
回顾一
函数
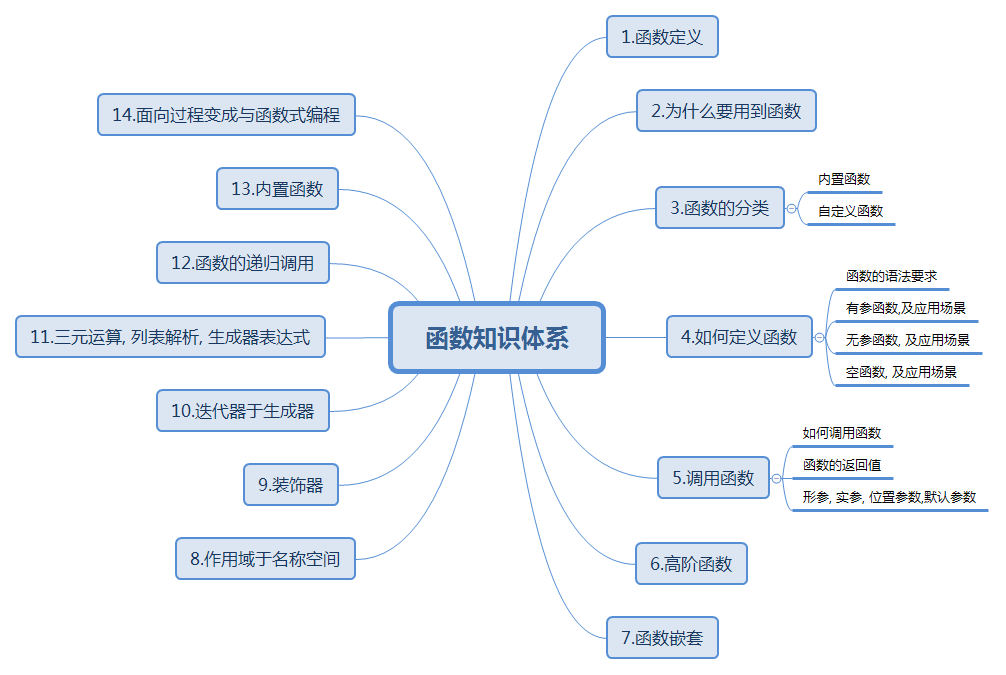
函数知识体系
what is function
- 函数的特点:
- 提高了代码的重用性-->不使用函数遇到重复的功能只能重复编写代码,代码冗余
- 结构清晰, 易维护--->不使用函数代码的组织结构不清晰, 可读性差
- 扩展性好--->现实中程序功能需要扩展
- 函数分类:
- 内置函数<python解释器已经为我们定义好功能的函数>
- 自定义函数<顾名思义需要我们自己编写该函数的功能>
- 定义函数
- 如何定义函数
-
# 函数基本语法 def func(参数1,参数2,....): '''注释''' 函数体 return 返回值 # 函数名即func要反应其意义
- 函数使用的原则:先定义, 在调用
- 函数即"变量", 任何的"变量"必须先定义好然后才可以 引用,未定义而直接引用的函数, 就相当于在引用一个不存在的变量名
![]() View Code
View Code# test1 def foo(): print("来自foo") bar() foo() # 这里直接运行foo函数会报错, 因为函数体内部的bar()函数并没有定义 # test2 def bar(): print("来自bar"') def foo(): print("来自foo") bar() foo() # 这里再次运行foo函数, 就不会再报错, 因为定义了bar函数 # test3 def foo(): print('来自foo') bar() def bar(): print('来自bar') foo() # 这里不会报错, 函数的使用,必须遵守原则, 先定义,后调用, 而且要明确区分定义阶段和调用阶段 # 定义阶段 def foo(): print('来自foo') bar() def bar(): print('来自bar') # 调用阶段<可以理解为运行函数> foo()
-
函数在定义阶段:只检测语法, 不执行代码, 即纠正语法错误, 逻辑错误只有执行后才会知道
- 函数即"变量", 任何的"变量"必须先定义好然后才可以 引用,未定义而直接引用的函数, 就相当于在引用一个不存在的变量名


-
- 定义函数的三种形式
- 无参: 应用场景仅仅执行一些操作
- 有参: 需要根据外部传入的参数, 才能执行相应的逻辑
- 空函数: 设计代码结构
- 有参&无参
1 def test1(tag, n): 2 '''有参''' 3 print(tag*n) 4 5 def test2(): 6 '''无参''' 7 print("hello world") 8 9 test1('=', 12) 10 test2() 11 test1('=', 12)
- 空函数
![]() View Code
View Code1 def auth(user,password): 2 ''' 3 auth function 4 :param user: 用户名 5 :param password: 密码 6 :return: 认证结果 7 ''' 8 pass 9 10 def get(filename): 11 ''' 12 :param filename: 13 :return: 14 ''' 15 pass 16 17 def put(filename): 18 ''' 19 :param filename: 20 :return: 21 ''' 22 def ls(dirname): 23 ''' 24 :param dirname: 25 :return: 26 ''' 27 pass 28 29 #程序的体系结构立见
- 定义函数的三种形式
调用函数
- 调用函数: 函数名加括号
- 返回值<return>:
- 没有return--->None
- return一个值--->返回一个值
- return多个值--->返回一个元组
- 什么时候用return
- 需要一个明确的结果, 则必须有返回值, 通常有参函数需要有返回值,
- 仅仅只是执行一些列操作, 最后不需要得到什么结果, 则不需要有返回值,通常无参函数不需要有返回值
函数的参数
-
形参与实参
-
形参即变量名
-
实参即变量值
-
顾名思义, 形参形式上是参数, 其实只是一个虚假的, 实参实际运行中需要的参数
-
- 位置参数<按照位置给形参传值>
- 从左到右的顺序定义
