transformer->多模态
Transformer (language)
https://www.cnblogs.com/kongen/p/18088002
https://www.infoq.cn/article/qbloqm0rf*sv6v0jmulf
https://arxiv.org/pdf/2402.06196
https://arxiv.org/pdf/1706.03762
ViT(Vision Transformer)
https://zhuanlan.zhihu.com/p/703561123
ViT,全称Vision Transformer,是计算机视觉领域的新晋明星!它巧妙地将自然语言处理中的Transformer模型引入到图像识别任务中,让图像也能像文字一样被“翻译”和理解。简单来说,ViT把图像切割成一系列小块(patch),然后像处理单词一样处理这些图像块,通过自注意力机制捕捉它们之间的关系,从而实现图像分类等任务。ViT的出现,为计算机视觉领域带来了新的视角和思路,让图像识别更加高效和准确!🎉
Vision Transformer(ViT)[1] 技术由谷歌团队在 ICLR 2021 提出,类似于 BERT [2],ViT 是 Encoder-only 结构,并不是目前流行的 Decoder-only 结构。据此, ViT 主要用于提取图像特征,其思想简单有效且具有良好的扩展性,被视为 Transformer 在计算机视觉领域应用的重要里程碑之一。本篇博文对 ViT 的核心技术原理进行梳理和总结。
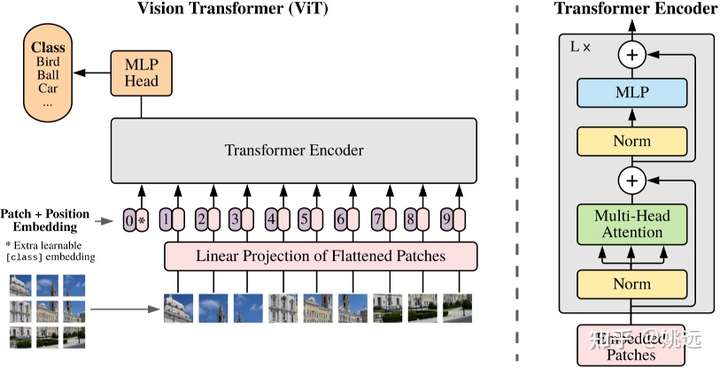
ViT 的架构如图 1 所示。具体而言,ViT 首先将输入图像划分为固定大小的图像块(Patch),这些图像块被拉平并通过线性变换映射为固定长度的向量。然后,这些向量序列
