3.Spark设计与运行原理,基本操作
1.Spark已打造出结构一体化、功能多样化的大数据生态系统,请用图文阐述Spark生态系统的组成及各组件的功能。
目前,Spark已经发展成为包含众多子项目的大数据计算平台。BDAS是伯克利大学提出的基于Spark的数据分析栈(BDAS)。其核心框架是Spark,同时涵盖支持结构化数据SQL查询与分析的查询引擎Spark SQL,提供机器学习功能的系统MLBase及底层的分布式机器学习库MLlib,并行图计算框架GraphX,流计算框架SparkStreaming,近似查询引擎BlinkDB,内存分布式文件系统Tachyon,资源管理框架Mesos等子项目。这些子项目在Spark上层提供了更高层、更丰富的计算范式。
图1-1展现了BDAS的主要项目结构图。
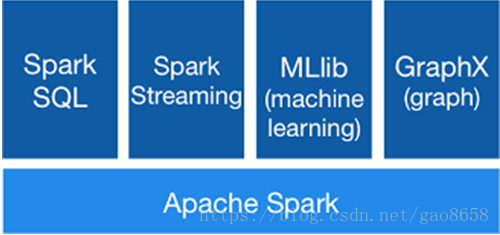
图1-1伯克利数据分析栈(BDAS)主要项目结构图
下面对BDAS的各个子项目进行更详细的介绍。
(1)Spark
Spark是整个BDAS核心组件,是一个大数据分布式编程框架,不仅实现了MapReduce的算子map 函数和reduce函数及计算模型,还提供更为丰富的算子,例如filter、join、groupByKey等。Spark将分布式数据抽象为RDD(弹性分布式数据集),并实现了应用任务调度、RPC、序列化和压缩,并为运行在其上层组件提供API。其底层采用Scala这种函数式语言书写而成,并且所提供的API深度借鉴Scala函数式的编程思想,提供与Scala类似的编程接口。
图1-2所示即为Spark的处理流程(主要对象为RDD):
Stage:阶段
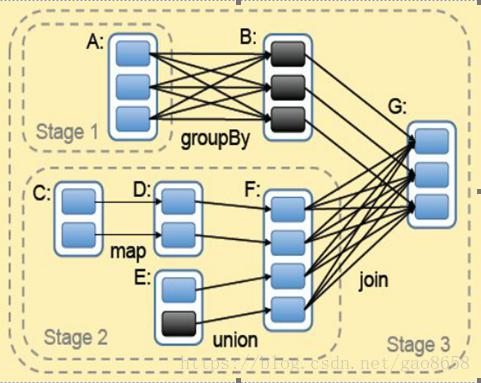
图1-2 Spark的任务处理流程图
Spark将数据在分布式环境下分区,然后将作业转化为有向无环图(DAG),并分阶段进行DAG的调度和任务的分布式并行处理。
(2)Spark SQL
SparkSQL提供在大数据上的SQL查询功能,类似于Shark在整个生态系统的角色,它们可以统称为SQL on Spark。之前,由于Shark的查询编译和优化器依赖Hive,使得Shark不得不维护一套Hive分支。而Spark SQL使用Catalyst做查询解析和优化器,并在底层使用Spark作为执行引擎实现SQL 的Operator。用户可以在Spark上直接书写SQL,相当于为Spark扩充了一套SQL算子,这无疑更加丰富了Spark的算子和功能。同时Spark SQL不断兼容不同的持久化存储(例如:HDFS、Hive等),为其发展奠定广阔的空间。
(3)SparkStreaming
SparkStreaming通过将流数据按指定时间片累积为RDD,然后将每个RDD进行批处理,进而实现大规模的流数据处理。其吞吐量能够超越现有主流流处理框架Storm,并提供丰富的API用于流数据计算。
(4)GraphX
GraphX基于BSP模型,在Spark之上封装类似Pregel的接口,进行大规模同步全局的图计算,尤其是当用户进行多轮迭代的时候,基于Spark内存计算的优势尤为明显。
(5)MLlib
MLlib是Spark之上的分布式机器学习算法库,同时包括相关的测试和数据生成器。MLlib 支持常见的机器学习问题:分类,回归,聚类以及协同过滤,同时也包括一个底层的梯度下降优化基础算法。
2.请详细阐述Spark的几个主要概念及相互关系:
RDD,DAG,Application, job,stage,task,Master, worker, driver,executor,Claster Manager
一 SparkContext
1 Spark程序的灵魂 ,用来创建最开始的RDD ;
2 在创建SparkContext 过程中 ,创建了 RpcEndPoint / DAGScheduler / TaskScheduler / ShuffleManager / BlockManager等 ,这些统称为 Driver ;
3 一个 SparkContext 就对应一个 Driver ;
4 一个 Application 中只能有一个SparkContext .
