
服务端调优与JVM调优
一、安装Jmeter
下载地址:http://jmeter.apache.org/download_jmeter.cgi
下载后直接进入bin目录,直接运行jmeter即可,我这里用得是mac,直接sh jmeter
1、调整语言
Options--Choose Languages--Chinese(Simple lified)
2、添加jmeter-plugin插件
下载地址:链接: https://pan.baidu.com/s/1RXD6JnT5LJx5mBvxmUf7JQ 提取码: 90ni
下载后文件为plugins-manager.jar格式,将其放入jmeter安装目录下的lib/ext目录,然后重启jmeter,即可。
3、添加jpgc插件
这个插件可以监测TPS,RT等重要指标。
选项-plugin Manager --jpgc - Standard Set,安装后重启。
二、压测
写一个简单的demo
@RequestMapping(value = "/goods/detail/nocache/{seckillId}",method = RequestMethod.GET) public TbSeckillGoods findOneNoCache(@PathVariable Integer seckillId){ TbSeckillGoods seckillGoods = seckillGoodsMapper.selectByPrimaryKey(id); }
运行:
nohup java -jar jshop.jar --spring.config.addition-location=application.yaml > shop.log 2>&1 &
这就是一个最简单的使用主键查询。
1、添加测试项(01-秒杀系统测试方案)
测试方案--添加--线程(用户)--线程组,设置测试接口名称(01-商品详情测试方案)。
测试接口--添加--取样器--HTTP请求(01-商品详情HTTP请求)
测试接口--添加--监听器--聚合报告(02-商品详情聚合报告)
测试接口--添加--监听器--查看结果树(03-商品详情结果树)
测试接口--添加--监听器--jp@gc - Transactions per Second (04-商品详情接口TPS)
测试接口--添加--监听器--jp@gc - Response Times Over Time(05-商品详情响应时间)

2、验证
点击开始,然后查看结果树中的响应数据,可以看到正常返回,验证无误。

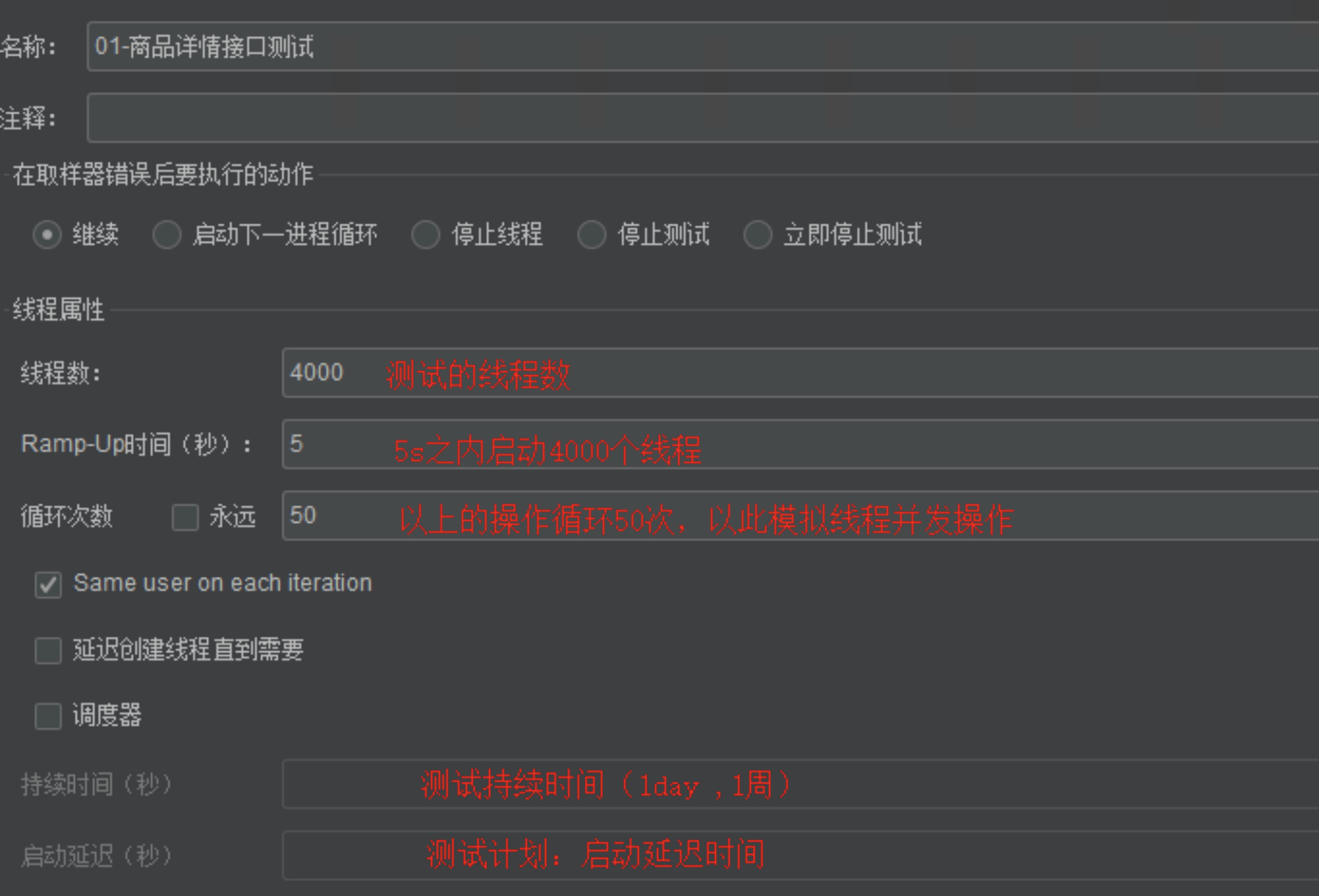
3、正式压测
修改测试方案中的线程数和循环次数,这里模拟20W个样本,线程数为4000,启动时间为5秒,循环次数为50次,这几个参数的意思是:在5秒内顺序启动4000个线程,这个操作循环50次。这50次循环是并行执行的。
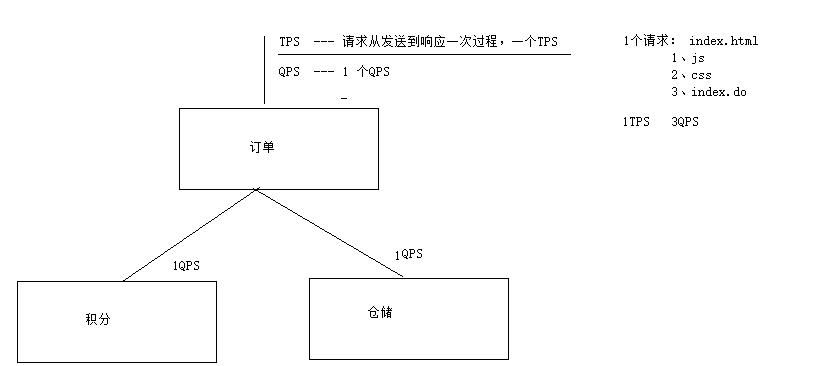
(1)TPS

