
Druid源码阅读--带流程图
一、架构分析
Druid类图如下所示:
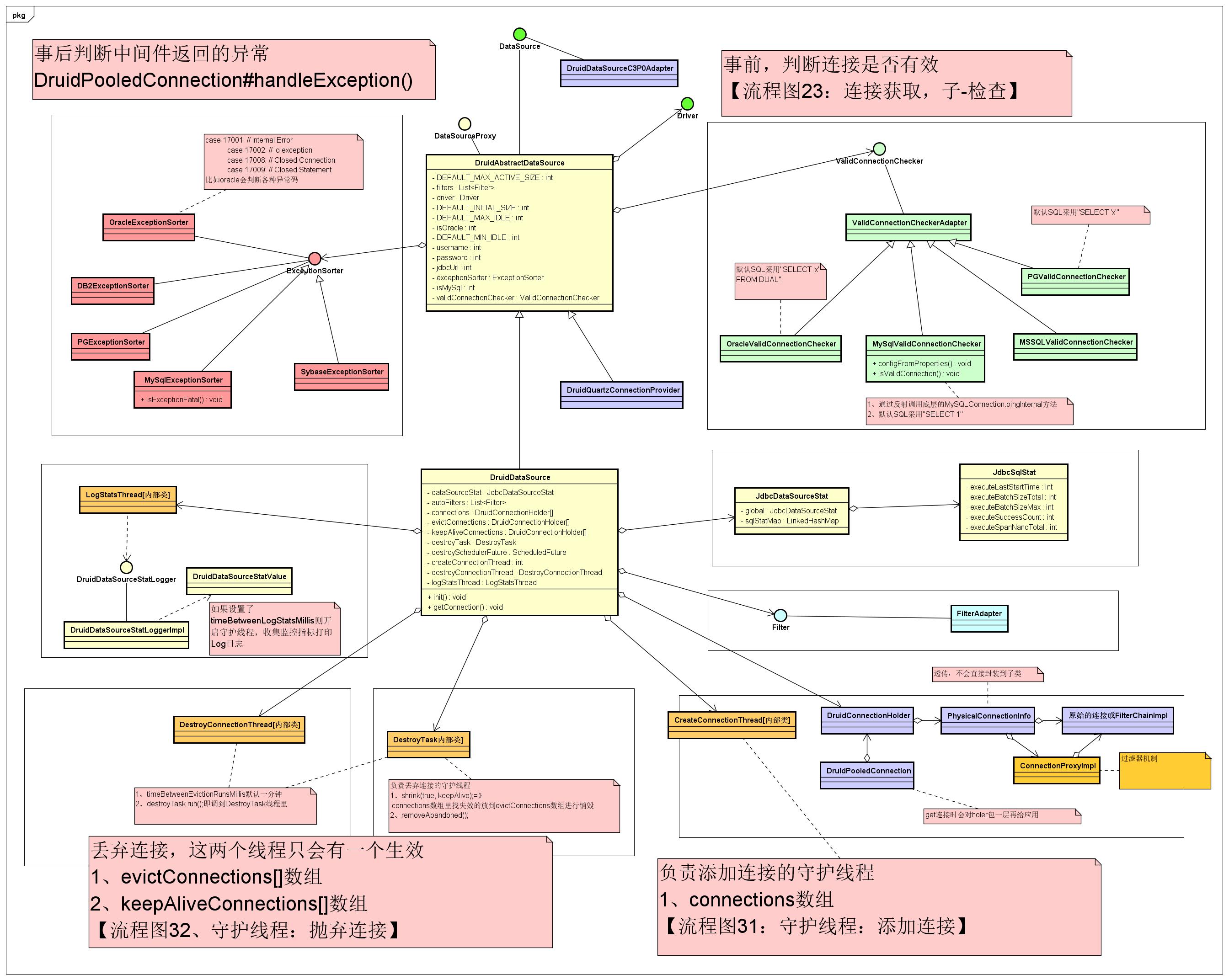
两大核心类:DruidDataSource和DruidAbstractDataSource
连接有效性check:从连接池中获取连接后会做有效性check,在类中有ValidConnectionChecker接口,对应有不同数据库的实现
异常处理:针对不同的数据库,druidPooledConnection#handleException为入口,ExceptionSorter接口,封装了对于异常的处理,不同的数据库有不同的实现,对于不同数据的错误状态码做处理。
三大数组:被驱逐的连接 evictconnections、可用连接 connections、保持活跃的连接 KeepAliveConnections
三大线程池:创建连接线程池CrerateConnectionThread、销毁连接线程池DestoryConnectionThread、连接监控线程池LogStatThread
监控:JdbcDataSourceStat,与LogStatThread结合使用
过滤器:Filter
扩展:DruidDataSourceC3P0Adapter
核心是DruidDataSource,包含了扩展过滤器集合
// 状态
protected JdbcDataSourceStat dataSourceStat;
// 过滤器
private static List<Filter> autoFilters;
// 三大数组
private volatile DruidConnectionHolder[] connections;
private DruidConnectionHolder[] evictConnections;
private DruidConnectionHolder[] keepAliveConnections;
// 三大线程(createConnectionThread、destroyConnectionThread、logStatsThread)
private DestroyTask destroyTask;
private volatile Future<?> createSchedulerFuture;
private CreateConnectionThread createConnectionThread;
private DestroyConnectionThread destroyConnectionThread;
private LogStatsThread logStatsThread;
// 获取连接
public DruidPooledConnection getConnection() throws SQLException {
return getConnection(maxWait);
}
// 初始化连接池
public void init() throws SQLException {
}
}
父类DruidAbstractDataSource,通用的一些参数设置
public static final int DEFAULT_MAX_ACTIVE_SIZE = 8;
public static final int DEFAULT_MAX_IDLE = 8;
protected volatile String username;
protected volatile String password;
protected volatile String jdbcUrl;
protected volatile String driverClass;
二、获取连接

Druid是使用懒加载创建线程池,在getConnection时调用的init方法对线程池做的初始化
(一)主流程
最先是创建线程池,主要是创建一把锁,同时初始化相关参数配置
/**
* 初始化
*/
public DruidDataSource() {
this(false);
}
public DruidDataSource(boolean fairLock) {
// 初始化公平锁lock,并绑定条件notEmpty和empty
super(fairLock);
// 设置属性值
configFromPropeties(System.getProperties());
}
public DruidAbstractDataSource(boolean lockFair) {
lock = new ReentrantLock(lockFair);
notEmpty = lock.newCondition();
empty = lock.newCondition();
}
然后是获取连接,获取连接分为两步,首先是调用init()方法初始化连接池,然后是从连接池中获取连接,而获取连接有两个分支,判断filters是否存在过滤器,如果存在则先执行过滤器中的内容,这采用责任链模式实现,但无论是否有过滤器,最终都是调用getConnectionDirect方法
public DruidPooledConnection getConnection() throws SQLException {
return getConnection(maxWait);
}
public DruidPooledConnection getConnection(long maxWaitMillis) throws SQLException {
// 初始化连接池
init();
// 这里有两个分支,判断filters是否存在过滤器,如果存在则先执行过滤器中的内容,这采用责任链模式实现。
// 无论是否有过滤器,最终都是调用getConnectionDirect方法
final int filtersSize = filters.size();
if (filtersSize > 0) {
//责任链执行过程
FilterChainImpl filterChain = createChain();
try {
return filterChain.dataSource_connect(this, maxWaitMillis);
} finally {
recycleFilterChain(filterChain);
}
} else {
//直接创建连接
return getConnectionDirect(maxWaitMillis);
}
}
public DruidPooledConnection dataSource_connect(DruidDataSource dataSource,
long maxWaitMillis) throws SQLException {
if (this.pos < filterSize) {
DruidPooledConnection conn = nextFilter().dataSource_getConnection(this, dataSource, maxWaitMillis);
return conn;
}
return dataSource.getConnectionDirect(maxWaitMillis);
}
(二)初始化连接池
1、如果已经初始化,不作处理,如果没有初始化,则先对整个初始化过程加锁。
2、遍历Filter并调用init方法来初始化过滤器,同时调用initFromSPIServiceLoader通过SPI加载过滤器(这里需要加上AutoLoad.class注解)
3、对JDBC相关参数的处理、校验等,例如调用DbType dbType = DbType.of(this.dbTypeName)来获取数据库类型,调用resolveDriver()加载驱动;并且对数据库的配置做校验
4、调用initExceptionSorter()方法初始化异常处理,这里使用策略模式,根据不同的数据库获取对应的ExceptionSorter实现,该类用于在连接产生不可用异常时及时将其从连接池排除
5、调用initValidConnectionChecker()方法初始化连接检验类型,这里使用策略模式,根据不同数据库获取不同的ValidConnectionChecker
6、调用validationQueryCheck()判断是否设置了数据库验证语句,如果没有设置,则在日志中输出
7、创建监控处理类JdbcDataSourceStat,这里会判断使用一个类还是多个类,这里主要是考虑一个系统存在分库分表、主从库等情况,会连接多个数据库
8、初始化三大数组
9、根据initialSize初始化连接,这里会判断是同步创建还是异步创建,如果是同步创建,则调用createPhysicalConnection方法来创建,如果是异步,则交由CreateConnectionTask线程执行;默认是异步创建
10、初始化三大线程:
调用createAndLogThread方法如果设置了timeBetweenLogStatsMillis,则开启守护线程,收集监控指标打印Log日志;调用createAndStartCreatorThread方法来创建负责添加连接的守护线程;调用createAndStartDestroyThread方法来创建负责丢弃连接的守护线程;
createAndStartCreatorThread和createAndStartDestroyThread通过CountDown来保证这两个线程启动完毕
11、最终设置初始化状态为已初始化,释放锁
public void init() throws SQLException {
......
