3', 'name1'] 根据values排序 print(sorted(zip(name_dic.keys(),name_dic.values()))) #[('name1', 30), ('name3', 25), ('name4', 18)]
18.三元表达式
name='12345h' res='数字' if name=='12345' else '不是数字' #三元表达式 print(res)
19.列表推导式
声明式编程语法:
[expression for item1 in iterable1 if condition1
for item2 in iterable2 if condition2
...
for itemN in iterableN if conditionN
]
for i in range(10): print(i) l=[i for i in range(10)] #列表推导式 print(l)
for i in range(10): if i<5: print(i) l=[i for i in range(10) if i<5] #类似于三元表达式 print(l)
20.生成器表达式
把列表推导式的[]换成()就是生成器表达式
优点:省内存,一次只产生一个值在内存中
res=(i for i in range(10) if i<3) print(res) #<generator object <genexpr> at 0x03921300> 这里的res就是一个生成器 print(next(res)) #-->0 print(res.__next__()) #-->1 print(res.__next__()) #-->2 print(res.__next__()) #-->StopIteration 抛异常
21.函数的作用
1.减少重复代码
2.方便修改,更易扩展
3.保持代码的一致性
#学习资料来源
https://www.cnblogs.com/linhaifeng/articles/7532512.html
https://www.cnblogs.com/linhaifeng/articles/6113086.html
https://www.cnblogs.com/linhaifeng/articles/6133014.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号