如果服务的TPS存在明显的抖动,说明要么服务有问题,要么网络有问题。TPS性能曲线不能出现明显抖动(当前条件当测试演变比较稳定),查看服务问题。
这里再说明一下TPS和QPS,TPS ,QPS,吞吐量:大多数情况下,单独一个接口: TPS = QPS = 吞吐量(每秒请求数)
(2)RT

(3)聚合报告

# 样本: 测试的样本数 20w
# 平均值: 所有的请求从发送请求到请求结束所消耗的平均时间
# 中位数:50%的请求在713ms之内响应结束
# 90%百分位:90%的请求在782ms之内响应结束
# 最小值: 请求消耗的最小时间
(4)测试参数
三、服务端调优
1、分析与调优
查看线程数:pstree -p 进程号 | wc -l
pstree -p 3769 | wc -l
如果没有命令,需要安装pstree:
yum -y install psmisc
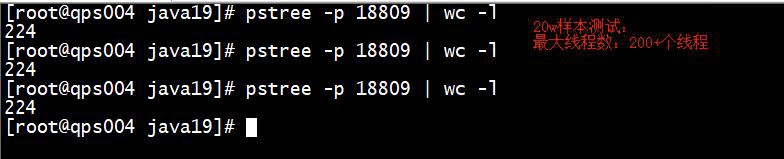
经过测试,发现服务器只产生了 200 个线程来处理业务请求,增加线程数,可以提升吞吐能力;考虑 cpu 处理能力的问题,cpu 上下文切换耗时,抢占 cpu 等待问题;考虑 cpu 性能损耗问题,使用 top 查看即可;
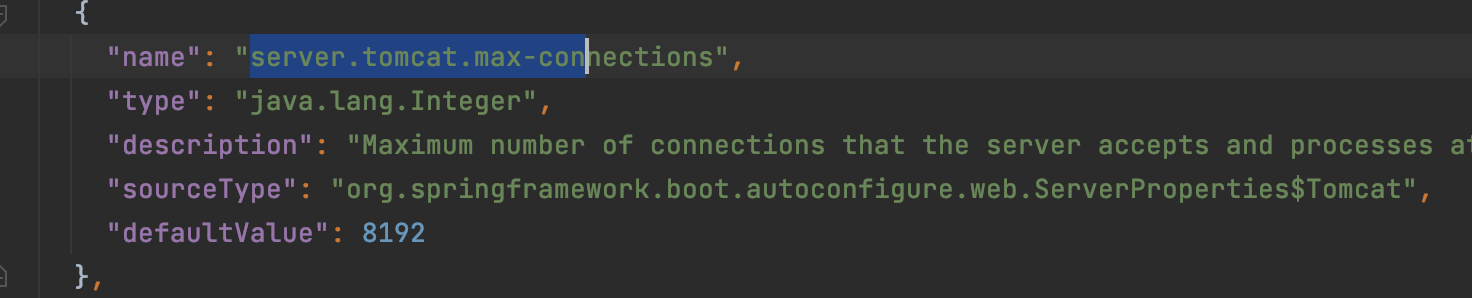
Springboot内置的Tomcat配置信息在:spring-boot-autoconfigure-2.2.5.RELEASE.jar中的spring-configuration-metadata.json中

其中比较重要的三个配置项:最大连接数、服务队列、最大线程数,三者的关系如下图所示:
首先使用等待队列接收请求,然后创建连接,然后执行业务,如果当最大连接数,等待队列都已经满了,tomcat 服务就会拒绝连接。

(1)最大连接数:
(2)服务队列

(3)最大线程数
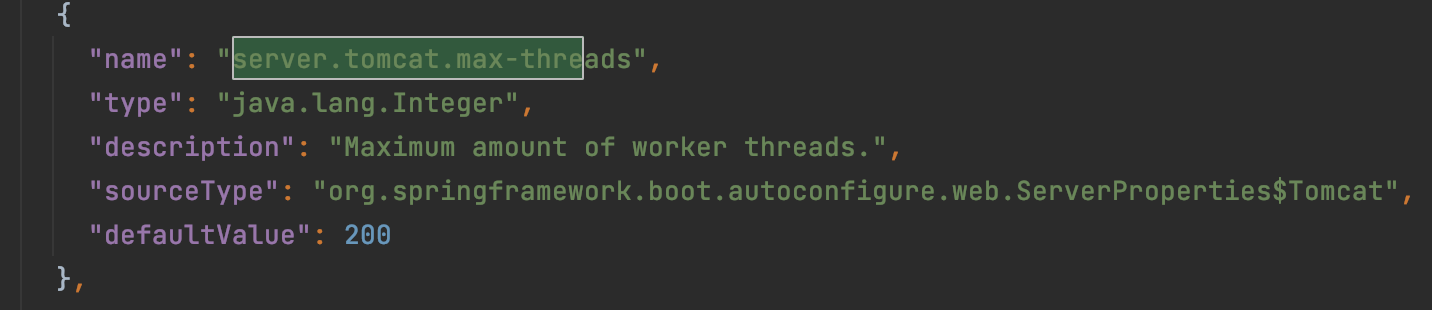
由于部署应用的服务器是4C8G,单个线程默认为200个线程,这里4个CPU,将线程数调整为800。
server: port: 9000 tomcat: # 编码格式 uri-encoding: utf-8 # 服务队列 accept-count: 1000 # 最大连接数 max-connections: 20000 # 最大线程数 max-threads: 800 # 初始化线程,应对突发流量 min-spare-threads: 10
2、验证压测