1 def foo(x, y, z): 2 print('传入的参数是:', x, y, z) 3 4 foo(1, 2, 3) 5 foo('a', 'b', 'c') 6 # 从左到右位置一一对应
- 从左到右的顺序定义
- 关键字参数<在位置参数右边, 同一个形参不能重复传值>
- 按照k=v的形式定义的实参
1 def foo(name, age, addr): 2 print("姓名: %s, 年龄:%s, 地址:%s" % (name, age, addr)) 3 4 foo(name='李云龙', age=30, addr='平安县')
- 按照k=v的形式定义的实参
- 默认参数<位置参数右边,通常为不可变类型>
- 形参在定义时就已经为其赋值
- 运行时可以传值也可以不传值, 经常需要变得参数定义成位置参数, 变化小的定义为默认参数
1 def foo(age, job, name='李云龙'): 2 print("姓名: %s, 年龄:%s, 职务:%s" % (name, age, job)) 3 4 foo(age=30, job='团长') 5 foo(name='张大彪', age=28, job='参谋长') 6 # 第二次运行, name重新赋值'张大彪'
- 可变长参数
- *args和**kwargs
1 def foo(name, job, *args): 2 print("姓名:%s, 职务:%s" % (name, job)) 3 print("事迹:", args) 4 5 foo('李云龙', '团长', '击溃坂田联队','攻打平安县', '剿灭黑云寨') 6 # name= 李云龙, job=团长, 其余事迹分别传入*args中
- *args和**kwargs
- 命名关键字参数
- *后定义的参数, 必须传值(有默认值的除外),必须按照关键字实参的形式传递
1 def foo(x,y,*args,a=1,b,**kwargs): 2 print(x,y) 3 print(args) 4 print(a) 5 print(b) 6 print(kwargs) 7 8 foo(1,2,3,4,5,b=3,c=4,d=5) 9 # 运行一下看一下输出结果 10
- *后定义的参数, 必须传值(有默认值的除外),必须按照关键字实参的形式传递
函数对象
- 函数第第一类对象, 即函数可以当做数据传递
- 函数可以被引用
- 可以当做参数传递
- 返回值可以是函数
- 可以当做容器类型的元素
- 函数的嵌套调用
1 def max(x, y): 2 '''选出较大的值''' 3 return x if x > y else y 4 5 def func(a, b, c, d): 6 '''用max()函数选出四个数中的最大值''' 7 res1 = max(a, b) 8 res2 = max(res1, c) 9 res3 = max(res2, d) 10 return res3 11 12 print('最大值是:', func(2,4,6,8))
-
函数的嵌套定义
1 def foo(): 2 def bar(): 3 def test(): 4 print("from the test") 5 test() 6 bar() 7 foo()
名称空间和作用域
- 三种名称空间:1.局部名称空间, 2.全局名称空间, 3.内置名称空间
- 名称空间加载顺序: 先是内置, 接着全局, 最后局部
- 名字查找顺序:先是局部, 接着全局, 最后内置<注意:全局的不可以查看局部的, 局部的可以查看全局的,换言之,-->段鹏知道丁伟, 丁伟不知道段鹏>
1 name = '李云龙' 2 def foo(): 3 name = "赵刚" 4 print('from the foo' ,name) 5 def bar(): 6 name = '丁伟' 7 print('from the bar', name) 8 def test(): 9 name = '孔杰' 10 print("from the test", name) 11 test() 12 bar() 13 foo() 14 # 可以将name分别注释, 即可看出效果
- 作用域
- 全局范围<内置与全局名称空间属于这个范畴>,全局存活 全局都有效
- 局部范围<局部名称空间属于该范畴>,临时存活, 局部有效
- 作用域关系是在函数定义阶段就已经固定的, 与函数的调用位置无关
