neo4j
neo4j
https://db-engines.com/en/ranking/graph+dbms
https://neo4j.com/docs/
https://www.cnblogs.com/yin-jihu/p/17983407
Cypher
https://zhuanlan.zhihu.com/p/88745411
Cypher查询语言
Cypher是Neo4J的声明式图形查询语言,允许用户不必编写图形结构的遍历代码,就可以对图形数据进行高效的查询。Cypher的设计目的类似SQL,适合于开发者以及在数据库上做点对点模式(ad-hoc)查询的专业操作人员。其具备的能力包括: - 创建、更新、删除节点和关系 - 通过模式匹配来查询和修改节点和关系 - 管理索引和约束等
Neo4J实战教程
直接讲解Cypher的语法会非常枯燥,本文通过一个实际的案例来一步一步教你使用Cypher来操作Neo4J。
这个案例的节点主要包括人物和城市两类,人物和人物之间有朋友、夫妻等关系,人物和城市之间有出生地的关系。
1. 首先,我们删除数据库中以往的图,确保一个空白的环境进行操作:
MATCH (n) DETACH DELETE n这里,MATCH是匹配操作,而小括号()代表一个节点node(可理解为括号类似一个圆形),括号里面的n为标识符。
2. 接着,我们创建一个人物节点:
CREATE (n:Person {name:'John'}) RETURN nCREATE是创建操作,Person是标签,代表节点的类型。花括号{}代表节点的属性,属性类似Python的字典。这条语句的含义就是创建一个标签为Person的节点,该节点具有一个name属性,属性值是John。
如图所示,在Neo4J的界面上可以看到创建成功的节点。

3. 我们继续来创建更多的人物节点,并分别命名:
CREATE (n:Person {name:'Sally'}) RETURN n
CREATE (n:Person {name:'Steve'}) RETURN n
CREATE (n:Person {name:'Mike'}) RETURN n
CREATE (n:Person {name:'Liz'}) RETURN n
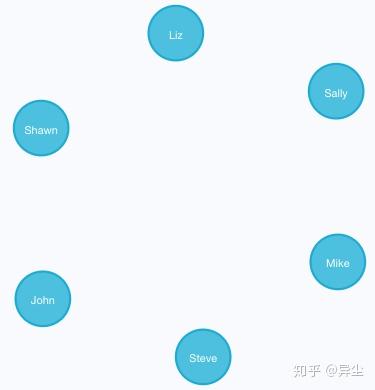
CREATE (n:Person {name:'Shawn'}) RETURN n如图所示,6个人物节点创建成功
4. 接下来创建地区节点
CREATE (n:Location {city:'Miami', state:'FL'})
CREATE (n:Location {city:'Boston', state:'MA'})
CREATE (n:Location {city:'Lynn', state:'MA'})
CREATE (n:Location {city:'Portland', state:'ME'})
CREATE (n:Location {city:'San Francisco', state:'CA'})可以看到,节点类型为Location,属性包括city和state。
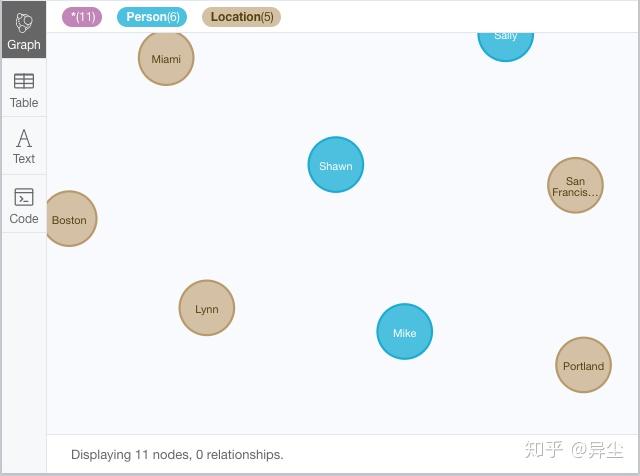
如图所示,共有6个人物节点、5个地区节点,Neo4J贴心地使用不用的颜色来表示不同类型的节点。
5. 接下来创建关系
MATCH (a:Person {name:'Liz'}),
(b:Person {name:'Mike'})
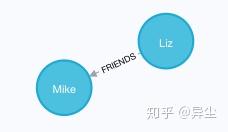
MERGE (a)-[:FRIENDS]->(b)这里的方括号[]即为关系,FRIENDS为关系的类型。注意这里的箭头-->是有方向的,表示是从a到b的关系。 如图,Liz和Mike之间建立了FRIENDS关系,通过Neo4J的可视化很明显的可以看出:
6. 关系也可以增加属性
MATCH (a:Person {name:'Shawn'}),
(b:Person {name:'Sally'})
MERGE (a)-[:FRIENDS {since:2001}]->(b)在关系中,同样的使用花括号{}来增加关系的属性,也是类似Python的字典,这里给FRIENDS关系增加了since属性,属性值为2001,表示他们建立朋友关系的时间。
7. 接下来增加更多的关系
MATCH (a:Person {name:'Shawn'}), (b:Person {name:'John'}) MERGE (a)-[:FRIENDS {since:2012}]->(b)