经过 20w 个样本的测试,发现 TPS 没有发生任何的变化,TPS = 2700
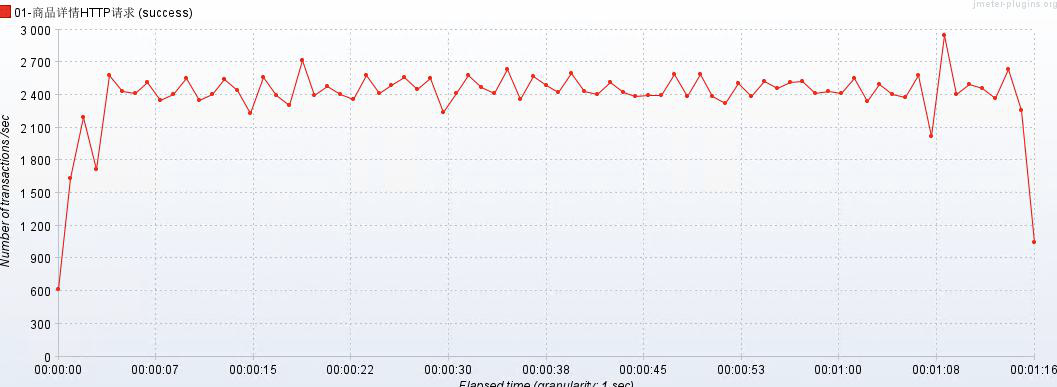
可以发现在服务器最大线程数增加了 4 倍,理论上来说,TPS 一定会增加 4 倍,但是根据实际测试结果,发现 TPS 没有任何的变化,这是因为没有执行任何业务,不是一个耗时的操作,主键查询:0-10ms 结束,无需要对一个不耗时操作进行调优。
结论:调优应该是对于耗时操作进行调优。
3、模拟耗时操作调优
模拟一个耗时操作
public TbSeckillGoods findOne(Integer id){ //直接从数据库查询 //主键查询 : cpu不耗时操作 TbSeckillGoods seckillGoods = seckillGoodsMapper.selectByPrimaryKey(id); //计算对象大小 //模拟程序耗时操作,如果方法是一个笔记耗时的操作,性能优化非常有必要的!! try { Thread.sleep(1000); LOGGER.info("模拟耗时操作,睡眠1s时间!"); LOGGER.info("对象占用jvm堆内存大小: {}", RamUsageEstimator.humanSizeOf(seckillGoods)); } catch (InterruptedException e) { e.printStackTrace(); } //返回结果 return seckillGoods; }
在未调优的情况下进行压测:没有优化之前,对于一个耗时操作来说,TPS = 200
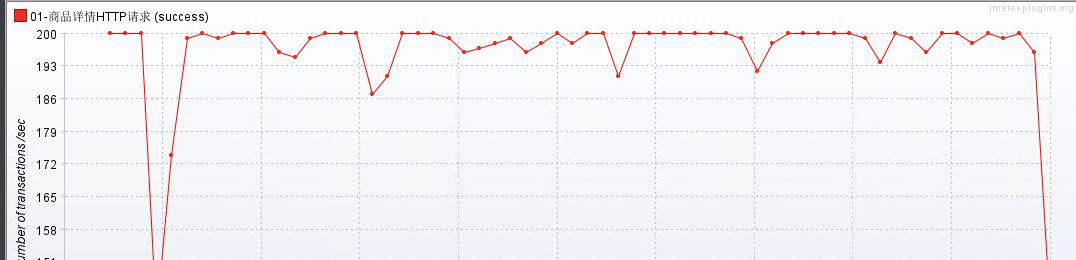
调优后压测:调优之后的 TPS 情况(线程数增加:800) -- 理论上: cpu 没有任何压力,TPS 应该会获得倍数的提升,提升 4 倍

