【转载 Hadoop&Spark 动手实践 2】Hadoop2.7.3 HDFS理论与动手实践
简介
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统。是根据google发表的论文翻版的。论文为GFS(Google File System)Google 文件系统(中文,英文)。
HDFS有很多特点:
① 保存多个副本,且提供容错机制,副本丢失或宕机自动恢复。默认存3份。
② 运行在廉价的机器上。
③ 适合大数据的处理。多大?多小?HDFS默认会将文件分割成block,64M为1个block。然后将block按键值对存储在HDFS上,并将键值对的映射存到内存中。如果小文件太多,那内存的负担会很重。

如上图所示,HDFS也是按照Master和Slave的结构。分NameNode、SecondaryNameNode、DataNode这几个角色。
NameNode:是Master节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间;
SecondaryNameNode:是一个小弟,分担大哥namenode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。
DataNode:Slave节点,奴隶,干活的。负责存储client发来的数据块block;执行数据块的读写操作。
热备份:b是a的热备份,如果a坏掉。那么b马上运行代替a的工作。
冷备份:b是a的冷备份,如果a坏掉。那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。
fsimage:元数据镜像文件(文件系统的目录树。)
edits:元数据的操作日志(针对文件系统做的修改操作记录)
namenode内存中存储的是=fsimage+edits。
SecondaryNameNode负责定时默认1小时,从namenode上,获取fsimage和edits来进行合并,然后再发送给namenode。减少namenode的工作量。
工作原理
写操作:

有一个文件FileA,100M大小。Client将FileA写入到HDFS上。
HDFS按默认配置。
HDFS分布在三个机架上Rack1,Rack2,Rack3。
a. Client将FileA按64M分块。分成两块,block1和Block2;
b. Client向nameNode发送写数据请求,如图蓝色虚线①------>。
c. NameNode节点,记录block信息。并返回可用的DataNode,如粉色虚线②--------->。
Block1: host2,host1,host3
Block2: host7,host8,host4
原理:
NameNode具有RackAware机架感知功能,这个可以配置。
若client为DataNode节点,那存储block时,规则为:副本1,同client的节点上;副本2,不同机架节点上;副本3,同第二个副本机架的另一个节点上;其他副本随机挑选。
若client不为DataNode节点,那存储block时,规则为:副本1,随机选择一个节点上;副本2,不同副本1,机架上;副本3,同副本2相同的另一个节点上;其他副本随机挑选。
d. client向DataNode发送block1;发送过程是以流式写入。
流式写入过程,
1>将64M的block1按64k的package划分;
2>然后将第一个package发送给host2;
3>host2接收完后,将第一个package发送给host1,同时client想host2发送第二个package;
4>host1接收完第一个package后,发送给host3,同时接收host2发来的第二个package。
5>以此类推,如图红线实线所示,直到将block1发送完毕。
6>host2,host1,host3向NameNode,host2向Client发送通知,说“消息发送完了”。如图粉红颜色实线所示。
7>client收到host2发来的消息后,向namenode发送消息,说我写完了。这样就真完成了。如图黄色粗实线
