课堂直播视频-爬虫-3
上回说到,我就差一个参数就可以获取视频了,第二天,我一步步看一步步找,终于我感觉好像问题出在flash上,我从请求中从来没获取到上次播放位置,而每次刷新都会从原来位置上播放,这样目光一下瞄准swf文件。
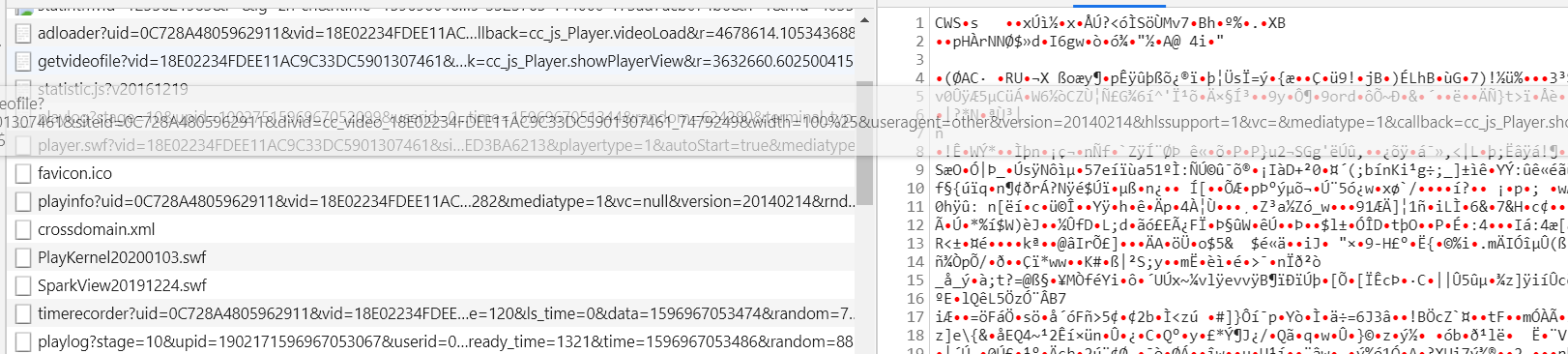
一堆乱码,只能先下载保存一个这样的文件了。
headers = {
"authority": "p.bokecc.com",
"accept-encoding": "gzip, deflate",
"accept-language": "zh-CN,zh;q=0.9",
# "Cache-Control": "no-cache",
"if-modified-since": "Tue, 10 Jul 2018 06:19:51 GMT",
"if-none-match": "5b445007-8c0e",
# "Connection": "keep-alive",
# "Cookie": "Hm_lvt_2c32a112d0d1558c3e63c2f90cd57477=1595775774,1595860124,1596264790; Hm_lpvt_2c32a112d0d1558c3e63c2f90cd57477=1596294515",
# "Pragma": "no-cache",
# "Host": "tzb.feelmoore.com",
"sec-fetch-dest": "embed",
"sec-fetch-mode": "no-cors",
"sec-fetch-site": "cross-site",
"path": "/flash/player.swf?vid=CCB1C8D79776B6469C33DC5901307461&siteid=0C728A4805962911&playerid=A8E5C78ED3BA6213&playertype=1&autoStart=true&mediatype=1",
"Referer": "http://www.kuaxue.com/Weixin/ClassUrl/shandong2/id/9867.shtml",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36"
# "
}
url ="https://p.bokecc.com/flash/player.swf?vid=CCB1C8D79776B6469C33DC5901307461&siteid=0C728A4805962911&playerid=A8E5C78ED3BA6213&playertype=1&autoStart=true&mediatype=1"
resp = requests.get(url, headers=headers)
print(resp.status_code)
with open('1.swf', 'wb') as f:
f.write(resp.content)
一通度娘,网上说swf文件需要反编译,又一通度娘,终于找到了一个大杀器,---jpexs-decompiler。下载安装,将刚才下载好的swf文件导入。
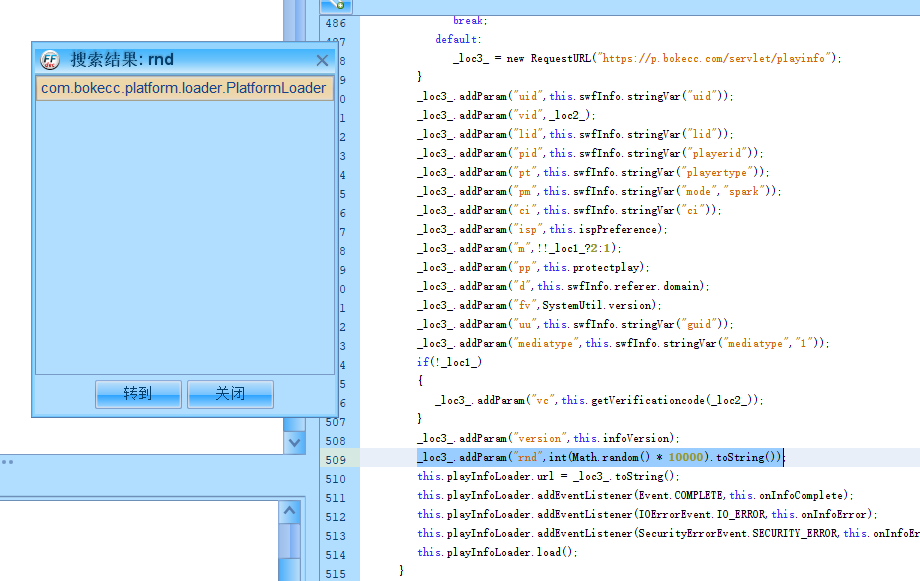
全局搜索一下rnd ,我去终于找到了,一看,无语了,随机数。。。。。
这下终于搞定了下载flv吧。
def get_real_url(uu, uid, vid, pid, id):
try:
headers = {
"authority": "p.bokecc.com",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"pragma": "no-cache",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "no-cors",
"sec-fetch-site": "cross-site",
"x-requested-with": "ShockwaveFlash/32.0.0.403",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36",
"path": "/servlet/playinfo?uid=" + uid + "&vid=" + vid + "&lid=&pid=" + pid + "&pt=1&pm=spark&ci=&isp=%2D1&m=1&pp=false&d=ktzb%2Efeelmoore%2Ecom&fv=WIN%2032%2C0%2C0%2C403&uu=" + uu + "&mediatype=1&vc=null&version=20140214&rnd=3156",