拼接到一个可学习的分类标记([CLS] token)后面,接着加上对应位置的可学习位置编码后,输入到 Transformer Encoder 中。最后,提取出 [CLS] token 对应的特征输入到分类器中进行学习。
图 1. ViT 网络的整体架构 [1]
MM-LLMs: Recent Advances in MultiModal Large Language Models
https://zhuanlan.zhihu.com/p/680487634
https://developer.volcengine.com/articles/7389112087835836466
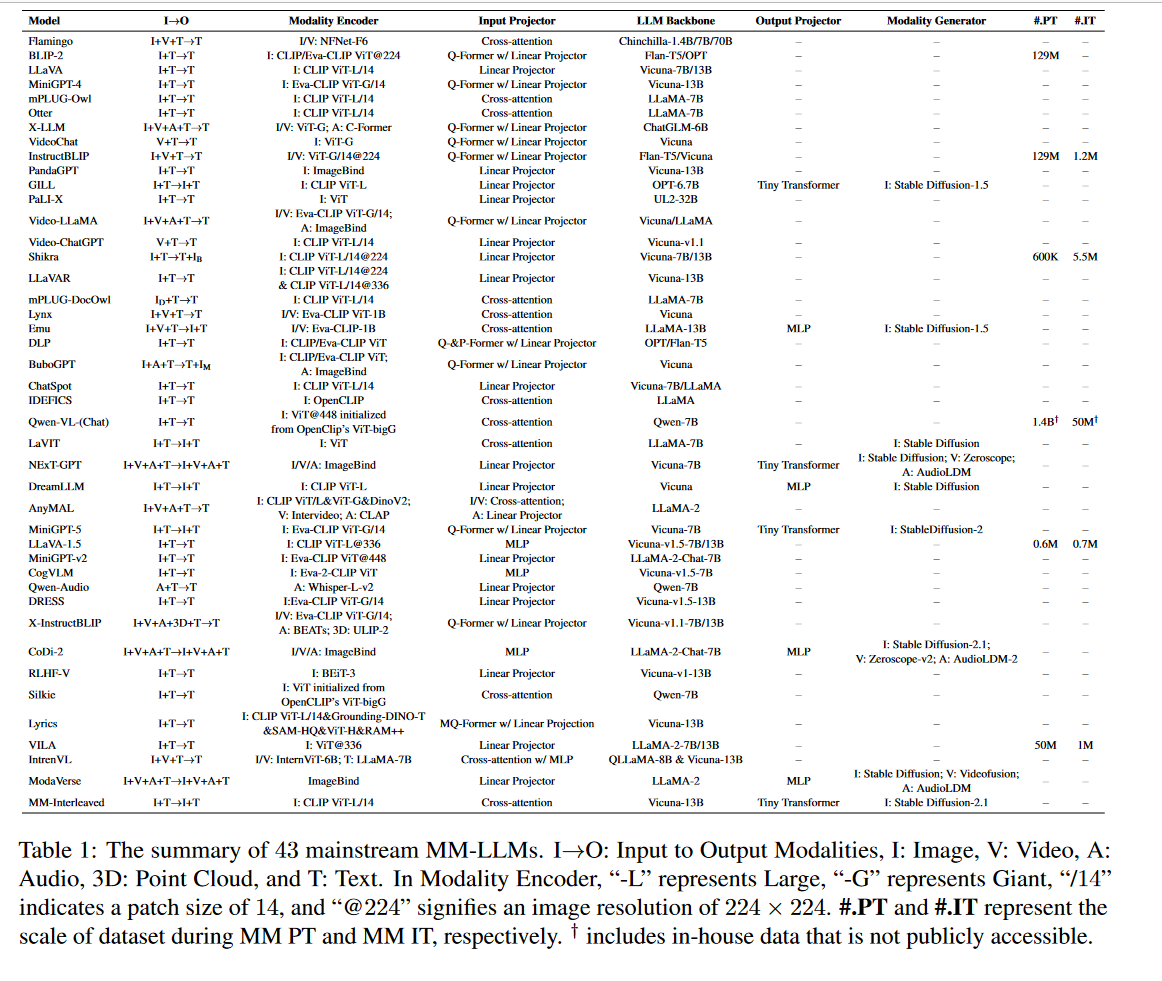
1、The (R)Evolution of Multimodal Large Language Models: A Survey
https://arxiv.org/abs/2402.12451
2、MM-LLMs: Recent Advances in MultiModal Large Language Models
https://arxiv.org/pdf/2401.13601.pdf
3、Large Language Models: A Survey
https://arxiv.org/pdf/2402.06196.pdf
MLLMs的发展路线
Flamingo 是第一个在视觉-语言领域探索上下文学习的模型。
MLLMs的发展路线经历了从单一模态到多模态融合的转变,以及从静态模型到动态、交互式系统的演进。
多模态大型语言模型(MLLMs)发展时间线( 2022.4-2024.2 )

多模态大模型(MLLMs)的分类
多模态大模型(MLLMs)的分类是基于它们的功能性和设计原则。以下是对这些分类的总结:
