课堂直播视频-爬虫-1
最近看我外甥女数学不会,我就从网上买了本辅导书-课堂直播,上面的例题可以扫一扫看老师讲解,这样也太费事了,看看能不能自动下载下来。打开一看flash。。。。。

哎,不行也得行啊,直接上,找到总的地址。
http://ktzb.feelmoore.com/LiveClassroom/nodes/getRootNode?isbn=9787552258608&nodeType=5

一步步来,先获取全部数据在说,f12简单操作,找到这个。
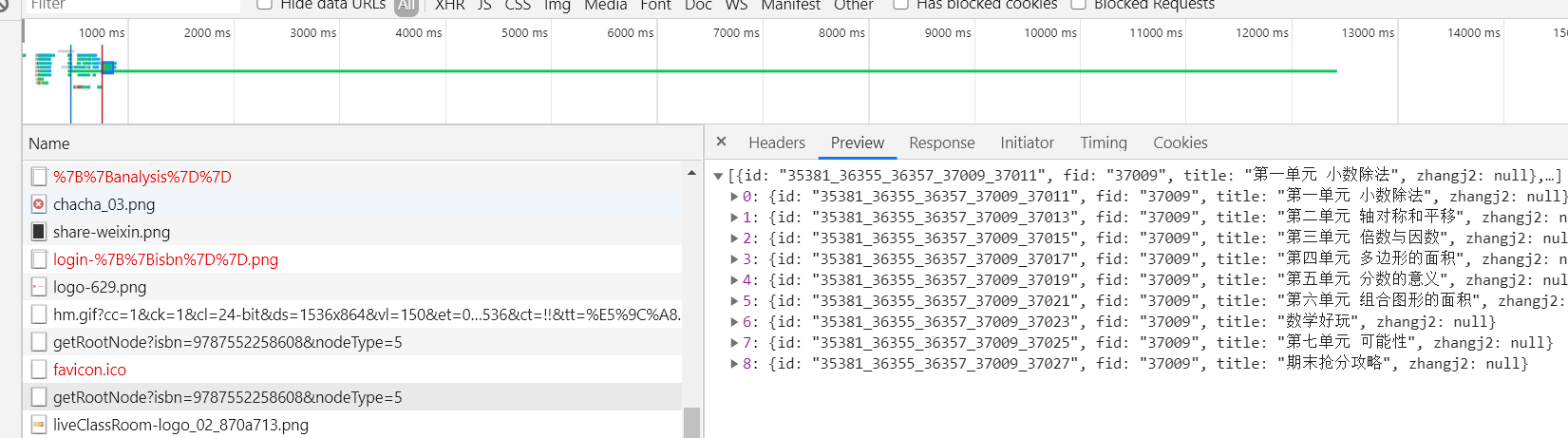
不说了,直接上代码。
def get_parent_url(id, node_type):
try:
result = []
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36",
"Host": "ktzb.feelmoore.com",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Referer": "http://ktzb.feelmoore.com/LivingClassroom/index.html?isbn=" + str(id),
"X-Requested-With": "XMLHttpRequest"
}
data = requests.get(
"http://ktzb.feelmoore.com/LiveClassroom/nodes/getRootNode?isbn=" + str(id) + "&nodeType=" + str(node_type),
headers=headers).text
for element in data:
temp = {}
temp['名字'] = element['title']
temp['id'] = element['id']
result.append(temp)
return result
except:
print("失败")
get_parent_url("9787552258608","5")
打开下一页,f12一下,我去,都不用我爬。
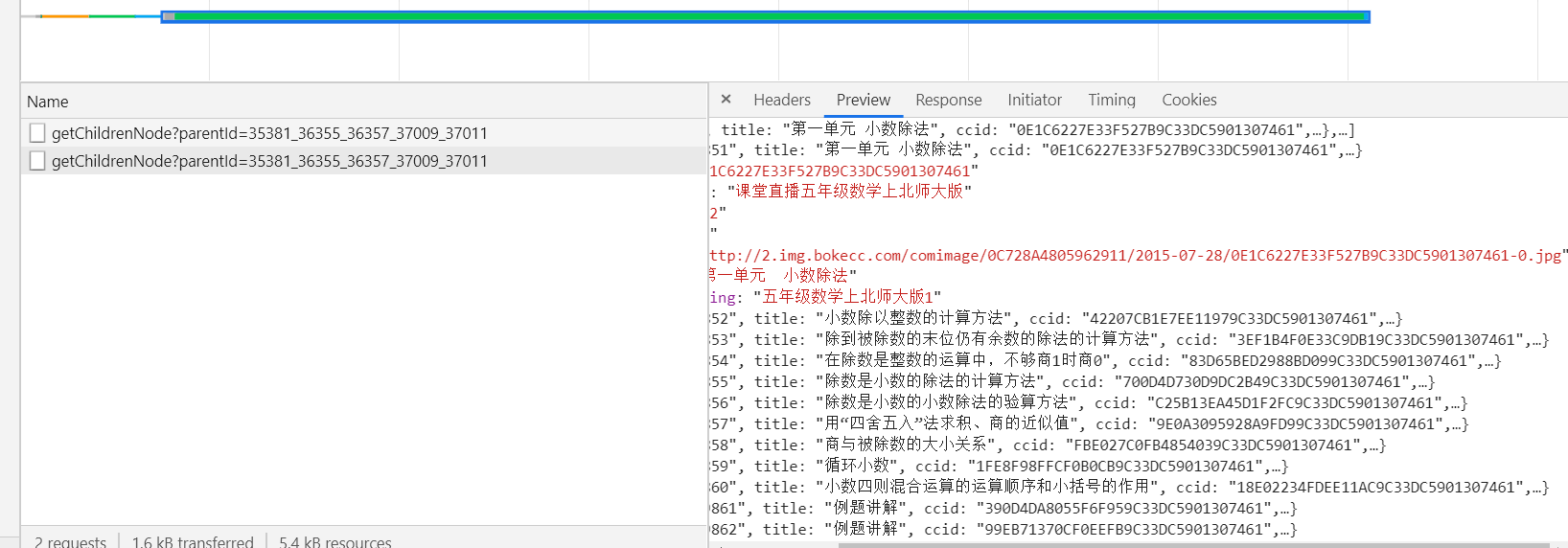
def get_children_url(id, parentId):
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36",
"Host": "ktzb.feelmoore.com",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Cookie": "PHPSESSID=ctjqa2ka7s5cie0crq023segs4", # 这里不是实时爬,所以直接抄它的cookie,在失效时间内凑合用
"Referer": "http://ktzb.feelmoore.com/LivingClassroom/index.html?isbn=" + str(id),
"X-Requested-With": "XMLHttpRequest"
}
data = requests.get("http://ktzb.feelmoore.com/LiveClassroom/nodes/getChildrenNode?parentId=" + str(parentId),
headers=headers).text
data = {"data": data}
with open("data/" + str(parentId) + '.json', "w", encoding="utf8") as dump_f:
json.dump(data, dump_f, ensure_ascii=False, indent=2)
return data
except:
print(parentId + "失败")
# for element in data:
# get_children_url('9787552258608', element['id'])
最终结果:

在这得瑟了,还以为有多难,结果就是啪啪打脸。。。。。。下回看我咋就被啪啪打脸。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号