数仓建模——维度表详细讲解
数仓建模——维度表详细讲解
https://www.woshipm.com/data-analysis/5788960.html
一、维度表是什么
维度表是一种数据建模技术,用于存储与数据中心的各个业务领域相关的维度信息。它通常用于构建数据仓库、数据集市等决策支持系统,以便进行多维数据分析和报告。
在数据仓库中,维度表是与事实表相对应的表。维度表是维度建模的基础和灵魂。事实表紧紧围绕业务过程进行设计,事实表存储度量数据,如销售额、数量、收入等,而维度表则围绕业务过程所处的环境进行设计,维度表存储描述度量数据的各个方面的信息,例如时间、地理位置、产品、客户等。维度表主要包含一个主键和各种维度字段,维度字段称为维度属性。
https://zhuanlan.zhihu.com/p/561736994
省流
事实表(Fact Table)又称主题表,其本质是记录交易的表,往往维度很大。
维度表(Dimension Table)又称维表,其本质是基础表,类似于事实表的外键
,往往维度较少,冗余较大。
例如商品价格表(包含商品名、价格等)是维度表;售货表(包含商品名、顾客名、交易数量等)是事实表。 例如顾客信息表(用户昵称、用户ip等)是维度表;顾客交易表(包含商品名、交易数量等)是事实表。
为什么我们需要维度表?
事实表一般非常大(往往是宽表),不适合使用常规方法查询,因此需要将一些维度剥离出来作为维度表。维度表出现的目的就是为了使事实表能够减少冗余,提高存储效率。
维度表用于关联事实表(其本身可能有冗余信息,可以帮助事实表节省空间),用于数据检索
。一个事实表都需要和一个或多个维度表相关联。维度表内的内容往往用于描述事实表中的数据,因此多为静态数据。
维度表和事实表的信息可以聚合在一起形成一个信息全面的表,称之为指标表,又称宽表。在数据中台(middle-end)中使用宽表,可以减轻业务系统
压力,同时为前端的服务提供快速的数据查询(相当于把数据压力剥离出来放到独立的系统中)。
大数据中常提到的星形结构
、雪花结构等本质就是针对不同的场景需求对表采取了不同程度的拆分用于提升存储或是查询效率。
https://zhuanlan.zhihu.com/p/12006187512
事实表和维度表是数据仓库设计中的两个核心概念,它们在数据分析和商业智能
中扮演着重要角色。理解并熟练掌握这两个概念,是成为一名优秀数据分析师的必经之路,而获取CDA数据分析师,则是对这些技能的一种行业认可,能够显著提升个人的职业竞争力。
事实表(Fact Table)
事实表记录业务活动的具体细节,如销售记录、订单信息等。它通常包含大量的行数据,主要存储可度量的数值信息,例如金额、交易量或数量等。事实表的设计原则是正确记录历史信息,每一条记录都是多个维度表的数据和指标值交汇的结晶。
事实表的粒度决定了其业务主键,所有度量值必须具有相同的粒度。例如,如果事实表记录的是每日销售额,那么粒度就是日,所有相关的度量值(如销售额、订单数量等)都必须基于日来计算。此外,事实表通常没有传统意义上的主键,因为其数据量会随时间增长,而维度表则有主键以节省存储空间。
在实际应用中,事实表的设计需要考虑到数据的完整性和一致性。例如,在电子商务销售分析中,销售事实表会记录每个销售记录的详细信息,如销售日期、客户ID、产品ID、数量和金额等。这些信息是后续数据分析的基础。
维度表(Dimension Table)
维度表用于描述事实表中的事件的要素,提供上下文信息,使数据更易于理解和分析。维度表通常包含描述性属性,如客户姓名、地址、电话等详细信息,并具有层次结构,便于聚合和查询。
维度表的设计原则是以合适的角度聚合主题内容,其主键通常是代理键(一种无意义的整数主键),用于过滤、分组和标记。常见的维度表包括时间维度表、产品维度表和客户维度表等。例如,时间维度表可能包括日期、月份、年份等信息,产品维度表可能包括产品ID、名称、类别、价格等信息。
维度表在数据分析中起着至关重要的作用。它们为事实表中的数据赋予了意义,使得分析师能够从不同的角度对数据进行深入分析。例如,在电子商务销售分析中,通过结合销售事实表和客户维度表,可以分析不同客户的购买行为,从而制定更有效的营销策略。
https://github.com/EbEmad/Dimensional-Modeling-Practiical-guide/tree/main/Dimension%20modeling/Snowflak_Dim
A Snowflake Dimension is a type of dimension modeling technique in data warehousing where the dimension data is normalized into multiple related tables, rather than being stored in a single denormalized table.
