

深度学习初识
深度学习概念
首先大家接触的是人工智能,那么比较容易混淆的概念有人工智能,机器学习,深度学习。它们三者之间的关系是人工智能最大,包括机器学习和深度学习是最大的概念,其次就是机器学习,机器学习包括深度学习,机器学习是第二大的概念,深度学习在它之内。
机器学习的流程
首先接受机器学习的流程,如下深度学习解决的是机器学习的特征提取的工程
可以是获取的数据更加符合我们问题的输入。
- 数据获取
- 特征工程
深度学习解决的是这个问题 - 建立模型
- 评估与应用
特征工程的作用
- 数据的特征决定了模型的上限
- 预处理和特征提取是最核心的
- 算法与参数决定了如何逼近这个上限
为啥要学深度学习
深度学习需要自己去提取特征,深度学习的应用,深度学习可以在计算机视觉和自然语言处理,人脸识别,医学的图像
深度学习的计算量比较大。
举例一个深度学习的应用实例:计算机视觉
在图像之中计算机理解图像的方式是把图像中每个位置看作一个个数值的像素点
数值的范围是0 -255
图像的存储是一个矩阵,图像一般是有颜色通道比如jpg就是RGB的
计算机视觉的挑战
- 部分遮盖
- 背景混入
机器学习常规套路
- 收集数据并给定标签
- 训练一个分类器
- 测试,评估
K近邻算法
判断数据周围的近邻的数据来分类,根据数据周围的数据附近的数据的类别的多少来判断此数据是哪种类型的数据
这就涉及到类型附近的这个范围,也就是周围如何定义,可能定义的大和定义的小是完全不同的结果
K近邻的计算流程
- 计算已知类别数据集中的点与当前点的距离
- 按照距离次序排序
- 选取与当前距离最小的K个点
- 确定前K个点所在类型的出现概率
- 返回前K个点出现频率最高的类别作为当前点预测分类
CIFAR-10数据介绍
十个类别
5000个训练数据
10000个测试数据
大小均为32 * 32
CIFAR10应用K近邻的算法
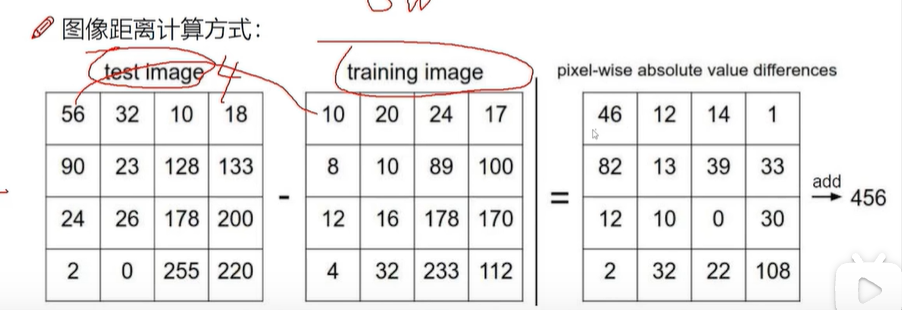
发现测试结果出现了部分可以,但是部分不可以,出错率较高
那么K近邻的算法不可以用来图像分类
主要是因为图像的背景不能区别出来
我们如何去判断一个图片的主题是哪个呢?需要用到神经网络结构
神经网络基础
线性函数
是一个从输入到输出的映射
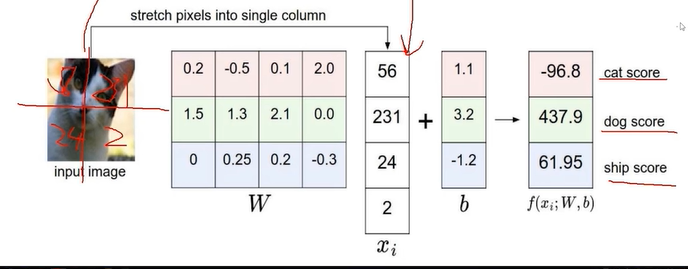
不如将一个图像进行输入,输出图像的类别。
当一个图像是32323的图像
那么为了让每个像素点对应的数据区分出重要程度,我们就需要权重来给出具体的参数
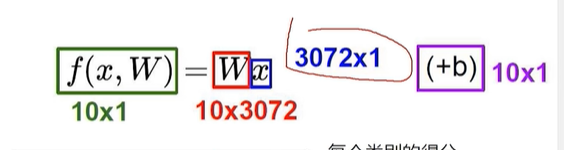
W 是要去看分的类别
W的权重参数
如果数据的权重值比较大的话就是对应位置就是重要点
还有一个就是有正有负正的表示重要,负的表示抑制。
损失函数
如何衡量分类结果
结果的结果有着明显的差异,我们需要明确的知道模型的当前效果!
如果损失函数的值相同,意味着两个模型一样吗?
答案是不一样

