Grounding LLMs
Grounding LLMs
https://techcommunity.microsoft.com/blog/fasttrackforazureblog/grounding-llms/3843857
What is Grounding?
Grounding is the process of using large language models (LLMs) with information that is use-case specific, relevant, and not available as part of the LLM's trained knowledge. It is crucial for ensuring the quality, accuracy, and relevance of the generated output. While LLMs come with a vast amount of knowledge already, this knowledge is limited and not tailored to specific use-cases. To obtain accurate and relevant output, we must provide LLMs with the necessary information. In other words, we need to "ground" the models in the context of our specific use-case.
Motivation for Grounding
The primary motivation for grounding is that LLMs are not databases, even if they possess a wealth of knowledge. They are designed to be used as general reasoning and text engines. LLMs have been trained on an extensive corpus of information, some of which has been retained, giving them a broad understanding of language, the world, reasoning, and text manipulation. However, we should use them as engines rather than stores of knowledge.
Despite their extensive knowledge, LLMs have limitations. Their knowledge is stale, as they are trained only up to a certain point in time (e.g., September 2021 for recent GPT models) and don't update continuously. Moreover, they only have access to public information and lack knowledge about anything behind corporate firewalls, private data, or use-case specific information. Consequently, we need a way to combine the general capabilities of LLMs with specific information relevant to our use-cases. Grounding provides a solution to this challenge, enabling us to leverage the power of LLMs while incorporating the necessary context and data.
Retrieval Augmented Generation (RAG) is the primary technique for grounding and the only one I will discuss in detail. RAG is a process for retrieving information relevant to a task, providing it to the language model along with a prompt, and relying on the model to use this specific information when responding. While sometimes used interchangeably with grounding, RAG is a distinct technique, albeit with some overlap. It is a powerful and easy-to-use method, applicable to many use-cases.
Fine-tuning, on the other hand, is an "honourable mention" when it comes to grounding. It involves orchestrating additional training steps to create a new version of the model that builds on the general training and infuses the model with task-relevant information. In the past, when we had less capable models, fine-tuning was more prevalent. However, it has become less relevant as time-consuming, expensive, and not offering a significant advantage in many scenarios.
The general consensus among experts in the field is that fine-tuning typically results in only a 1-2% improvement in accuracy (depending on how accuracy is defined). While there may be specific scenarios where fine-tuning offers more significant gains, it should be considered a last-resort option for optimisation, rather than the starting go-to technique. Often, customers approach us with the intention of embarking on a fine-tuning project, but we recommend they first explore the possibilities of RAG before resorting to fine-tuning.
Use-cases for Grounding / Retrieval-Augmented Generation (RAG)
Grounding, particularly with retrieval-augmented generation, has a wide range of applications. One obvious use case is search and question-answering (Q&A) systems. For instance, when you interact with Bing chat, it transparently retrieves search results and uses them to ground its responses. Similarly, many users are now building systems that leverage large language models (LLMs) to distil and make sense of information from their repositories, enabling Q&A over documents.
Another use case is generating content with information from an app or user interface. For example, Microsoft's Copilot, integrated with Visual Studio Code, uses an LLM to provide context-aware suggestions based on the document you are working on. This approach is also being implemented in Microsoft 365 and Power Platform, and developers are now being invited to create their own context-aware applications.
Retrieving information from APIs or external sources, such as the weather forecast or stock quotes, is another area where grounding can be beneficial. Additionally, grounding can be used for memory and state management in multi-step generation processes. Since LLMs are stateless, incorporating previous interactions or generated content can help produce more contextually relevant responses.
A Simple Retrieval-Augmented Generation Model
A basic retrieval-augmented generation model begins with a trigger, such as a user query or instruction. This trigger is sent to a retrieval function, which fetches relevant content based on the query. The retrieved content is then merged back into the context window of the LLM, along with the input prompt and the query itself. Care is taken to leave enough space for the model's response.
Finally, the LLM generates an output based on the combined input and retrieved content. This simple yet effective approach often yields impressive results, demonstrating the value of grounding in practical applications.
https://zhuanlan.zhihu.com/p/12089028946
理论基础
在认知科学中,GROUNDING 研究的是语言和实际世界之间的关系。Stevan Harnad
在其著名的 Symbol Grounding Problem
中指出,符号本身是抽象的,模型如果无法与具体世界进行连接,其所谓的理解仅仅是一种符号操纵。
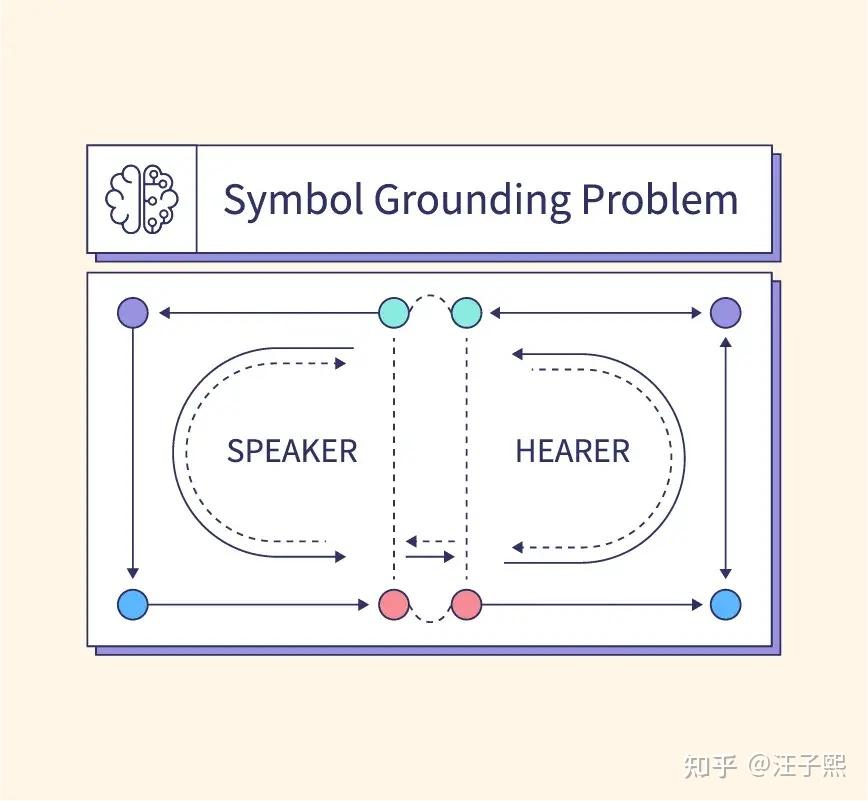
例如,在传统的符号系统中,模型可能只知道 "猫" 这个词汇的定义和语义规则,而不真正理解 "猫" 是一种具有特定视觉、听觉和行为特征的生物。GROUNDING 的目标就是弥补这种鸿沟。
在深度学习的语境中,GROUNDING 通常需要通过多模态数据(例如图像、文本和音频)来实现,使模型在学习词汇时,同时了解其在感知世界中的表现。
GROUNDING 的关键问题与挑战
- 符号到意义的映射:如何将抽象符号映射到具体的世界感知?这需要模型具备从数据中提取和关联概念的能力。
- 上下文依赖性:一个词语的意义往往依赖于上下文。例如,
"bank"在"river bank"和"savings bank"中含义完全不同。 - 模态对齐:在多模态学习中,如何对齐不同模态的信息,使得模型能从视觉、语言等多种输入中获得一致的理解?
- 时间和动态环境:现实世界是动态变化的,如何使模型在不断变化的环境中更新其 GROUNDING?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号