- 查看作用域: globals(), locals()
global和nonlocal关键字
- 闭包:
- 内部函数包含对外部作用域而非全局作用域的引用
- 闭包的意义与应用
- 意义:返回的函数对象, 不仅仅是一个函数对象, 在该函数外还包裹了一层作用域,这使得函数无论在何处调用,优先使用自己外层包裹的作用域
- 应用领域:延迟计算
1 from urllib.request import urlopen 2 3 def index(url): 4 def get(): 5 return urlopen(url).read() 6 return get 7 8 9 baidu = index('http://www.baidu.com') 10 print(baidu().decode('utf-8'))
装饰器
- 装饰器的作用
- 开放封闭原则: 对修改封闭, 对扩展开放
- 什么是装饰器
- 装饰其他的器具,本身可以是任意可调用对象, 被装饰者也可以是任意可调用对象
- 原则: 1.不修改被装饰对象的源代码,2.不修改被装饰对象的可调用方式
- 目标: 在遵循1和2的前提下, 为被装饰对象添加新的功能
- 装饰器的使用
- 无参装饰器
1 import time 2 3 def timmer(func): 4 def wrapper(): 5 start_time = time.time() 6 func() 7 stop_time = time.time() 8 print("函数的运行时间是: ",stop_time-start_time) 9 return wrapper 10 11 @timmer 12 def test(): 13 '''测试函数''' 14 time.sleep(3) 15 # 函数运行时间延迟3秒 16 print("函数运行完毕!") 17 18 test()
- 有参装饰器
1 import time 2 def timmer(func): 3 def wrapper(*args,**kwargs): 4 start_time = time.time() 5 res = func(*args,**kwargs) # 运行的是test 6 stop_time = time.time() 7 print("test函数运行时间是 %s" %(stop_time-start_time)) 8 return res 9 return wrapper 10 11 12 @timmer 13 def test(name, age,gender): 14 time.sleep(3) 15 print("test函数运行完毕") 16 print("作者是 %s, 今年 %s 岁, 性别 %s" %(name, age, gender)) 17 return '这是test的返回值' 18 19 res = test('Gunner',25,gender = 'male') # 就是运行wrapper
- 无参装饰器
- 装饰器的语法
- 装饰器补充:wraps
1 from functools import wraps 2 3 def deco(func): 4 @wraps(func) #加在最内层函数正上方 5 def wrapper(*args,**kwargs): 6 return func(*args,**kwargs) 7 return wrapper 8 9 @deco 10 def index(): 11 '''哈哈哈哈''' 12 print('from index') 13 14 print(index.__doc__)
迭代器
- 迭代器概念
- 迭代是一个重复的过程, 每次重复即一次迭代, 并且每次迭代的结果都是下一次迭代的初始值
- 为什么要有迭代器
- 字符串, 字典, 元组可以通过索引取值, 但对于字典, 集合,文件等没有索引, 为了获取没有索引的值, 则必须找出一种不依赖于索引的迭代方式, 这就是迭代器
- 可迭代对象就是指内置有__iter__方法的对象
- 可迭代对象执行__iter__()得到的结果就是迭代器对象,而迭代器对象指的是不仅内置有__iter__又的内置有__next__方法的对象,文件类型是可迭代对象
- 注意: 迭代器对象一定是可迭代对象, 而可迭代对象不一定是迭代器对象
- 迭代器对象的使用
- for循环
