

2-python自动化-day02
本节内容:
- 列表、元组操作
- 字符串操作
- 字典操作
- 集合操作
- 文件操作
- 字符编码与转码
转载: http://www.cnblogs.com/alex3714/articles/5717620.html
一、列表(list)符号:[]
是我们最以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储、修改等操作
切片:取多个元素


>>> names = ["Alex","Tenglan","Eric","Rain","Tom","Amy"] >>> names[1:-1] #取下标1至-1的值,不包括-1 ['Tenglan', 'Eric', 'Rain', 'Tom'] >>> names[0:3] ['Alex', 'Tenglan', 'Eric'] >>> names[:3] #如果是从头开始取,0可以忽略,跟上句效果一样 ['Alex', 'Tenglan', 'Eric'] >>> names[3:] #如果想取最后一个,必须不能写-1,只能这么写 ['Rain', 'Tom', 'Amy'] >>> names[3:-1] #这样-1就不会被包含了 ['Rain', 'Tom'] >>> names[0::2] #后面的2是代表,每隔一个元素,就取一个 ['Alex', 'Eric', 'Tom'] >>> names[::2] #和上句效果一样 ['Alex', 'Eric', 'Tom']
统计
>>> names ['Alex', 'Tenglan', 'Amy', 'Tom', 'Amy', 1, 2, 3] >>> names.count("Amy") 2
排序&翻转
>>> names ['Alex', 'Tenglan', 'Amy', 'Tom', 'Amy', 1, 2, 3] >>> names.sort() #排序 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unorderable types: int() < str() #3.0里不同数据类型不能放在一起排序了,擦 >>> names ['Alex', 'Amy', 'Amy', 'Tenglan', 'Tom', '1', '2', '3'] >>> names.sort() >>> names ['1', '2', '3', 'Alex', 'Amy', 'Amy', 'Tenglan', 'Tom'] >>> names.reverse() #反转 >>> names ['Tom', 'Tenglan', 'Amy', 'Amy', 'Alex', '3', '2', '1']
获取下标
>>> names ['Tom', 'Tenglan', 'Amy', 'Amy', 'Alex', '3', '2', '1'] >>> names.index("Amy") 2 #只返回找到的第一个下标
二、元组(Tuple)符号:()
元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表
语法
names = ("alex","jack","eric")
它只有2个方法,一个是count,一个是index,完毕。
三、字典(dict)符号:{key:value}
字典一种key - value 的数据类型,使用就像我们上学用的字典,通过笔划、字母来查对应页的详细内容。
语法:
info = {
'stu1101': "TengLan Wu",
'stu1102': "LongZe Luola",
'stu1103': "XiaoZe Maliya",
}
字典的特性:
- dict是无序的
- key必须是唯一的,so 天生去重
4.集合(set)符号:{}
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
5.字符编码
详细文章:
http://www.cnblogs.com/yuanchenqi/articles/5956943.html
http://www.cnblogs.com/zhangqigao/p/6496172.html
需知:
1.在python2默认编码是ASCII, python3里默认是unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
上面提到,UNICODE字符串可以与任意字符编码的字节进行相互转换,如图:
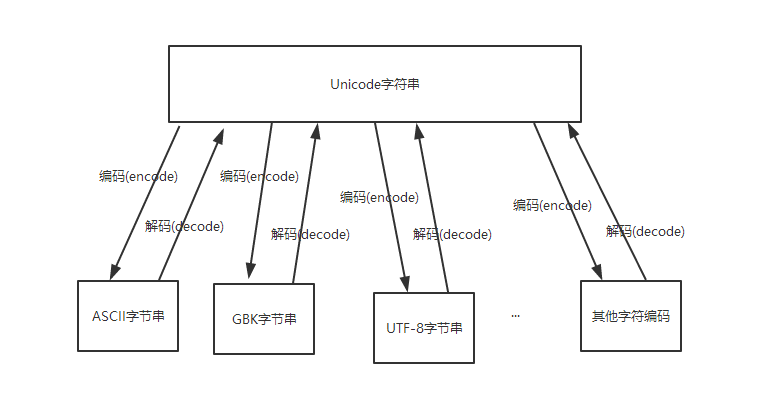
那么大家很容易想到一个问题,就是不同的字符编码的字节可以通过Unicode相互转换吗?答案是肯定的。
Python2中的字符串进行字符编码转换过程是:
字节串-->decode('原来的字符编码')-->Unicode字符串-->encode('新的字符编码')-->字节串
Python3中定义的字符串默认就是unicode,因此不需要先解码,可以直接编码成新的字符编码:
字符串-->encode('新的字符编码')-->字节串

 浙公网安备 33010602011771号
浙公网安备 33010602011771号