import math
from pandas import DataFrame
def sigmoid(x):#激活函数
return 1/(1+math.exp(-x))
f = open(r"data.txt")
line = f.readline()
data_list = []
while line:
num = list(map(float,line.split(',')))
data_list.append(num)
line = f.readline()
f.close()
x1 = data_list[0]
x2 = data_list[1]
y = data_list[2]
yita = 0.1
for i in range(0,9):
#中间层神经元输入和输出层神经元输入
Net_in = DataFrame(0.6,index=['input1','input2','theata'],columns=['a'])
Out_in = DataFrame(0,index=['input1','input2','input3','input4','theata'],columns=['a'])
Net_in.iloc[0] = x1[i]
Net_in.iloc[1] = x2[i]
Net_in.iloc[2,0] = -1
Out_in.iloc[4,0] = -1
#中间层和输出层神经元权值
W_mid=DataFrame(0.5,index=['input1','input2','theata'],columns=['mid1','mid2','mid3','mid4'])
W_out=DataFrame(0.5,index=['input1','input2','input3','input4','theata'],columns=['a'])
W_mid_delta=DataFrame(0,index=['input1','input2','theata'],columns=['mid1','mid2','mid3','mid4'])
W_out_delta=DataFrame(0,index=['input1','input2','input3','input4','theata'],columns=['a'])
#中间层的输出
for i in range(0,4):
Out_in.iloc[i,0] = sigmoid(sum(W_mid.iloc[:,i]*Net_in.iloc[:,0]))
#输出层的输出/网络输出
res = sigmoid(sum(Out_in.iloc[:,0]*W_out.iloc[:,0]))
error = abs(res-y[i])
#输出层权值变化量
W_out_delta.iloc[:,0] = yita*res*(1-res)*(y[i]-res)*Out_in.iloc[:,0]
W_out_delta.iloc[4,0] = -(yita*res*(1-res)*(y[i]-res))
W_out = W_out + W_out_delta #输出层权值更新
#中间层权值变化量
for i in range(0,4):
W_mid_delta.iloc[:,i] = yita*Out_in.iloc[i,0]*(1-Out_in.iloc[i,0])*W_out.iloc[i,0]*res*(1-res)*(y[i]-res)*Net_in.iloc[:,0]
W_mid_delta.iloc[2,i] = -(yita*Out_in.iloc[i,0]*(1-Out_in.iloc[i,0])*W_out.iloc[i,0]*res*(1-res)*(y[i]-res))
W_mid = W_mid + W_mid_delta #中间层权值更新
new_x1 = [0.38, 0.29]
new_x2 = [0.49, 0.47]
for i in range(0,2):
Net_in = DataFrame(0.6,index=['input1','input2','theata'],columns=['a'])
Out_in = DataFrame(0,index=['input1','input2','input3','input4','theata'],columns=['a'])
Net_in.iloc[0] = new_x1[i]
Net_in.iloc[1] = new_x2[i]
Net_in.iloc[2,0] = -1
Out_in.iloc[4,0] = -1
for i in range(0,4):#中间层的输出
Out_in.iloc[i,0] = sigmoid(sum(W_mid.iloc[:,i]*Net_in.iloc[:,0]))
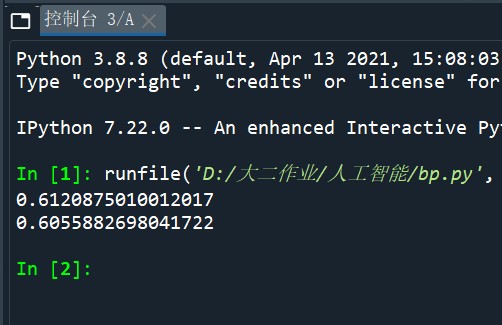
res = sigmoid(sum(Out_in.iloc[:,0]*W_out.iloc[:,0]))#输出层的输出
print(res)
![]()
import numpy as np
import scipy.special
import matplotlib.pyplot
class NeuralNetwork():
def __init__(self,inputnodes,hiddennodes,outputnodes,learningrate):
#设置输入层节点,隐藏节点和输出层节点的数量
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
#学习率设置
self.lr = learningrate
#权重矩阵设置,正态分布
