2.安装Spark与Python练习
1.环境测试
spark版本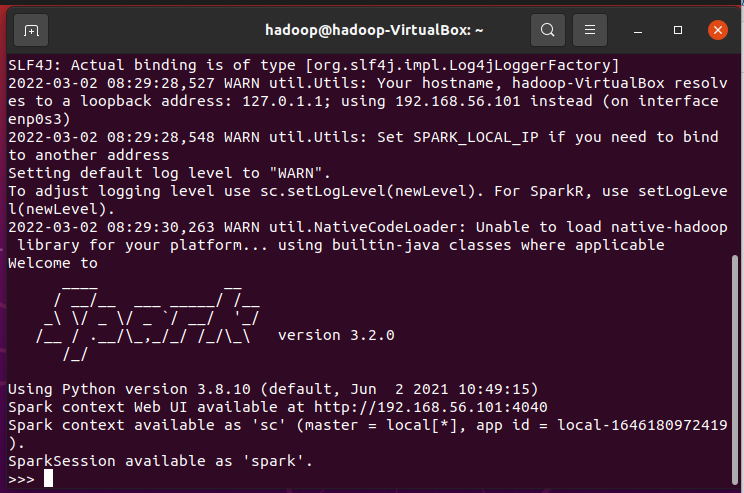
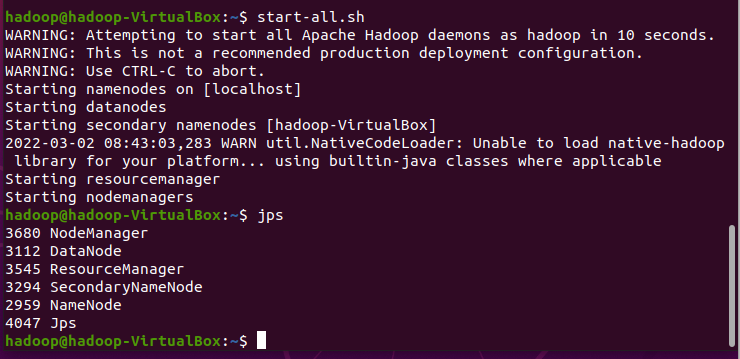
Python环境
2.在pyspark中测试代码
测试代码:print('打印一个spark')
输出: 打印一个spark
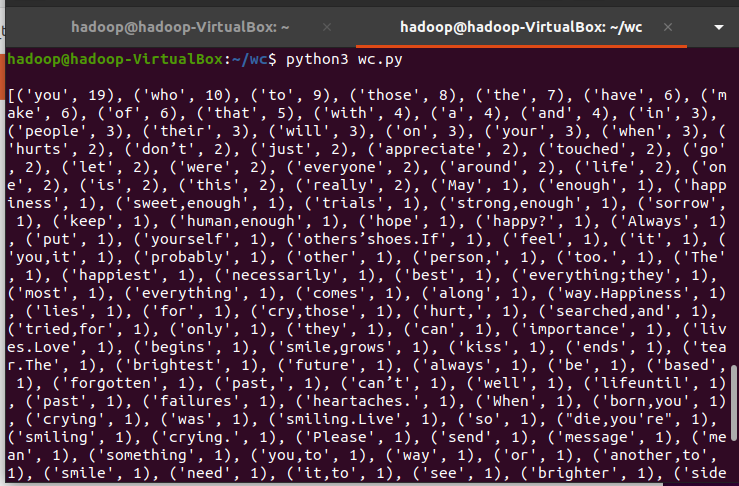
词频统计:
查看代码
import os
import re
path='/home/hadoop/wc/spark_test.txt'
with open(path) as f:
for line in f:
line = re.sub(u"[0-9\s+.!/,$%^*()?;;:-【】+\"\']+|[+——!,;:。?、~@#¥%……&*()><-]+", "", line)
print(line)
text=f.read()
words = text.split()
wc={}
for word in words:
wc[word]=wc.get(word,0)+1
wclist=list(wc.items())
wclist.sort(key=lambda x:x[1],reverse=True)
print(wclist)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号