// 如果已经初始化,不作处理
boolean init = false;
try {
if (inited) {
return;
}
initStackTrace = Utils.toString(Thread.currentThread().getStackTrace());
// 获取数据源id,同时设置connectionId、statementId、resultSetId、transactionId
this.id = DruidDriver.createDataSourceId();
if (this.id > 1) {
long delta = (this.id - 1) * 100000;
this.connectionIdSeedUpdater.addAndGet(this, delta);
this.statementIdSeedUpdater.addAndGet(this, delta);
this.resultSetIdSeedUpdater.addAndGet(this, delta);
this.transactionIdSeedUpdater.addAndGet(this, delta);
}
// 设置连接超时时间,如果没有设置,取默认值 10000
if (connectTimeout == 0) {
connectTimeout = DEFAULT_TIME_CONNECT_TIMEOUT_MILLIS;
}
// 设置TCP连接超时时间,如果没有设置,取默认值 10000
if (socketTimeout == 0) {
socketTimeout = DEFAULT_TIME_SOCKET_TIMEOUT_MILLIS;
}
if (this.jdbcUrl != null) {
this.jdbcUrl = this.jdbcUrl.trim();
// 从封装的驱动url进行初始化数据源的驱动、名称、链接地址、过滤器集合
initFromWrapDriverUrl();
// 初始化连接超时时间和Socket超时时间
initFromUrlOrProperties();
}
// 初始化过滤器
for (Filter filter : filters) {
filter.init(this);
}
if (this.dbTypeName == null || this.dbTypeName.length() == 0) {
this.dbTypeName = JdbcUtils.getDbType(jdbcUrl, null);
}
DbType dbType = DbType.of(this.dbTypeName);
if (JdbcUtils.isMysqlDbType(dbType)) {
boolean cacheServerConfigurationSet = false;
if (this.connectProperties.containsKey("cacheServerConfiguration")) {
cacheServerConfigurationSet = true;
} else if (this.jdbcUrl.indexOf("cacheServerConfiguration") != -1) {
cacheServerConfigurationSet = true;
}
if (cacheServerConfigurationSet) {
this.connectProperties.put("cacheServerConfiguration", "true");
}
}
if (maxActive <= 0) {
throw new IllegalArgumentException("illegal maxActive " + maxActive);
}
if (maxActive < minIdle) {
throw new IllegalArgumentException("illegal maxActive " + maxActive);
}
if (getInitialSize() > maxActive) {
throw new IllegalArgumentException("illegal initialSize " + this.initialSize + ", maxActive " + maxActive);
}
if (timeBetweenLogStatsMillis > 0 && useGlobalDataSourceStat) {
throw new IllegalArgumentException("timeBetweenLogStatsMillis not support useGlobalDataSourceStat=true");
}
if (maxEvictableIdleTimeMillis < minEvictableIdleTimeMillis) {
throw new SQLException("maxEvictableIdleTimeMillis must be grater than minEvictableIdleTimeMillis");
}
if (keepAlive && keepAliveBetweenTimeMillis <= timeBetweenEvictionRunsMillis) {
throw new SQLException("keepAliveBetweenTimeMillis must be greater than timeBetweenEvictionRunsMillis");
}
if (this.driverClass != null) {
this.driverClass = driverClass.trim();
}
// 使用SPI加载过滤器,放入过滤器集合
initFromSPIServiceLoader();
// 解析驱动,设置数据库驱动和驱动类
resolveDriver();
// 初始化验证,设置数据库类型
initCheck();
this.netTimeoutExecutor = new SynchronousExecutor();
// 根据不同的数据库初始化数据库异常类
initExceptionSorter();
// 根据不同的数据库初始化数据库验证类
initValidConnectionChecker();
// 校验验证连接设置是否正确
validationQueryCheck();
// 设置数据源监控
if (isUseGlobalDataSourceStat()) {
dataSourceStat = JdbcDataSourceStat.getGlobal();
if (dataSourceStat == null) {
dataSourceStat = new JdbcDataSourceStat("Global", "Global", this.dbTypeName);
JdbcDataSourceStat.setGlobal(dataSourceStat);
}
if (dataSourceStat.getDbType() == null) {
dataSourceStat.setDbType(this.dbTypeName);
}
} else {
dataSourceStat = new JdbcDataSourceStat(this.name, this.jdbcUrl, this.dbTypeName, this.connectProperties);
}
// 设置数据源监控是否可重置
dataSourceStat.setResetStatEnable(this.resetStatEnable);
// 初始化连接池数组,长度为最大活跃连接数
connections = new DruidConnectionHolder[maxActive];
// 初始化待清理的连接数组,长度为最大活跃连接数
evictConnections = new DruidConnectionHolder[maxActive];
// 初始化待探活的连接数组,长度为最大活跃连接数
keepAliveConnections = new DruidConnectionHolder[maxActive];
// 初始化连接标志数组,长度为最大活跃连接数
connectionsFlag = new boolean[maxActive];
// 初始化疑似泄露的连接数组,长度为最大活跃连接数
shrinkBuffer = new DruidConnectionHolder[maxActive];
SQLException connectError = null;
// 创建连接
// 如果有创建连接线程池,且需要异步初始化,循环向线程池中添加需要创建的连接数
if (createScheduler != null && asyncInit) {
for (int i = 0; i < initialSize; ++i) {
submitCreateTask(true);
}
} else if (!asyncInit) {
// 如果不是异步创建连接,则在主线程循环创建连接
while (poolingCount < initialSize) {
try {
PhysicalConnectionInfo pyConnectInfo = createPhysicalConnection();
DruidConnectionHolder holder = new DruidConnectionHolder(this, pyConnectInfo);
connections[poolingCount++] = holder;
} catch (SQLException ex) {
LOG.error("init datasource error, url: " + this.getUrl(), ex);
if (initExceptionThrow) {
connectError = ex;
break;
} else {
Thread.sleep(3000);
}
}
}
if (poolingCount > 0) {
poolingPeak = poolingCount;
poolingPeakTime = System.currentTimeMillis();
}
}
// 创建日志线程
createAndLogThread();
// 创建 创建连接线程
createAndStartCreatorThread();
// 创建 销毁连接线程
createAndStartDestroyThread();
// 等待创建连接线程和销毁连接线程都执行完之后,再继续执行主线程
initedLatch.await();
init = true;
initedTime = new Date();
// 注册MBEAN todo:需要再确认
registerMbean();
if (connectError != null && poolingCount == 0) {
throw connectError;
}
// 如果要保持心跳
// 如果创建连接线程池不为空,则直接创建最小连接数的连接,
// 否则通知在empty上等待的线程,可以获取连接
if (keepAlive) {
// async fill to minIdle
if (createScheduler != null) {
for (int i = 0; i < minIdle; ++i) {
submitCreateTask(true);
}
} else {
this.emptySignal();
}
}
} catch (SQLException e) {
LOG.error("{dataSource-" + this.getID() + "} init error", e);
throw e;
} catch (InterruptedException e) {
throw new SQLException(e.getMessage(), e);
} catch (RuntimeException e) {
LOG.error("{dataSource-" + this.getID() + "} init error", e);
throw e;
} catch (Error e) {
LOG.error("{dataSource-" + this.getID() + "} init error", e);
throw e;
} finally {
inited = true;
lock.unlock();
if (init && LOG.isInfoEnabled()) {
String msg = "{dataSource-" + this.getID();
if (this.name != null && !this.name.isEmpty()) {
msg += ",";
msg += this.name;
}
msg += "} inited";
LOG.info(msg);
}
}
}
(三)从连接池获取连接主流程
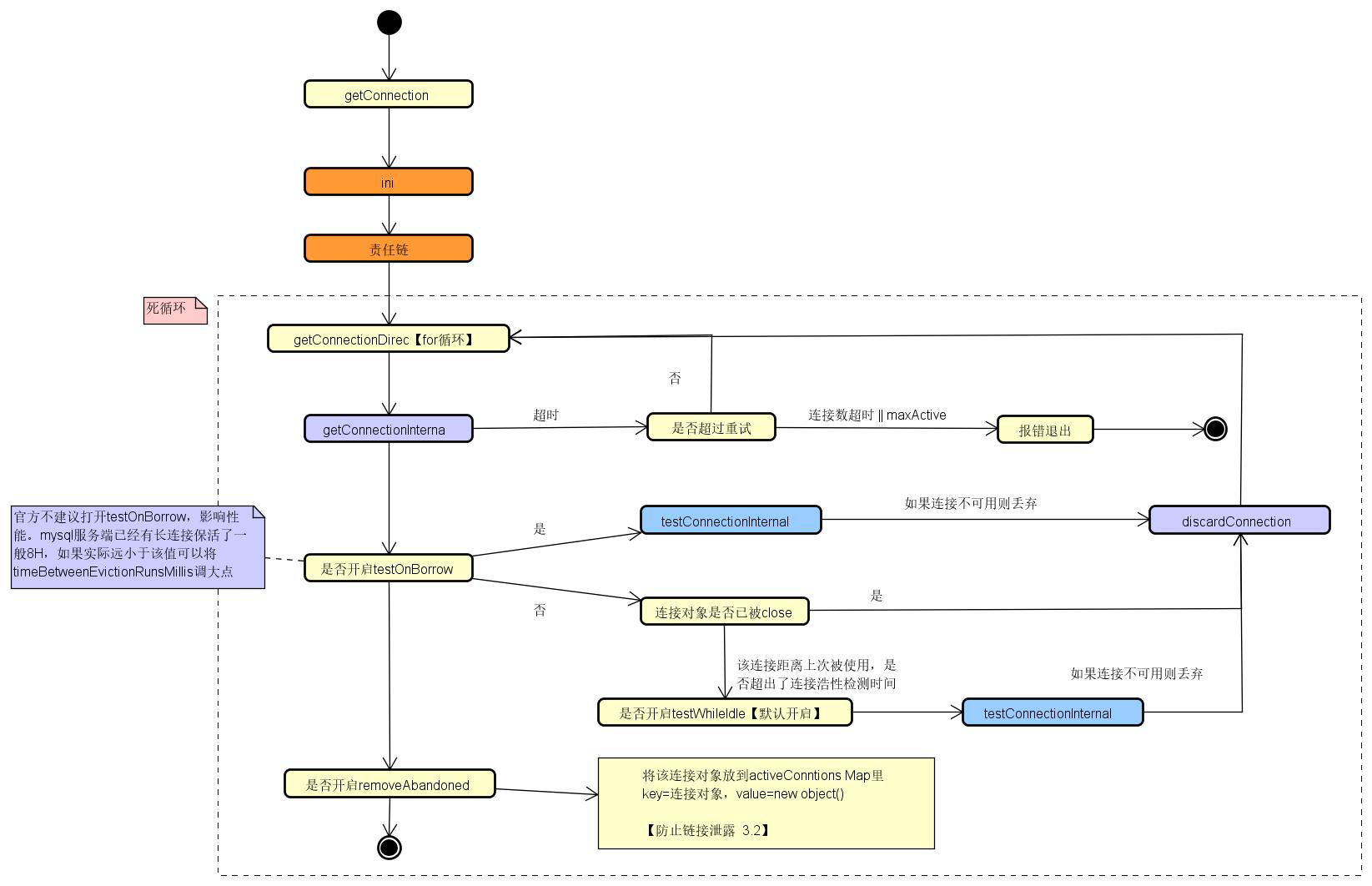
执行完init()方法,然后是从连接池中获取连接,而获取连接有两个分支,判断filters是否存在过滤器,如果存在则先执行过滤器中的内容,这采用责任链模式实现,但无论是否有过滤器,最终都是调用getConnectionDirect方法。
1、在该方法中自旋调用getConnectionInternal获取连接,如果获取连接超时,在没有达到最大重试次数并且连接没有满的情况下,继续自旋重试获取连接。(这里特殊说明一下,在大多数框架中,真正做一件事的方法一般叫 doxxxx,例如该方法可以叫doGetConnection)
2、获取连接后,如果开启了testOnBorrow(每次获取连接都校验连接有效性),则调用testConnectionInternal测试连接有效性。该参数在高并发的时候会造成性能下降,因此不太建议设置为true;但是对于一些网络环境比较复杂的场景,还是比较有用的。
3、如果没有开启testOnBorrow,首先判断连接是否已经关闭,如果关闭,则继续自旋获取下一个连接;如果没有关闭,则继续执行。
4、如果开启了testWhileIdle,则定时检测连接是否可用,这个定时是如果连接闲置时间(当前时间减去最后一次活跃时间)大于连接检测时间间隔(timeBetweenEvictionRunsMillis),则执行一次检测,该参数默认开启。
5、如果开启了removeAbandoned,则会监控是否有连接泄露,即将该连接对象放到activeConnectionsMap里,key是连接对象,这样就可以做相关的告警或者强制回收;该参数默认是关闭的,这是因为现在我们都是使用框架开发,框架都会在事务提交时将连接自动关闭,因此不需要开启,但是如果使用原生API开发,还是建议开启。
6、最终设置事务是否自动提交,但是我们一般不做设置,这是因为我们在使用Spring框架时,框架层面就会做这方面的设置。
可以看到,如果开启了testOnBorrow,testWhileIdle参数就不起作用了。
public DruidPooledConnection getConnectionDirect(long maxWaitMillis) throws SQLException {
int notFullTimeoutRetryCnt = 0;
// 死循环,一直尝试获取
for (; ; ) {
// handle notFullTimeoutRetry
// 获取连接:getConnectionInternal
// 如果没有超过最大重试次数(notFullTimeoutRetryCnt <= this.notFullTimeoutRetryCount)且连接没有耗尽(不满足this.poolingCount + this.activeCount >= this.maxActive),重新进入for循环获取
// 否则直接排除异常
DruidPooledConnection poolableConnection;
try {
poolableConnection = getConnectionInternal(maxWaitMillis);
} catch (GetConnectionTimeoutException ex) {
if (notFullTimeoutRetryCnt <= this.notFullTimeoutRetryCount && !isFull()) {
notFullTimeoutRetryCnt++;
if (LOG.isWarnEnabled()) {
LOG.warn("get connection timeout retry : " + notFullTimeoutRetryCnt);
}
continue;
}
throw ex;
}
// 如果开启testOnBorrow,则验证连接是否有效
// 如果开启,每次获取连接时候都要到数据库验证连接有效性,这在高并发的时候会造成性能下降,可以将testOnBorrow设置成false,testWhileIdle设置成true这样能获得比较好的性能
if (testOnBorrow) {
boolean validated = testConnectionInternal(poolableConnection.holder, poolableConnection.conn);
if (!validated) {
if (LOG.isDebugEnabled()) {
LOG.debug("skip not validated connection.");
}
discardConnection(poolableConnection.holder);
continue;
}
} else {
// 检测是否关闭,如果连接已关闭,则继续for循环获取下一个连接
if (poolableConnection.conn.isClosed()) {
discardConnection(poolableConnection.holder); // 传入null,避免重复关闭
continue;
}
// 此时判断连接空闲的依据是空闲时间大于timeBetweenEvictionRunsMillis(默认1分钟),并不是使用minEvictableIdleTimeMillis跟maxEvictableIdleTimeMillis,
// 也就是说如果连接空闲时间超过一分钟就测试一下连接的有效性,但并不是直接剔除;而如果空闲时间超过了minEvictableIdleTimeMillis则会直接剔除
// TODO:此处描述应该更清晰一点
// 连接空闲时间大于timeBetweenEvictionRunsMillis指定的毫秒,就会执行参数validationQuery指定的SQL来检测连接是否有效。这个参数会定期执行。
// 检测是否空闲
if (testWhileIdle) {
......