二 RDD
1 什么是RDD
RDD 的全称是 Resilient Distributed Dataset ,是一个弹性的 ,可复原(可容错)的分布式数据集 .
是 Spark 中最基本的抽象数据集,是一个不可变的 / 有多个分区的 / 可以并行计算的集合 . RDD 中并不装真正要计算的数据 ,而装的是描述信息 ,描述以后从哪里读取数据 ,调用了什么方法 ,传入了什么函数 ,以及依赖关系等 .
可以认为是一个代理 ,你对RDD进行操作 ,相当于在Driver端先是记录下计算的描述信息 ,然后生成Task ,将Task 调度到 Executor端才执行真正的计算逻辑 .
2 RDD(有弹性/可复原/分布式的数据集) 的特点
1 有一些列连续的分区 : 分区编号从0开始,分区的数量决定了对应阶段Task的并行度
1) 如果是从 hdfs 中读取数据,分区的数量由hdfs中数据的输入切片数量决定
2) sc.textFile可以指定rdd的分区数量, 最小的分区数量为 2(如果不指定的话默认也是2)
3) 如果一个大文件,一个小文件, 大文件大小/(全部文件相加大小/最小分区数) > 1.1 倍 ,大文件会有指定的分区数输入切片
4) 当分区的数量大于切片的数量 ,多个Task可以读取一个输入切片;当分区的数量小于切片的数量,RDD分区的数量由切片数量决定
2 有一个函数作用在每个输入切片(分区)上 :每一个分区都会生成一个Task ,对该分区的数据进行计算 ,这个函数就是具体的计算逻辑
3 RDD 和 RDD 之间存在一些列依赖关系 : RDD 调用 Transformation 后会生成一个新的 RDD ,子RDD 会记录父 RDD 的依赖关系,包括宽依赖(有 shuffle) 和窄依赖(没有 shuffle), 可以根据依赖关系恢复失败的任务和划分Stage
4 (可选的) K-V 的 RDD在 Shuffle 会有分区器 ,默认使用HashPartition ,分区器决定数据到下游哪个分区
5 (可选的) 如果从HDFS 中读取数据 ,会有一个最优位置,即将Executor中的Task调度到数据所在的节点上,要求Worker 和 DateNode部署在同一个节点或 Yarn 上 ,通过访问NameNode 获取数据块位置信息(spark 在调度任务之前会读取 NameNode的元数据信息 ,获取数据的位置 ,移动计算而不是移动数据 ,这样可以提高计算效率 ) .
3 RDD算子的分类
1) Transformation : 即转换算子 ,调用转换算子会生成一个新的RDD ,Transformation 是 Lazy 的,不会触发 job 执行 .
2) Action : 行动算子 ,调用行动算子会触发job执行 ,本质上是调用了 sc.runJob 方法 ,该方法从最后一个RDD,根据其依赖关系 ,从后往前 ,划分 Stage ,生成 TaskSet .
