

强化学习-广义策略迭代
参考:
(1)强化学习(第二版)
(2)强化学习精要-核心算法与TensorFlow实现
一、广义策略迭代(GPI)
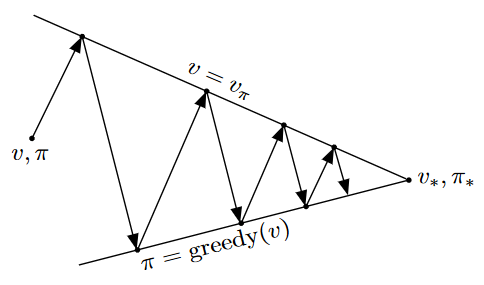
策略迭代包括两个同时进行的相互作用的流程,即策略评估和策略改进。策略总是基于特定的价值函数进行改进,价值函数也始终会向对应特定策略的真实价值函数收敛。我们可以从图中看出,策略改进会使之前的价值函数对于改进后的策略不再收敛,而策略评估也会使得之前的策略不再是重新收敛后的价值函数的贪心策略。但是随着两个流程的交替进行,我们最终得到了最优的策略和价值函数。在GPI中,我们可以让每次走的步子小一些,即可以不必等到价值函数收敛就去执行策略改进,这样做也通常可以得到最优的策略和价值函数。
二、广义策略迭代实例
1、游戏背景介绍
请参考:https://www.cnblogs.com/lihanlihan/p/15956427.html
2、代码实现
import numpy as np import gym from gym.spaces import Discrete from contextlib import contextmanager import time class SnakeEnv(gym.Env): #棋格数 SIZE = 100 def __init__(self, dices): #动作上限列表 self.dices = dices #梯子 self.ladders = {82: 52, 52: 92, 26: 66, 98: 22, 14: 22, 96: 63, 35: 12, 54: 78, 76: 57} #状态空间 self.observation_space = Discrete(self.SIZE + 1) #动作空间 self.action_space = Discrete(len(dices)) #初始位置 self.pos = 1 def reset(self): self.pos = 1 return self.pos def step(self, a): step = np.random.randint(1, self.dices[a] + 1) self.pos += step #到达终点,结束游戏 if self.pos == 100: return 100, 100, 1, {} #超过终点位置,回退 elif self.pos > 100: self.pos = 200 - self.pos if self.pos in self.ladders: self.pos = self.ladders[self.pos] return self.pos, -1, 0, {} def reward(self, s): if s == 100: return 100 else: return -1 def render(self): pass class TableAgent(): def __init__(self, env): #状态空间数 self.s_len = env.observation_space.n #动作空间数 self.a_len = env.action_space.n #每个状态的奖励 self.r = [env.reward(s) for s in range(0, self.s_len)] #策略(初始时每个状态只采取第一个策略) self.pi = np.array([0 for s in range(0, self.s_len)]) #状态转移概率 self.p = np.zeros([self.s_len, self.a_len, self.s_len], 'float') ladder_move = np.vectorize(lambda x: env.ladders[x] if x in env.ladders else x) for src in range(1, 100): for i, dice in enumerate(env.dices): prob = 1 / dice step = np.arange(1, dice + 1) step += src step = np.piecewise(step, [step > 100, step <= 100], [lambda x: 200 - x, lambda x: x]) step = ladder_move(step) for dst in step: self.p[src, i, dst] += prob #状态价值函数 self.value_pi = np.zeros((self.s_len)) #状态-动作价值函数 self.value_q = np.zeros((self.s_len, self.a_len)) #打折率 self.gamma = 0.8 def play(self, state): return self.pi[state] class PolicyIteration(): def __init__(self): pass def policy_evaluation(self, agent, iters): for i in range(iters): for i in range(1, agent.s_len): ac = agent.pi[i] transition = agent.p[i, ac, :] agent.value_pi[i] = np.dot(transition, agent.r + agent.gamma * agent.value_pi) def policy_improvement(self, agent): new_policy = np.zeros_like(agent.pi) for i in range(1, agent.s_len): for j in range(0, agent.a_len): #动作价值函数 agent.value_q[i, j] = np.dot(agent.p[i, j, :], agent.r + agent.gamma * agent.value_pi) #策略改进 max_act = np.argmax(agent.value_q[i, :]) new_policy[i] = max_act if np.all(np.equal(new_policy, agent.pi)): return False else: agent.pi = new_policy return True def policy_iteration(self, agent): iteration = 0 while True: iteration += 1 self.policy_evaluation(agent) ret = self.policy_improvement(agent) if not ret: break class ValueIteration(): def __init__(self): pass def value_iteration(self, agent): iteration = 0 while True: iteration += 1 f = 0 #遍历状态 for i in range(1, agent.s_len): d = agent.value_pi[i] value_sas = [] #遍历动作 for j in range(0, agent.a_len): value_sa = np.dot(agent.p[i, j, :], agent.r + agent.gamma * agent.value_pi) value_sas.append(value_sa) agent.value_pi[i] = max(value_sas) f = max(f, abs(agent.value_pi[i] - d)) if f < 1e-6: break print('Iter {} rounds converge'.format(iteration)) #计算动作价值函数,选取最优的策略 for i in range(1, agent.s_len): for j in range(0, agent.a_len): agent.value_q[i, j] = np.dot(agent.p[i, j, :], agent.r + agent.gamma * agent.value_pi) max_act = np.argmax(agent.value_q[i, :]) agent.pi[i] = max_act def eval_game(env, policy): state = env.reset() return_val = 0 for epoch in range(100): while True: if isinstance(policy, TableAgent): act = policy.play(state) elif isinstance(policy, list): act = policy[state] else: raise IOError('Illegal policy') state, reward, terminate, _ = env.step(act) return_val += reward if terminate: break return return_val / 100 @contextmanager def timer(name): start = time.time() yield end = time.time() print('{} cost:{}'.format(name, end - start)) def policy_iteration_demo(): env = SnakeEnv([3, 6]) agent = TableAgent(env) pi_algo = PolicyIteration() iteration = 0 with timer('time'): while True: iteration += 1 #将策略评估轮数设置为5(将策略评估轮数设置为1时误差偏大导致获得的策略稍差) pi_algo.policy_evaluation(agent, 1) #策略改进 res = pi_algo.policy_improvement(agent) if not res: break print('return_val={}'.format(eval_game(env, agent))) print(agent.pi) policy_iteration_demo()
3、运行结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号