只关注一个局部的参数就会容易过拟合
解决这个问题,可以借助正则化惩罚
正则惩罚和数据没关和数据模型训练中的参数有关
读者可以先了解这个正则化
Softmax分类器
当我们想要一个概率值

exp表示映射成一个大的数据,放大差距
normalize表示转换成概率
归一化的操作就是求概率
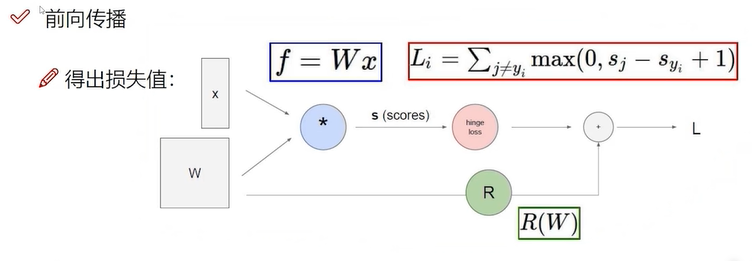
这个图中是将输入数据和权值做一个计算,然后再计算损失函数接着加上正则化惩罚来计算和正确的结果之间的差距
这是一个典型的前向传播,那么如何更新模型中的参数呢,就需要反向传播了,也就用到了梯度下降算法,通过梯度下降算法来更新权重,一次次的权重就会把这个参数设计的更好。
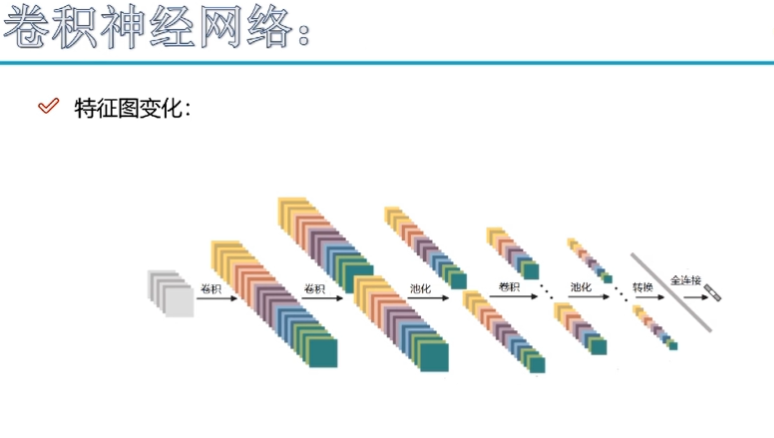
池化层
池化层是将卷积层得到的大量数据进行筛选压缩
224* 224* 64->112* 112* 64
MAX POOLING操作,是选这个框中的最大值
迁移学习
以为针对的问题可能需要大量的数据,所以我们设计的实验模型可能效果不是特别好,如果数据充足,但是依旧可能在训练模型的过程需要大量的时间
所以就需要迁移学习的方法
卷积操作就需要相当于特征提取,我们可以利用它的卷积层,当然也可以对它的权重进行改变。
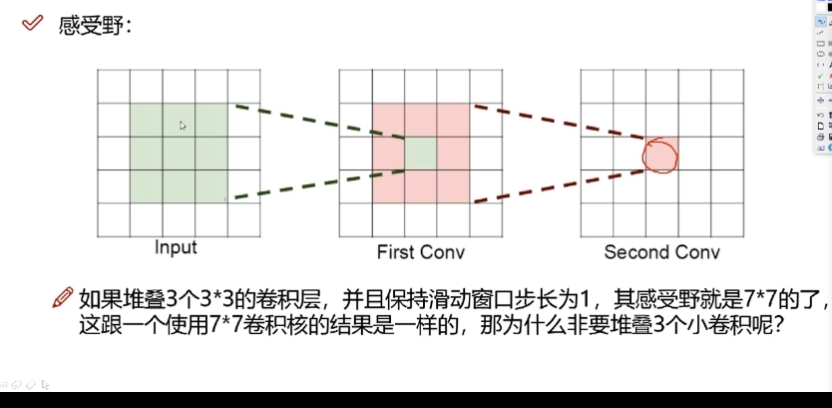
感受野

 浙公网安备 33010602011771号
浙公网安备 33010602011771号