1 #基于for循环,我们可以完全不再依赖索引去取值了 2 dic={'a':1,'b':2,'c':3} 3 for k in dic: 4 print(dic[k]) 5 6 #for循环的工作原理 7 #1:执行in后对象的dic.__iter__()方法,得到一个迭代器对象iter_dic 8 #2: 执行next(iter_dic),将得到的值赋值给k,然后执行循环体代码 9 #3: 重复过程2,直到捕捉到异常StopIteration,结束循环
- 迭代器的优缺点
- 优点:提供一种统一的, 不依赖于索引的迭代方式, 惰性计算, 节省内存
- 缺点: 无法获取长度(只能在程序运行结束后才回到有几个值),一次性, 只能往后走, 不能往后退
生成器
- 什么是生成器
- 只要函数内部包含有yield关键字, 那函数名()得到的结果就是生成器, 并且不会执行函数内部代码
- 生成器与迭代器的关系
- 协程函数
- yield总结
三元表达式
-
1 name = input("姓名>>: ") 2 res = '团长' if name =='李云龙' else '你他娘的真是个天才' 3 print(res)
列表推导式
1 # 列表解析 2 egg_list1 = [] 3 for i in range(10): 4 egg_list1.append('鸡蛋%s' % i) 5 6 print(egg_list1) 7 # egg_list2是列表解析 8 egg_list2 = ['鸡蛋%s' % i for i in range(10)] 9 print(egg_list2)
- 优点: 方便, 改变了编程习惯, 可称之为声明式编程
生成器表达式
egg_list2 = ('鸡蛋%s' % i for i in range(10)) print(egg_list2.__next__()) print(egg_list2.__next__()) print(egg_list2.__next__()) print(next(egg_list2)) print(list(egg_list2)) # __next__() = next()二者等效 # 将列表解析的[]换成()就是生成器表达式 # 优点: 省内存, 一次只产生一个值在内存中
递归
- 定义
- 递归调用时函数嵌套调用的一种特殊形式, 函数在调用时, 直接或间接调用了自身, 就是递归调用
![]() View Code
View Code1 # 自己调用自己 2 def foo(): 3 print('from the foo') 4 foo() 5 6 foo() 7 8 # 间接调用自己 9 def f1(): 10 print('来自f1') 11 f2() 12 13 def f2(): 14 print('来自f2') 15 f1() 16 17 f1()
- 递归调用时函数嵌套调用的一种特殊形式, 函数在调用时, 直接或间接调用了自身, 就是递归调用
- 递归调用的两个阶段
- 推递
- --->就是从里向外一层一层结束递归
- 回溯
- --->就是从外向里一层一层递归调用下去<必须要有一个明确的结束条件, 没进入下一次递归时, 问题的规模都应该有所减少>
- 推递
- python中的递归效率低且没有尾递归优化
- python中的递归效率低, 需要在进入下一次递归时保留当前的状态, python没有尾递归, 且对递归层级做了限制
- 总结递归的使用
- 1.必须有一个明确的结束条件
- 2.每次进入更深一层递归时,问题规模相比上一次递归都应有所减少
- 3.递归效率不高, 递归层次过多会导致栈溢出
- 二分法
- 想从一个按照从小到大排列的数字列表中找到指定的数字, 遍历的效率太低, 用二分法可以极大缩小问题规模
匿名函数
- 什么是匿名函数
def func(x, y): return x + y print(func(10, 20)) res = lambda x, y: x + y print(res(5,10)) # 即lambda表达式, 后面跟参数, :后面是简单的式子
- 有名字的函数与匿名函数对比
- 有名函数:循环使用, 保存了名字, 通过名字就可以重复引用函数功能
- 匿名函数:一次性使用, 随时使用随时定义
内置函数
-
https://docs.python.org/3/library/functions.html?highlight=built#ascii

 浙公网安备 33010602011771号
浙公网安备 33010602011771号