
python正则表达式
python中使用re模块来完成正则表达式,内置了许多表达式的方法,这里就简单的介绍几种常用的
一.re.match(pattern,string,flags)
pattern:表示书写的正则表达式
string:需要匹配的字符串
flags:匹配方式(如:不区分大小写)
flags主要分为以下几种(使用多个匹配方式时可以用|隔开(或的意思))
re.I :不区分大小写
re.L: 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
re.M :多行模式
re.S :即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
re.U :表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
re.X :为了增加可读性,忽略空格和 # 后面的注释
我们在使用re模块调用match方法进行正则表达式匹配的会得到如下结果,不便于直接查看,可以在后面加上span()方法
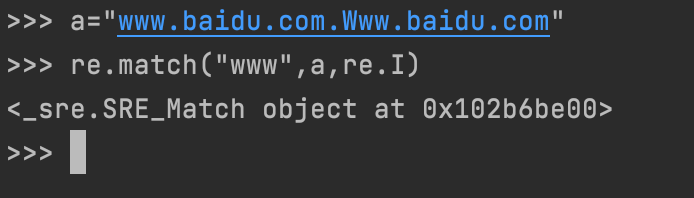
会得到匹配第一个符合条件的字符纬度(简单理解为坐标吧),我们可以看出,a中有两个“www”,但是匹配出来的只

显示出来一个匹配的结果,这是因为match()方法从目标字符的开头开始匹配,若匹配有结果返回,没有结果返回none,
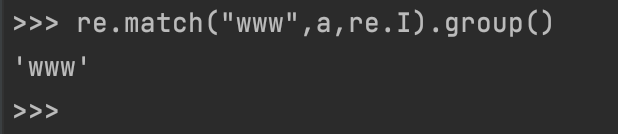
我们要想返回匹配的正则表达式的结果,可以使用group()方法查看匹配后返回的结果。
二.re.search(pattern,string,flags)
pattern:表示书写的正则表达式
string:需要匹配的字符串
flags:匹配方式(如:不区分大小写)
search()和match()使用大致相同,唯一的不同就是匹配的方式,这也是两者的不同点,search()是从整个字符串进行匹配的
有结果返回第一个匹配的结果,没有结果就返回none,match(从开头开始匹配,若开头就不符合匹配要求直接返回none)
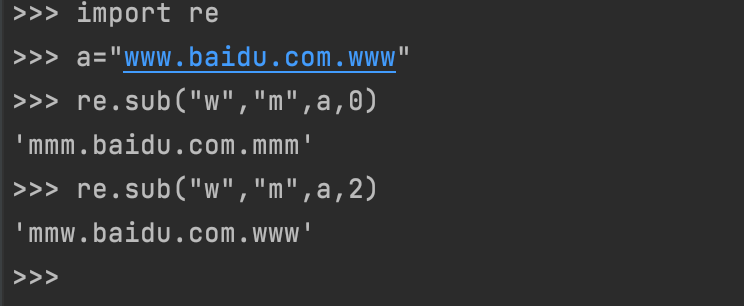
三.re.sub(pattern,repl,string,count,flags),对匹配的结果替换
pattern:表示书写的正则表达式
repl:匹配后的结果
string:需要匹配的字符串
count:匹配的结果个数要替换的结果(0表示匹配的全部都替换,具体数字表示前多少个要替换)
flags:匹配方式(如:不区分大小写)
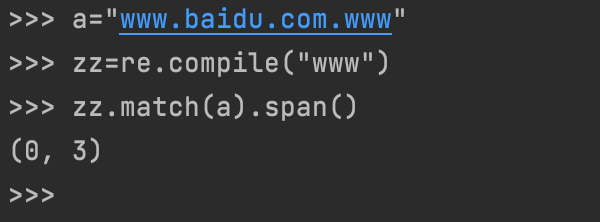
四.re.compile(pattern),加工一个正则表达式并生成一个对象
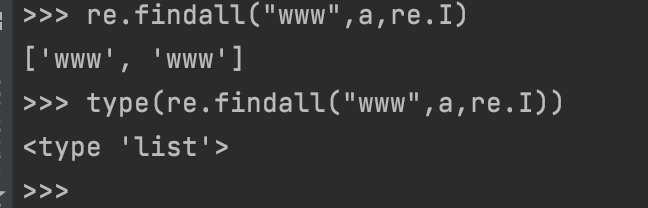
五.re.findall(pattern,string,flags),将匹配的所有结果生成list
pattern:表示书写的正则表达式
string:需要匹配的字符串
flags:匹配方式(如:不区分大小写)
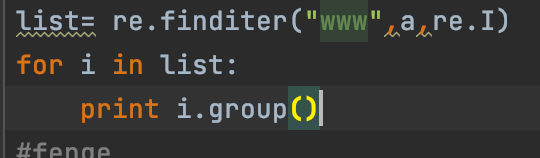
六.re.finditer(pattern,string,flags),将匹配的所有结果已迭代的形式返回
pattern:表示书写的正则表达式
string:需要匹配的字符串
flags:匹配方式(如:不区分大小写)
七.re.split(pattern,string,maxsplit,flags),在匹配的结果之间进行分割,并返回list形式
pattern:表示书写的正则表达式
string:需要匹配的字符串
maxspilt:对匹配结果的前多少个进行分割
flags:匹配方式(如:不区分大小写)

八.常见的元字符
例:匹配0-100:^(100|[0-9]{1,2})$
| . | 匹配任何字符(除了换行符) |
| ^ | 匹配字符串的开头 |
| & | 匹配字符串的结尾 |
| * | 匹配前面的子表达式零次或多次 |
| + | 匹配前面的子表达式一次或多次 |
| ? | 匹配前面的子表达式零次或一次 |
| {n} | 匹配前面的子表达式恰好n次 |
| {n,} | 匹配前面的子表达式至少n次 |
| {n,m} | 匹配前面的子表达式至少n次,但不超过m次 |
| [...] | 字符集,匹配方括号中的任何字符 |
| [^...] | 否定字符集,匹配任何不在方括号中的字符 |
| \d | 匹配任何数字,等价于[0-9] |
| \D | 匹配任何非数字字符,等价于[^0-9] |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等 |
| \S | 匹配任何非空白字符 |
| \w | 匹配任何单词字符,等价于[a-zA-Z0-9_] |
| \W | 匹配任何非单词字符 |
| | | 或的意思 |
注:以上正则表达式中的写法是以www代表的,这种写法不规范,建议书写的按照正确的表达式写法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号