功能性分类:
理解(Understanding):这类MLLMs主要关注于理解和处理多模态输入,例如图像、视频、音频和文本。
生成(Generation):这类模型不仅理解输入,还能生成特定模态的输出,如图像、视频、音频或文本。
设计分类:
工具使用(Tool-using):这类模型将LLM视为黑盒,并提供对特定多模态专家系统的访问,通过推理来执行特定的多模态任务。
端到端(End-to-end):这类模型是整体联合训练的,意味着整个模型在训练过程中是一起优化的。
模态转换:
I+T→T:图像和文本输入,文本输出。
V+T→T:视频和文本输入,文本输出。
A+T→T:音频和文本输入,文本输出。
3D+T→T:3D点云和文本输入,文本输出。
I+V+A+T→T:图像、视频、音频和文本输入,文本输出。
特定功能:
文档理解(ID):处理文档内容的理解任务。
输出边界框(IB):在图像中识别并输出对象的边界框。
输出分割掩模(IM):生成图像中对象的分割掩模。
输出检索图像(IR):从数据库中检索与输入相关的图像。
122个MLLMs的分类体系 ,I:图像,V:视频,A/S:音频/语音,T:文本。ID:文档理解,IB:输出边界框,IM:输出分割掩模,IR:输出检索图像。
https://arxiv.org/pdf/2401.13601

MM-LLMs的模型架构
https://zhuanlan.zhihu.com/p/680487634
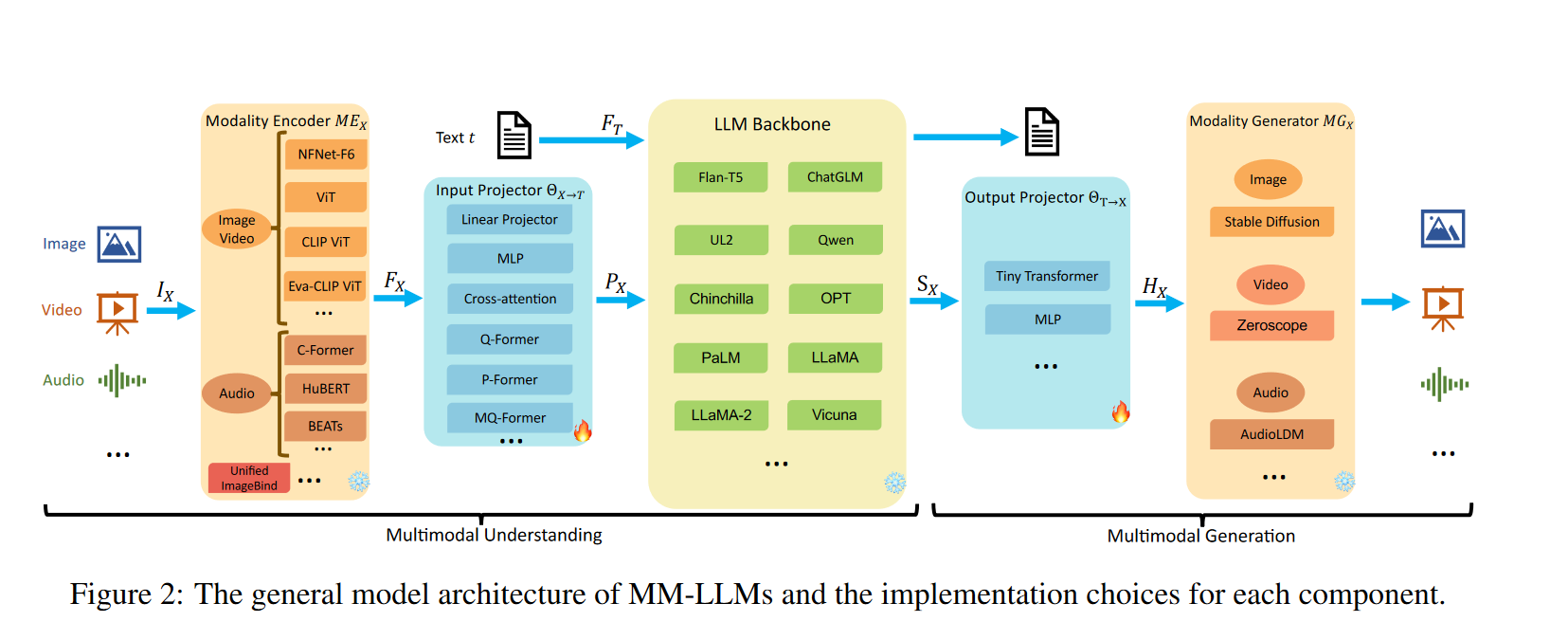
如图所示,MM-LLMs的模型架构包括以下5个组成部分:
(Modality Encoder): 负责对不同的模态输入IX进行编码,得到对应的特征FX。IX可以是图像、视频、音频、3D等不同类型的输入。常用的编码器包括:
- 图像编码器:NFNet-F6、ViT、CLIP ViT、Eva-CLIP ViT
- 视频编码器
- :ULIP-2、PointBERT
- 统一编码器:ImageBind,支持图像、视频、文本、音频、热图等多种模态
输入投影器(Input Projector): 负责将编码后的其他模态特征FX投影到文本特征空间T,得到对齐的特征PX。常用的实现方法有:
- 直接线性投影或多层感知机
- 交叉注意力:利用可训练的查询向量与编码特征FX进行压缩,得到固定长度的表示,并直接输入LLM或进行交叉注意力融合
- Q-Former:从FX中提取相关特征,作为提示PX
- P-Former:生成参考提示,对Q-Former生成的提示进行对齐约束
LLM骨干网络
(LLM Backbone): 利用预训练的大型语言模型作为核心,负责对齐后的特征进行语义理解、推理和决策,并输出文本输出t和来自其他模态的信号令牌SX。常用的LLM包括:
- Flan-T5
- ChatGLM
- UL2
- Qwen
- Chinchilla
- OPT
- PaLM
- LLaMA
- LLaMA-2
- Vicuna
输出投影器(Output Projector): 将LLM骨干网络中的信号令牌SX映射到特征HX,以使其可被后续的模态生成器MGX理解。通常采用Tiny Transformer或多层感知机来实现。
模态生成器(Modality Generator): 负责生成不同模态的输出,通常采用预训练的潜在扩散模型
(LDMs),将输出投影器映射的特征HX作为条件输入,以生成多模态内容。常用的LDMs包括:
- 图像合成:Stable Diffusion
- 视频合成:Zeroscope
- 音频合成:AudioLDM-2