It represents hierarchical relationships explicitly by breaking down the dimension into levels — for example:
Country → State → City.
This design reduces data redundancy and improves data integrity, but at the cost of more complex joins.
| CountryID | CountryName |
|---|---|
| 1 | USA |
| StateID | StateName | CountryID |
|---|---|---|
| 10 | Texas | 1 |
| CityID | CityName | StateID |
|---|---|---|
| 100 | Dallas | 10 |
| 101 | Austin | 10 |
| DateID | FullDate | Day | Month | Quarter | Year |
|---|---|---|---|---|---|
| 20240701 | 2024-07-01 | 1 | 7 | Q3 | 2024 |
| 20240702 | 2024-07-02 | 2 | 7 | Q3 | 2024 |
| SaleID | CityID | DateID | Amount |
|---|---|---|---|
| 1 | 100 | 20240701 | 300.00 |
| 2 | 101 | 20240702 | 450.00 |
| SaleID | CountryName | StateName | CityName | FullDate | Amount |
|---|---|---|---|---|---|
| 1 | USA | Texas | Dallas | 2024-07-01 | 300.00 |
| 2 | USA | Texas | Austin | 2024-07-02 | 450.00 |
+---------------------+
| Dim_Country |
+---------------------+
| CountryID (PK) |
| CountryName |
+---------------------+
▲
|
+---------------------+
| Dim_State |
+---------------------+
| StateID (PK) |
| StateName |
| CountryID (FK) |
+---------------------+
▲
|
+---------------------+
| Dim_City |
+---------------------+
| CityID (PK) |
| CityName |
| StateID (FK) |
+---------------------+
▲
|
+------------------+ +-------------------+
| Dim_Date | | Fact_Sales |
+------------------+ +-------------------+