"Referer": 'http://www.kuaxue.com/Weixin/ClassUrl/shandong2/id/' + str(id) + '.shtml'
}
url = "https://p.bokecc.com/servlet/playinfo?uid=" + uid + "&vid=" + vid + "&lid=&pid=" + pid + "&pt=1&pm=spark&ci=&isp=%2D1&m=1&pp=false&d=ktzb%2Efeelmoore%2Ecom&fv=WIN%2032%2C0%2C0%2C403&uu=" + uu + "&mediatype=1&vc=null&version=20140214&rnd=3156"
print(url)
data = requests.get(url,
headers=headers).text
soup = BeautifulSoup(data, 'lxml')
# print(soup)
# img = soup.get('response')
res = soup.find_all("response")[0]
upid = re.findall(r'<upid>(.+?)</upid>', str(res))
if upid != []:
temp = res.find_all("video")[0].find_all("quality")
return str(temp[len(temp) - 1].find_all("copy")[0]["playurl"]) + "&upid=" + upid[0] + "&pt=0&pi=1"
else:
return ""
except:
print(vid+"获取playinfo失败")
return ""
def download(url, id, save_home,name):
try:
headers = {
# "Accept: */*
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Pragma": "no-cache",
"Host": url.replace("http://", "").split(".com")[0] + ".com",
# "path": url.replace("http://", "").split(".com")[1],
"Referer": "http://ktzb.feelmoore.com/LivingClassroom/index.html?isbn=" + str(id),
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36"
# "
}
resp = requests.get(url, headers=headers)
#
with open(save_home+name + '.flv', 'wb') as f:
f.write(resp.content)
except:
print(name+"下载视频失败")
uu = "474A2CC1946AEBAA0B83195A8F5ED539EB85CB9F"
uid = '0C728A4805962911'
pid = 'A8E5C78ED3BA6213'
for file in os.listdir("data/"):
with open("data/"+file, encoding='utf8') as data_json:
data_json = json.load(data_json)
list_data = str(data_json['data']).replace("[", '').replace("]", '').split("},")
result = []
for element in list_data:
try:
result.append(json.loads(element + "}"))
except:
result.append(json.loads(element))
for element in result:
vid =element['ccid']
id=element['id']
print(id)
flv_url = get_real_url(uu,uid, vid, pid, id)
download(flv_url, id, "flv/", element['title'])


 浙公网安备 33010602011771号
浙公网安备 33010602011771号