这5个部分共同组成了MM-LLMs的模型架构,每个部分都有其特定的功能和实现选择。
https://arxiv.org/pdf/2401.13601
https://arxiv.org/pdf/2401.13601
MM-LLM的训练流程
https://zhuanlan.zhihu.com/p/680487634
MM-LLM的训练流程主要包括多模态预训练(MM PT)和多模态指令调优(MM IT)两个阶段。
多模态预训练(MM PT): 在预训练阶段,通常利用X-Text数据集来训练输入投影器和输出投影器,以实现不同模态之间的对齐。对于多模态理解模型,只需优化输入投影器的目标函数。对于多模态生成模型,则需要优化输入投影器、输出投影器和模态生成器的目标函数。X-Text数据集包括:
- 图像-文本数据集:图像-文本对、交错图像-文本语料
- 视频数据集:视频-文本对、交错视频-文本语料
- 音频数据集:音频-文本对、交错音频-文本语料
多模态指令调优
(MM IT): 在指令调优阶段,通常利用一组以指令格式组织的数据集对预训练的MM-LLMs进行微调。这个阶段包括监督式微调(SFT)和基于人类反馈的强化学习(RLHF),旨在更好地与人类意图保持一致,并增强模型的交互能力。SFT将部分预训练阶段的数据转换为指令感知格式,然后使用相同的优化目标对预训练模型进行微调。SFT数据集可以组织成单轮问答或多轮对话。在SFT之后,RLHF会进一步微调模型,利用自然语言反馈(NLF)对模型的响应进行反馈,从而训练模型根据NLF生成相应的响应。RLHF数据集通常包括人类标注或自动生成的NLF。
image + text 模块融合架构
https://arxiv.org/pdf/2402.12451
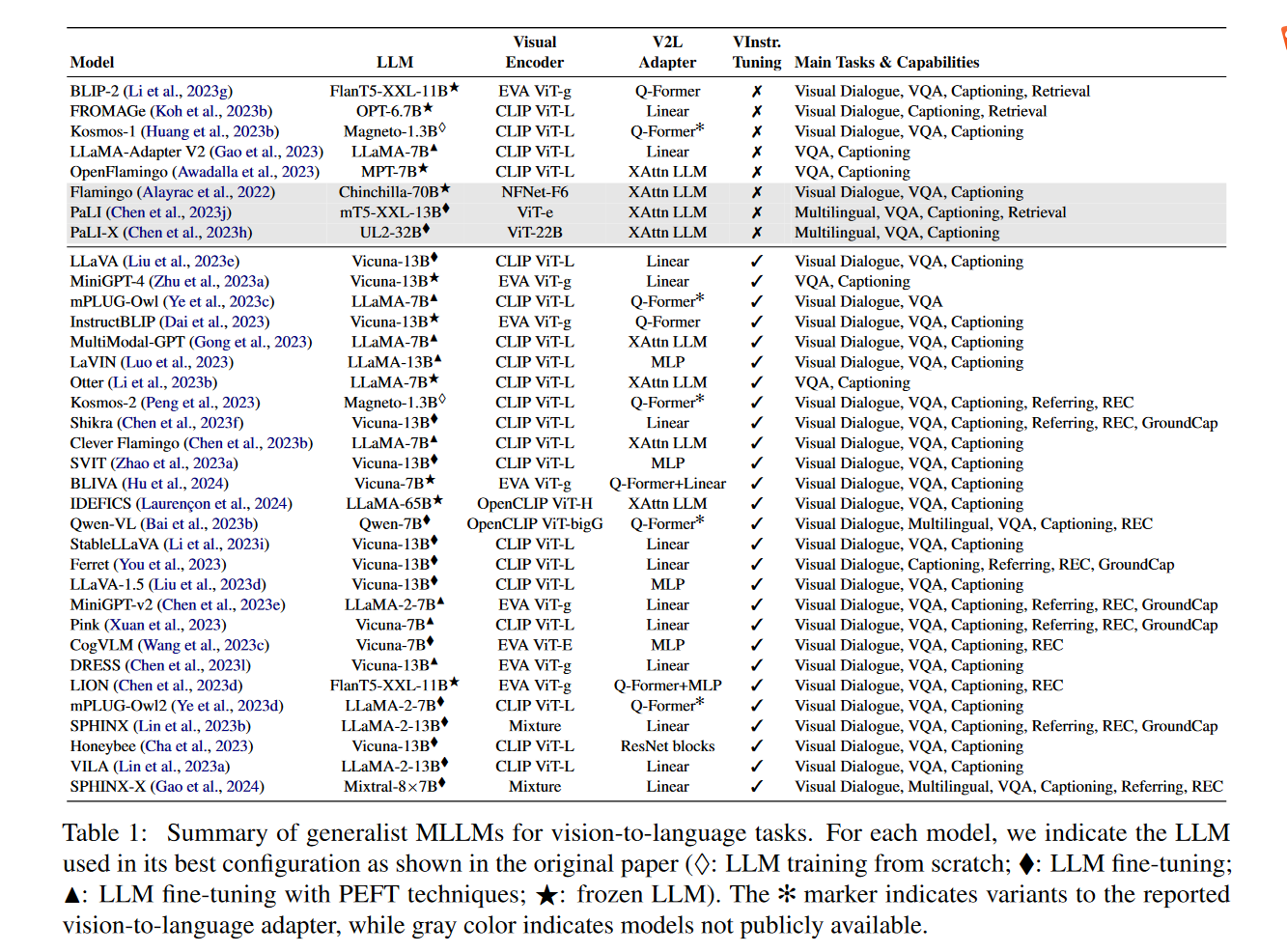