if (idleMillis >= timeBetweenEvictionRunsMillis
|| idleMillis < 0 // unexcepted branch
) {
boolean validated = testConnectionInternal(poolableConnection.holder, poolableConnection.conn);
if (!validated) {
if (LOG.isDebugEnabled()) {
LOG.debug("skip not validated connection.");
}
discardConnection(poolableConnection.holder);
continue;
}
}
}
}
// 是否回收连接泄露
// 如果有线程从Druid中获取到了连接并没有及时归还,那么Druid就会定期检测该连接是否会处于运行状态,如果不处于运行状态,则被获取时间超过removeAbandonedTimeoutMillis就会强制回收该连接。
if (removeAbandoned) {
StackTraceElement[] stackTrace = Thread.currentThread().getStackTrace();
poolableConnection.connectStackTrace = stackTrace;
poolableConnection.setConnectedTimeNano();
poolableConnection.traceEnable = true;
activeConnectionLock.lock();
try {
activeConnections.put(poolableConnection, PRESENT);
} finally {
activeConnectionLock.unlock();
}
}
// 设置数据源事务是否自动提交
if (!this.defaultAutoCommit) {
poolableConnection.setAutoCommit(false);
}
return poolableConnection;
}
}
(四)从连接池中获取连接详解
1、首先判断连接池状态 closed 和enable状态是否正确,如果不正确则记录相关信息,然后抛出异常
2、第一次进入,判断如果createScheduler是否存在,如果存在且executor.getQueue().size()大于0,那么将启用直接创建逻辑,退出本次循环,并调用createPhysicalConnection创建PhysicalConnectionInfo
3、如果不满足上述条件,则判断是否设置了超时时间,如果maxWait大于0,表示有超时时间,调用 pollLast(nanos),反之则调用takeLast()
4、上述步骤获取了一个DruidConnectionHolder,增加holder的使用次数,这个使用次数是监控要用的,最后封装成一个DruidPooledConnection返回
这里再说一下Druid中关于连接的类关系,连接时使用CreateConnectionThread线程创建的,获取到的连接是DruidConnectionHolder(也就是说数组中存储的DruidConnectionHolder),但是会包装为DruidPooledConnection代理类进行返回。
private DruidPooledConnection getConnectionInternal(long maxWait) throws SQLException {
// 首先判断连接池状态 closed 和enable状态是否正确,如果不正确则抛出异常退出
if (closed) {
connectErrorCountUpdater.incrementAndGet(this);
throw new DataSourceClosedException("dataSource already closed at " + new Date(closeTimeMillis));
}
if (!enable) {
connectErrorCountUpdater.incrementAndGet(this);
if (disableException != null) {
throw disableException;
}
throw new DataSourceDisableException();
}
final long nanos = TimeUnit.MILLISECONDS.toNanos(maxWait);
final int maxWaitThreadCount = this.maxWaitThreadCount;
DruidConnectionHolder holder;
for (boolean createDirect = false; ; ) {
// 直接创建连接的逻辑
if (createDirect) {
createStartNanosUpdater.set(this, System.nanoTime());
if (creatingCountUpdater.compareAndSet(this, 0, 1)) {
PhysicalConnectionInfo pyConnInfo = DruidDataSource.this.createPhysicalConnection();
holder = new DruidConnectionHolder(this, pyConnInfo);
......
}
}
final ReentrantLock lock = this.lock;
try {
lock.lockInterruptibly();
} catch (InterruptedException e) {
connectErrorCountUpdater.incrementAndGet(this);
throw new SQLException("interrupt", e);
}
try {
......
// 判断如果createScheduler存在,且executor.getQueue().size()大于0 那么将启用createDirect逻辑,退出本持循环
if (createScheduler != null
&& poolingCount == 0
&& activeCount < maxActive
&& creatingCountUpdater.get(this) == 0
&& createScheduler instanceof ScheduledThreadPoolExecutor) {
ScheduledThreadPoolExecutor executor = (ScheduledThreadPoolExecutor) createScheduler;
if (executor.getQueue().size() > 0) {
createDirect = true;
continue;
}
}
//如果maxWait大于0,调用 pollLast(nanos),反之则调用takeLast()
//获取连接的核心逻辑
if (maxWait > 0) {
holder = pollLast(nanos);
} else {
holder = takeLast();
}
......
}
......
break;
}
......
// 获得holder之后,通过holder产生连接
holder.incrementUseCount();
DruidPooledConnection poolalbeConnection = new DruidPooledConnection(holder);
return poolalbeConnection;
}
具体流程如下:
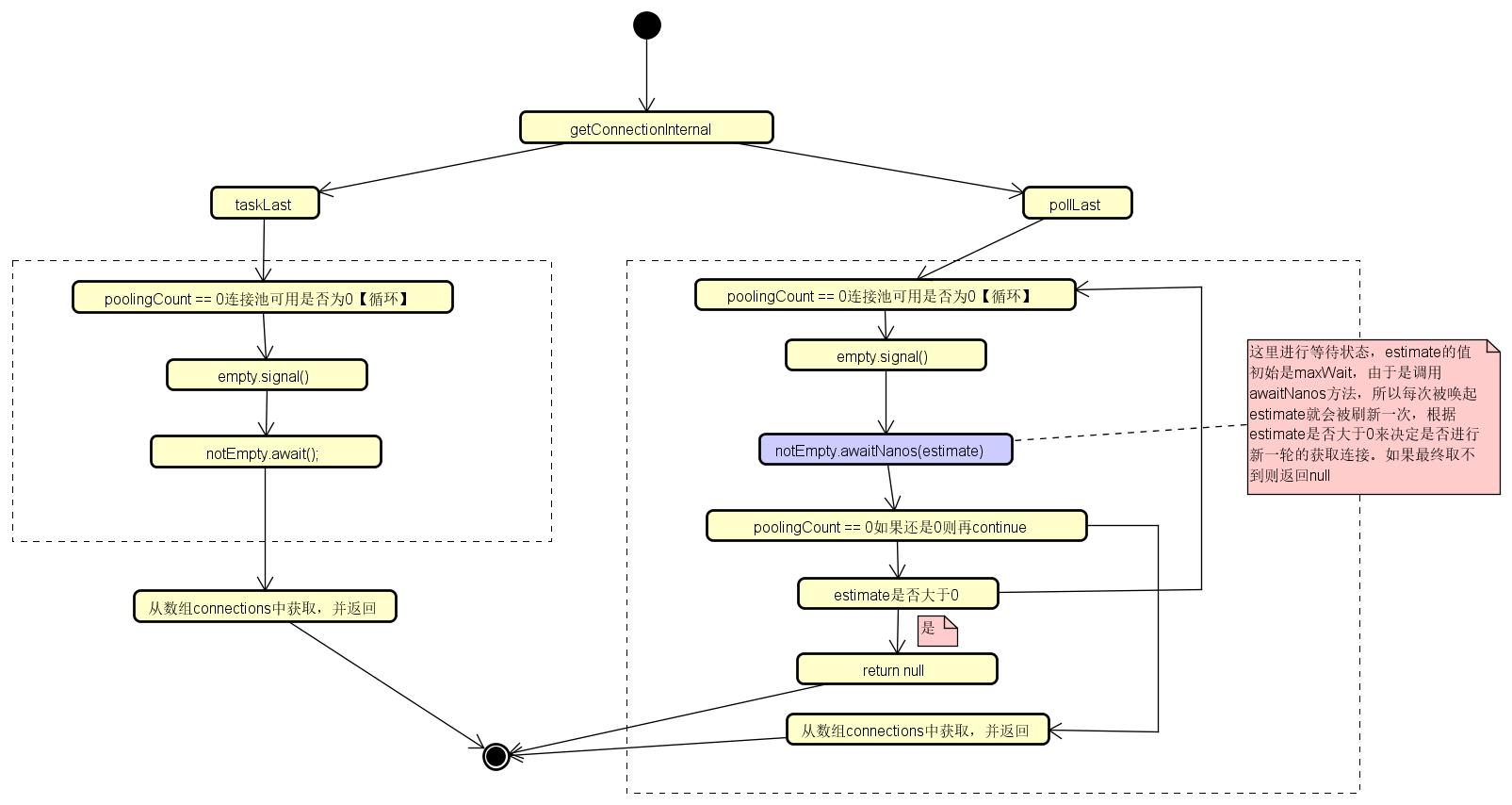
1、takeLast()
taskLast是阻塞获取,如果连接池中没有可用连接(poolingCount == 0),则一直阻塞获取,知道获取到可用连接,这时可以拿到可用连接数;如果获取到连接,则将可用连接数减一,同时将connections数组中该连接置为空。
阻塞获取首先调用notEmpty.await()一直阻塞等待,直到应用侧归还或者生产者生产;一旦被通知了不为空,则会继续往下执行;
在调用阻塞等待之前,还会调用emptySignal()方法来发通知,通知持有的empty的对象放行,如果没有达到最大连接数,则去创建新的连接
DruidConnectionHolder takeLast() throws InterruptedException, SQLException {
try {
while (poolingCount == 0) {
emptySignal(); // send signal to CreateThread create connection
......
try {
notEmpty.await(); // signal by recycle or creator
}
......
}
......
decrementPoolingCount();
DruidConnectionHolder last = connections[poolingCount];
connections[poolingCount] = null;
return last;
}
private void emptySignal() {
if (createScheduler == null) {
empty.signal();
return;
}
if (createTaskCount >= maxCreateTaskCount) {
return;
}
if (activeCount + poolingCount + createTaskCount >= maxActive) {
return;
}
submitCreateTask(false);
}
2、pollLast(nanos)
与takeLast()的区别是调用notEmpty.awaitNanos(estimate)函数增加了超时时间,
private DruidConnectionHolder pollLast(long nanos) throws InterruptedException, SQLException {
long estimate = nanos;
for (; ; ) {
if (poolingCount == 0) {
emptySignal(); // send signal to CreateThread create connection
......
try {
long startEstimate = estimate;
estimate = notEmpty.awaitNanos(estimate); // signal by
......
}
......
}
......
