

sql 语句(1)
完整语法
Select [列名]/*/all from 表名 [where条件子句] [group by子句] [having子句] [order by子句] [limit 子句];
datediff(now(),hiredate)/365 //表示现在的时间减去入职时间除以365天,也就是入职多少年
datediff()表示两个日期之间的天数
now()表示现在的时间
count(*)、count(1)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL。
count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空。
length()可以统计字符个数
ifnull((comm,0))表示若comm值为null则返回值为0
avg()统计平均值
in()
SELECT * FROM Customers WHERE Country IN ('Germany', 'France', 'UK');
表示在customers表中查询country列值是'Germany', 'France', 'UK'的职工信息
去重查询,查出来的结果,将重复给去除(所有字段都相同):select distinct */列名 from 表名
#比如名字我只记得后面是LACK,第一个字母忘了,WHERE ename like "_LACK"
#我只记得是A开头的, WHERE ename LIKE "A%"
#我只记得名字包含字母A,WHERE ename LIKE "%A%"
#名字大部分人都是英文的,有个中文名但是我不记得了,WHERE ename REGEXP "^[\\u4e00-\\9fa5]{2, 4}$"
#汉族人一般名字是2~4个字,汉字Unicode在\\u4e00-\\9fa5之间,^以...开头,$表示以...结尾。
group by 子句:(以字段名分组显示查询结果)
语法:
select 列名称,聚合函数(列名称) from 表名 where 条件子句 group by 列名 with rollup //with rollup表示对分组结果集再次做汇总计算(回溯统计)
select子句的列名称里不能出现除了分组列之外的列
group by 列名 [asc/desc] 对分组后的整个结果进行排序
GROUP_CONCAT函数(把分组查询中的某个字段拼接成一个字符串)
e.g:查询每个部门内底薪超过2000元的人数和员工姓名:
SELECT deptno, COUNT(*), GROUP_CONCAT(ename) FROM t_emp WHERE sal >= 2000 GROUP BY deptno;
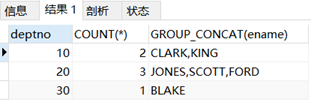
看到ename都是逗号连接的字符串
Between本身是闭区间。between左边的值必须小于或者等于右边的值

(反了,应该是小数在前边)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号