4 创建RDD的方法和查看RDD数量的方法
1 通过并行化方式 ,将Driver端的集合转为RDD (可以指定分区数量,默认是2个分区)
1.1 将Driver端的scala集合并行化成RDD,RDD中并没有真正要计算的数据,只是记录以后从集合中的哪些位置获取数据
val rdd1:RDD[Int] = sc.parallelize(Array(1,2,3,4,5,6))
val rdd1:RDD[Int] = sc.parallelize(Array(1,2,3,4,5,6) ,2)
2 从HDFS指定的目录创建RDD (可以指定分区数量)
2.1 指定以后从哪里读取创建RDD,可以是多种文件系统,需要指定文件系统的协议,如hdfs://,flile://,s3://等
val lines:RDD[String] = sc.textFile("hdfs://linux04:8020/wc")
val lines:RDD[String] = sc.textFile("hdfs://linux04:8020/wc" , 3)
3 查看RDD数量的方法
val rdd1:RDD[Int] = sc.parallelize(Array(1,2,3,4,5,6))
rdd1.partitions.length
5 RDD的数量分析
1) 读取 hdfs 中的目录有两个输入切片 ,最原始的 HadoopRDD的分区为2 ,以后没有改变RDD的分区数量的话 ,RDD的分区都是2 (Task 的数量取决于 Stage 中最后一个RDD分区的数量) .
2) 在调用 reduceByKey 方法时 ,有shuffle 产生, 要划分 Stage ,所以有两个 Stage ,Stage-0(ShuffleMapStage) 是前面的Stage ,在任务执行时先执行 ,Stage-1(ResultStage) 是后面的 ,等前面的任务执行完毕后才执行后面的 ;一个 Stage 对应一个 TaskSet ,一个TaskSet 中有一到多个Task ,但是 Task 的数量取决于 Stage 中最后一个RDD分区的数量 .
3) 第一个 Stage 的并行度为2 ,所以有 2 个Task ,并且为 ShuffleMapTask .第二个 Stage 的并行度也为 2 ,所以也有 2个 Task ,并且为 ResultTask ,所以一共有 4 个 Task .
总结 : 以上有两个输入切片 ,即有两个分区 (之后分区数一直没有改变),一个完整的 DAG ,一个 Job , 两个Stage(因为有一次shuffle产生) , 两个 TaskSet(一个stage对应一个taskset) , 四个Task (每个TaskSet 各有两个Task) , 两个输出文件 .
三 Application
1 使用 SparkSubmit 提交的一个计算应用 ;
2 一个Application 中可以触发多次 Action ,触发一次 Action 产生一个 Job ;
3 一个Application 中可以有一到多个 Job .
四 DAG
1 DAG 是指有向无环图(有方向 ,无闭环) ;
2 是对多个RDD转换过程和依赖关系的描述 ;
3 触发 Action 就会形成一个完整的 DAG ,一个DAG 对应一个 Job .
五 Job
1 Driver 端向 Executor 提交的作业 ,触发一次 Action 形成一个完整的 DAG ;
2 一个DAG 对应一个 Job ;
3 一个Job 中有一到多个Stage ,一个Stage 对应一个TaskSet ,一个TaskSet 中有一到多个 Task .
六 Stage
1 Stage 是指任务执行阶段 ;
2 Stage 执行是有先后顺序的 ,先执行前面的 ,再执行后面的 ;
3 一个Stage 对应一个TaskSet ,一个TaskSet 中的 Task 的数量取决于Stage 中最后一个RDD 分区的数量 .
七 TaskSet
1 是指保存同一种计算逻辑的多个Task 的集合 ;
2 一个TaskSet 中的Task 计算逻辑都一样 ,当时计算的数据不一样 (计算的数据来自不同的输入切片) .
八 Task
1 是Spark中任务最小的执行单位 ,Task 分类两种 ,即 ShuffleMapTask 和 ResultTask .
