目录
描述统计学的数值方法
位置的度量
平均数
样本平均数:
\[\bar{x} = \frac{\sum x_i}{n}
\]
总体平均数:
\[\mu = \frac{\sum x_i}{N}
\]
加权平均数:
\[\bar{x} = \frac {\sum w_ix_i}{\sum w_i}
\]
几何平均数:
\[\bar{x} = \sqrt[n]{x_1x_2...x_n}
\]
中位数
将数据按照从小到大排列:
对于偶数个观测值,中位数为中间两数的平均值。
对于奇数个观测值,中位数为中间数。
众数
出现最多的数据,可能不止一个。
百分位数
至少有\(p\%\)的数据小于等于该值,至少有\(1-p\%\)的数据大于等于该值。
将数据按照从小到大的顺序排列,并计算\(n \times p\%\):
若为整数,则取该值与下一位数的平均数。 即\(\frac {2n \times p\%+1}2\)
若不为整数,则向上取整。
中位数、四分位数等是特殊的百分位数。
变异程度的度量
极差与四分位数间距
极差:最大值与最小值之差
\[max(x_i) - min(x_i)
\]
四分位数间距(Interquantile Range,IQR):四分位数之差
\[IQR = Q_3 - Q_1
\]
极差与四分位数间距都是变异程度的简单度量,相比较而言,极差更容易受异常值影响,因此多采用四分位数间距。
方差与标准差
方差是对数据总体变异程度的度量。
总体方差:
\[\sigma^2 = \frac{\sum (x_i - \mu)^2}{N}
\]
样本方差:
\[s^2 = \frac{\sum(x_i - \bar x)^2}{n-1}
\]
其中样本方差为无偏方差。
无偏性:统计量的估计值的均值等于该统计量。
\[E(\hat\theta) = \theta
\]
证明:
其中\(\mu\)为总体均值,\(\sigma\)为总体标准差
\[\begin{split} E(s^2) & = \frac 1{n-1}\sum E(x_i-\bar x)^2 & =\frac 1{n-1}\sum (Ex_i^2+E(\bar x)^2-2Ex_i\bar x) \end{split}
\]
对于随机变量\(X\)
\[\begin{split} DX & = E(X-EX)^2 \\ & = E[ X^2 -2XEX + (EX)^2 ] \\& = EX^2 - (EX)^2 \end{split}
\]
故有
\[EX^2 = \mu^2 + \sigma^2
\]
同理,由于
\[E\bar X = \mu
\]
\[D\bar X = \frac {\sigma^2}{n}
\]
故
\[E\bar X^2 = \mu^2 + \frac {\sigma^2}{n}
\]
又有
\[\begin{split} EX_i\bar X & = \frac 1n EX_i(X_i+\sum_{j \neq i} X_j) \\ & = \frac 1n(EX_i^2+EX_i\sum_{j\neq i} EX_j)\\&=\mu^2 + \frac 1n \sigma^2 \end{split}
\]
故
\[E(s^2) = \frac 1{n-1} \sum (\mu^2 + \sigma^2 + \mu^2 + \frac {\sigma^2}{n} - 2\mu^2 - \frac {2\sigma^2}n) = \sigma^2
\]
标准差(s):方差的算术平方根。
标准差系数(变异系数):标准差除以平均数。$$\frac s{\bar x}$$ 实际上是标准差的归一化,由于标准差大小受到随机变量值的大小影响,因此,不同随机变量变异程度对比时,可用标准差系数。
分布形态、相对位置度量以及异常值检测
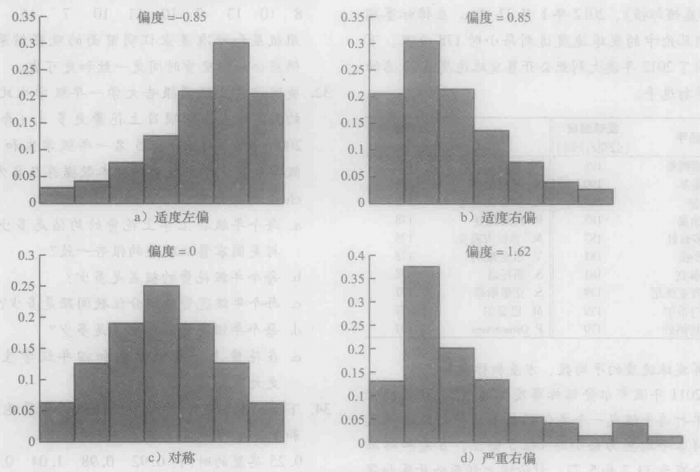
分布形态的度量——偏度
偏度:若随机变量的三阶矩存在,则偏度定义如下:
\[skew(X)= \frac {E(X-\mu)^3} {\sigma^3}
\]
当偏度大于0时,称为右偏,偏度小于零称为左偏。
![image]()
切比雪夫定理
切比雪夫定理:对于任意分布,与均值距离\(z\)个标准差的之内的数据所占的比例至少为\(1-\frac1{z^2}\),其中\(z>0\)
切比雪夫定理来源于切比雪夫不等式:
\[P(|x-\mu|\geq\epsilon)\leq\frac{\sigma^2}{\epsilon^2}
\]
或
\[P(|x - \mu|\leq\epsilon)\geq1 - \frac{\sigma^2}{\epsilon^2}
\]
针对连续变量的切比雪夫不等式证明:
要证
\[P(|x - \mu|\geq\epsilon)\leq\frac {\sigma^2}{\epsilon^2}
\]
只需
\[\epsilon^2\int_{|x - \mu|\geq\epsilon}f(x)dx\leq\sigma^2
\]
即
\[\int_{|x - \mu|\geq\epsilon}\epsilon^2f(x)dx\leq\int(x-\mu)^2f(x)dx
\]
由于
\[\int_{|x - \mu|\geq\epsilon}(x - \mu)^2f(x)dx\leq\int(x - \mu)^2f(x)dx
\]
且
