机器学习实战(二)决策树
转载请注明源出处:http://www.cnblogs.com/lighten/p/7603601.html
1.原理
回顾上章所说的kNN算法,其利用输入样本和训练样本的特征点差异,来选择k个最小差异的标记样本,这k个样本大部分处于哪个分类就认定输入的样本是哪个分类的。为了处理各个特征取值范围不同对差异的影响,采取了数值归一化的处理方法。从以上步骤可以看出,kNN默认所有特征是同等重要的,输入样本最终是由所有特征共同决定的,但是实际上呢?事物虽然有许多的特征,但是通常是由几个重要特征来判断其分类的,也就是说特征对于分类是有不同影响力的,有的对分类起到了较为关键性作用。以上就是本章所要说的决策树的一个引导内容。
决策树的原理也比较简单,其将特征按照中要程度进行排序,一个输入样本先通过重要的特征进行选择,该输入样本该特征接下来进入了哪个判断条件,进入下一个选择的特征,直到找到其最终分类。这就好像猜谜游戏,提问者提出猜一个人名,猜测者通过不断的提问:国内还是国外,近代还是古代,男还是女,不断的进行选择,最终缩小到具体的人名。由于提问次数有限,所以肯定需要将最能缩小范围的问题放在最前面,这个就是决策树的一般思路。
那么问题来了,对于一个事物而言,其有N个特征,如何判断哪个特征比较重要呢?换个说法就是如何构建决策树。这牵扯到一个重要的理论——信息论。
1.1 信息熵
二十世纪克劳德·香农创建了信息论,这是一个非常重要的理论,近代社会经历了蒸汽革命,电力革命以及信息革命,信息论可以说是信息革命根基。在二十世纪描述信息一向被认为是很困难甚至是不可能的事情,到现在要一个普通人定义信息估计也会说的是似而非,无法概括信息究竟是个什么。香农的一个伟大贡献就是其确定了描述信息的数学方法,顺便一提,计算机数据存储的基本单位比特也是由香农定义并命名的,如果没有信息论,可以说近代计算机发明是很困难的事情。
回归正题。信息论中提出了一个很重要的概念——熵。熵的含义是体系的混乱程度,体系越混乱,熵的值越大。放在信息论中,信息熵的含义就变成了信息量的大小。以本文介绍的分类问题为例,从分类角度描述狗这个事物的信息量,狗被划分的品种越多,那么狗的信息肯定更加丰富,信息熵越大,即狗的分类体系越复杂,分类越多。下面香农给出的公式可以说明上面所说的内容。
定义一个体系中的某一个事物(分类体系中的一种类别)其信息为:
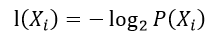
P(Xi)就是该类别出现的概率。整个体系的信息熵计算方法如下:

简单理解一下就知道,分类越多,每个分类的概率就越小,l(Xi)的值就会越大,H肯定就更大,所以分类越多,信息熵越大。上面公式和数学中所学的期望很像,期望的计算也是可能性的出现概率*可能性的值累加起来,所以信息熵也被看成是信息的期望。
1.2 信息增益
通过上面的内容可以理解信息熵的基本概念,但是信息熵对于特征的重要程度有什么关系呢?其实这里面还有一个概念就是信息增益。信息熵越大,所能说明的就是情况越复杂,换句话就是说信息熵越小,情况越简单,如果一个特征的值已知,计算这种情况下的新的信息熵,信息增益=最初的信息熵-新的信息熵,信息增益越大的,则该特征越重要。
如何理解这个概念呢?其实很简单,已知了一个特征,其计算出来的信息熵越小,信息增益的值就会越大,信息熵越小代表情况更简单,即通过该特征的值更容易使分类情况简单,这不就意味着该特征对于一个事物的分类起到的作用更大吗。所以通过信息增益的大小可以衡量特征的重要程度。
具体计算过程就是:选择一个特征,得出其在训练样本中所有可能的解,按找不同的解划分子集,例如特征X的值有0,1,样本被划分成子集X=1和子集X=2,分别计算这两个子集的信息熵,再乘以子集占全部集合的比例,最后得到的就是新的信息熵。其实也就是一种期望,该特征特定解的出现概率*该特征特定解的子集(不包含该特征)的信息熵,该特征所有解之和就是新数据集的信息熵。
2.决策树具体实现方法
原理中只说明了如何进行选择具有决定性的特征,那么具体如何构建决策树呢?方法很简单,选择最有决定性的特征,其有若干解,构建若干解的子集的决策树,这样递归下去,直到所有的答案指向同一个分类,或者是最后一个特征了,挑选大部分训练集所选择的分类。文字说明比较难懂,看下面的伪逻辑:
loop(dataSet):
if dataSet 所有分类都是同一个,返回该分类
if dataSet 没有可以进行选择的条件了,返回该结果集大部分指向的分类
通过信息增益指标,选择当前dataSet最有决定性的特征
for 该特征的值:
该值所得出的子集subDataSet
tree = loop(subDataSet) 构建该特征的该值的子树
return tree
整个过程就是一个不断分叉的过程,选择当前具有决定性的特征,通过其值构建子树,构建子树的方法就是使用子训练集再通过构建树的方法进行构建,构建的终点就是要不全是一个分类,要不不能再分叉了就选择最终大部分所在的结果。
3.问题及优缺点
优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据
缺点:可能会产生过度匹配问题。
由上面的内容也可以看出,决策树一旦构建成功,可以很快的计算出输入内容的结果,根据特征的值不断的选择。缺点可以通过裁剪决策树来处理,较为流行的决策有ID3,C4.5,CART。
4.代码
下面代码出自《机器学习实战》一书,原书中所有代码例子可以在网站:这里。进行下载。
# 计算当前数据集的信息熵
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet: #the the number of unique elements and their occurance
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2) #log base 2
return shannonEnt
# 得到满足指定特征axis的指定value的子集
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis] #chop out axis used for splitting
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
# 根据信息增益获取最佳特征
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #the last column is used for the labels
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures): #iterate over all the features
featList = [example[i] for example in dataSet]#create a list of all the examples of this feature
uniqueVals = set(featList) #get a set of unique values
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy #calculate the info gain; ie reduction in entropy
if (infoGain > bestInfoGain): #compare this to the best gain so far
bestInfoGain = infoGain #if better than current best, set to best
bestFeature = i
return bestFeature #returns an integer
# 计算最终不可分时大部分所指向的分类
def majorityCnt(classList):
classCount={}
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
# 构建决策树
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]#stop splitting when all of the classes are equal
if len(dataSet[0]) == 1: #stop splitting when there are no more features in dataSet
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:] #copy all of labels, so trees don't mess up existing labels
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
return myTree

 浙公网安备 33010602011771号
浙公网安备 33010602011771号