Python高级应用程序设计任务
Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
基于requests的携程旅游(北京景点)爬取和分析
2.主题式网络爬虫爬取的内容与数据特征分析
爬取内容包括景点的名称、评论量、分数。其数据特征有以下几点:
(1)分析景点、评分、评论数据,并进行清洗
(2)分析景点和评论数的关系,构建数据分析模型,观察模型图价格的分布情况。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:
(1)利用requests方法请求网页。
(2)利用lxml进行网页解析,同时利用其语法获取需要的数据信息。
(3)利用循环实现翻页获取数据。
技术难点:
(1)要在爬取数据之前加入请求头部信息,否则会出现错误提示。
(2)注意要获取的数据在哪一个标签下,利用F12进行数据检查和分析所要爬取的数据特征。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
查看源代码 li 对应着每一个攻略信息,都是静态页面,无ajax、js产生的动态数据。

2.Htmls页面解析
通过解析可以发现我们想要获取的楼房名称是在li标签下,dl下的a标签中。
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
def pachong(): for i in range(1,10): url = 'https://you.ctrip.com/searchsite/sight/?query=%e5%8c%97%e4%ba%ac&isAnswered=&isRecommended=&publishDate=&PageNo='+str(i) res = get_tree(url) # 获取景点的列表 li_list = res.xpath('//ul[@class="jingdian-ul cf"]/li') # 循环列表,拿取每一个数据 for li in li_list: dic = {} # # 景点名 name = li.xpath('./dl/dt/a[1]/text()') dic['name'] = name[0] # 保存景点图片,以景点名命名 picture = li.xpath('./a/img/@src')[0] pic_url = picture # 因为有些图片地址路径不全,价格判断 if 'http' not in picture: pic_url = 'https:'+picture pic = requests.get(pic_url) dir = f'./{name[0]}.png' pinglun = li.xpath('./dl/dd/a/text()') # 评论数量 dic['pinglun'] = pinglun[0] xq_url = li.xpath('./a/@href') # 详情页 xq_url = 'https://you.ctrip.com'+xq_url[0] res1 = get_tree(xq_url) # 因为评分分两种格式,使用if判断拿取 fen = res1.xpath('//span[@class="score"]/b/text()') if fen ==[]: fen1 = res1.xpath('//div[@class="score"]/span/i/text()') dic['pingfen'] = fen1[0] else: dic['pingfen'] = fen[0] #保存数据 with open('景区.txt','a',encoding='utf8') as fp2: fp2.write(str(dic)) fp2.write('\n') print(dic) time.sleep(1)
2.对数据进行清洗和处理
# 清洗数据 name = [] pinglun = [] pingfen = [] for i in data: lst1 = i.split(',') dic = {} for j in range(len(lst1)): dic[j] = lst1[j].split(':')[1].strip().replace("'", "").replace('}', '') name.append(dic[0]) pinglun.append(int(dic[1].replace('条点评', ''))) pingfen.append(float(dic[2]))
3.文本分析(可选):jieba分词、wordcloud可视化
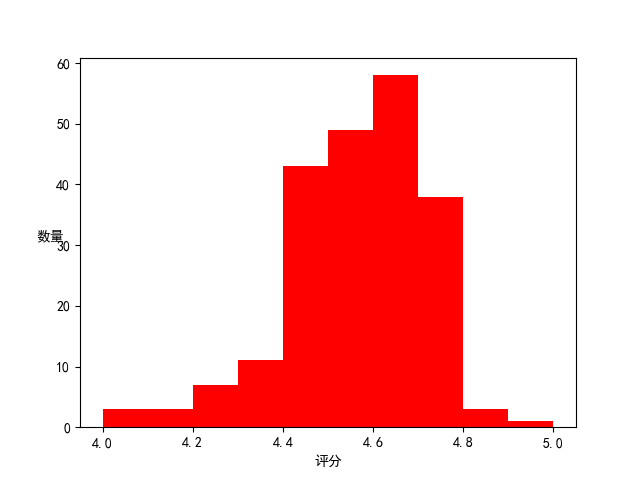
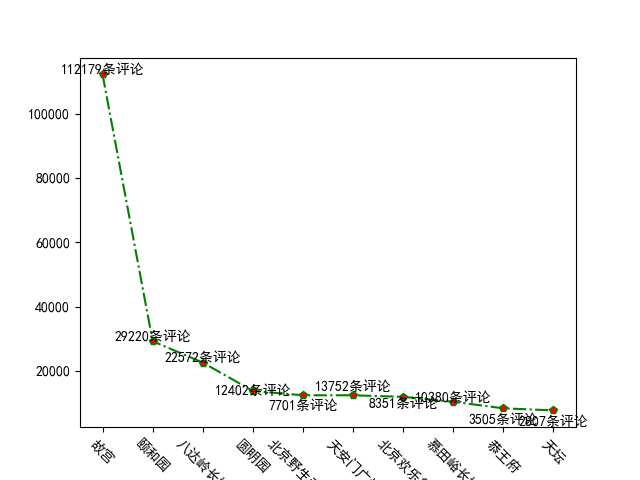
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
5.数据持久化

6.附完整程序代码
import requests from lxml import etree import math import time import matplotlib.pyplot as plt import pandas as pd import json # 返回xpath数据 def get_tree(url): # 获取 网页内容,返回 xpath 数据 headers = { 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36' } res = requests.get(url=url,headers=headers).content.decode('utf-8') # 保存网页,方便查看内容 # with open('qu.html','w',encoding='utf8')as fp: # fp.write(res) res = etree.HTML(res) return res # 爬虫函数 def pachong(): for i in range(1,10): url = 'https://you.ctrip.com/searchsite/sight/?query=%e5%8c%97%e4%ba%ac&isAnswered=&isRecommended=&publishDate=&PageNo='+str(i) res = get_tree(url) # 获取景点的列表 li_list = res.xpath('//ul[@class="jingdian-ul cf"]/li') # 循环列表,拿取每一个数据 for li in li_list: dic = {} # # 景点名 name = li.xpath('./dl/dt/a[1]/text()') dic['name'] = name[0] # 保存景点图片,以景点名命名 picture = li.xpath('./a/img/@src')[0] pic_url = picture # 因为有些图片地址路径不全,价格判断 if 'http' not in picture: pic_url = 'https:'+picture pic = requests.get(pic_url) dir = f'./{name[0]}.png' pinglun = li.xpath('./dl/dd/a/text()') # 评论数量 dic['pinglun'] = pinglun[0] xq_url = li.xpath('./a/@href') # 详情页 xq_url = 'https://you.ctrip.com'+xq_url[0] res1 = get_tree(xq_url) # 因为评分分两种格式,使用if判断拿取 fen = res1.xpath('//span[@class="score"]/b/text()') if fen ==[]: fen1 = res1.xpath('//div[@class="score"]/span/i/text()') dic['pingfen'] = fen1[0] else: dic['pingfen'] = fen[0] #保存数据 with open('景区.txt','a',encoding='utf8') as fp2: fp2.write(str(dic)) fp2.write('\n') print(dic) time.sleep(1) # 评分图绘制 def pingfentu(): # 读数据 with open('景区.txt', 'r', encoding='utf8')as fp: data = fp.read() data = data.split('\n') # 清洗数据 name = [] pinglun = [] pingfen = [] for i in data: lst1 = i.split(',') dic = {} for j in range(len(lst1)): dic[j] = lst1[j].split(':')[1].strip().replace("'", "").replace('}', '') name.append(dic[0]) pinglun.append(int(dic[1].replace('条点评', ''))) pingfen.append(float(dic[2])) data = {'名字': name, '评论数': pinglun, '评分': pingfen} # # 转为DataFrane 格式数据 df1 = pd.DataFrame(data) # 分析及绘图 # --------------------------------- # 评分图 plt.figure() # 修改默认字体 plt.rcParams['font.sans-serif'] = 'SimHei' # 正常显示符号,解决方块问题 plt.rcParams['axes.unicode_minus'] = False pingfen1 = [i for i in df1['评分']] group = [4.0 + i / 10 for i in range(11)] plt.hist(pingfen1, group, color='r') plt.xlabel('评分') plt.ylabel('数量', rotation=0) plt.savefig('评分图.png') plt.show() # 评论图绘制 def pingluntu(): with open('景区.txt', 'r', encoding='utf8')as fp: data = fp.read() data = data.split('\n') # 清洗数据 name = [] pinglun = [] pingfen = [] for i in data: lst1 = i.split(',') dic = {} for j in range(len(lst1)): dic[j] = lst1[j].split(':')[1].strip().replace("'", "").replace('}', '') name.append(dic[0]) pinglun.append(int(dic[1].replace('条点评', ''))) pingfen.append(float(dic[2])) data = {'名字': name, '评论数': pinglun, '评分': pingfen} # # 转为DataFrane 格式数据 df1 = pd.DataFrame(data) # 评论数前10绘图 df1_10 = df1.sort_values(by='评论数', ascending=False)[:20] plt.figure() plt.rcParams['font.sans-serif'] = 'SimHei' # 正常显示符号,解决方块问题 plt.rcParams['axes.unicode_minus'] = False x = [i for i in range(10)] plt.plot(x, df1_10['评论数'][:10], color='g', linestyle='-.', marker='p', markerfacecolor='r') plt.xticks(x, df1_10['名字'][:10], rotation=-45) for i in range(10): p = df1_10['评论数'][i] plt.text(x[i], p + 100, '%d条评论' % p, horizontalalignment='center') plt.savefig('评论图.png') plt.show() if __name__ == '__main__': pachong() pingfentu() pingluntu()
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
排除评论过少的景点,评分高的景点评论越多
2.对本次程序设计任务完成的情况做一个简单的小结。
经过这段时间对爬虫知识的学习,我对爬虫所使用的requests库、BeautifulSoup库、scrapy框架、lxml库有初步的认识,对爬虫的流程也有初步的了解。虽然这次爬取图片出了许多问题直到最后也没解决,希望自己以后能够爬取动态网页。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号