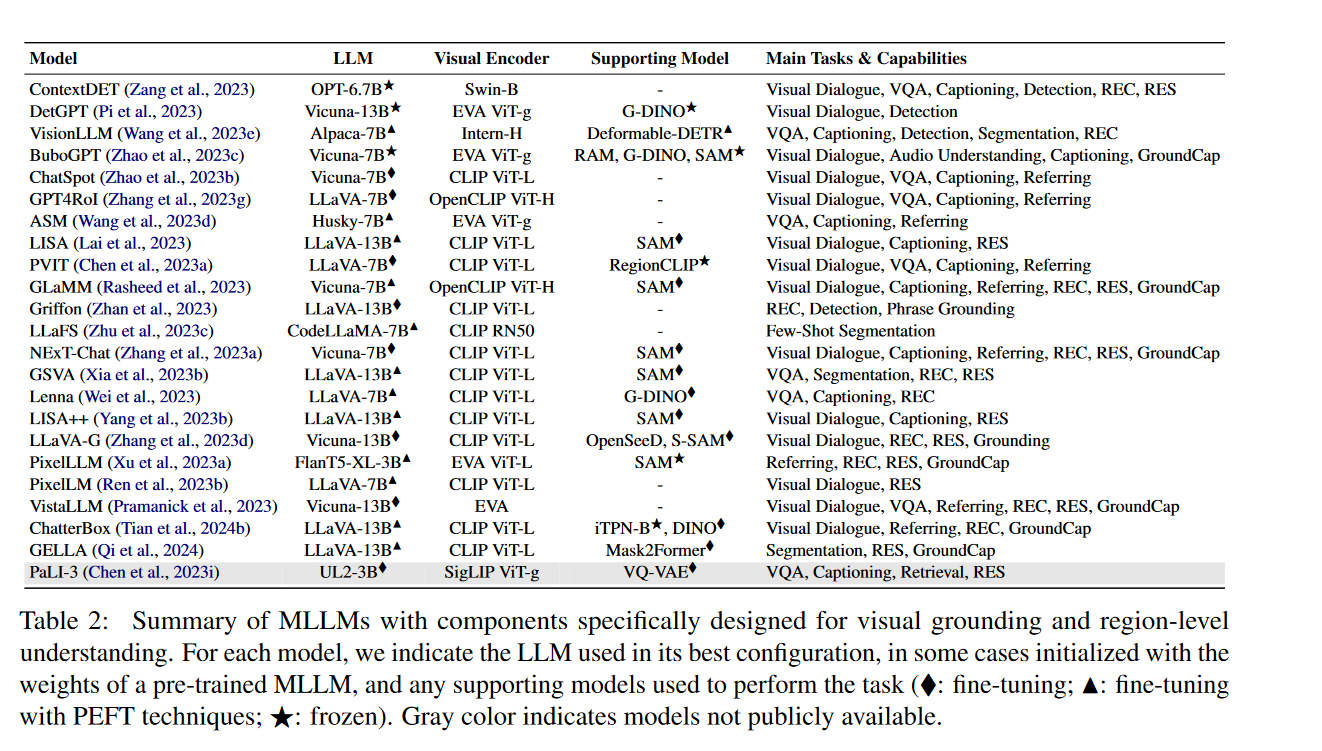
https://developer.volcengine.com/articles/7389112087835836466
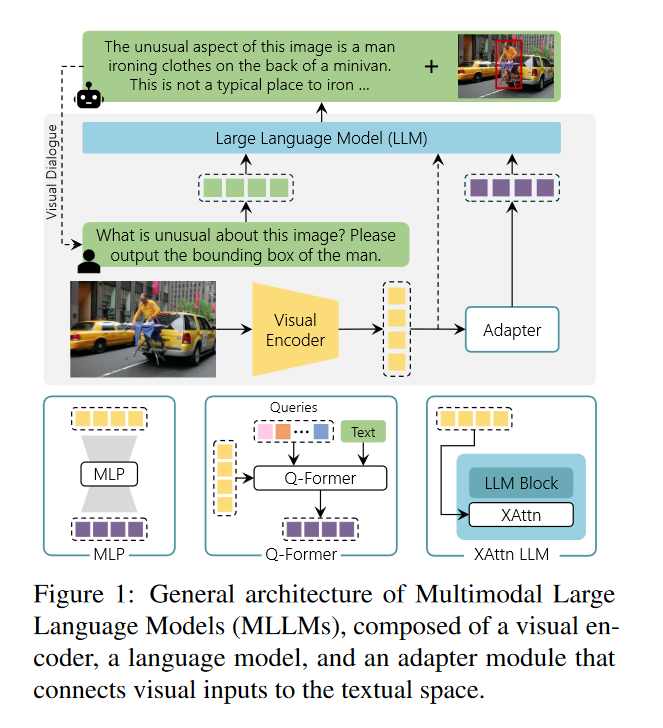
多模态大型语言模型(MLLMs)处理视觉理解任务,包括视觉问答(VQA)、图像生成和编辑等任务:
- 视觉基础(Visual Grounding):MLLMs的视觉基础能力指的是在对话中定位内容的能力,也称为指称性对话。这包括理解输入区域的内容(称为指称)和定位给定文本描述的区域(称为基础)。为了实现这些能力,MLLMs需要具备处理输入区域的序列到序列方法和序列到区域的方法。
- 图像生成和编辑:现代MLLMs不仅能够从视觉数据中提取信息,还能够生成视觉输出。这通常是通过将MLLM框架与图像生成机制(如Stable Diffusion模型)整合来实现的。这些模型通过交叉注意力层将文本或视觉嵌入条件化,生成图像。
- 其他模态和应用:除了处理图像,一些研究还提出了专门设计用于处理视频序列的MLLMs。这些模型独立处理视频帧,并使用基于CLIP的骨干网络提取帧级特征,然后通过池化机制或基于Q-Former的解决方案进行组合。此外,还有研究关注于设计能够处理多种模态的模型,这些模型通过Transformer块(如Q-Former和Perceiver)对齐多模态特征
CLIP (图像-文本关联紧密, 按照相似度进行学习),只能进行搜索,无法生成。
BLIP 实现生成功能。
https://www.bilibili.com/video/BV1t44y1c7pK/?vd_source=57e261300f39bf692de396b55bf8c41b
