

30作业
一:hadoop1.x和hadoop2.x区别
答:Hadoop1.x由MapReduce(数据计算和资源调度)、HDFS(数据存储)、Common(辅助工具组成)
Hadoop2.x中将MapReduce中的资源调度功能提取出来形成了一个新的模块,也就是Yarn。
这样可以降低耦合度,MapReduce负责运算数据,yarn负责资源调度
二:概念理解
(1)HDFS组成:
NameNode:
答:它可以存储文件的元数据(元数据就是数据属性,如文件名、大小、目录结构等)
DataNode:
答:可以在本地文件系统存储文件块数据,也可以进行数据的校验和
SecondaryNameNode:
答:用来监控HDFS状态的辅助后台程序,并且每隔一定时间会获取HDFS元数据的快照。
快照相当于每隔一段时间对元数据进行备份,如果再某个时间点数据发生问题,可以回滚,使用备份
(2)YARN组成
ResourceManager(处理客户端请求)
答:(1)处理客户端请求
(2)监控NodeManager
(3)启动和监控ApplicationMaster
(4)资源的分配和调度
NodeManager()
答:(1)管理单个节点上的资源
(2)处理来自ResourceManager和AppplicationMaster的命令
ApplicationMaster()
答:(1)负责数据的切分
(2)为应用程序申请资源并分配给内部的任务
(3)任务的监控和容错
Container
(3)MapReduce组成
答:它分为Map阶段和Reduce阶段,Map阶段并行处理输入数据,Reduce阶段对Map结果进行收集汇总
三:本地运行Hadoop 案例
1、需求:(1)在hadoop-2.7.2文件下创建一个input文件夹
(2)将Hadoop的xml配置文件复制到input
(3)执行share目录下的MapReduce程序,找到input下所有包含dfs的文件


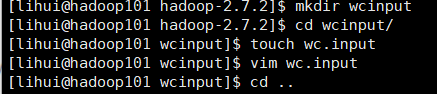
2、需求:(1)在hadoop-2.7.2文件夹下创建一个wcinput文件夹
(2)在wcinput文件夹下创建一个wc.input文件
(3)编辑wc文件
(4)查看wcinput目录下所有文件里每个单词出现的次数,将结果汇总到wcoutput文件夹里

四:伪分布式运行Hadoop 案例
1、需求:(1)在HDFS文件系统创建一个input文件夹

(2)将测试文件内容上传到文件系统

(3)查看上传的文件是否正确

(4)运行MapReduce程序

(5)查看输出结果

(6)将测试内容下载到本地

(7)删除输出结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号