ShuffleMapTask :
1) 可以读取各种数据源的数据
2) 也可以读取shuffle后的数据
3) 专门为shuffle做准备
ResultTask :
1) 可以读取各种数据源的数据
2) 也可以读取shuffle后的数据
3) 专门为了产生计算结果
2 Task 其实就是类的实例 ,有属性(从哪里读取数据/读取的是哪个切片的数据) ,有方法(如何计算 / 即数据的计算分析逻辑) ;
3 Task 的数量取决于Stage 中最后一个RDD分区的数量 ,Task 的数量决定并行度(分区数) ,同时也要考虑Spark 中可用的 cores .
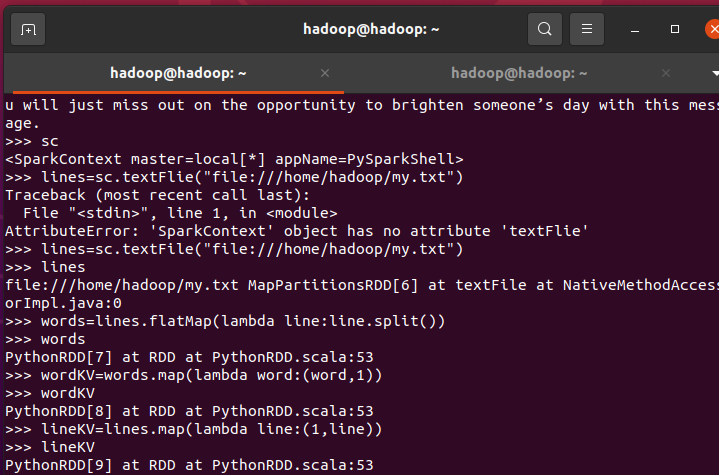
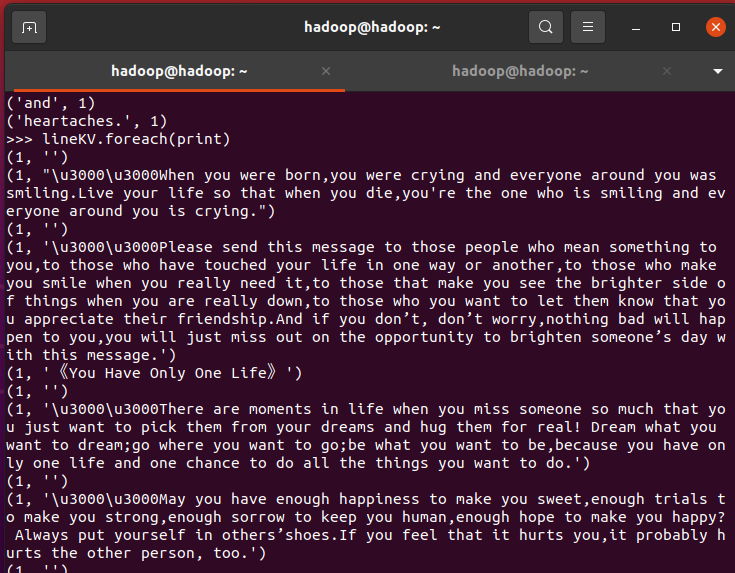
3.在PySparkShell尝试以下代码,观察执行结果,理解sc,RDD,DAG。请画出相应的RDD转换关系图。
>>> sc
>>> lines = sc.textFile("file:///home/hadoop/my.txt")
>>> lines