8>发送完block1后,再向host7,host8,host4发送block2,如图蓝色实线所示。
9>发送完block2后,host7,host8,host4向NameNode,host7向Client发送通知,如图浅绿色实线所示。
10>client向NameNode发送消息,说我写完了,如图黄色粗实线。。。这样就完毕了。
分析,通过写过程,我们可以了解到:
①写1T文件,我们需要3T的存储,3T的网络流量贷款。
②在执行读或写的过程中,NameNode和DataNode通过HeartBeat进行保存通信,确定DataNode活着。如果发现DataNode死掉了,就将死掉的DataNode上的数据,放到其他节点去。读取时,要读其他节点去。
③挂掉一个节点,没关系,还有其他节点可以备份;甚至,挂掉某一个机架,也没关系;其他机架上,也有备份。
读操作:

读操作就简单一些了,如图所示,client要从datanode上,读取FileA。而FileA由block1和block2组成。
那么,读操作流程为:
a. client向namenode发送读请求。
b. namenode查看Metadata信息,返回fileA的block的位置。
block1:host2,host1,host3
block2:host7,host8,host4
c. block的位置是有先后顺序的,先读block1,再读block2。而且block1去host2上读取;然后block2,去host7上读取;
上面例子中,client位于机架外,那么如果client位于机架内某个DataNode上,例如,client是host6。那么读取的时候,遵循的规律是:
优选读取本机架上的数据。
HDFS中常用到的命令
1、hadoop fs
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
hadoop fs -ls /hadoop fs -lsrhadoop fs -mkdir /user/hadoophadoop fs -put a.txt /user/hadoop/hadoop fs -get /user/hadoop/a.txt /hadoop fs -cp src dsthadoop fs -mv src dsthadoop fs -cat /user/hadoop/a.txthadoop fs -rm /user/hadoop/a.txthadoop fs -rmr /user/hadoop/a.txthadoop fs -text /user/hadoop/a.txthadoop fs -copyFromLocal localsrc dst 与hadoop fs -put功能类似。hadoop fs -moveFromLocal localsrc dst 将本地文件上传到hdfs,同时删除本地文件。 |
2、hadoop fsadmin
|
1
2
3
|
hadoop dfsadmin -reporthadoop dfsadmin -safemode enter | leave | get | waithadoop dfsadmin -setBalancerBandwidth 1000 |
3、hadoop fsck
4、start-balancer.sh
========================================================================
再来一篇更加详细的!
1、HDFS简介
HDFS(Hadoop Distributed File System)是Hadoop项目的核心子项目,是分布式计算中数据存储管理的基础,是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它所具有的高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征为海量数据提供了不怕故障的存储,为超大数据集(Large Data Set)的应用处理带来了很多便利。