MATCH (a:Person {name:'Mike'}), (b:Person {name:'Shawn'}) MERGE (a)-[:FRIENDS {since:2006}]->(b)
MATCH (a:Person {name:'Sally'}), (b:Person {name:'Steve'}) MERGE (a)-[:FRIENDS {since:2006}]->(b)
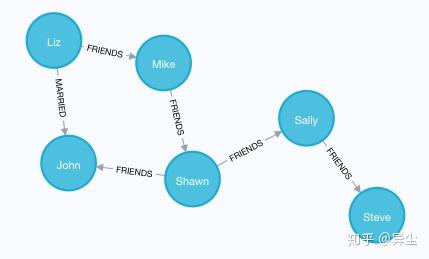
MATCH (a:Person {name:'Liz'}), (b:Person {name:'John'}) MERGE (a)-[:MARRIED {since:1998}]->(b)如图,人物关系图已建立好,有点图谱的意思了吧?
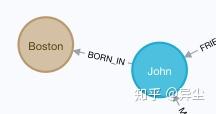
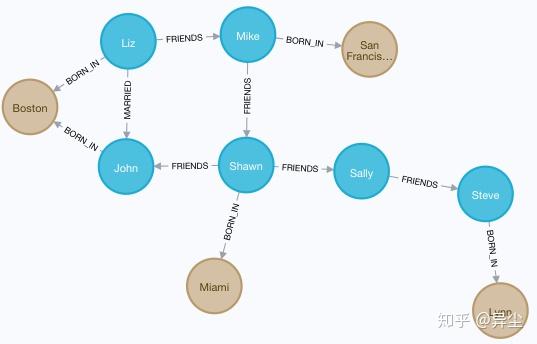
8. 然后,我们需要建立不同类型节点之间的关系-人物和地点的关系
MATCH (a:Person {name:'John'}), (b:Location {city:'Boston'}) MERGE (a)-[:BORN_IN {year:1978}]->(b)这里的关系是BORN_IN,表示出生地,同样有一个属性,表示出生年份。
如图,在人物节点和地区节点之间,人物出生地关系已建立好。
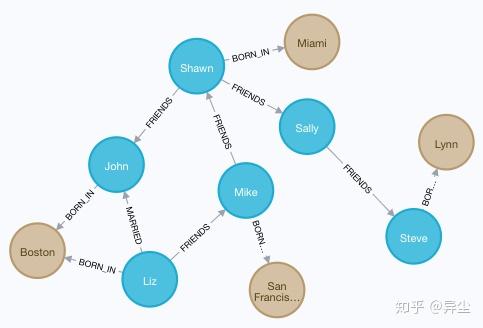
9. 同样建立更多人的出生地
MATCH (a:Person {name:'Liz'}), (b:Location {city:'Boston'}) MERGE (a)-[:BORN_IN {year:1981}]->(b)
MATCH (a:Person {name:'Mike'}), (b:Location {city:'San Francisco'}) MERGE (a)-[:BORN_IN {year:1960}]->(b)
MATCH (a:Person {name:'Shawn'}), (b:Location {city:'Miami'}) MERGE (a)-[:BORN_IN {year:1960}]->(b)
MATCH (a:Person {name:'Steve'}), (b:Location {city:'Lynn'}) MERGE (a)-[:BORN_IN {year:1970}]->(b)建好以后,整个图如下
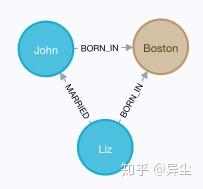
10. 至此,知识图谱的数据已经插入完毕,可以开始做查询了。我们查询下所有在Boston出生的人物
MATCH (a:Person)-[:BORN_IN]->(b:Location {city:'Boston'}) RETURN a,b结果如图
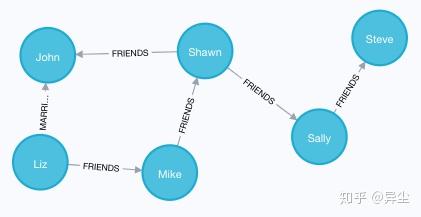
11. 查询所有对外有关系的节点
MATCH (a)-->() RETURN a注意这里箭头的方向,返回结果不含任何地区节点,因为地区并没有指向其他节点(只是被指向)
12. 查询所有有关系的节点
MATCH (a)--() RETURN a结果如图
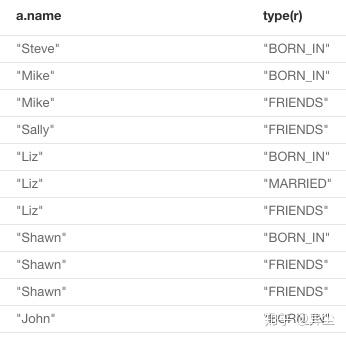
13. 查询所有对外有关系的节点,以及关系类型
MATCH (a)-[r]->() RETURN a.name, type(r)结果如图
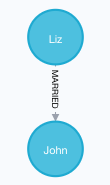
14. 查询所有有结婚关系的节点
MATCH (n)-[:MARRIED]-() RETURN n结果如图
15. 创建节点的时候就建好关系
CREATE (a:Person {name:'Todd'})-[r:FRIENDS]->(b:Person {name:'Carlos'})结果如图
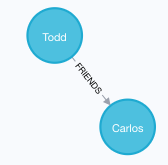
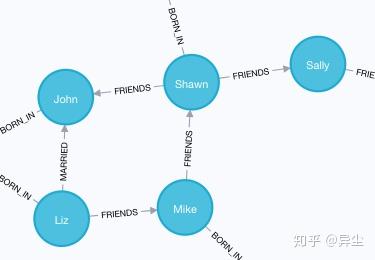
16. 查找某人的朋友的朋友
MATCH (a:Person {name:'Mike'})-[r1:FRIENDS]-()-[r2:FRIENDS]-(friend_of_a_friend) RETURN friend_of_a_friend.name AS fofName返回Mike的朋友的朋友:

从图上也可以看出,Mike的朋友是Shawn,Shawn的朋友是John和Sally
17. 增加/修改节点的属性
MATCH (a:Person {name:'Liz'}) SET a.age=34
MATCH (a:Person {name:'Shawn'}) SET a.age=32
MATCH (a:Person {name:'John'}) SET a.age=44
MATCH (a:Person {name:'Mike'}) SET a.age=25这里,SET表示修改操作
18. 删除节点的属性
MATCH (a:Person {name:'Mike'}) SET a.test='test'
MATCH (a:Person {name:'Mike'}) REMOVE a.test删除属性操作主要通过REMOVE
19. 删除节点
MATCH (a:Location {city:'Portland'}) DELETE a删除节点操作是DELETE
20. 删除有关系的节点
MATCH (a:Person {name:'Todd'})-[rel]-(b:Person) DELETE a,b,rel
数据迁移
https://zhuanlan.zhihu.com/p/397909985
Neo4j 提供了 neo4j-admin 来进行数据的导入导出,在迁移之前,需要停止 Neo4j 服务。
数据导入
# 下载其他已导出的 Neo4j 数据
wget https://labfile.oss.aliyuncs.com/courses/4043/graph.db.dump
# 停止 Neo4j 服务
sudo neo4j stop
# 导入到本地数据库中
sudo neo4j-admin load --from=graph.db.dump --database=graph.db --force
# 启动 Neo4j 服务
sudo neo4j start数据导出
# 停止 Neo4j 服务
sudo neo4j stop
# 导出数据到本地 /home/shiyanlou/Code 目录下
sudo neo4j-admin dump --database=graph.db --to=/home/shiyanlou/Code
# 启动 Neo4j 服务
sudo neo4j start
另外一种迁移方法:
如果neo4j数据是以volume形式存储, 那么可以从远端的容器内将数据文件打包压缩, 然后传送到本地, 然后将本地volume中灌入远端数据。
text2cypher
https://github.com/neo4j-labs/text2cypher
Repository for resources related to translating natural language into Cypher queries.
Includes datasets of natural language and corresponding Cypher query pairs, along with graph information for evaluation.
Contains notebooks that detail different methods for evaluating large language models (LLMs) on the datasets provided. Each notebook should provide a step-by-step guide on assessing model accuracy and performance in real-world scenarios.
Provides notebooks and scripts for finetuning LLMs using the datasets. These resources are intended to help improve model performance in natural language to Cypher translation.
neo4j-langgraph-text2cypher
https://github.com/fanqingsong/neo4j-langgraph-text2cypher

NebulaGraph
https://zhuanlan.zhihu.com/p/657195992
https://github.com/wey-gu/NebulaGraph-GPT

 浙公网安备 33010602011771号
浙公网安备 33010602011771号