| DateID (PK) |<------| DateID (FK) |
| FullDate | | CityID (FK) |
| Day, Month, etc. | | Amount |
+------------------+ | SaleID (PK) |
+-------------------+
| Benefit | Description |
|---|---|
| Storage Efficiency | Removes redundant data by splitting hierarchies into separate tables |
| Data Integrity | Foreign key constraints ensure consistency across levels |
| Query Flexibility | Enables analysis at multiple levels (e.g., by country, state, or city) |
| Maintainability | Easier to update individual dimensions without affecting others |
| Advantage | Trade-off |
|---|---|
| Reduces redundancy | Requires more joins |
| Clean structure | Slightly complex query writing |
| Easier updates | May lead to slower performance |
https://github.com/fanqingsong/data-modelling-with-postgresql
https://github.com/fanqingsong/Snowflake_dbt_etl
https://zhuanlan.zhihu.com/p/629478342
dbt(data build tool)的设计初衷就是为了应对数据转换层的挑战。dbt提供了一种基于模型的数据转换方法,旨在简化和标准化数据转换的过程。它提供了一种可扩展、可维护和可测试的方式来定义、执行和文档化数据转换逻辑。
通过使用dbt,数据团队可以使用SQL来定义数据转换操作,将其组织成模型(models),并通过依赖关系来管理数据转换流程。dbt支持模块化的设计和重用,可以将常用的转换逻辑封装成可复用的模型片段。此外,dbt还提供了丰富的功能,如数据验证、异常处理、数据测试等,以提高数据质量和可靠性。
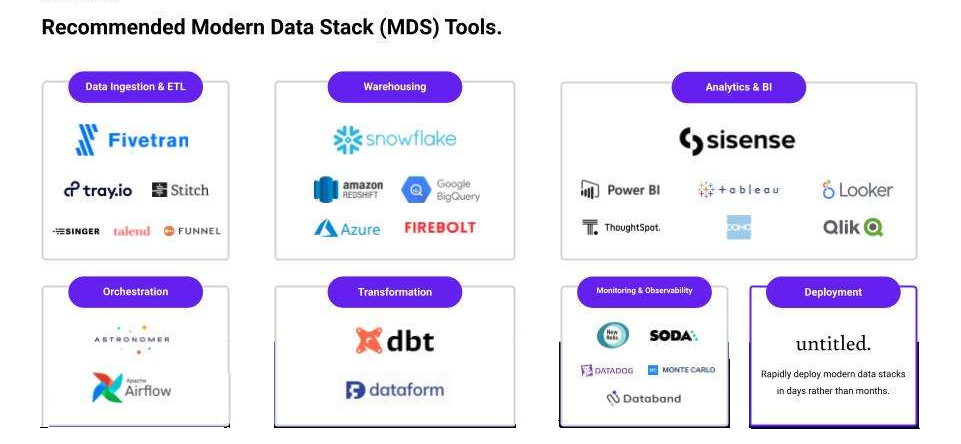
dbt还支持与其他数据工具的集成,例如数据抽取工具(如Fivetran、AirByte、Stitch)、数据仓库(如Snowflake、BigQuery)和BI工具(如Tableau、Looker),从而实现端到端的数据转换和分析流程。
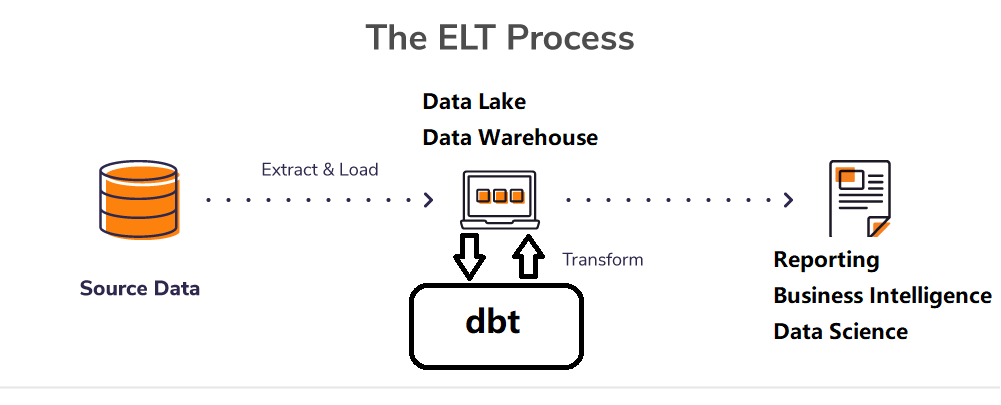
因此,dbt是为了应对数据转换层的挑战而设计的工具,旨在提供一种灵活、可维护和可扩展的方式来处理数据转换需求,并帮助数据团队更高效地构建和管理数据管道。
dbt 是现代数据栈
(MDS)重要的组成部分。dbt被广泛视为DataOps实践方式的一部分,为数据团队提供了高效、可靠的数据转换和集成解决方案。