Hadoop整合了众多文件系统,在其中有一个综合性的文件系统抽象,它提供了文件系统实现的各类接口,HDFS只是这个抽象文件系统的一个实例。提供了一个高层的文件系统抽象类org.apache.hadoop.fs.FileSystem,这个抽象类展示了一个分布式文件系统,并有几个具体实现,如下表1-1所示。
表1-1 Hadoop的文件系统
|
文件系统 |
URI方案 |
Java实现 (org.apache.hadoop) |
定义 |
|
Local |
file |
fs.LocalFileSystem |
支持有客户端校验和本地文件系统。带有校验和的本地系统文件在fs.RawLocalFileSystem中实现。 |
|
HDFS |
hdfs |
hdfs.DistributionFileSystem |
Hadoop的分布式文件系统。 |
|
HFTP |
hftp |
hdfs.HftpFileSystem |
支持通过HTTP方式以只读的方式访问HDFS,distcp经常用在不同的HDFS集群间复制数据。 |
|
HSFTP |
hsftp |
hdfs.HsftpFileSystem |
支持通过HTTPS方式以只读的方式访问HDFS。 |
|
HAR |
har |
fs.HarFileSystem |
构建在Hadoop文件系统之上,对文件进行归档。Hadoop归档文件主要用来减少NameNode的内存使用。 |
|
KFS |
kfs |
fs.kfs.KosmosFileSystem |
Cloudstore(其前身是Kosmos文件系统)文件系统是类似于HDFS和Google的GFS文件系统,使用C++编写。 |
|
FTP |
ftp |
fs.ftp.FtpFileSystem |
由FTP服务器支持的文件系统。 |
|
S3(本地) |
s3n |
fs.s3native.NativeS3FileSystem |
基于Amazon S3的文件系统。 |
|
S3(基于块) |
s3 |
fs.s3.NativeS3FileSystem |
基于Amazon S3的文件系统,以块格式存储解决了S3的5GB文件大小的限制。 |
Hadoop提供了许多文件系统的接口,用户可以使用URI方案选取合适的文件系统来实现交互。
2、HDFS基础概念
2.1 数据块(block)
-
HDFS(Hadoop Distributed File System)默认的最基本的存储单位是64M的数据块。
-
和普通文件系统相同的是,HDFS中的文件是被分成64M一块的数据块存储的。
-
不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间。
2.2 NameNode和DataNode
HDFS体系结构中有两类节点,一类是NameNode,又叫"元数据节点";另一类是DataNode,又叫"数据节点"。这两类节点分别承担Master和Worker具体任务的执行节点。
1)元数据节点用来管理文件系统的命名空间
-
其将所有的文件和文件夹的元数据保存在一个文件系统树中。
-
这些信息也会在硬盘上保存成以下文件:命名空间镜像(namespace image)及修改日志(edit log)
-
其还保存了一个文件包括哪些数据块,分布在哪些数据节点上。然而这些信息并不存储在硬盘上,而是在系统启动的时候从数据节点收集而成的。
2)数据节点是文件系统中真正存储数据的地方。
-
客户端(client)或者元数据信息(namenode)可以向数据节点请求写入或者读出数据块。
-
其周期性的向元数据节点回报其存储的数据块信息。
3)从元数据节点(secondary namenode)
-
从元数据节点并不是元数据节点出现问题时候的备用节点,它和元数据节点负责不同的事情。
-
其主要功能就是周期性将元数据节点的命名空间镜像文件和修改日志合并,以防日志文件过大。这点在下面会相信叙述。
-
合并过后的命名空间镜像文件也在从元数据节点保存了一份,以防元数据节点失败的时候,可以恢复。
2.3 元数据节点目录结构
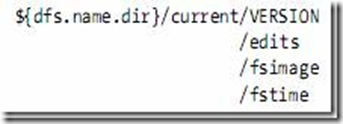