DruidConnectionHolder last = connections[poolingCount];
......
return last;
}
}
(五)连接可用性检测
在获取到连接后,无论是开启testOnBorrow或testWhileIdle,都会做连接可用性检测,只是检测时机不一样,做链接检测都是使用的下述代码,调用testConnectionInternal验证连接可用性,如果不可用,调用discardConnection丢弃连接。
boolean validated = testConnectionInternal(poolableConnection.holder, poolableConnection.conn);
if (!validated) {
if (LOG.isDebugEnabled()) {
LOG.debug("skip not validated connection.");
}
discardConnection(poolableConnection.holder);
continue;
}
如果存在连接验证类ValidConnectionChecker的实例,则调用该实例的isValidConnection方法做验证,如果没有,则判断是否有验证SQL,如果不存在,则直接返回连接可用,如果存在,则使用连接创建Statement,并执行sql验证;
以mysql的ValidConnectionChecker子类MySqlValidConnectionChecker为例,在isValidConnection方法中,如果设置了使用ping验证(usePingMethod),则通过反射调用ping命令执行,没有没有设置该种方式验证,那么也是执行设置的validateQuery查询语句,如果查询语句为空,则直接使用默认值。
对于mysql来说,除了要验证连接是否可用外,还需要判断连接空闲时间(当前时间 - 最后一次收包时间)如果大于连接检测时间间隔,则仍然返回连接不可用。
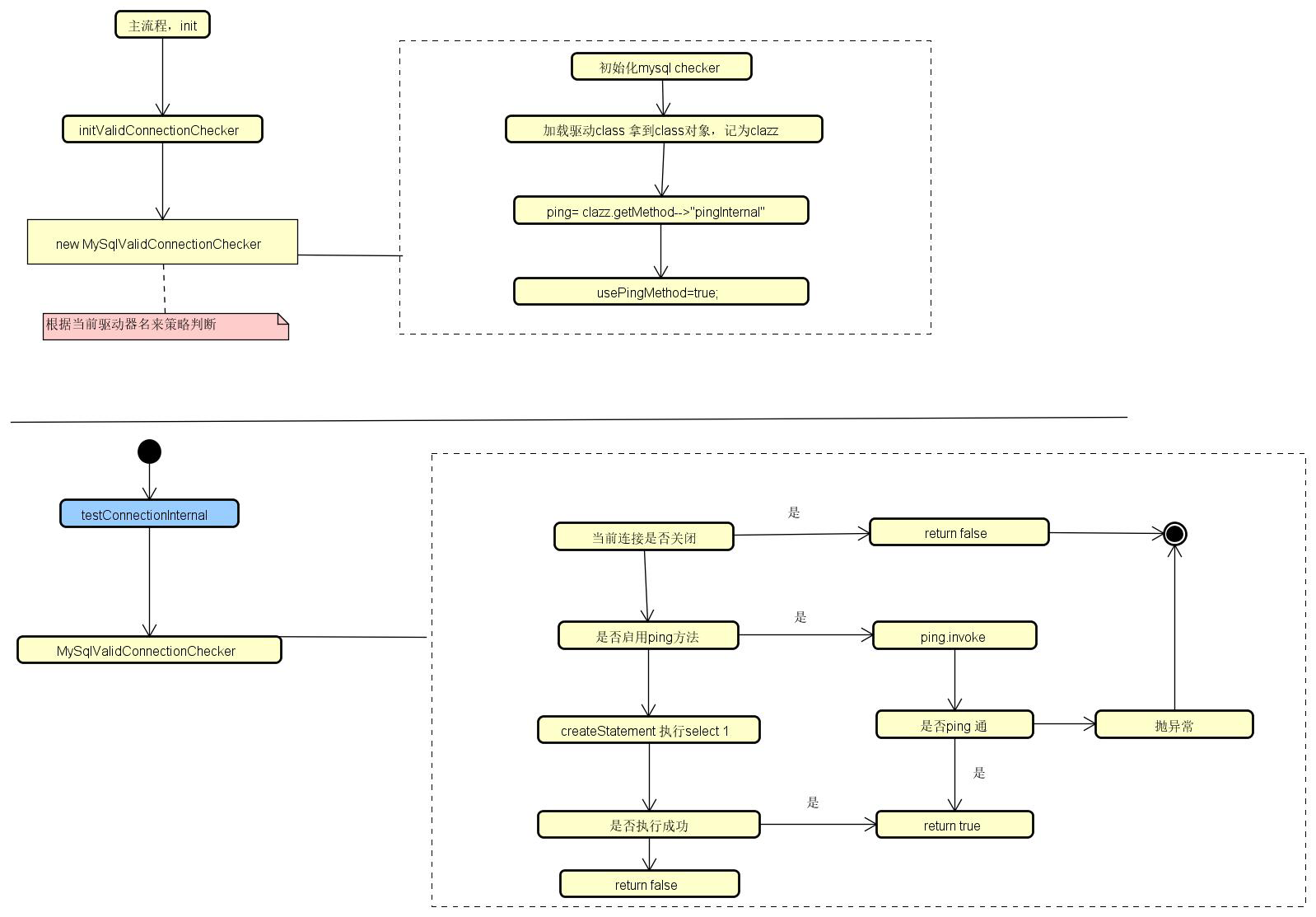
protected boolean testConnectionInternal(DruidConnectionHolder holder, Connection conn) {
......
try {
if (validConnectionChecker != null) {
boolean valid = validConnectionChecker.isValidConnection(conn, validationQuery, validationQueryTimeout);
......
if (valid && isMySql) { // unexcepted branch
long lastPacketReceivedTimeMs = MySqlUtils.getLastPacketReceivedTimeMs(conn);
if (lastPacketReceivedTimeMs > 0) {
long mysqlIdleMillis = currentTimeMillis - lastPacketReceivedTimeMs;
if (mysqlIdleMillis >= timeBetweenEvictionRunsMillis) {
discardConnection(holder);
String errorMsg = "discard long time none received connection. "
+ ", jdbcUrl : " + jdbcUrl
+ ", version : " + VERSION.getVersionNumber()
+ ", lastPacketReceivedIdleMillis : " + mysqlIdleMillis;
LOG.warn(errorMsg);
return false;
}
}
......
}
return valid;
}
......
if (null == validationQuery) {
return true;
}
try {
stmt = conn.createStatement();
if (getValidationQueryTimeout() > 0) {
stmt.setQueryTimeout(validationQueryTimeout);
}
rset = stmt.executeQuery(validationQuery);
if (!rset.next()) {
return false;
}
}
......
}
public class MySqlValidConnectionChecker extends ValidConnectionCheckerAdapter implements ValidConnectionChecker, Serializable {
......
public boolean isValidConnection(Connection conn,
String validateQuery,
int validationQueryTimeout) throws Exception {
......
if (usePingMethod) {
......
ping.invoke(conn, true, validationQueryTimeout * 1000);
......
return true;
}
String query = validateQuery;
if (validateQuery == null || validateQuery.isEmpty()) {
query = DEFAULT_VALIDATION_QUERY;
}
......
rs = stmt.executeQuery(query);
return true;
......
}
}
(六)连接不可用时丢弃连接
在验证连接失效后,会调用discardConnection丢弃连接,逻辑比较简单,首先关闭Connection和Socket,然后加锁改变holder的状态和相关的数据统计,最后判断如果活跃的连接数小于最小连接数,则调用emptySignal()创建新的连接。
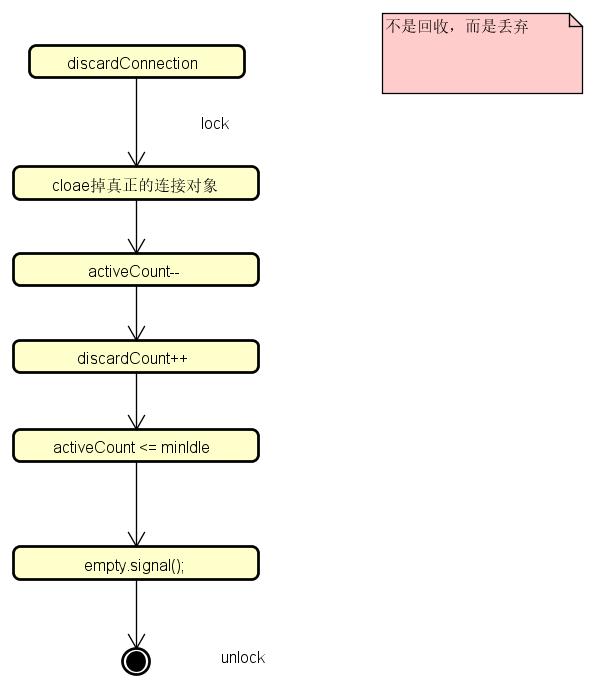
public void discardConnection(DruidConnectionHolder holder) {
if (holder == null) {
return;
}
Connection conn = holder.getConnection();
if (conn != null) {
JdbcUtils.close(conn);
}
Socket socket = holder.socket;
if (socket != null) {
JdbcUtils.close(socket);
}
lock.lock();
try {
if (holder.discard) {
return;
}
if (holder.active) {
activeCount--;
holder.active = false;
}
discardCount++;
holder.discard = true;
if (activeCount <= minIdle) {
emptySignal();
}
} finally {
lock.unlock();
}
}
三、生产连接

在创建连接时,首先判断是否等待连接,如果需要等待,判断已有连接数是否已经达到最大,如果达到最大,则阻塞等待;如果没有达到最大连接数,则直接调用createPhysicalConnection方法创建新的连接;
创建连接后,将连接封装为DruidConnectionHolder,放入连接池数组connections
public class CreateConnectionThread extends Thread {
public void run() {
initedLatch.countDown();
for (; ; ) {
......
try {
boolean emptyWait = true;
......
if (emptyWait) {
// 必须存在线程等待,才创建连接
if (poolingCount >= notEmptyWaitThreadCount //
&& (!(keepAlive && activeCount + poolingCount < minIdle))
&& !isFailContinuous()
) {
empty.await();
}
// 防止创建超过maxActive数量的连接
if (activeCount + poolingCount >= maxActive) {
empty.await();
continue;
}
}
}
......
PhysicalConnectionInfo connection = null;
try {
connection = createPhysicalConnection();
}
......
boolean result = put(connection);
......
}
}
}
四、连接清理
清理连接的线程是DestroyConnectionThread,该线程是个守护线程,其自旋调用DestroyTask执行清理操作;在清理时,根据设置的执行频率做回收操作,默认一分钟回收一次;DestroyTask清理连接主要分两部分,一个是shrink方法,用于连接池瘦身,一个是removeAbandoned方法,主动回收长期未归还的连接,防止连接泄露。
public class DestroyConnectionThread extends Thread {
......
public void run() {
initedLatch.countDown();
for (; ; ) {
// 从前面开始删除
try {
if (closed || closing) {
break;
}
if (timeBetweenEvictionRunsMillis > 0) {
Thread.sleep(timeBetweenEvictionRunsMillis);
} else {
Thread.sleep(1000); //
}
......