self.wih = np.random.normal(0.0, pow(self.hnodes,-0.5),(self.hnodes,self.inodes))
self.who = np.random.normal(0.0, pow(self.onodes,-0.5),(self.onodes,self.hnodes))
#激活函数设置,sigmoid函数
self.activation_function = lambda x: scipy.special.expit(x)
pass
def train(self,input_list,target_list):
#转换输入输出列表到二维数组
inputs = np.array(input_list,ndmin=2).T
targets = np.array(target_list,ndmin=2).T
#计算到隐藏层的信号
hidden_inputs = np.dot(self.wih,inputs)
#计算隐藏层输出的信号
hidden_outputs = self.activation_function(hidden_inputs)
final_inputs = np.dot(self.who,hidden_outputs)#计算到输出层的信号
final_outputs = self.activation_function(final_inputs)
output_errors = targets-final_outputs
hidden_errors = np.dot(self.who.T,output_errors)
#隐藏层和输出层权重更新
self.who+=self.lr*np.dot((output_errors*final_outputs*(1.0-final_outputs)),np.transpose(hidden_outputs))
#输入层和隐藏层权重更新
self.wih+=self.lr*np.dot((hidden_errors*hidden_outputs*(1.0-hidden_outputs)),np.transpose(inputs))
pass
def query(self,input_list):
#转换输入列表到二维数组
inputs = np.array(input_list,ndmin=2).T
#计算到隐藏层的信号
hidden_inputs = np.dot(self.wih,inputs)
#计算隐藏层输出的信号
hidden_outputs = self.activation_function(hidden_inputs)
#计算到输出层的信号
final_inputs = np.dot(self.who,hidden_outputs)
final_outputs = self.activation_function(final_inputs)
return final_outputs
print('n')
input_nodes = 2#设置每层节点个数
hidden_nodes = 20
output_nodes = 1
learning_rate = 0.1#设置学习率为0.1
n = NeuralNetwork(input_nodes,hidden_nodes,output_nodes,learning_rate)#创建神经网络
training_data_file = open("data_tr.txt",'r')
training_data_list = training_data_file.readlines()
training_data_file.close()
print(training_data_list[0])
#训练神经网络
for record in training_data_list:
all_values = record.split(',')
inputs = np.asfarray(all_values[0:2])
targets = np.zeros(output_nodes)
targets[0] = all_values[2]
n.train(inputs,targets)
pass
#读取测试文件
test_data_file = open("data_te.txt","r")
test_data_list = test_data_file.readlines()
#readlines()方法读取文件所有行,保存在一个列表list向量中,每行作为一个元素,但读取大文件会比较占内存
test_data_file.close()
scorecard = []
total = 0
correct = 0
for record in test_data_list:
total += 1
all_values = record.split(',')
correct_label = float(all_values[2])#比较值
inputs = np.asfarray(all_values[0:2])
outputs = n.query(inputs)
label = float(outputs)
if(abs(label-correct_label)/correct_label<=0.3):
scorecard.append(1)
correct += 1
else:
scorecard.append(0)
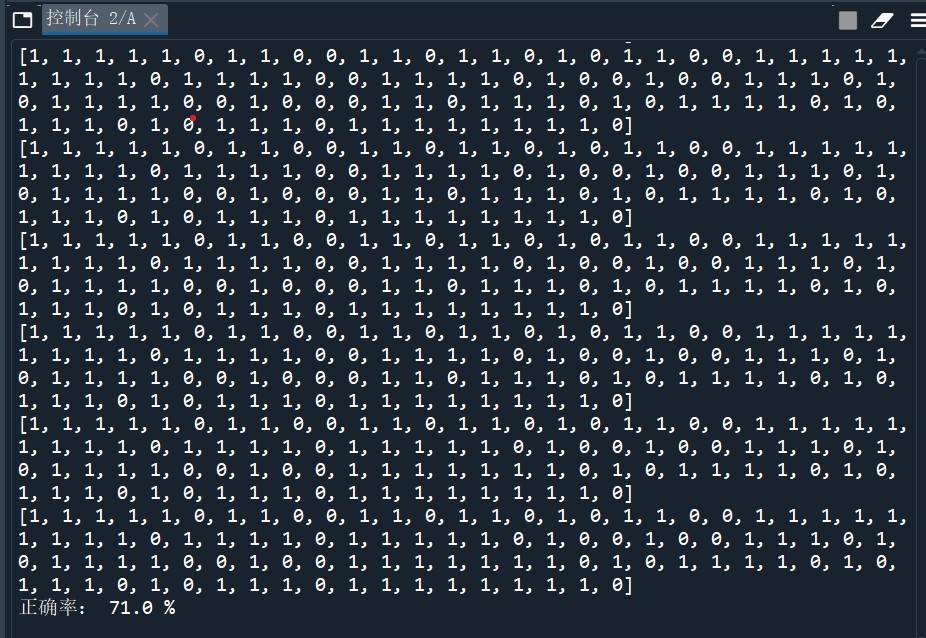
print(scorecard)
print('正确率:',(correct/total)*100,'%')
![]()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号