经过测试:发现 TPS 有了 4 倍的提升,tps = 800
4、Keepalive
客户端和服务端连接的时候,为了防止频繁建立连接,释放连接,浪费资源,这样就好损耗的性能,造成性能严重下降;
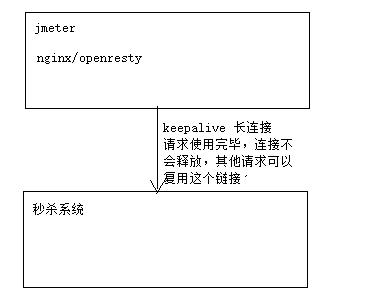
可以发现: jmeter connection : keep -alive 长连接
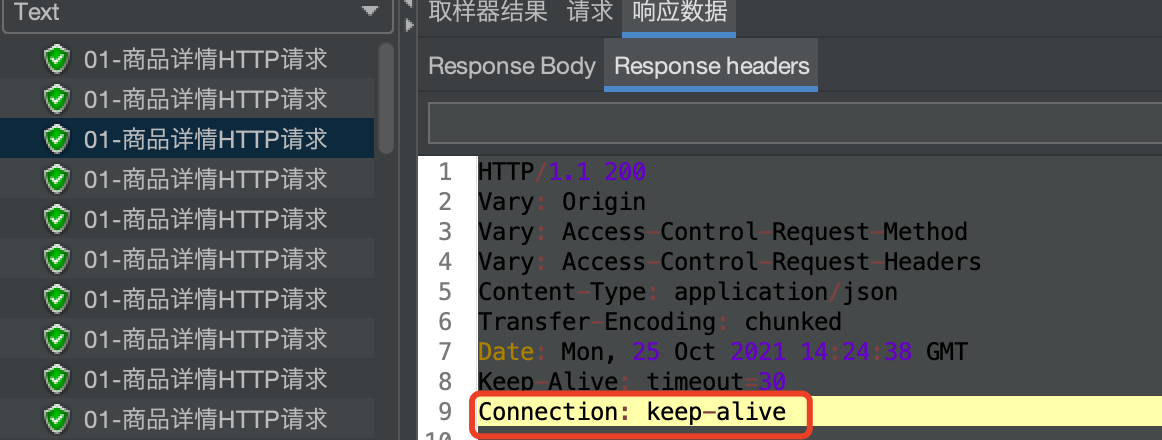
查看连接数:
netstat -anp | grep ESTABLISHED | wc -l
但是keepalive 长连接本身也会消耗大量资源,如果这些长连接不能及时释放,长连接将会占用大量资源,系统 TPS 就会上不去;因此对 keepalive 设置一个比较合理的连接数;另外: 长连接也必须及时释放,没有请求使用这个链接,这个链接一段时间必须释放;
可以在代码中定制tomcat服务器的长链接设置。
@Component public class WebServerConfig implements WebServerFactoryCustomizer<ConfigurableWebServerFactory>{ // 定制tomcat服务器 @Override public void customize(ConfigurableWebServerFactory configurableWebServerFactory) { ((TomcatServletWebServerFactory)configurableWebServerFactory).addConnectorCustomizers(new TomcatConnectorCustomizer() { // 获取tomcat连接器 @Override public void customize(Connector connector) { // 获取protocol Http11NioProtocol protocolHandler = (Http11NioProtocol) connector.getProtocolHandler(); // 如果keepalive连接30s,还没有人使用,释放此链接 protocolHandler.setKeepAliveTimeout(30000); // 允许开启最大长连接数量,4cpu,8gb protocolHandler.setMaxKeepAliveRequests(10000); } }); } }
四、线上问题分析
(一)问题分类
发现问题,解决问题 (测试时候发现一些问题,修复,调试,调优 , 更多的时候: 上线以后发现一些问题,解决问题)系统出现问题分类:
1、系统异常
CPU 占用率过高,磁盘满了,磁盘 IO 阻塞,网络流量异常等等问题
排查指令:TOP,free,dstat , pstack , vmstat , strace 获取异常信息,排查系统异常
2、业务异常
流量太大系统扛不住,耗时长,线程死锁,并发问题,频繁 full gc ,oom 等等
排查: top, jstack ,pstack , strack 日志
(二)问题排查
1、TOP命令
Top 指令监控 cpu 使用情况,根据 cpu 使用分析系统整体运行情况
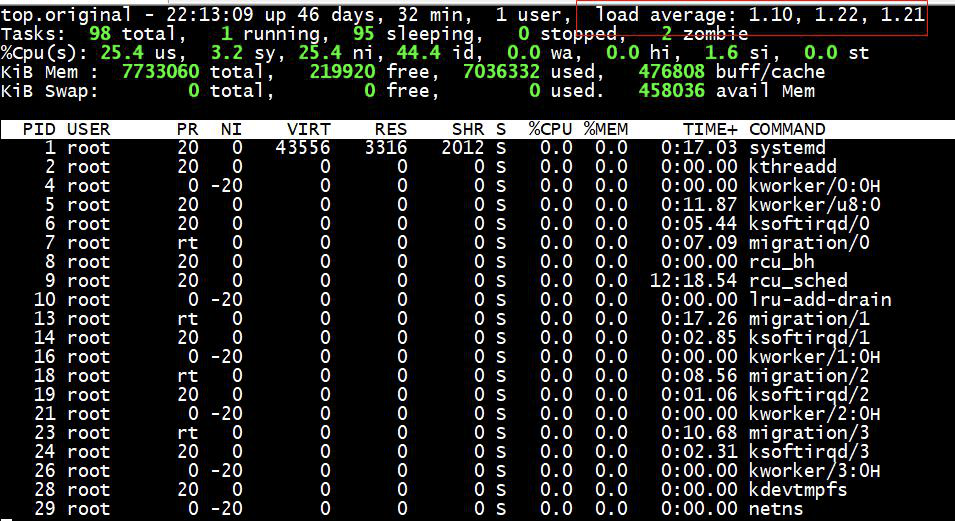
关注性能指标: load average : 1 分钟之内 cpu 平均使用率,5 分钟之内 cpu 平均使用率,15分钟之内 cpu 平均使用率;如果1分钟之内cpu使用率较高,但是5分钟或15分钟内较低,有可能是短暂的流量激增导致,可以暂时不用关心。
单核心 cpu:
1)load average < 1 , 表示 cpu 毫无压力,比较空闲,运行流畅
2)load average = 1 , 表示 cpu 刚刚被占满,没有可供提供的 cpu 资源
3)load average > 1 , 表示 cpu 已经满负荷运作,线程处于阻塞等待状态,等待 cpu资源
4)load average > 5 , 表示 cpu 已经处于超负荷运作,线程已经大面积阻塞,必须进行优化处理;
4 核心 cpu:
1)load average < 4 , 表示 cpu 毫无压力,比较空闲,运行流畅
2)load average = 4 , 表示 cpu 刚刚被占满,没有可供提供的 cpu 资源
3)load average > 4 , 表示 cpu 已经满负荷运作,线程处于阻塞等待状态,等待 cpu资源
4)load average > 10 , 表示 cpu 已经处于超负荷运作,线程已经大面积阻塞,必须进行优化处理;
2、Free命令
Free 排查线程问题:内存问题很多时候引起 cpu 较高的原因。

3、磁盘
Df 指令查看磁盘问题,查看磁盘使用情况,有时候服务出现问题,其实就是磁盘出现问题。

4、网络
Dstat 命令: 集成 vmstat , iostat , netstat ,工具完成任务,-c 查看 cpu 使用情况, -d 查看磁盘读写,-n 网络状态 -l 显示系统负载
详细的参数展示可以参考下这篇文章:http://www.yishimei.cn/network/850.html
五、JVM调优概述
(一)为什么调优
1、调优的目的
调优的目的就是为了提升项目性能,避免项目出现一些不可预知的 bug(频繁 fullgc,oom);
(1)jvm 堆内存空间对象太多(Java 线程,垃圾对象),导致内存空间被占满,程序跑不动 –性能严重下降,通过调优:及时释放内存空间
(2)垃圾回收线程太多(频繁的垃圾回收,垃圾回收线程也会占用 CPU,内存资源),必然导致程序性能下降,通过调优:防止频繁的 gc
(3)垃圾回收导致 STW (stop the world : 停止整个世界 --- 整个业务执行全部暂停),通过调优:尽可能减少 gc 次数