>>> words=lines.flatMap(lambda line:line.split())
>>> words
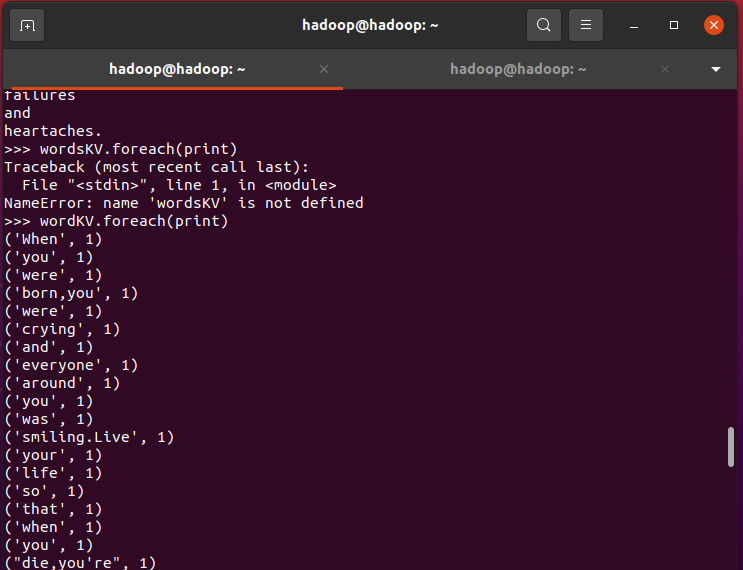
>>> wordKV=words.map(lambda word:(word,1))
>>> wordKV
>>> lineKV=lines.map(lambda line:(1,line))
>>> lineKV
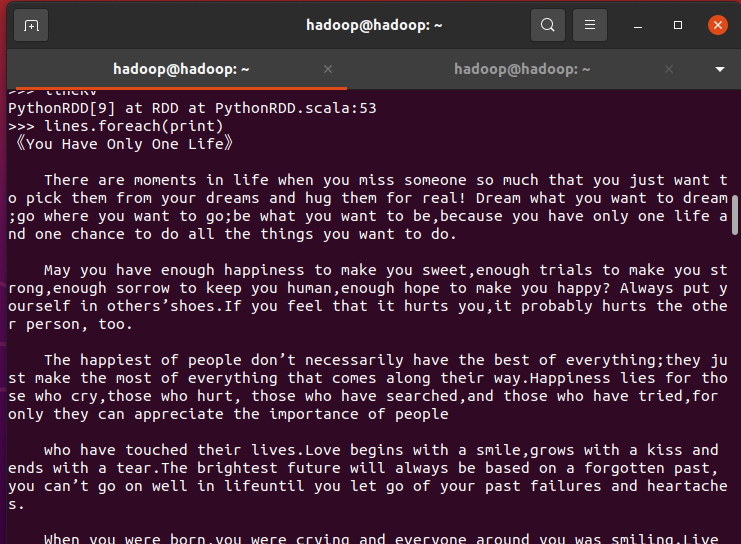
>>> lines.foreach(print)
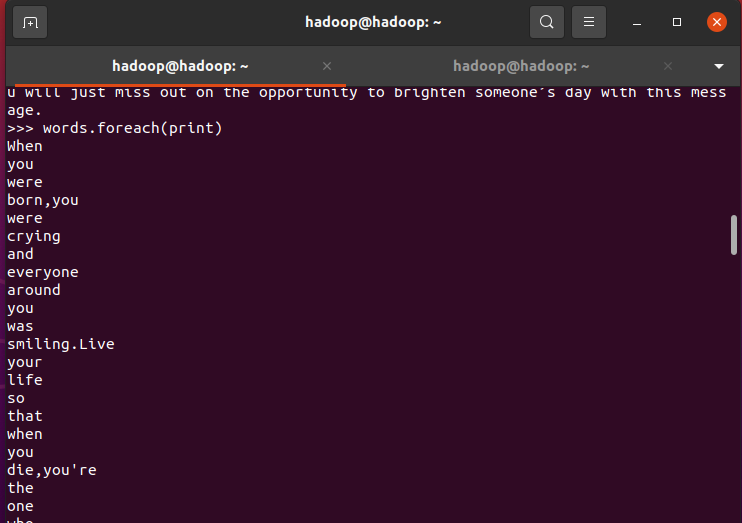
>>> words.foreach(print)
>>>wordKV.foreach(print)
>>>lineKV.foreach(print)
自己生成sc
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My App")
sc=SparkContext(conf=conf)