destroyTask.run();
} catch (InterruptedException e) {
break;
}
}
}
}
public class DestroyTask implements Runnable {
public DestroyTask() {
}
@Override
public void run() {
shrink(true, keepAlive);
if (isRemoveAbandoned()) {
removeAbandoned();
}
}
}
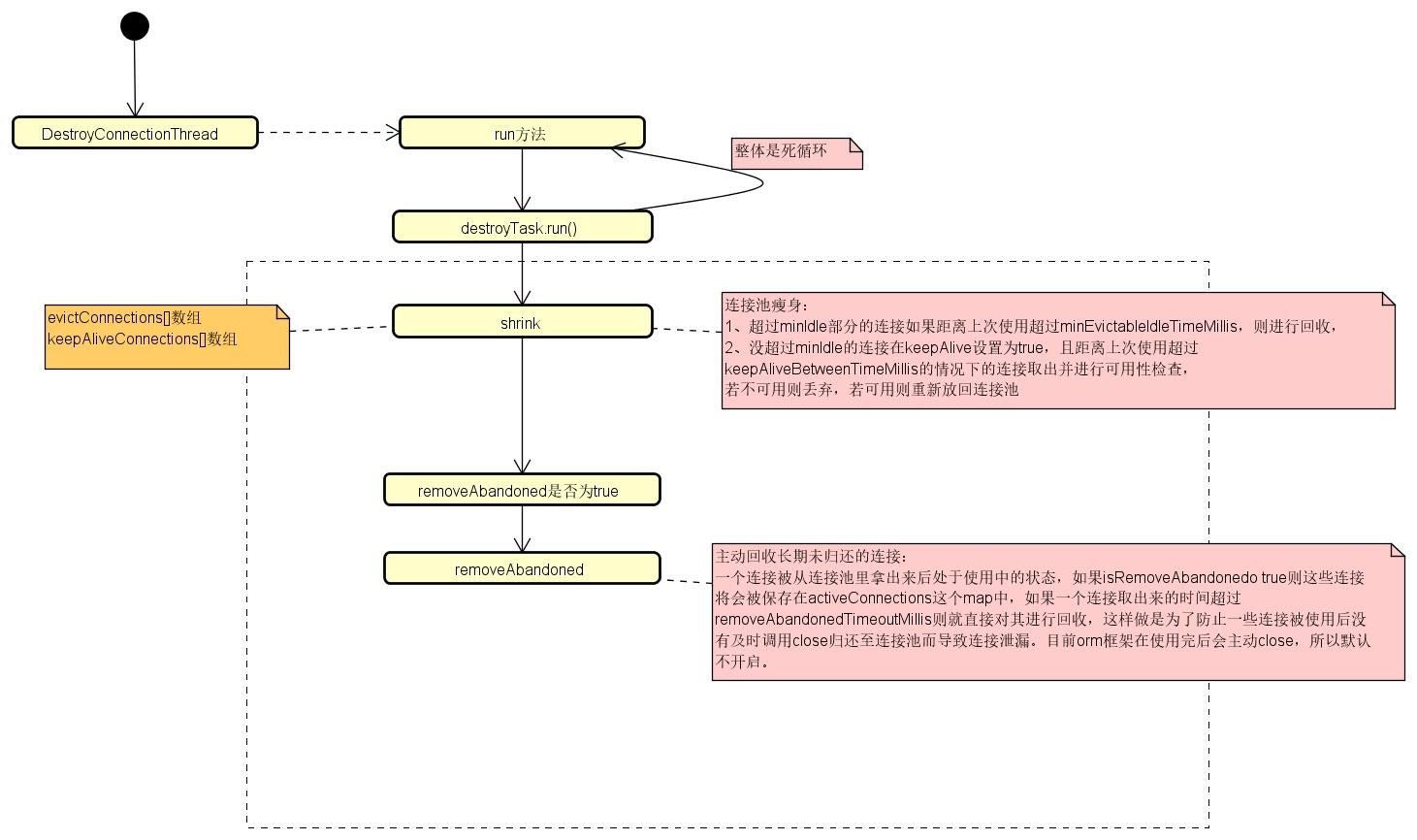
1、连接池瘦身
从连接池数组connections中获取每一个连接,如果距上次连接使用超过了设置的时间,则放入保活数组keepAliveConnections中,待后续处理;
选择指定个数连接(即要清理的连接个数:现有连接数 - 最小连接数),然后将其放入待回收数组evictConnections中,这里有不同的处理分支,如果不需要检查时间,则只要没有到达回收上限,则一直向回收数组evictConnections中添加连接;如果需要验证时间,则需要判断超时时间和连接空闲时间。
(1)保活判断1:如果存在致命错误且最近一次致命错误发生时间大于最近一次连接时间,则将连接放入保活数组keepAliveConnections;
(2)回收判断:如果“保活判断1”不成立,则判断超时时间,即当前时间与连接事件的间隔如果大于超时时间,则需要回收;判断闲置时间(即当前时间与最后活跃时间差)如果大于等于最小可驱逐空闲时间毫秒,同时没有达到可驱逐上线或空闲时间已经超过了最大的可驱逐空闲时间,则也需要回收;如果需要回收,会将连接放入evictConnections数组
(3)保活判断2:在需要保活且连接空闲时间超过了设置的保活间隔,也将其放入保活数组keepAliveConnections
如果存在需要保活和回收的连接,则将连接数组connections中需要保活和回收的连接先移除。具体的做法是:移除方法是采用一个缓冲数组shrinkBuffer,将可用的连接先放入shrinkBuffer中,然后将连接数组connections全部置位null,然后再将缓存数组shrinkBuffer中的连接copy到连接数组connections中,最后清空缓存数组shrinkBuffer,这样连接数组connections中保留的都是正常的连接。
同时判断现有正常的连接数量+活跃的连接数量是否小于最小连接数,如果小于,则说明需要填充连接
连接回收:如果存在需要回收的连接,则调用JdbcUtils.close(connection)关闭,然后更新销毁的连接数destroyCount,最终将回收数组清空
保活处理:如果存在需要保活的连接,则调用validateConnection验证连接可用性,如果可用,则将其重新放入连接数组connections中,如果没有放进去,则需要将线程回收。
public void shrink(boolean checkTime, boolean keepAlive) {
final Lock lock = this.lock;
try {
lock.lockInterruptibly();
} catch (InterruptedException e) {
return;
}
boolean needFill = false;
int evictCount = 0;
int keepAliveCount = 0;
int fatalErrorIncrement = fatalErrorCount - fatalErrorCountLastShrink;
fatalErrorCountLastShrink = fatalErrorCount;
try {
......
for (int i = 0; i < poolingCount; ++i) {
DruidConnectionHolder connection = connections[i];
// 如果存在致命错误且最近一次致命错误发生时间大于最近一次连接事件,则将连接放入保活数组keepAliveConnections
if ((onFatalError || fatalErrorIncrement > 0) && (lastFatalErrorTimeMillis > connection.connectTimeMillis)) {
keepAliveConnections[keepAliveCount++] = connection;
connectionsFlag[i] = true;
continue;
}
if (checkTime) {
// 当前时间 - 连接时间的间隔如果 大于 超时时间,则需要回收
if (phyTimeoutMillis > 0) {
long phyConnectTimeMillis = currentTimeMillis - connection.connectTimeMillis;
if (phyConnectTimeMillis > phyTimeoutMillis) {
evictConnections[evictCount++] = connection;
connectionsFlag[i] = true;
continue;
}
}
// 判断闲置时间:即当前时间与最后活跃时间差,如果小于最小可驱逐空闲时间,则不需要处理
long idleMillis = currentTimeMillis - connection.lastActiveTimeMillis;
if (idleMillis < minEvictableIdleTimeMillis
&& idleMillis < keepAliveBetweenTimeMillis
) {
break;
}
// 判断闲置时间:即当前时间与最后活跃时间差,如果大于等于最小可驱逐空闲时间毫秒
if (idleMillis >= minEvictableIdleTimeMillis) {
// 如果还没有达到回收上限,则将该连接放在回收数组evictConnections
if (checkTime && i < checkCount) {
evictConnections[evictCount++] = connection;
connectionsFlag[i] = true;
continue;
}
// 如果空闲时间超过了最大可驱逐时间,也将该连接放入回收数组evictConnections
else if (idleMillis > maxEvictableIdleTimeMillis) {
evictConnections[evictCount++] = connection;
connectionsFlag[i] = true;
continue;
}
}
// 如果需要保活,且连接空闲时间超过了设置的保活间隔,则将其放入保活数组keepAliveConnections
if (keepAlive && idleMillis >= keepAliveBetweenTimeMillis) {
keepAliveConnections[keepAliveCount++] = connection;
connectionsFlag[i] = true;
}
} else {
if (i < checkCount) {
evictConnections[evictCount++] = connection;
connectionsFlag[i] = true;
} else {
break;
}
}
}
// 如果存在需要保活和回收的连接,则将连接数组connections中需要保活和回收的连接先移除
// 移除方法是采用一个缓冲数组shrinkBuffer,将可用的连接先放入shrinkBuffer中,
// 然后将连接数组connections全部置位null,然后再将缓存数组shrinkBuffer中的连接copy到连接数组connections中,
// 最后清空缓存数组shrinkBuffer
int removeCount = evictCount + keepAliveCount;
if (removeCount > 0) {
int remaining = 0;
for (int i = 0; i < connections.length; i++) {
if (!connectionsFlag[i]) {
shrinkBuffer[remaining++] = connections[i];
}
}
Arrays.fill(connections, 0, poolingCount, null);
System.arraycopy(shrinkBuffer, 0, connections, 0, remaining);
Arrays.fill(shrinkBuffer, 0, remaining, null);
poolingCount -= removeCount;
}
keepAliveCheckCount += keepAliveCount;
// 判断现有正常的连接数量+活跃的连接数量是否小于最小连接数,如果小于,则需要填充连接
if (keepAlive && poolingCount + activeCount < minIdle) {
needFill = true;
}
} finally {
lock.unlock();
}
// 连接回收
if (evictCount > 0) {
for (int i = 0; i < evictCount; ++i) {
DruidConnectionHolder item = evictConnections[i];
Connection connection = item.getConnection();
JdbcUtils.close(connection);
destroyCountUpdater.incrementAndGet(this);
}
Arrays.fill(evictConnections, null);
}
// 连接保活
if (keepAliveCount > 0) {
// keep order
for (int i = keepAliveCount - 1; i >= 0; --i) {
DruidConnectionHolder holder = keepAliveConnections[i];
Connection connection = holder.getConnection();
holder.incrementKeepAliveCheckCount();
boolean validate = false;
try {
// 验证连接是否可用
this.validateConnection(connection);
validate = true;
} catch (Throwable error) {
keepAliveCheckErrorLast = error;
keepAliveCheckErrorCountUpdater.incrementAndGet(this);
if (LOG.isDebugEnabled()) {
LOG.debug("keepAliveErr", error);
}
}
boolean discard = !validate;
// 如果可用,则将其重新放入连接数组connections中,如果没有放进去,则需要将连接回收
if (validate) {
holder.lastKeepTimeMillis = System.currentTimeMillis();
boolean putOk = put(holder, 0L, true);
if (!putOk) {
discard = true;
}
}
// 连接回收
if (discard) {
try {
connection.close();
} catch (Exception error) {
discardErrorLast = error;
discardErrorCountUpdater.incrementAndGet(DruidDataSource.this);
if (LOG.isErrorEnabled()) {
LOG.error("discard connection error", error);
}
}
if (holder.socket != null) {
try {
holder.socket.close();
} catch (Exception error) {
discardErrorLast = error;
discardErrorCountUpdater.incrementAndGet(DruidDataSource.this);
if (LOG.isErrorEnabled()) {
LOG.error("discard connection error", error);
}
}
}
lock.lock();
try {
holder.discard = true;
discardCount++;
if (activeCount + poolingCount <= minIdle) {
emptySignal();
}
} finally {
lock.unlock();
}
}
}
this.getDataSourceStat().addKeepAliveCheckCount(keepAliveCount);
Arrays.fill(keepAliveConnections, null);
}
if (needFill) {
lock.lock();
try {
int fillCount = minIdle - (activeCount + poolingCount + createTaskCount);
for (int i = 0; i < fillCount; ++i) {
emptySignal();
}
} finally {
lock.unlock();
}
} else if (onFatalError || fatalErrorIncrement > 0) {
lock.lock();
try {
emptySignal();
} finally {
lock.unlock();
}
}
}
2、移除长期未归还的连接
循环所有活跃连接,如果连接正在运行,则不处理,否则判断连接时间距当前时间是否已经超过了设置的超时时间,如果超过则需要回收,这里是先将该连接从活跃连接Map中移除,然后放入待回收连接集合abandonedList。
然后循环待回收连接集合,关闭连接,并设置连接状态为已被移除。
public int removeAbandoned() {
int removeCount = 0;
long currrentNanos = System.nanoTime();
List<DruidPooledConnection> abandonedList = new ArrayList<DruidPooledConnection>();
activeConnectionLock.lock();
try {
Iterator<DruidPooledConnection> iter = activeConnections.keySet().iterator();
for (; iter.hasNext(); ) {
DruidPooledConnection pooledConnection = iter.next();
// 连接如果正在运行,则不处理
if (pooledConnection.isRunning()) {
continue;
}
// 连接时间距当前时间已经超过了设置的超时时间,则需要回收(将该连接从活跃连接Map中移除,然后放入待回收连接集合abandonedList)
long timeMillis = (currrentNanos - pooledConnection.getConnectedTimeNano()) / (1000 * 1000);
if (timeMillis >= removeAbandonedTimeoutMillis) {
iter.remove();
pooledConnection.setTraceEnable(false);
abandonedList.add(pooledConnection);
}
}
} finally {
activeConnectionLock.unlock();
}
if (abandonedList.size() > 0) {
for (DruidPooledConnection pooledConnection : abandonedList) {
final ReentrantLock lock = pooledConnection.lock;
lock.lock();
try {
if (pooledConnection.isDisable()) {
continue;
}
} finally {
lock.unlock();
}
// 关闭连接
JdbcUtils.close(pooledConnection);
// 回收连接
pooledConnection.abandond();
removeAbandonedCount++;
removeCount++;
if (isLogAbandoned()) {
StringBuilder buf = new StringBuilder();
buf.append("abandon connection, owner thread: ");
buf.append(pooledConnection.getOwnerThread().getName());
buf.append(", connected at : ");
buf.append(pooledConnection.getConnectedTimeMillis());
buf.append(", open stackTrace\n");
StackTraceElement[] trace = pooledConnection.getConnectStackTrace();
for (int i = 0; i < trace.length; i++) {
buf.append("\tat ");
buf.append(trace[i].toString());
buf.append("\n");
}
buf.append("ownerThread current state is " + pooledConnection.getOwnerThread().getState()
+ ", current stackTrace\n");
trace = pooledConnection.getOwnerThread().getStackTrace();
for (int i = 0; i < trace.length; i++) {
buf.append("\tat ");
buf.append(trace[i].toString());
buf.append("\n");
}
LOG.error(buf.toString());
}
}
}
return removeCount;
}
五、回收连接
当客户端关闭连接时,会调用连接池的close方法,此时连接池会做连接回收。
public void close() throws SQLException {
......
