
scrapy 用法
1、 创建scrapy项目:在终端Terminal运行命令:scrapy startproject 【项目名称】
scrapy startproject lfj_pro
PS D:\pythonProject8_scrapy> scrapy startproject lfj_pro New Scrapy project 'lfj_pro', using template directory 'C:\Users\Administrator\AppData\Local\Programs\Python\Python311\Lib\site-packages\scrapy\templates\project', created in: D:\pythonProject8_scrapy\lfj_pro You can start your first spider with: cd lfj_pro scrapy genspider example example.com PS D:\pythonProject8_scrapy>


2、 切换目录,创建爬虫程序
切换目录:cd 【项目目录】
创建爬虫程序: scrapy genspider 【爬虫程序名字】【域名/起始爬虫地址】
PS D:\pythonProject8_scrapy> cd lfj_pro PS D:\pythonProject8_scrapy\lfj_pro> scrapy genspider lfj_baidu https://www.baidu.com Created spider 'lfj_baidu' using template 'basic' in module: lfj_pro.spiders.lfj_baidu
创建的py文件

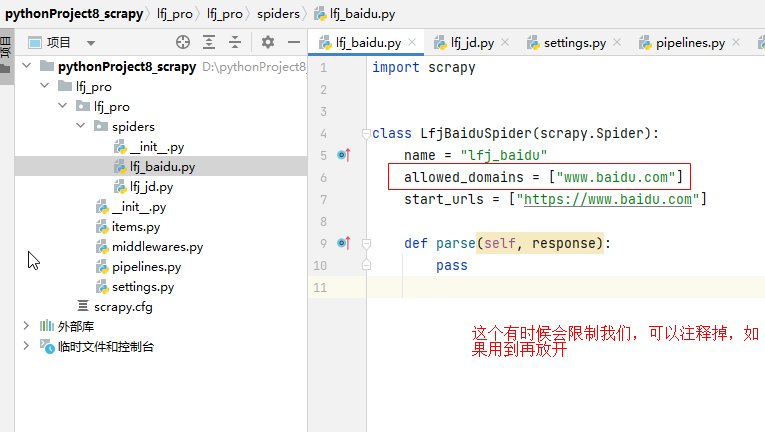

PS D:\pythonProject8_scrapy\lfj_pro> scrapy genspider lfj_jd https://jd.com Created spider 'lfj_jd' using template 'basic' in module: lfj_pro.spiders.lfj_jd

3、 运行脚本:scrapy crawl 【脚本名字】,记得先把settings.py里的【ROBOTSTXT_OBEY】的值改为【False】
scrapy crawl lfj_baidu
这里有个需要注意的问题,直接运行爬虫程序会显示Forbidden,这是因为robots(网站跟爬虫间的协议)
2023-09-11 11:48:54 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://baidu.com/robots.txt> (referer: None) 2023-09-11 11:48:54 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET http://baidu.com>
robots是一个君子协议,我们就不遵守了
将【项目名字】\【项目名字】\settings.py里的【ROBOTSTXT_OBEY】的值改为【False】
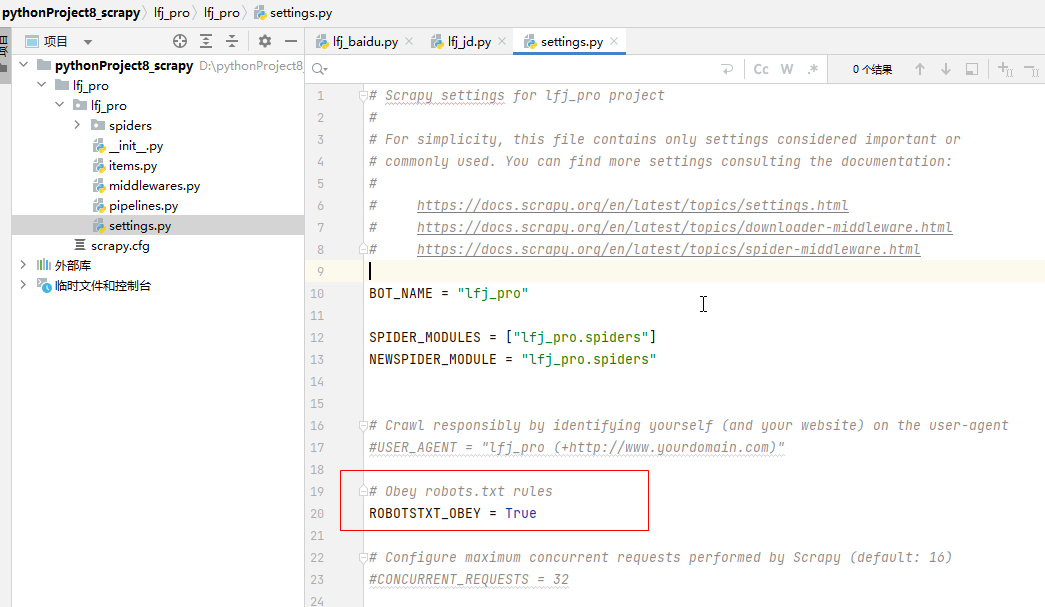
4、 编写逻辑代码,比如获取百度首页,写入文件

但是得到的不太对,那这里应该是遇到了反爬


 浙公网安备 33010602011771号
浙公网安备 33010602011771号