2、JVM 调优的本质
jvm 调优本质就是(对内存空间的调优)及时是否垃圾对象占用的内存空间,让程序性能得以提升,让其他业务线程可以使用内存空间;
3、如果把 jvm 堆内存设置的足够大(无限大),是不是不需要垃圾回收?
理论上确实可以考虑内存空间垂直扩容,解决 JVM 内存问题,但是同样存在问题:
(1)成本问题 --- 高性能服务器
(2)一旦触发垃圾回收 --- gc 时间比较长
(3)微服务架构场景下(每一个服务都是一个微小,独立的服务) --- 水平扩展
(4)寻址能力的问题(JVM 默认内存调优分配空间: 32GB,超过32G就不会进行调优):
32 位操作系统: 2~32 = 4GB 内存空间 --- Java 对象 8 字节 指针压缩 : 4GB *8 = 32GB
64 位操作系统 2~64 = 16384PB
小结: JVM 内存空间设置,必须设置一个大小合适的内存空间,不能太大,也不能设置太小;
(1)成本问题 --- 高性能服务器
(2)一旦触发垃圾回收 --- gc 时间比较长
(3)微服务架构场景下(每一个服务都是一个微小,独立的服务) --- 水平扩展
(二)JVM 调优原则
1、gc 时间足够小(堆内存设置足够小)
此原则就是让我们在设置堆内存空间时候,不要把内存空间设置的太多,防止 gc 消耗太多的时间;
2、gc 的次数足够少(堆内存空间设置的足够大)
GC 触发条件: 内存空间被占满,立即触发垃圾回收(ps,po),也就是说内存空间被占满一次,就发生一次 gc,占满多次就发生多次 gc;
3、发生 fullgc 周期足够长(最好不要发生 fullgc)
(1)metaspace 元数据空间大小设置合适 ,metaspace 一旦发生扩容,fullgc 就会发生
(2)老年代空间设置一个合理的大小,防止 fullgc
(3)尽量让垃圾对象在年轻代回收(90%)
(4)尽量防止大对象的产生,一旦大对象多了以后,就可能发生 fullgc , 甚至 OOM
(三)JVM 调优原理
1、JVM 调优本质:
回收垃圾,及时释放内存空间。在 Java 堆内存中,那些没有被引用的对象就是垃圾(高并发模式下,大量的请求在内存空间中创建了大量的对象,这些对象不会主动消失,必须进行垃圾回收,当然 Java 语言自己提供了垃圾回收器,帮助我们回收垃圾,JVM 垃圾是自动进回收的)
JVM 提供 2 种方法寻找垃圾:引用计数法和根可达算法
2、垃圾清理算法:
mark-sweep 标记清除算法、copying 拷贝算法、mark-compact 标记压缩算法。
标记清除算法:
过程:(1)使用根可达算法找到垃圾对象,对垃圾对象进行标记(仅仅是做一个标记);(2)对标记的对象做清除。
优点: 简单,高效;
缺点: 产生很多的内存碎片
copying 算法 – 一开始把内存空间一分为二,分为 2 份大小相同的内存空间,一般内存空间作为备份使用。
过程:(1)选择(寻址)存活对象;(2)把存活对象拷贝另一半空闲空间中,且是连续的空间;(3)把存活对象拷贝结束后,另一半空间中就是垃圾对象(全是垃圾对象),直接清除即可;
优点:简单,内存空间是连续的,不会存在内存碎片
缺点:内存空间的浪费
mark-compact 标记压缩算法:
过程:(1)标记垃圾(只标记,不清除);(2)再次扫描内存空间(未被标记的对象就是存活对象),找到存活对象,且把存活对象向一端移动(一端内存空间是连续的)--压缩,整理;(3)当存活对象全部被移动到一端后,另一端就是垃圾对象,直接清除即可
3、垃圾回收器
Java 语言提供了 10 种垃圾回收器:
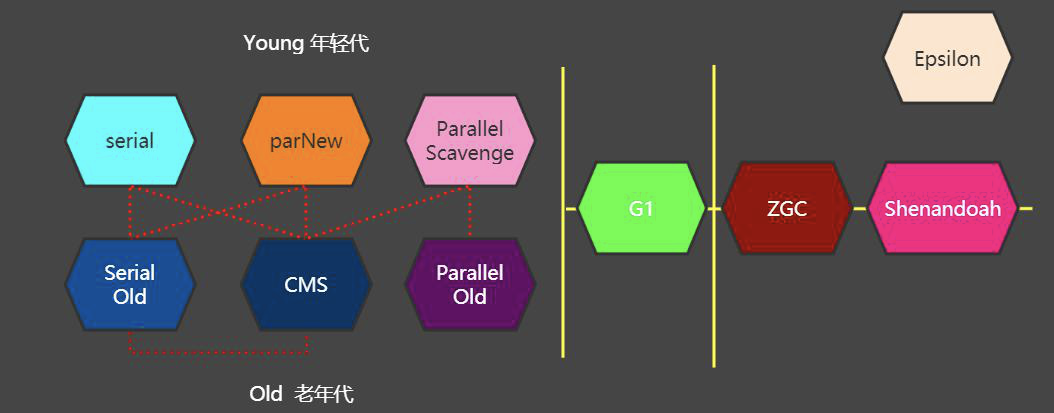
特点:
(1)Serial(年轻代) Serial Old(老年代) , parNew(年轻代) CMS(老年代) , Parallel Scavenge(年轻代) Parallel Old(老年代) 都属于物理分代模型中垃圾回收器,年轻代,老年代模型,分别都使用不同的垃圾回收器;
(2)G1 在逻辑上分代模型,使用非常方便;关于年轻代,老年代只需要使用 g1 一个垃圾回收器即可;
(3)zgc zgc 是 jdk11 新加入的垃圾回收器,在试验阶段;
(4)shenandoah openJDK 的垃圾回收器
(5)epsilon 是 debug 使用的,在调试环境下,验证 jvm 内存参数设置的可行性;
(6)Serial 和 Serial Old 串行化的垃圾回收器
(7)parNew和CMS : 响应时间优先垃圾回收器组合 (fullgc 比较多,无法避免 --- cms)
(8)parallel scavenge 和 parallel old : 吞吐量优先的垃圾回收器组合
常用垃圾回收器组合:
(1)Serail + Serial Old : 串行化的垃圾回收器,适合单核心的 cpu 服务器
(2)parNew + CMS : 响应时间有些的垃圾回收器,并行,并发垃圾
(3)Parallel Scavenge+Parallel Old : 并行垃圾回收器
(4)g1 逻辑上分代垃圾回收器
4、垃圾回收器原理
(1)Serial+Serial Old
Serial : 年轻代垃圾回收器,单线程垃圾回收器; Serial Old : 老年代的垃圾回收器,也是一个单线程的垃圾回收器,适合单核心 cpu 情况。
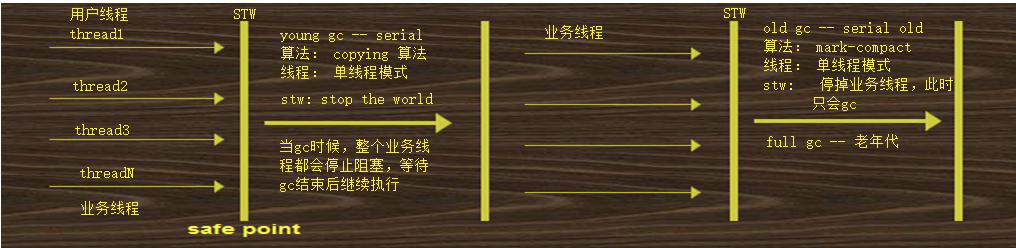
注意:1、stw : 任何垃圾回收器都无法避免 stw(stop the world : 当进行 gc 的时候,整个业务线程必须暂停),如果 stw 时间过长,或者 stw 发生次数过多,都会影响程序的性能;2、垃圾回收线程: 多线程,单线程,并发,并行
(2)Parallel Scavenge + Parallel Old
Parallel Scavenge+Parallel Old : 并行垃圾回收器,吞吐量优先的垃圾回收器组合,是 JDK8 默认垃圾回收器组合;(并行: 同一个时候,同时执行,并行;并发: 在一段时间内,多个线程抢占式交叉执行,叫做并发模式;)
PS + PO : 垃圾回收器进行垃圾回收器的时候,采用多线程模式回收垃圾