VERSION文件是java properties文件,保存了HDFS的版本号。
-
layoutVersion是一个负整数,保存了HDFS的持续化在硬盘上的数据结构的格式版本号。
-
namespaceID是文件系统的唯一标识符,是在文件系统初次格式化时生成的。
-
cTime此处为0
-
storageType表示此文件夹中保存的是元数据节点的数据结构。
namespaceID=1232737062
cTime=0
storageType=NAME_NODE
layoutVersion=-18
2.4 数据节点的目录结构
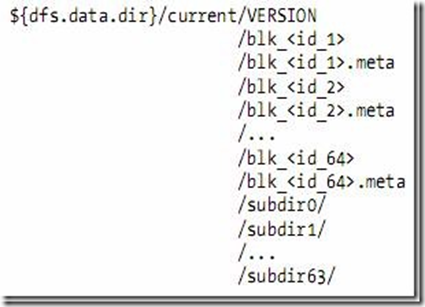
-
数据节点的VERSION文件格式如下:
namespaceID=1232737062
storageID=DS-1640411682-127.0.1.1-50010-1254997319480
cTime=0
storageType=DATA_NODE
layoutVersion=-18
-
blk_<id>保存的是HDFS的数据块,其中保存了具体的二进制数据。
-
blk_<id>.meta保存的是数据块的属性信息:版本信息,类型信息,和checksum
-
当一个目录中的数据块到达一定数量的时候,则创建子文件夹来保存数据块及数据块属性信息。
2.5 文件系统命名空间映像文件及修改日志
-
当文件系统客户端(client)进行写操作时,首先把它记录在修改日志中(edit log)
-
元数据节点在内存中保存了文件系统的元数据信息。在记录了修改日志后,元数据节点则修改内存中的数据结构。
-
每次的写操作成功之前,修改日志都会同步(sync)到文件系统。
-
fsimage文件,也即命名空间映像文件,是内存中的元数据在硬盘上的checkpoint,它是一种序列化的格式,并不能够在硬盘上直接修改。
-
同数据的机制相似,当元数据节点失败时,则最新checkpoint的元数据信息从fsimage加载到内存中,然后逐一重新执行修改日志中的操作。
-
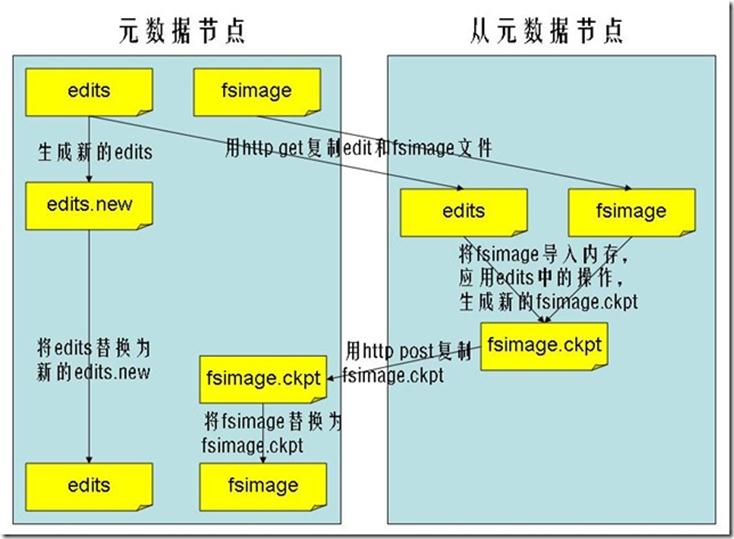
从元数据节点就是用来帮助元数据节点将内存中的元数据信息checkpoint到硬盘上的
-
checkpoint的过程如下:
-
从元数据节点通知元数据节点生成新的日志文件,以后的日志都写到新的日志文件中。
-
从元数据节点用http get从元数据节点获得fsimage文件及旧的日志文件。
-
从元数据节点将fsimage文件加载到内存中,并执行日志文件中的操作,然后生成新的fsimage文件。
-
从元数据节点奖新的fsimage文件用http post传回元数据节点
-
元数据节点可以将旧的fsimage文件及旧的日志文件,换为新的fsimage文件和新的日志文件(第一步生成的),然后更新fstime文件,写入此次checkpoint的时间。
-
这样元数据节点中的fsimage文件保存了最新的checkpoint的元数据信息,日志文件也重新开始,不会变的很大了。
-
3、HDFS体系结构
HDFS是一个主/从(Mater/Slave)体系结构,从最终用户的角度来看,它就像传统的文件系统一样,可以通过目录路径对文件执行CRUD(Create、Read、Update和Delete)操作。但由于分布式存储的性质,HDFS集群拥有一个NameNode和一些DataNode。NameNode管理文件系统的元数据,DataNode存储实际的数据。客户端通过同NameNode和DataNodes的交互访问文件系统。客户端联系NameNode以获取文件的元数据,而真正的文件I/O操作是直接和DataNode进行交互的。
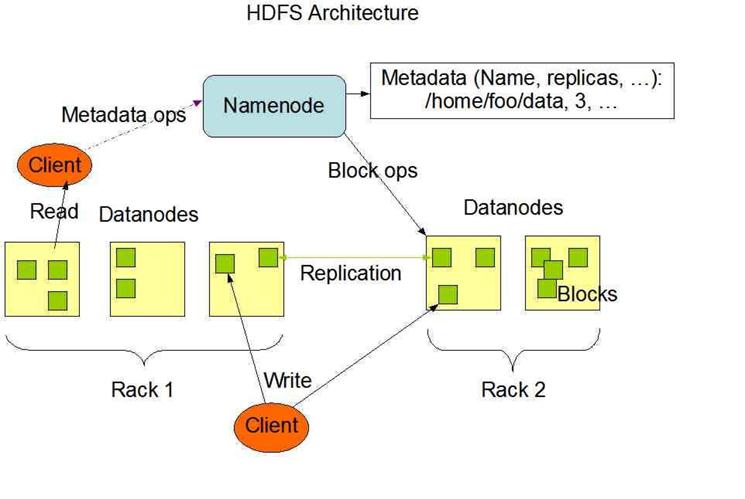
图3.1 HDFS总体结构示意图
1)NameNode、DataNode和Client
-
NameNode可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。
-
DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,同时周期性地将所有存在的Block信息发送给NameNode。
-
Client就是需要获取分布式文件系统文件的应用程序。
2)文件写入
-
Client向NameNode发起文件写入的请求。
-
NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
-
Client将文件划分为多个Block,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
3)文件读取
-
Client向NameNode发起文件读取的请求。
-
NameNode返回文件存储的DataNode的信息。
-
Client读取文件信息。
HDFS典型的部署是在一个专门的机器上运行NameNode,集群中的其他机器各运行一个DataNode;也可以在运行NameNode的机器上同时运行DataNode,或者一台机器上运行多个DataNode。一个集群只有一个NameNode的设计大大简化了系统架构。
4、HDFS的优缺点
4.1 HDFS的优点
1)处理超大文件
这里的超大文件通常是指百MB、设置数百TB大小的文件。目前在实际应用中,HDFS已经能用来存储管理PB级的数据了。
2)流式的访问数据
HDFS的设计建立在更多地响应"一次写入、多次读写"任务的基础上。这意味着一个数据集一旦由数据源生成,就会被复制分发到不同的存储节点中,然后响应各种各样的数据分析任务请求。在多数情况下,分析任务都会涉及数据集中的大部分数据,也就是说,对HDFS来说,请求读取整个数据集要比读取一条记录更加高效。
3)运行于廉价的商用机器集群上
Hadoop设计对硬件需求比较低,只须运行在低廉的商用硬件集群上,而无需昂贵的高可用性机器上。廉价的商用机也就意味着大型集群中出现节点故障情况的概率非常高。这就要求设计HDFS时要充分考虑数据的可靠性,安全性及高可用性。
4.2 HDFS的缺点
1)不适合低延迟数据访问
如果要处理一些用户要求时间比较短的低延迟应用请求,则HDFS不适合。HDFS是为了处理大型数据集分析任务的,主要是为达到高的数据吞吐量而设计的,这就可能要求以高延迟作为代价。
改进策略:对于那些有低延时要求的应用程序,HBase是一个更好的选择。通过上层数据管理项目来尽可能地弥补这个不足。在性能上有了很大的提升,它的口号就是goes real time。使用缓存或多master设计可以降低client的数据请求压力,以减少延时。还有就是对HDFS系统内部的修改,这就得权衡大吞吐量与低延时了,HDFS不是万能的银弹。
2)无法高效存储大量小文件
因为Namenode把文件系统的元数据放置在内存中,所以文件系统所能容纳的文件数目是由Namenode的内存大小来决定。一般来说,每一个文件、文件夹和Block需要占据150字节左右的空间,所以,如果你有100万个文件,每一个占据一个Block,你就至少需要300MB内存。当前来说,数百万的文件还是可行的,当扩展到数十亿时,对于当前的硬件水平来说就没法实现了。还有一个问题就是,因为Map task的数量是由splits来决定的,所以用MR处理大量的小文件时,就会产生过多的Maptask,线程管理开销将会增加作业时间。举个例子,处理10000M的文件,若每个split为1M,那就会有10000个Maptasks,会有很大的线程开销;若每个split为100M,则只有100个Maptasks,每个Maptask将会有更多的事情做,而线程的管理开销也将减小很多。
改进策略:要想让HDFS能处理好小文件,有不少方法。
-
利用SequenceFile、MapFile、Har等方式归档小文件,这个方法的原理就是把小文件归档起来管理,HBase就是基于此的。对于这种方法,如果想找回原来的小文件内容,那就必须得知道与归档文件的映射关系。
-
横向扩展,一个Hadoop集群能管理的小文件有限,那就把几个Hadoop集群拖在一个虚拟服务器后面,形成一个大的Hadoop集群。google也是这么干过的。
-