// 判断拥有连接的线程是否是当前线程,如果是,则同步回收,否则调用syncClose方法异步回收
DruidAbstractDataSource dataSource = holder.getDataSource();
boolean isSameThread = this.ownerThread == Thread.currentThread();
if (!isSameThread) {
dataSource.setAsyncCloseConnectionEnable(true);
}
if (dataSource.removeAbandoned || dataSource.asyncCloseConnectionEnable) {
syncClose();
return;
}
......
}
同步回收和异步回收执行流程都一样,都是先执行过滤链,然后调用recycle()方法进行回收。
public void syncClose() throws SQLException {
lock.lock();
try {
......
// 向所有连接监听器发送连接关闭事件
for (ConnectionEventListener listener : holder.connectionEventListeners) {
listener.connectionClosed(new ConnectionEvent(this));
}
DruidAbstractDataSource dataSource = holder.getDataSource();
List<Filter> filters = dataSource.getProxyFilters();
// 使用责任链模式
if (filters.size() > 0) {
FilterChainImpl filterChain = new FilterChainImpl(dataSource);
filterChain.dataSource_recycle(this);
} else {
recycle();
}
this.disable = true;
} finally {
CLOSING_UPDATER.set(this, 0);
lock.unlock();
}
}
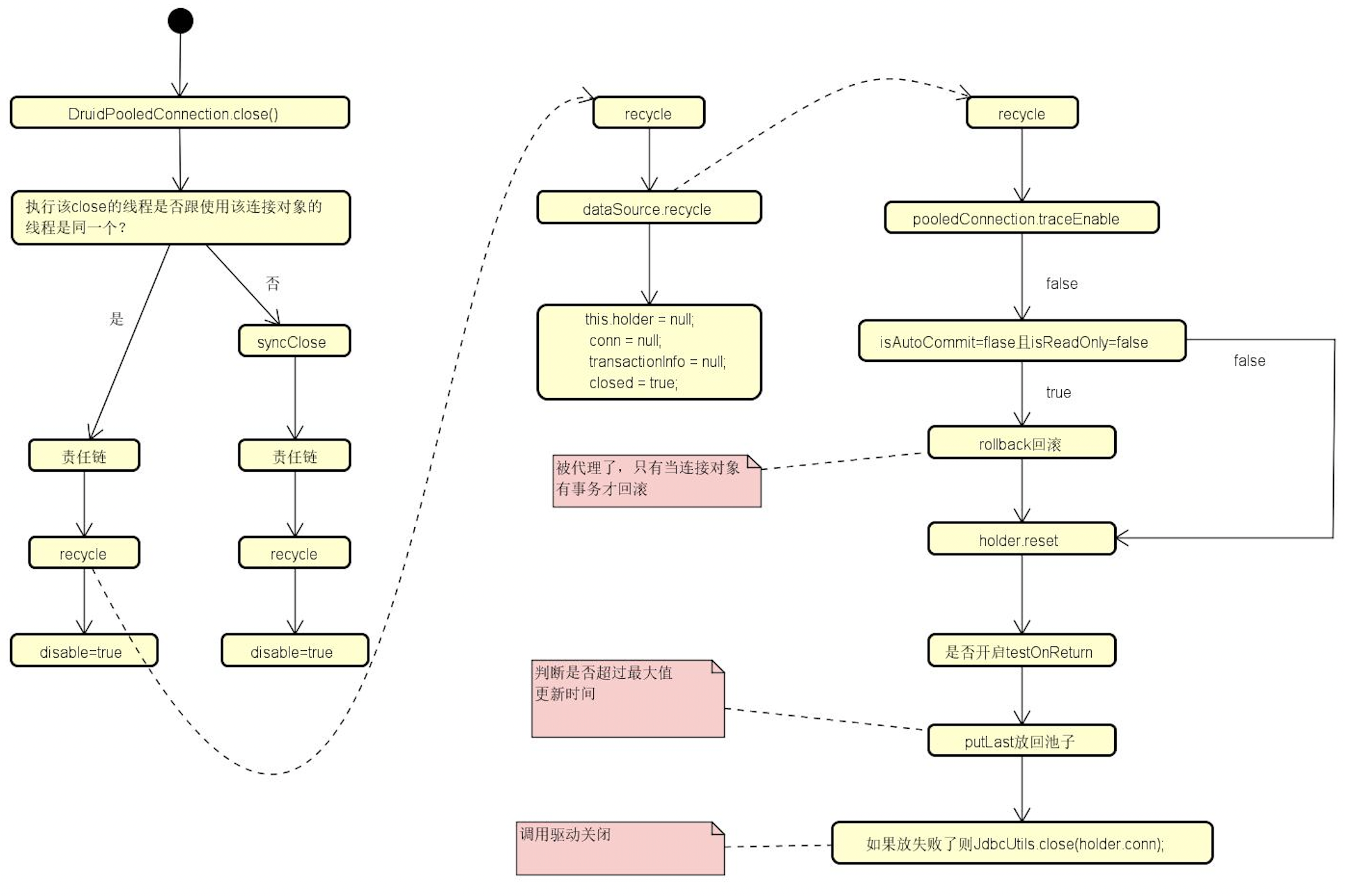
在recycle方法中,如果该连接还没有被移除,则回收连接,回收完毕后,设置当前代理连接持有的连接为空、事务信息为空、事务已关闭(代理层)。
public void recycle() throws SQLException {
if (this.disable) {
return;
}
DruidConnectionHolder holder = this.holder;
if (holder == null) {
if (dupCloseLogEnable) {
LOG.error("dup close");
}
return;
}
if (!this.abandoned) {
holder.dataSource.recycle(this);
}
this.holder = null;
conn = null;
transactionInfo = null;
closed = true;
}
如果追踪状态是开启中,则将其关闭;
调用holder.reset()将连接重置,这里会判断连接的持有线程是否是当前线程,如果是,则直接调用reset方法重置连接,否则需要加锁处理。
重置完成后,需要判断连接是否需要回收,如果设置的有连接最大使用次数,且当前连接使用次数已经超过该限制,则丢弃该物理连接;
如果物理连接已经关闭,更新连接池活跃连接数量、关闭连接数量,代理连接活跃状态;
测试连接有效性,如果无效,需要更新相关的数据;
最后将连接放入连接池数组connections的最后
总体来说,连接回收就是将代理连接释放对于物理连接的持有,重置DruidConnectionHolder的各种使用数据,移除活跃连接数组中的该连接,判断该连接的各种状态,例如是否到达最大使用次数、是否可用等等,如果状态需要丢弃,则丢弃该连接,如果不需要丢弃,则将其放入可用连接数组中,待下一次被使用。
/**
* 回收连接
*/
protected void recycle(DruidPooledConnection pooledConnection) throws SQLException {
final DruidConnectionHolder holder = pooledConnection.holder;
if (holder == null) {
LOG.warn("connectionHolder is null");
return;
}
boolean asyncCloseConnectionEnable = this.removeAbandoned || this.asyncCloseConnectionEnable;
boolean isSameThread = pooledConnection.ownerThread == Thread.currentThread();
if (logDifferentThread //
&& (!asyncCloseConnectionEnable) //
&& !isSameThread
) {
LOG.warn("get/close not same thread");
}
final Connection physicalConnection = holder.conn;
if (pooledConnection.traceEnable) {
Object oldInfo = null;
activeConnectionLock.lock();
try {
if (pooledConnection.traceEnable) {
oldInfo = activeConnections.remove(pooledConnection);
pooledConnection.traceEnable = false;
}
} finally {
activeConnectionLock.unlock();
}
if (oldInfo == null) {
if (LOG.isWarnEnabled()) {
LOG.warn("remove abandoned failed. activeConnections.size " + activeConnections.size());
}
}
}
final boolean isAutoCommit = holder.underlyingAutoCommit;
final boolean isReadOnly = holder.underlyingReadOnly;
final boolean testOnReturn = this.testOnReturn;
try {
// check need to rollback?
if ((!isAutoCommit) && (!isReadOnly)) {
pooledConnection.rollback();
}
// reset holder, restore default settings, clear warnings
if (!isSameThread) {
final ReentrantLock lock = pooledConnection.lock;
lock.lock();
try {
holder.reset();
} finally {
lock.unlock();
}
} else {
holder.reset();
}
if (holder.discard) {
return;
}
// 如果设置的有链接最大使用次数,且当前连接使用次数已经超过该限制,则丢弃该物理连接
if (phyMaxUseCount > 0 && holder.useCount >= phyMaxUseCount) {
discardConnection(holder);
return;
}
// 更新连接池活跃连接数量、关闭连接数量,代理连接活跃状态
if (physicalConnection.isClosed()) {
lock.lock();
try {
if (holder.active) {
activeCount--;
holder.active = false;
}
closeCount++;
} finally {
lock.unlock();
}
return;
}
// 测试连接有效性
if (testOnReturn) {
boolean validated = testConnectionInternal(holder, physicalConnection);
if (!validated) {
JdbcUtils.close(physicalConnection);
destroyCountUpdater.incrementAndGet(this);
lock.lock();
try {
if (holder.active) {
activeCount--;
holder.active = false;
}
closeCount++;
} finally {
lock.unlock();
}
return;
}
}
if (holder.initSchema != null) {
holder.conn.setSchema(holder.initSchema);
holder.initSchema = null;
}
if (!enable) {
discardConnection(holder);
return;
}
boolean result;
final long currentTimeMillis = System.currentTimeMillis();
if (phyTimeoutMillis > 0) {
long phyConnectTimeMillis = currentTimeMillis - holder.connectTimeMillis;
if (phyConnectTimeMillis > phyTimeoutMillis) {
discardConnection(holder);
return;
}
}
lock.lock();
try {
if (holder.active) {
activeCount--;
holder.active = false;
}
closeCount++;
// 将该连接放入连接池数组connections的最后
result = putLast(holder, currentTimeMillis);
recycleCount++;
} finally {
lock.unlock();
}
if (!result) {
JdbcUtils.close(holder.conn);
LOG.info("connection recycle failed.");
}
} catch (Throwable e) {
holder.clearStatementCache();
if (!holder.discard) {
discardConnection(holder);
holder.discard = true;
}
LOG.error("recycle error", e);
recycleErrorCountUpdater.incrementAndGet(this);
}
}
六、过滤器链
(一)过滤器与过滤器链

首先Java数据库操作过程是:datasource -》connection -》(Prepared)Statement -》 resultSet,在Druid中使用了装饰模式,分别扩展了几个类ConnectionProxyImpl、StatementProxyImpl、ResultProxyImpl,并且每个类中有上一个类的属性,即ConnectionProxyImpl有DataSourceProxyImpl的属性、StatementProxyImpl中有DataSourceProxyImpl的属性等等,以此类推,这样的结果就是后面的三个都可以拿到datasource。
Druid提供了Filter接口和过滤器链现类FilterChainImpl。
Filter接口中的各个方法即为监控使用的方法,按照方法名的下划线分割,前半部分可以看出是哪个对象的,例如connection_getAutoCommit、connection_commit、connection_xxx即为connection的方法。
public interface Filter extends Wrapper {
ConnectionProxy connection_connect(FilterChain chain, Properties info) throws SQLException;
StatementProxy connection_createStatement(FilterChain chain, ConnectionProxy connection) throws SQLException;
PreparedStatementProxy connection_prepareStatement(FilterChain chain, ConnectionProxy connection, String sql)