(3)parNew+CMS
parNew : 年轻代垃圾回收器,并行的垃圾回收器;
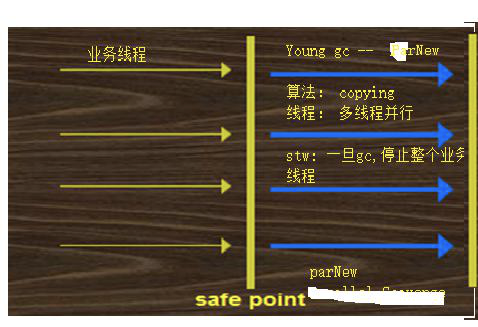
CMS : 并发垃圾回收器,响应时间优先垃圾回收器
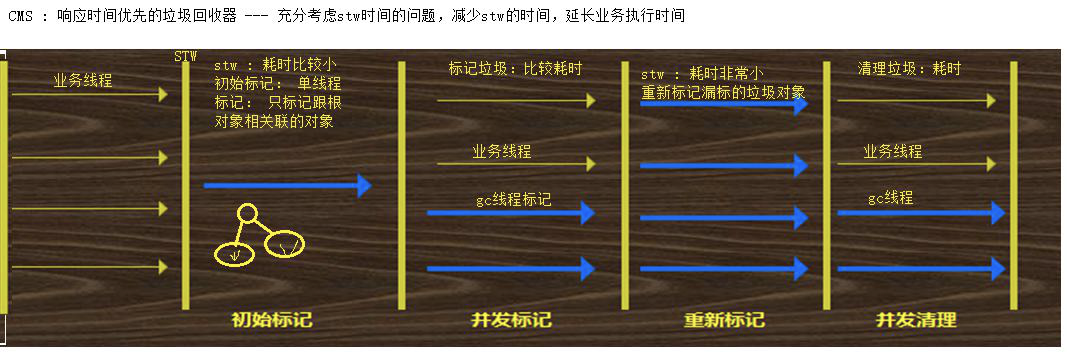
初始化标记:(寻址垃圾比较耗时)只标记跟根对象相关联的对象,因此耗时比较少,且采用单线程模式标记
并发标记: (寻址垃圾比较耗时)为了防止 gc 时候 stw, 因此使用并发模式标记垃圾,也就是说让业务线程和 gc 标记线程交叉执行;
重新标记: 重新标记漏标的对象,此时漏标对象比较少,因此耗时比较少
并发清理:(清理垃圾比较耗时) 采用并发模式清理垃圾,业务线程和清理垃圾线程交叉执行,以此减少业务线程停顿的时间;
(4)G1
G1 jdk11 成为了默认的垃圾回收器;采用了分区的思想;对内存进行逻辑上分代;采用RememberSet 集合记录每一个 region 区域
5、内存分代模型
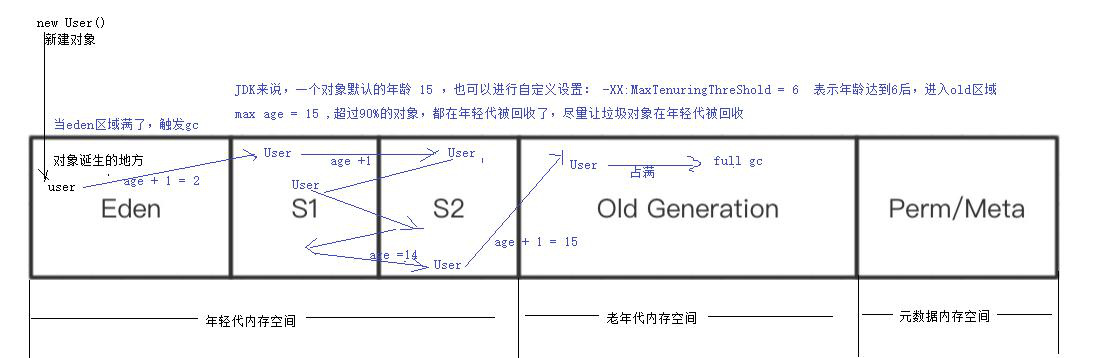
通过内存分代模型: 大多数对象都会在年轻代被回收(90%+),超过 15 次没有被回收的对象就进入 old 区域。垃圾回收器触发时机:
(1)ps + po : 当内存空间(eden,old)被占满后,触发垃圾回收器
(2)cms 垃圾回收器
jdk1.5 : 68% ,当 eden 区域被装载到 68%的时候,触发垃圾回收器
jdk1.6+ : 92% 触发垃圾回收器
六、JVM调优实战
(一)调优实战
JVM 调优的本质就是 GC(垃圾回收,及时释放掉内存,提供给其他的线程使用—并发模式),每次 GC 的时候,导致业务线程 STW, 因此必须进行综合的考量:频繁的 gc 也会导致性能下降
JVM 调优其实就是选择一个合适的垃圾回收器(在不同的场景下),设置一些合理垃圾回收参数(参考 JVM 内存模型),分配合理的内存(gc 时间少,次数少,jvm 内存既不能太大,也不能太小)。因此调优的实践本质就是设置 jvm 参数
1、典型设置
典型的参数设置: 服务器配置 —> 4cpus,8GB
1、-Xmx4000m 设置 JVM 堆内存最大值(经验值设置:3500m --- 4000m,内存大小的设置,没有一个固定值,根据业务场景实际情况,根据压力测试运行情况进行调试,在上线后,进行调试)。例如: 对象 1 占用内存 128KB;对象 2 占用内存 300KB
2、-Xms4000m 设置 JVM 初始化内存(必须和 Xmx 最大内存设置一致,防止内存抖动,损耗性能)
3、-Xmn2g 设置年轻代大小(eden ,s0 ,s1)
4、-Xss256k 设置线程堆栈大小,jdk1.5+版本线程堆栈默认 1MB, 相同内存情况下,线程堆栈越小,操作系统有能力创建更多线程,系统性能将会越好;
查看对象占用JVM堆内存大小:
RamUsageEstimator.humanSizeOf(seckillGoods)
然后调整代码的执行命令,设置上面的参数:
nohup java -Xmx4000m -Xms4000m -Xmn2g -Xss256k -jar jshop.jar --spring.config.addition-location=application.yaml > shop.log 2>&1 &