MiniGPT4-Video: Advancing Multimodal LLMs for Video Understanding with Interleaved Visual-Textual Token
https://vision-cair.github.io/MiniGPT4-video/
https://arxiv.org/pdf/2404.03413
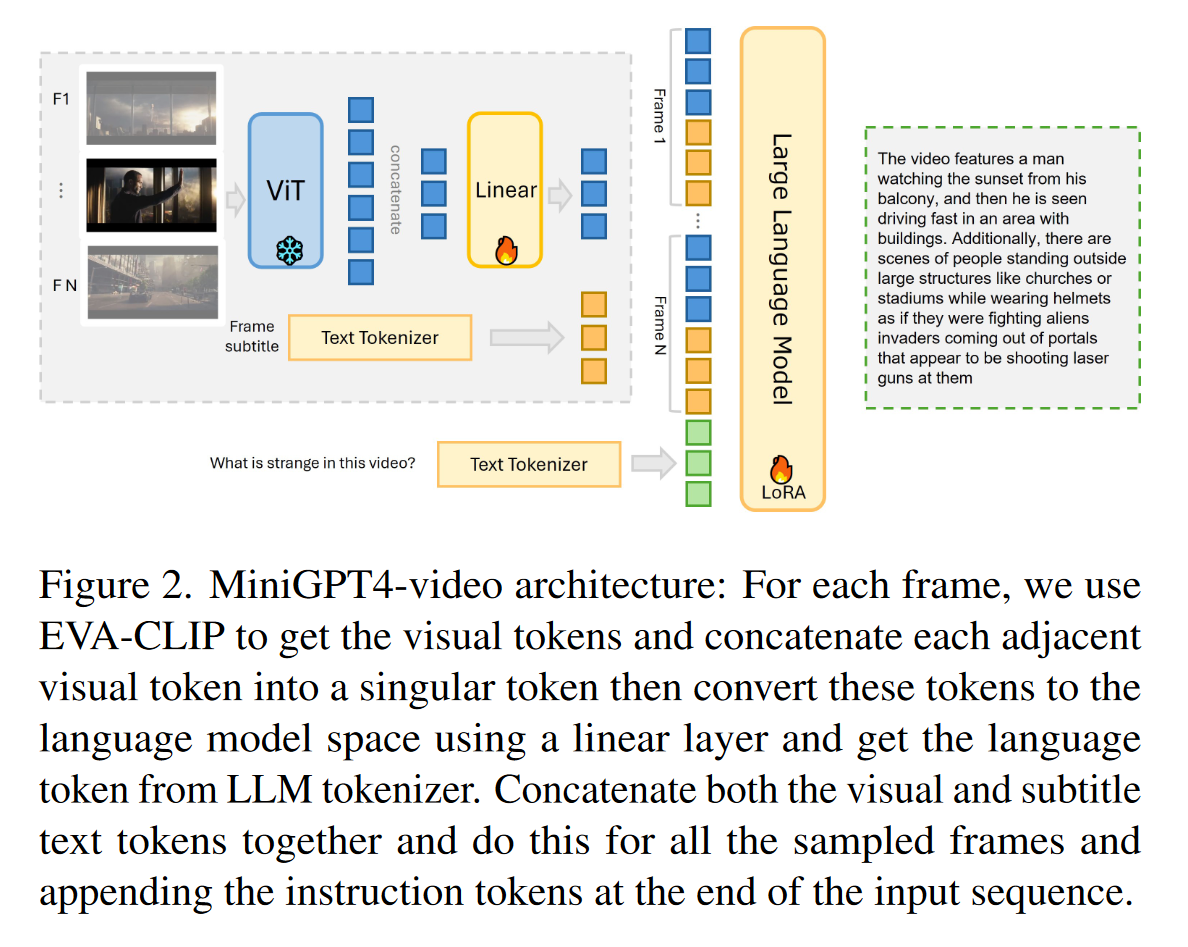

Video-LLaMA An Instruction-tuned Audio-Visual Language Model for Video Understanding
https://zhuanlan.zhihu.com/p/638603634
https://arxiv.org/pdf/2306.02858
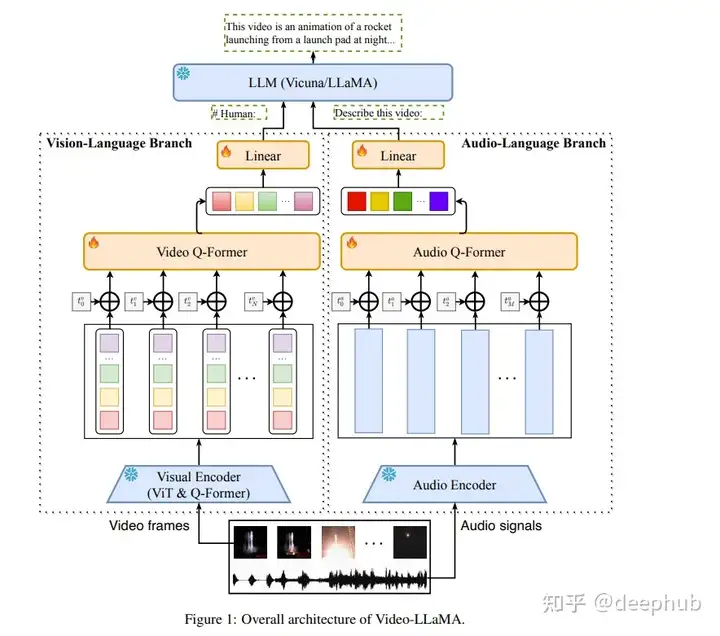
在数字时代,视频已经成为一种主要的内容形式。但是理解和解释视频内容是一项复杂的任务,不仅需要视觉和听觉信号的整合,还需要处理上下文的时间序列的能力。本文将重点介绍称为video - llama的多模态框架。Video-LLaMA旨在使LLM能够理解视频中的视觉和听觉内容。论文设计了两个分支,即视觉语言分支和音频语言分支,分别将视频帧和音频信号转换为与llm文本输入兼容的查询表示。
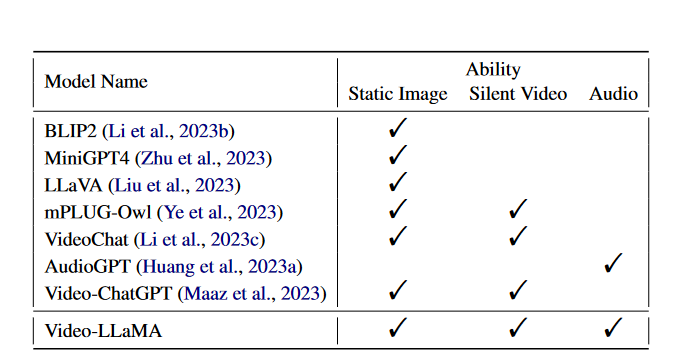
video - llama结合了视频中的视觉和听觉内容,可以提高语言模型对视频内容的理解。他们提出了一个视频Q-former来捕捉视觉场景的时间变化,一个音频Q-former
来整合视听信号。该模型在大量视频图像标题对和视觉指令调优数据集上进行训练,使视觉和音频编码器的输出与LLM的嵌入空间对齐。作者发现video - llama展示了感知和理解视频内容的能力,并根据视频中呈现的视觉和听觉信息产生有意义的反应。