\[|x - \mu|\geq\epsilon \Rightarrow (x - \mu)^2\geq\epsilon^2 \Rightarrow \int_{|x - \mu|\geq\epsilon}\epsilon^2f(x)dx\leq\int_{|x - \mu|\geq\epsilon}(x - \mu)^2f(x)dx
\]
故原命题得证。
异常值检测
异常值检测有两种简单的方法:
1)z-score法
\[z = \frac{x-\mu}{\sigma}
\]
由于日常数据大多近似服从正态分布,由标准正态分布表可知,数据位于\(z=\pm3\)之内的的概率为99.87%,因此,对于z位于该区间之外的数据认为是异常值。
2)四分位数间距法
\[上限 = Q1 - 1.5IQR
\]
\[下限 = Q3 + 1.5IQR
\]
五数概括法和箱线图
五数概括法
用最大值最小值中位数以及上下四分位数五个数字对数据进行概括的方法。
箱线图
import os
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
os.chdir('G:\精通特征工程\数据文件\第2章')
df = pd.read_excel('Restaurant.xlsx')
df.head()
|
Restaurant |
Quality Rating |
Meal Price ($) |
| 0 |
1 |
Good |
18 |
| 1 |
2 |
Very Good |
22 |
| 2 |
3 |
Good |
28 |
| 3 |
4 |
Excellent |
38 |
| 4 |
5 |
Very Good |
33 |
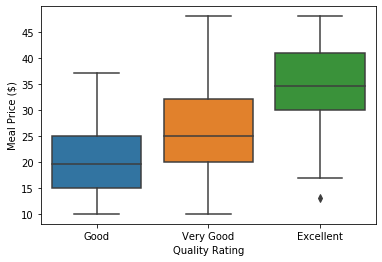
以上数据为某城市100家餐厅的代表餐品价格以及餐厅的质量评级,下面使用箱线图描述不同等级的餐厅价格分布。其中:
-
箱内线:中位数。
-
箱子上边界:第三四分位数\(Q_3\)
-
箱子下边界:第一四分位数\(Q_1\)
-
上边界线:\(min\{max(X),Q_3+1.5IQR\}\)
-
下边界线:\(max\{min(X),Q_1-1.5IQR\}\)
-
上下边界外的点:异常值。
sns.boxplot('Quality Rating','Meal Price ($)',data=df,whis=1.5)
plt.show()
![image]()
两变量之间关系的度量
协方差
协方差是两随机变量线性相关性的度量,协方差绝对值越大,两随机变量相关性越强,协方差为正数表明两随机变量正相关,协方差为负表明两随机变量负相关。对于一组容量为N的数据,其观测值为\((X_1,Y_1),(X_2,Y_2)...(X_N,Y_N)\),其协方差定义如下:
总体协方差:$$Cov(X,Y) = E(X-EX)(Y-EY) = \frac{\sum(X_i-EX)(Y_i-EY)}{N}$$
类似的,样本协方差为:$$s_{xy} = \frac{\sum(x_i-\bar x)(y_i-\bar y)}{n-1}$$
样本协方差为总体协方差的无偏估计量,其证明如下:
\[\begin{split}E(s_{xy}) &= \frac 1{n-1}\sum E(x_iy_i-x_i\bar y -\bar xy_i+\bar x \bar y)\\&=\frac1{n-1}\sum[E(x_iy_i)-E(x_i\frac{y_i+\sum_{j\neq i}y_j}n)-E(y_i\frac{x_i+\sum_{j\neq i}x_j}n)+E(\frac{\sum_{i,j=1}^{n}x_iy_j}{n^2}]\\&=\frac1{n-1}\sum [EXY -\frac 2nEXY - \frac {2(n-1)}n EXEY +\frac {nEXY+n(n-1)EXEY}{n^2}]\\&=EXY-EXEY\\&=Cov(X,Y)\end {split}
\]
相关系数
协方差的问题在于受数据大小影响,例如,将所有数据扩大5倍,则线性相关性不变但是协方差绝对值增大,为避免这种现象,我们采用相关系数描述相关性。
总体相关系数:
\[\rho_{X,Y}=\frac {Cov(X,Y)}{\sigma _X\sigma _Y}=\frac{\sum(X_i-\mu_X)(Y_i-\mu_Y)}{\sqrt{\sum(X_i-\mu_X)^2\sum(Y_i-\mu_Y)^2}}
\]
样本相关系数:
\[r{xy} = \frac {s_{xy}}{s_xs_y}=\frac{\sum(x_i-\bar x)(y_i-\bar y)}{\sqrt{\sum(x_i-\bar x)^2\sum(y_i-\bar y)^2}}
\]
- 样本相关系数不是总体相关系数的无偏估计。
- 相关系数取值范围为[-1,1],其绝对值越接近1线性相关性越强。
相关系数取值范围的证明:
由柯西-施瓦茨不等式
\[(\sum a_ib_i)^2\leq\sum a_i^2\sum b_i^2
\]
易证明相关系数取值范围为[-1,1]
柯西-施瓦茨不等式简单证明:
够造一个恒不为负的二次函数
\[f(x)=(\sum a_ix+\sum b_i)^2=(\sum a_i)^2x^2+2\sum a_i\sum b_ix+(\sum b_i)^2
\]
由于其恒为非负,故有判别式小于等于0,即:
\[4(\sum a_i\sum b_i)^2-4(\sum a_i)^2(\sum b_i)^2\leq0
\]
原命题得证。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号