根据压力测试结果(20w 样本),发现 JVM 内存参数设置后,没有任何优化效果(变化),原因就在于在这个业务场景下没有发生频繁的 gc(gc 导致 stw ,stw 最终影响性能);那我们是根据什么指标判断 jvm 调优的参数是合适的,是否能提到调优的效果的呢:
(1)发生几次 GC ,GC 次数是否减少,是否频繁的发生 GC, 发送 GC 时间
(2)业务线程执行时间比例 (业务线程执行时间超过 95%, 5%时间 gc 时间,此时不需要调优)
(3)是否发生 fullgc (fullgc 耗时比较长,性能影响比较大,fullgc 发生次数)
(4)oom
2、GC日志
JVM 在 gc 的时候输出日志,把日志写入文件中,使用相应工具(gceasy.io)对日志进行分析,分析 jvm 堆内存调优的结果是否合适。
nohup java -Xmx4000m -Xms4000m -Xmn2g -Xss256k -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop.jar --spring.config.addition-location=application.yaml > shop.log 2>&1 &
通过 jvm 相关参数,输出 gc 日志,通过分析 gc 日志判定 gc 的参数设置是否合理;从而给调试 jvm 堆内存设置提供参考依据;
拿到 gc 日志后,可以在 gceasy.io 网站进行在线分析
(1)内存使用情况
用于展示各分代的总内存和最大使用内存。
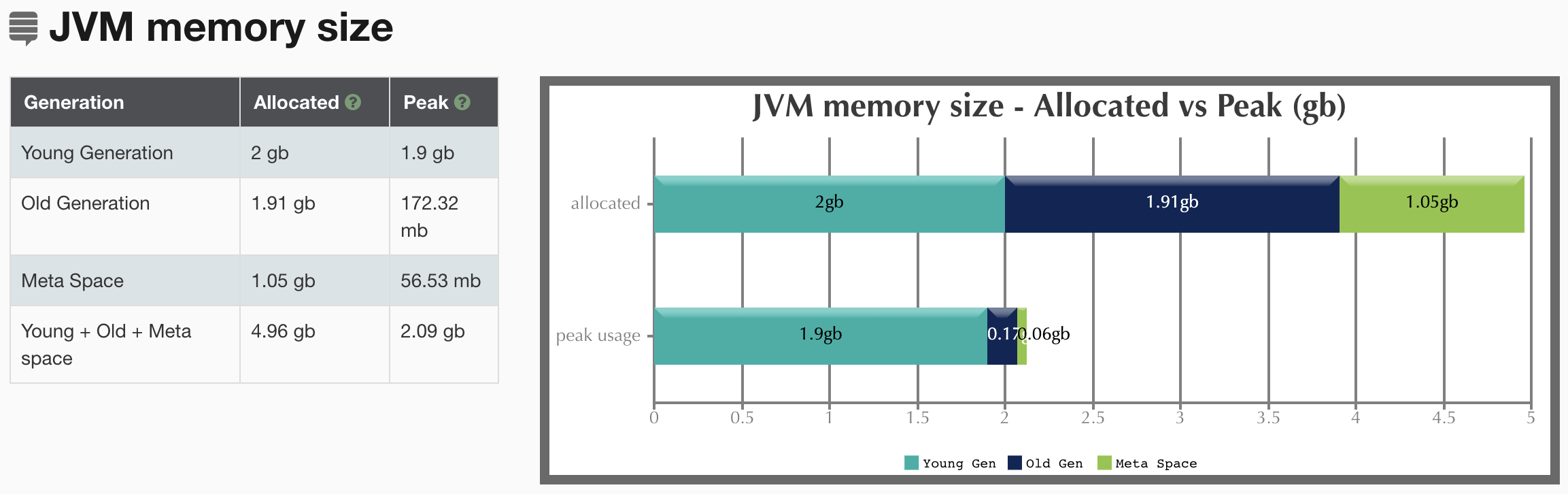
(2)执行时间对比
这个是关键的是否需要JVM调优的判断标准,如果业务时间占比大于95%,就无需调优。
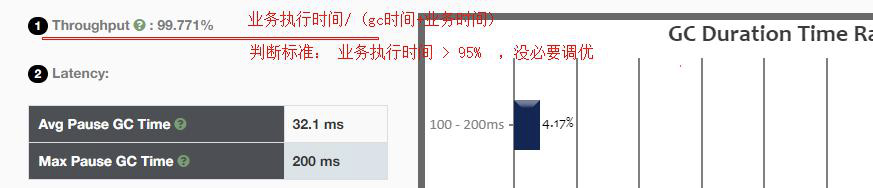
(3)GC耗时占比
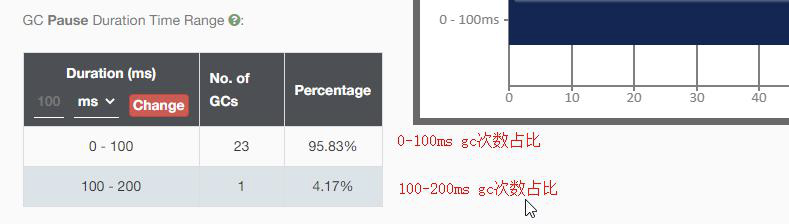
(4)发生GC的时间点和次数
根据内存分布情况,old 最大使用 157mb , 而在此时却发生了 fullgc ,很明显这是不正常的,必须进行调试,规避不正常的 fullgc
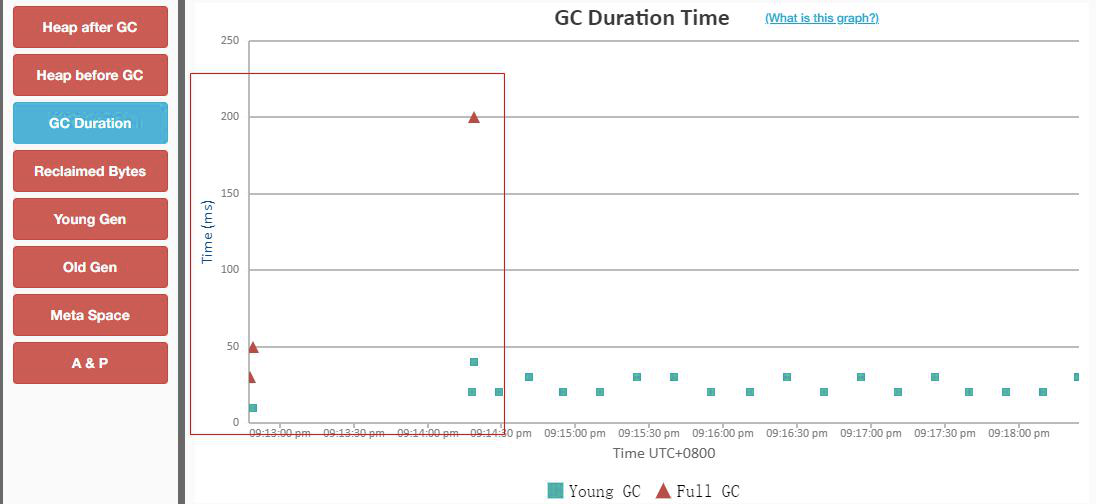
(5)GC统计