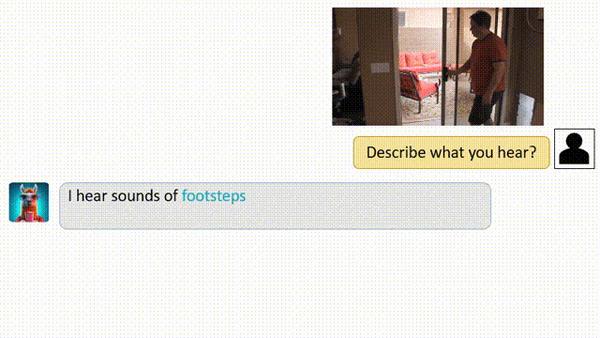
1、Video Q-former:一个动态的视觉解释器
Video Q-former是video - llama
框架的关键组件。它旨在捕捉视觉场景中的时间变化,提供对视频内容的动态理解。视频Q-former跟踪随时间的变化,以一种反映视频演变性质的方式解释视觉内容。这种动态解释为理解过程增加了一层深度,使模型能够以更细致入微的方式理解视频内容。
2、Audio Q-former:视听集成
Audio
Q-former是Video-LLaMa框架的另一个重要组件。它集成了视听信号,确保模型完整地理解视频内容。Audio
Q-former同时处理和解释视觉和听觉信息,增强对视频内容的整体理解。这种视听信号的无缝集成是Video-LLaMa框架的一个关键特征,它在其有效性中起着至关重要的作用。
模型是在视频图像标题对和视觉指令调优数据集的大量数据集上训练的。这个训练过程将视觉和音频编码器
的输出与语言模型的嵌入空间对齐。这种对齐确保了高水平的准确性和理解力,使模型能够根据视频中呈现的视觉和听觉信息生成有意义的响应。
影响和潜力
video - llama模型展示了一种令人印象深刻的感知和理解视频内容的能力。它基于视频中呈现的视觉和听觉信息。这种能力标志着视频理解领域的重大进步,为各个领域的应用开辟了新的可能性。

例如,在娱乐行业,Video-LLaMa可用于为视障观众生成准确的语音描述。在教育领域,它可以用来创建交互式学习材料。在安全领域,它可以用来分析监控录像,识别潜在的威胁或异常情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号