throws SQLException;
FilterChainImpl通过dataSource持有了所有配置的filter,因此FilterChainImpl的构造方法必须传值dataSource。
public interface FilterChain {
ConnectionProxy connection_connect(Properties info) throws SQLException;
StatementProxy connection_createStatement(ConnectionProxy connection) throws SQLException;
PreparedStatementProxy connection_prepareStatement(ConnectionProxy connection, String sql) throws SQLException;
CallableStatementProxy connection_prepareCall(ConnectionProxy connection, String sql) throws SQLException;
StatementProxy connection_createStatement(......) throws SQLException;
PreparedStatementProxy connection_prepareStatement(......) throws SQLException;
在各个ProxyImpl中对各自实现的connection、Statement、resultSet接口方法的增强,均是调用了FilterChainImpl的相关方法,比如ConnectionProxyImpl中会依次调用所有 Filter的connection_commit方法,是责任链的一种实现方法。
Druid内置了许多过滤器,例如数据库连接加解密过滤器ConfigFilter、防火墙过滤器wallFilter、监控过滤器StatFilter等等
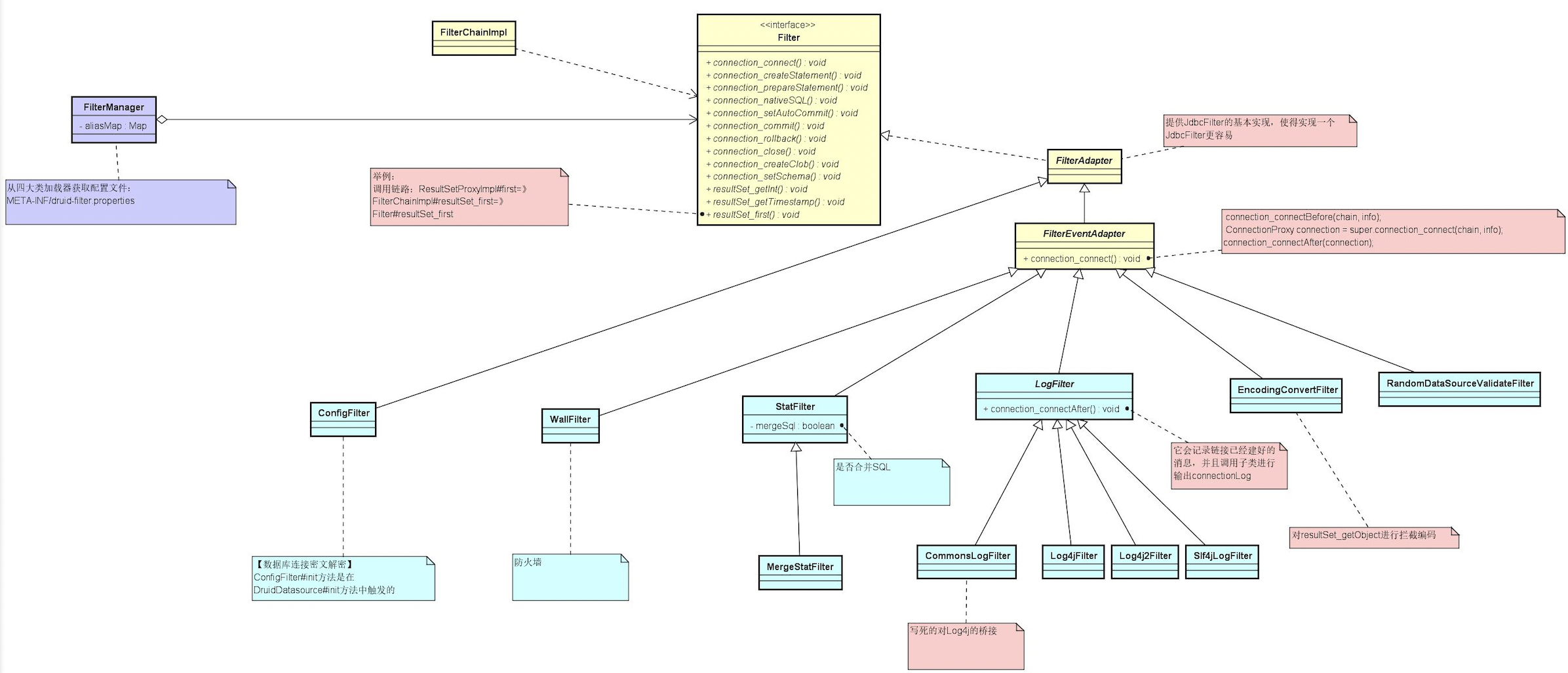
(二)初始化过滤器
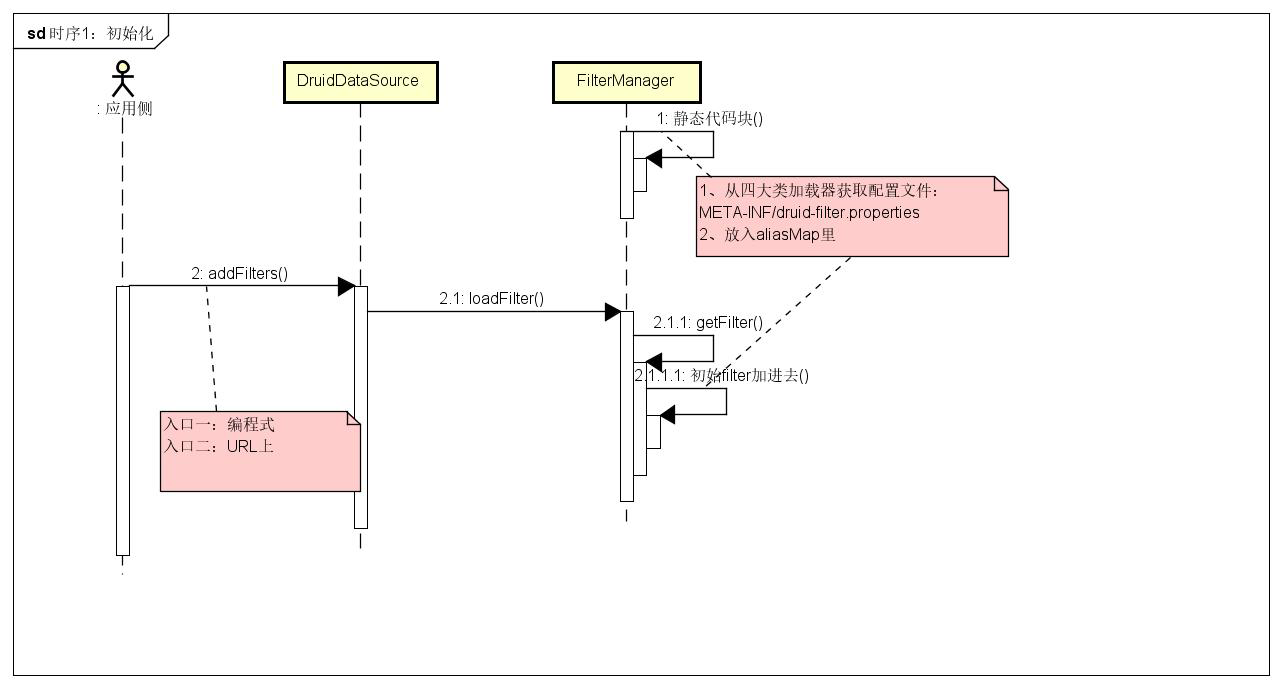
在Druid中使用过滤器主要有两种方式,一种是在jdbcUrl上设置filter,一种是获取DruidDataSource后,使用setFilters方法设置filter
// 方式一:
dataSource.setFilters("stat");
// 方式二:
dataSource.setUrl("jdbc:wrap-jdbc:filters=stat,log4j:jdbc:mock:xxx");
1、方式一
(1)入口
先看方式一,在setFilters方法中,解析传入的过滤器集合,使用逗号分割后,调用FilterManager的静态方法loadFilter加载过滤器并放入filters集合中。
public void setFilters(String filters) throws SQLException {
if (filters != null && filters.startsWith("!")) {
filters = filters.substring(1);
this.clearFilters();
}
this.addFilters(filters);
}
public void addFilters(String filters) throws SQLException {
if (filters == null || filters.length() == 0) {
return;
}
String[] filterArray = filters.split("\\,");
for (String item : filterArray) {
FilterManager.loadFilter(this.filters, item.trim());
}
}
(2)加载Druid内置过滤器配置类
在FilterManager类中还有另外一些静态代码块、静态方法和静态属性,这些静态内容会将META-INF/druid-filter.properties中的所有配置放入filterProperties中,如果这些配置以druid.filters开头,则被放入别名集合aliasMap中。
private static final ConcurrentHashMap<String, String> aliasMap = new ConcurrentHashMap<String, String>(16, 0.75f, 1);
static {
try {
Properties filterProperties = loadFilterConfig();
for (Map.Entry<Object, Object> entry : filterProperties.entrySet()) {
String key = (String) entry.getKey();
if (key.startsWith("druid.filters.")) {
String name = key.substring("druid.filters.".length());
aliasMap.put(name, (String) entry.getValue());
}
}
} catch (Throwable e) {
LOG.error("load filter config error", e);
}
}
public static Properties loadFilterConfig() throws IOException {
Properties filterProperties = new Properties();
loadFilterConfig(filterProperties, ClassLoader.getSystemClassLoader());
loadFilterConfig(filterProperties, FilterManager.class.getClassLoader());
loadFilterConfig(filterProperties, Thread.currentThread().getContextClassLoader());
return filterProperties;
}
private static void loadFilterConfig(Properties filterProperties, ClassLoader classLoader) throws IOException {
if (classLoader == null) {
return;
}
for (Enumeration<URL> e = classLoader.getResources("META-INF/druid-filter.properties"); e.hasMoreElements(); ) {
URL url = e.nextElement();
Properties property = new Properties();
InputStream is = null;
try {
is = url.openStream();
property.load(is);
} finally {
JdbcUtils.close(is);
}
filterProperties.putAll(property);
}
}
Druid中默认的过滤器类型(META-INF/druid-filter.properties中的所有配置),包括了监控、编解码、日志、防火墙等
druid.filters.default=com.alibaba.druid.filter.stat.StatFilter
druid.filters.stat=com.alibaba.druid.filter.stat.StatFilter
druid.filters.mergeStat=com.alibaba.druid.filter.stat.MergeStatFilter
druid.filters.counter=com.alibaba.druid.filter.stat.StatFilter
druid.filters.encoding=com.alibaba.druid.filter.encoding.EncodingConvertFilter
druid.filters.log4j=com.alibaba.druid.filter.logging.Log4jFilter
druid.filters.log4j2=com.alibaba.druid.filter.logging.Log4j2Filter
druid.filters.slf4j=com.alibaba.druid.filter.logging.Slf4jLogFilter
druid.filters.commonlogging=com.alibaba.druid.filter.logging.CommonsLogFilter
druid.filters.commonLogging=com.alibaba.druid.filter.logging.CommonsLogFilter
druid.filters.wall=com.alibaba.druid.wall.WallFilter
druid.filters.config=com.alibaba.druid.filter.config.ConfigFilter
druid.filters.haRandomValidator=com.alibaba.druid.pool.ha.selector.RandomDataSourceValidateFilter
druid.filters.mysql8DateTime=com.alibaba.druid.filter.mysql8datetime.MySQL8DateTimeSqlTypeFilter
(3)将过滤器实例放入过滤器集合filters中
最终调用的是FilterManager.loadFilter方法,会从alisMap中根据别名获取对应的实现类,如果有,直接通过反射创建过滤器,如果没有,则认为其是一个全限定名,直接根据全限定名反射获取。最终会将获取的过滤器实例放入数据源的过滤器集合filters中。
由此可见,虽然Druid提供了很多过滤器,但是需要我们手动开启哪些过滤器。
public static void loadFilter(List<Filter> filters, String filterName) throws SQLException {
if (filterName.length() == 0) {
return;
}
String filterClassNames = getFilter(filterName);
if (filterClassNames != null) {
for (String filterClassName : filterClassNames.split(",")) {
......
Filter filter;
try {
filter = (Filter) filterClass.newInstance();
}
......
filters.add(filter);
}
return;
}
......
Class<?> filterClass = Utils.loadClass(filterName);
try {
Filter filter = (Filter) filterClass.newInstance();
filters.add(filter);
} catch (Exception e) {
throw new SQLException("load managed jdbc driver event listener error. " + filterName, e);
}
}
(4)初始化过滤器
在初始化连接池时,会有以下代码和过滤器有关,主要包含三部分:
a、调用initFromWrapDriverUrl方法设置数据源的相关属性值,其中就包括过滤器集合;这个就是使用方式二会走的逻辑,最终也是将过滤器放入filters集合中。
b、如果存在过滤器,则调用filter.init(this)方法初始化这些过滤器;
c、同时也会调用initFromSPIServiceLoader方法使用SPI的方式加载过滤器。
public void init() throws SQLException {
......
try {
......
if (this.jdbcUrl != null) {
this.jdbcUrl = this.jdbcUrl.trim();
// 从封装的驱动url进行初始化数据源的驱动、名称、链接地址、过滤器集合
initFromWrapDriverUrl();
// 初始化连接超时时间和Socket超时时间
initFromUrlOrProperties();
}
// 初始化过滤器
for (Filter filter : filters) {
filter.init(this);
}
......
// 使用SPI加载过滤器
initFromSPIServiceLoader();
......