3、fullGC问题
20w 样本测试后,old 区域使用最大值 157mb, old 区域分配的内存是 1.9gb , 却发生了 full gc,这肯定不正常的,原因: metaspaceSize 云数据空间发生了扩展,导致了 fullgc 的发发生;metaspace 发生一次扩容,就会发生一次 fullgc(可以查看gc日志,可以看到元空间占用内存在变大)
jstat -gcutil 11811 jstat -gc 11811 2s 3 java -XX:+PrintFlagsFinal -version | grep MetaspaceSize

根据 metaspace 扩容阀值的大小,看出超过 20m,就会发生第一次扩容(gc日志);

Metaspace 发生了扩容(gc日志):

解决方案: 观察 gc 日志,看 metaspace 最大使用空间是多少,然后把 metaspace 空间大小设置为比这个值大即可;
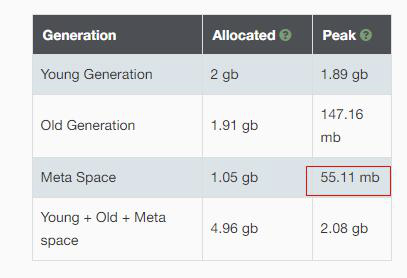
根 据 上 图 所 示 , metaspace>55.11mb ; metaspace = 256m , 完 全 够 用 的 ;-XX:MaxMetaspaceSize=500m :定义最大的元数据空间,此时如果 metaspace 装不下,就会发生 fullgc ,同时 oom;
nohup java -Xmx4000m -Xms4000m -Xmn2g -Xss256k -XX:MetaspaceSize=256m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop.jar --spring.config.addition-location=application.yaml > shop.log 2>&1 &
查看日志优化情况,看 fullgc 是否发生:
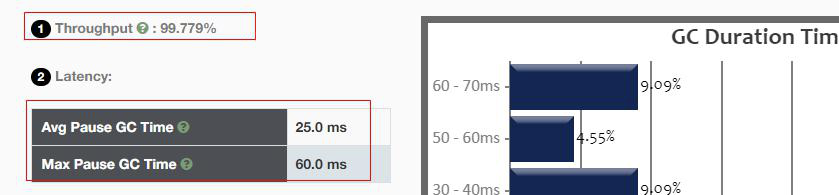
可以发现此时 fullgc 消失了,说明解决问题:

4、Yong&old
年轻代,老年代大小比例的设置根据业务情况进行灵活的设置,无非就是 yong 空间设置大些,尽量让对象在年轻被回收;或者是老年代设置大些,在一些大对象,老年代对象比较多的情况下;
设置方案: -XX:NewRatio = 4 ,年轻代 : 老年代比值 = 1:4,预测结果: 年轻代空间进一步缩小(更频繁的 yong gc – 耗时少),老年代的空间进一步增大(尽量防止 fullgc 的发生 – 不耗时)
分配结果: 1、yong : old = 1:4 (4000MB) 800MB:3200MB , yong memory 变得更小了,oldmemory 变得更大了;2、-Xmn2g 直接设置年轻代大小,剩下的就是老年代的;
修改配置:将Xmn删除(-Xmn2g),新增NewRatio配置项(-XX:NewRatio=4)
nohup java -Xmx4000m -Xms4000m -XX:NewRatio=4 -Xss256k -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop.jar --spring.config.addition-location=application.yaml > shop.log 2>&1 &

Yong gc 发生的次数更多了,但是 gc 时间更加快速了,但是总消耗的时间变多了;
但是这种也不是不能这样设置,这是一个需要权衡的结果,使用场景: 防止发生 fullgc(fullgc 有一些,消耗时间)

5、Eden & s0 & s1
尽量让对象在年轻代被回收(大多数对象都在年轻代被释放内存)官方推荐设置: eden : s0 : s1 = 8:1:1 设置方式: -XX:SurvivorRatio = 8。
(二)垃圾回收器组合
1、吞吐量优先
并行垃圾回收器:
年轻代: parNew , Parallel Scavenge
老年代: Parallel old
对于吞吐量优先的垃圾回收器: 使用常用组合: ps + po ,此组合是 jdk1.8 默认的垃圾回收器
nohup java -Xmx4000m -Xms4000m -Xmn2g -Xss256k -XX:MetaspaceSize=256m -XX:+UseParallelGC -XX:+UseParallelOldGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop.jar --spring.config.addition-location=application.yaml > shop.log 2>&1 &
2、响应时间优先
响应时间优先组合: parNew + CMS 垃圾回收器 ,响应时间优先主要是对 CMS(老年代垃圾回收器)来说的,适用于:老年代发生 fullgc 比较多的情况,且无法避免 fullgc;
-XX:+UseParNewGC : 年轻代垃圾回收器,并行的垃圾回收器
-XX:+UseConcMarkSweepGC: 老年代的垃圾回收器,并发的垃圾回收器(业务线程交叉执行)
nohup java -Xmx4000m -Xms4000m -Xmn2g -Xss256k -XX:MetaspaceSize=256m -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop.jar --spring.config.addition-location=application.yaml > shop.log 2>&1 &
3、G1 组合
XX:+UseG1GC : 表示使用 g1 垃圾回收器; 使用更加简单,逻辑上分代模型;
nohup java -Xmx4000m -Xms4000m -Xmn2g -Xss256k -XX:MetaspaceSize=256m -XX:+UseG1GC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintHeapAtGC -Xloggc:gc.log -jar jshop.jar --spring.config.addition-location=application.yaml > shop.log 2>&1 &
可以发现: 垃圾回收次数比较少的,但是总耗时比较长;
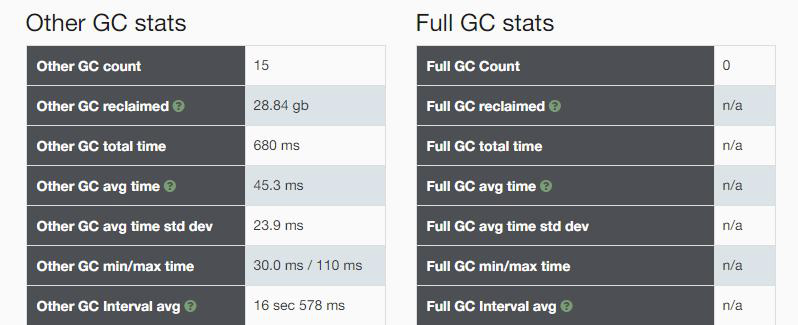
-----------------------------------------------------------
---------------------------------------------
朦胧的夜 留笔~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号