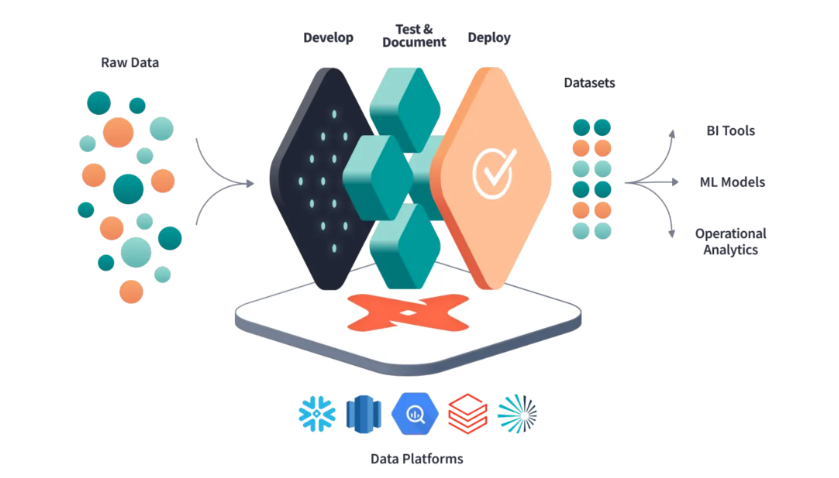
dbt 官方的架构图:
dbt 的特性
dbt建立在SQL之上,类似于传统数据库,但它使用CTE
(Common Table Expressions)和模板引擎(如Jinja
)构建了额外的功能。这使得您可以在SQL中引入更多的逻辑(如循环、函数等),以便访问、重组和组织数据。dbt的灵活性和选项使您可以像对数据集进行编程一样进行数据转换,从而更好地满足各种需求。dbt主要特征如下:
- 模块化开发,优化工作流的构造:使用.sql或.py文件编写模块化的数据转换代码 - dbt会处理繁琐的依赖管理任务。
- 不需要再写各类模板化的 DML(Data Manipulation Language) 和 DDL(Data Definition Language),只需要写 select 语句 / Python DataFrame 即可,dbt 会编译为具体的 DML/DDL 进行执行
- 搭建可重用/模块化的数据模型,不用每次数据分析都从原始数据开始
- 利用元数据找到运行时间长的模型,并通过增量模型极大降低查询的执行时间
- 编写符合 DRY(Don’t Repeat Yourself) 原则的代码,支持 macro, hooks 和 包管理
- 测试和文档化:在将每个模型投入生产之前进行测试,并与所有数据利益相关者共享动态生成的文档。
- 支持快速编写数据质量测试,提前处理好各 Edge Cases。
- 围绕描述、模型依赖关系、模型SQL、源代码和测试自动生成文档。这些文档展示了现有的模型、相关的数据库对象以及每个模型的详细信息。通过生成的依赖图,dbt使数据文档变得透明和可见。在其Web应用程序中,dbt呈现项目的文档,并提供有关项目(包括模型代码、项目DAG和应用于列的测试)以及数据仓库(列数据类型、表大小)的信息。
- 版本控制和持续集成/持续发布(CI/CD):通过在开发环境进行安全部署来实现版本控制和持续集成/持续交付,实现更稳定的分析构建。通过启用Git的版本控制,实现团队协作和回滚到先前的状态功能。
- 使用成熟的版本控制流程(git),支持 branch/pull request/code review
- 不再需要复制粘贴 SQL 语句,极大减少错误和逻辑变化。基于不同层级的数据模型逐步构造分析,上游改动自动传导
- 支持发布数据模型的主版本,封装所有复杂的业务逻辑,无需重新实现即可基于该模型二次开发
dbt并没有完全取代ETL和ELT,但它确实在转换层/阶段中提供了更大的灵活性。通过使用dbt,您可以自由地多次聚合、规范化和排序数据,而无需不断更新管道和重新执行。
dbt不是ETL和ELT的替代品,但随着现代技术的发展,传统的ETL和ELT方法变得越来越过时。不论您选择遵循ETL还是ELT,可以肯定的是,dbt在转换层(Transform)方面是一个巨大的改进。它提供了更多的灵活性和功能,让您能够更好地处理数据转换的需求。
dbt致力于解决ELT中的T(ransform)环节挑战。其核心思想在于将软件工程的核心概念应用于数据处理和分析领域,引入了模块化和可重用的开发方式,从而提升了数据转换的可靠性和可维护性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号