}
filter.init(this) 就是将过滤器初始化,这里不同的过滤器初始化方式肯定是不同的,例如下面就是监控过滤器的初始化方法
public void init(DataSourceProxy dataSource) {
lock.lock();
try {
if (this.dbType == null) {
this.dbType = DbType.of(dataSource.getDbType());
}
configFromProperties(dataSource.getConnectProperties());
configFromProperties(System.getProperties());
} finally {
lock.unlock();
}
}
2、方式二添加过滤器
在 initFromWrapDriverUrl()方法中,调用DruidDriver.parseConfig(jdbcUrl, null)解析jdbcUrl上携带的内容,赋值给DataSourceProxyConfig,如果存在过滤器,则将过滤器添加到filters集合中。再往parseConfig中看,实际上是判断jdbcUrl中是否携带了“filters=”,如果携带了,就解析对应的值,调用FilterManager.loadFilter方法创建过滤器并放入过滤器集合filters中。
FilterManager.loadFilter上面已经分析,流程完全一样。
/**
* 从封装的驱动url进行初始化数据源的驱动、名称、链接地址、过滤器集合
* @throws SQLException
*/
private void initFromWrapDriverUrl() throws SQLException {
......
// 根据 jdbcUrl 初始化代理数据源的相关配置,以及初始化过滤器
DataSourceProxyConfig config = DruidDriver.parseConfig(jdbcUrl, null);
......
// 将代理数据源配置类中的过滤器初始化,并放入数据源的的过滤器集合中
for (Filter filter : config.getFilters()) {
addFilter(filter);
}
}
public static DataSourceProxyConfig parseConfig(String url, Properties info) throws SQLException {
String restUrl = url.substring(DEFAULT_PREFIX.length());
......
// 设置代理数据源的过滤器集合
if (restUrl.startsWith(FILTERS_PREFIX)) {
int pos = restUrl.indexOf(':', FILTERS_PREFIX.length());
String filtersText = restUrl.substring(FILTERS_PREFIX.length(), pos);
for (String filterItem : filtersText.split(",")) {
// 根据过滤器名称,通过反射创建过滤器,并将其加入代理数据源的过滤器集合中
FilterManager.loadFilter(config.getFilters(), filterItem);
}
restUrl = restUrl.substring(pos + 1);
}
......
return config;
}
3、SPI方式加载过滤器
使用SPI加载Filter子类,子类需要有AutoLoad注解才会被加载,然后初始化每一个过滤器并将其放入filters集合。
private void initFromSPIServiceLoader() {
if (loadSpifilterSkip) {
return;
}
if (autoFilters == null) {
List<Filter> filters = new ArrayList<Filter>();
// 使用SPI加载Filter子类
ServiceLoader<Filter> autoFilterLoader = ServiceLoader.load(Filter.class);
for (Filter filter : autoFilterLoader) {
// 如果过滤器上使用了AutoLoad注解,则将其加入过滤器集合
AutoLoad autoLoad = filter.getClass().getAnnotation(AutoLoad.class);
if (autoLoad != null && autoLoad.value()) {
filters.add(filter);
}
}
autoFilters = filters;
}
for (Filter filter : autoFilters) {
if (LOG.isInfoEnabled()) {
LOG.info("load filter from spi :" + filter.getClass().getName());
}
addFilter(filter);
}
}
private void addFilter(Filter filter) {
boolean exists = false;
for (Filter initedFilter : this.filters) {
if (initedFilter.getClass() == filter.getClass()) {
exists = true;
break;
}
}
if (!exists) {
filter.init(this);
this.filters.add(filter);
}
}
(三)创建过滤器链
1、创建代理数据源连接
(1)创建连接入口
在上面提到,创建连接是交给单独的线程创建的,具体代码可以参考上面,这里简单列一下调用关系,根据调用关系可以看到,如果过滤器集合filters中没有数据,即没有设置过滤器,则直接调用getDriver().connect(url, info)使用驱动包创建连接;如果有过滤器,则需要处理过滤器然后生成一个连接。
最终会将物理连接封装为PhysicalConnectionInfo,然后在外层会将PhysicalConnectionInfo的相关属性赋值给DruidConnectionHolder,最终封装一个DruidPooledConnection返回给客户端。
也就是说客户端拿到的连接是DruidPooledConnection,该连接中持有DruidConnectionHolder,而DruidConnectionHolder中持有物理连接PhysicalConnectionInfo。
如果有过滤器,首先是创建一个过滤器链,然后调用filterChain.connection_connect方法返回一个连接,最后调用recycleFilterChain将创建过滤器链中变更的属性值重置。
public class CreateConnectionThread extends Thread {
public void run() {
PhysicalConnectionInfo connection = createPhysicalConnection();
}
}
public abstract class DruidAbstractDataSource {
// 创建连接
public PhysicalConnectionInfo createPhysicalConnection() throws SQLException {
conn = createPhysicalConnection(url, physicalConnectProperties);
return new PhysicalConnectionInfo(conn, connectStartNanos, connectedNanos, initedNanos, validatedNanos, variables, globalVariables);
}
// 创建连接
public Connection createPhysicalConnection(String url, Properties info) throws SQLException {
Connection conn;
if (getProxyFilters().isEmpty()) {
conn = getDriver().connect(url, info);
} else {
FilterChainImpl filterChain = createChain();
conn = filterChain.connection_connect(info);
recycleFilterChain(filterChain);
}
createCountUpdater.incrementAndGet(this);
return conn;
}
// 获取过滤器
public List<Filter> getProxyFilters() {
return filters;
}
}
(2)过滤链处理
首先创建了过滤链,然后调用过滤链的connection_connect方法,在connection_connect方法中,如果不是最后一个过滤器,则调用过滤器的connection_connect方法,如果到了最后一个过滤器,则创建一个物理连接,并将连接封装成ConnectionProxyImpl返回。
也就是说,如果存在过滤器,那么客户端拿到的连接是DruidPooledConnection,该连接中持有DruidConnectionHolder,而DruidConnectionHolder中持有物理连接ConnectionProxy。
public class FilterChainImpl implements FilterChain {
protected int pos; // 过滤器链下标
private final DataSourceProxy dataSource;
public ConnectionProxy connection_connect(Properties info) throws SQLException {
if (this.pos < filterSize) {
return nextFilter()
.connection_connect(this, info);
}
Driver driver = dataSource.getRawDriver();
String url = dataSource.getRawJdbcUrl();
Connection nativeConnection = driver.connect(url, info);
if (nativeConnection == null) {
return null;
}
return new ConnectionProxyImpl(dataSource, nativeConnection, info, dataSource.createConnectionId());
}
(3)过滤器
过滤器接口提供了connection_connect方法,在不同的过滤器中,可以根据自身需要选择前置处理、后置处理、环绕处理。
例如监控过滤器StatFilter,在获取连接的connection_connect方法中,采用了环绕处理,在调用下一个过滤器之前,先执行beforeConnect()方法进行前置处理,然后再调用过滤器链的chain.connection_connect方法执行下一个过滤器,最后调用afterConnected()执行后置处理。
public ConnectionProxy connection_connect(FilterChain chain, Properties info) throws SQLException {
ConnectionProxy connection = null;
long startNano = System.nanoTime();
long startTime = System.currentTimeMillis();
long nanoSpan;
long nowTime = System.currentTimeMillis();
// 前置处理
JdbcDataSourceStat dataSourceStat = chain.getDataSource().getDataSourceStat();
dataSourceStat.getConnectionStat().beforeConnect();
// 调用过滤器链执行下一个过滤器
try {
connection = chain.connection_connect(info);
nanoSpan = System.nanoTime() - startNano;
} catch (SQLException ex) {
dataSourceStat.getConnectionStat().connectError(ex);
throw ex;
}
// 后置处理
dataSourceStat.getConnectionStat().afterConnected(nanoSpan);
if (connection != null) {
JdbcConnectionStat.Entry statEntry = getConnectionInfo(connection);
dataSourceStat.getConnections().put(connection.getId(), statEntry);
statEntry.setConnectTime(new Date(startTime));
statEntry.setConnectTimespanNano(nanoSpan);
statEntry.setEstablishNano(System.nanoTime());
statEntry.setEstablishTime(nowTime);
statEntry.setConnectStackTrace(new Exception());
dataSourceStat.getConnectionStat().setActiveCount(dataSourceStat.getConnections().size());
}
return connection;
}
七、防火墙
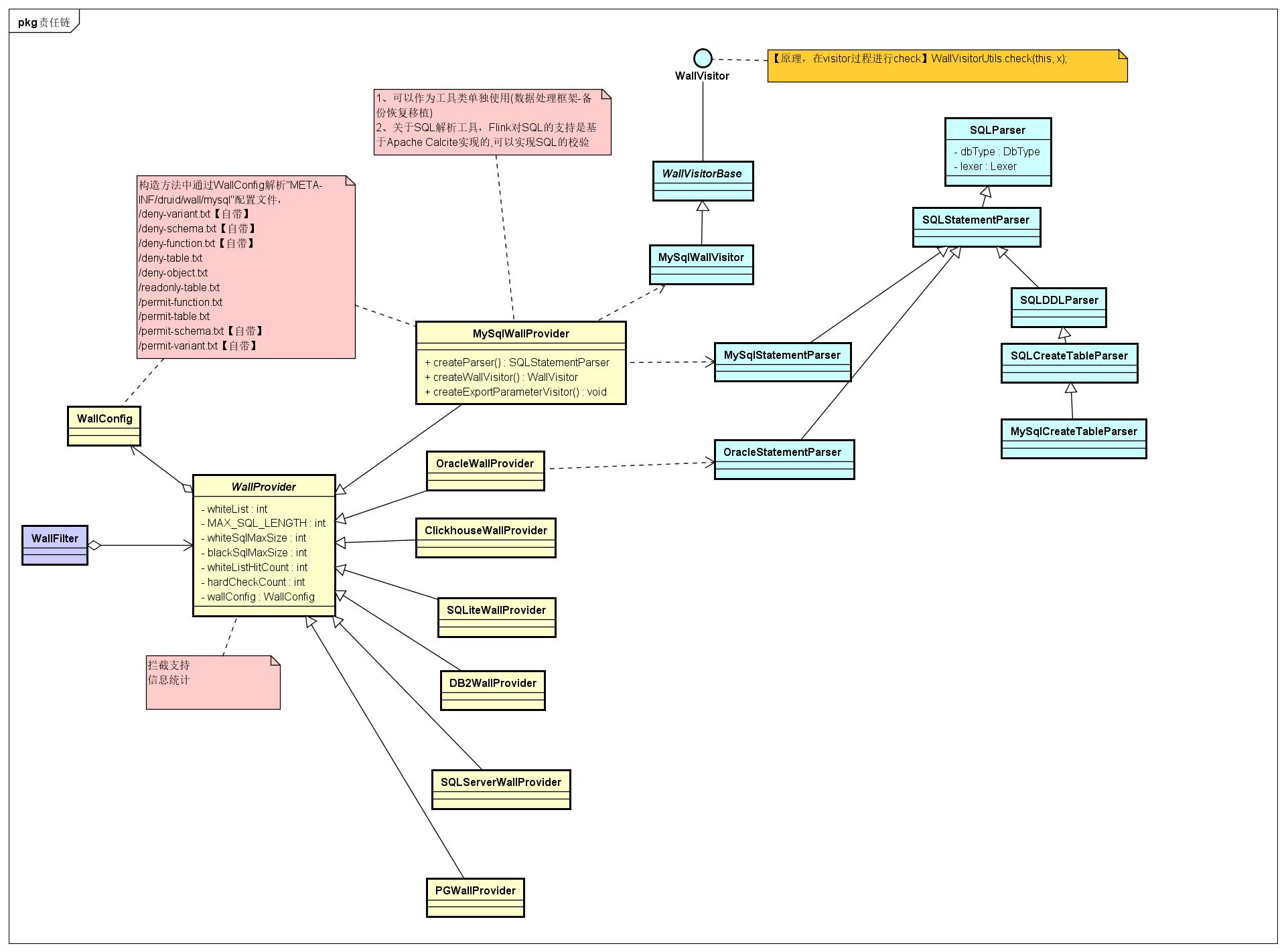
end
最后给一个从网上找的总流程图,非常清晰

-----------------------------------------------------------
---------------------------------------------
朦胧的夜 留笔~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号