多Master设计,这个作用显而易见了。正在研发中的GFS II也要改为分布式多Master设计,还支持Master的Failover,而且Block大小改为1M,有意要调优处理小文件啊。
-
附带个Alibaba DFS的设计,也是多Master设计,它把Metadata的映射存储和管理分开了,由多个Metadata存储节点和一个查询Master节点组成。
3)不支持多用户写入及任意修改文件
在HDFS的一个文件中只有一个写入者,而且写操作只能在文件末尾完成,即只能执行追加操作。目前HDFS还不支持多个用户对同一文件的写操作,以及在文件任意位置进行修改。
5、HDFS常用操作
先说一下"hadoop fs 和hadoop dfs的区别",看两本Hadoop书上各有用到,但效果一样,求证与网络发现下面一解释比较中肯。
粗略的讲,fs是个比较抽象的层面,在分布式环境中,fs就是dfs,但在本地环境中,fs是local file system,这个时候dfs就不能用。
5.1 文件操作
1)列出HDFS文件
此处为你展示如何通过"-ls"命令列出HDFS下的文件:
hadoop fs -ls
执行结果如图5-1-1所示。在这里需要注意:在HDFS中未带参数的"-ls"命名没有返回任何值,它默认返回HDFS的"home"目录下的内容。在HDFS中,没有当前目录这样一个概念,也没有cd这个命令。

图5-1-1 列出HDFS文件
2)列出HDFS目录下某个文档中的文件
此处为你展示如何通过"-ls 文件名"命令浏览HDFS下名为"input"的文档中文件:
hadoop fs –ls input
执行结果如图5-1-2所示。

图5-1-2 列出HDFS下名为input的文档下的文件
3)上传文件到HDFS
此处为你展示如何通过"-put 文件1 文件2"命令将"Master.Hadoop"机器下的"/home/hadoop"目录下的file文件上传到HDFS上并重命名为test:
hadoop fs –put ~/file test
执行结果如图5-1-3所示。在执行"-put"时只有两种可能,即是执行成功和执行失败。在上传文件时,文件首先复制到DataNode上。只有所有的DataNode都成功接收完数据,文件上传才是成功的。其他情况(如文件上传终端等)对HDFS来说都是做了无用功。
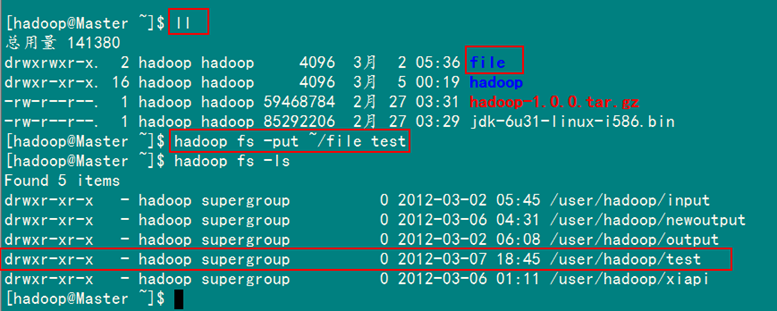
图5-1-3 成功上传file到HDFS
4)将HDFS中文件复制到本地系统中
此处为你展示如何通过"-get 文件1 文件2"命令将HDFS中的"output"文件复制到本地系统并命名为"getout"。
hadoop fs –get output getout
执行结果如图5-1-4所示。

图5-1-4 成功将HDFS中output文件复制到本地系统
备注:与"-put"命令一样,"-get"操作既可以操作文件,也可以操作目录。
5)删除HDFS下的文档
此处为你展示如何通过"-rmr 文件"命令删除HDFS下名为"newoutput"的文档:
hadoop fs –rmr newoutput
执行结果如图5-1-5所示。
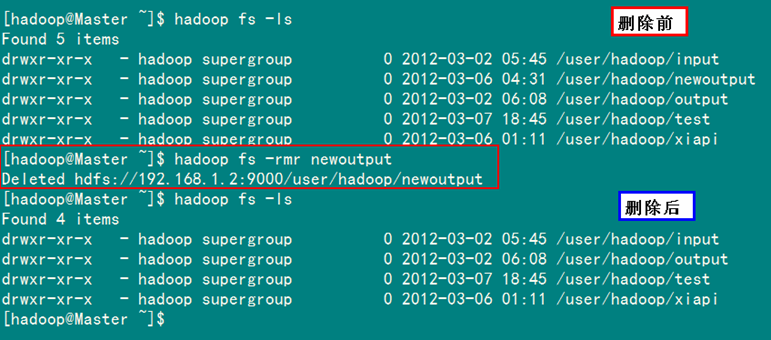
图5-1-5 成功删除HDFS下的newoutput文档
6)查看HDFS下某个文件
此处为你展示如何通过"-cat 文件"命令查看HDFS下input文件中内容:
hadoop fs -cat input/*
执行结果如图5-1-6所示。
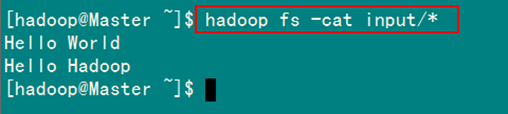
图5-1-6 HDFS下input文件的内容
"hadoop fs"的命令远不止这些,本小节介绍的命令已可以在HDFS上完成大多数常规操作。对于其他操作,可以通过"-help commandName"命令所列出的清单来进一步学习与探索。
5.2 管理与更新
1)报告HDFS的基本统计情况
此处为你展示通过"-report"命令如何查看HDFS的基本统计信息:
hadoop dfsadmin -report
执行结果如图5-2-1所示。
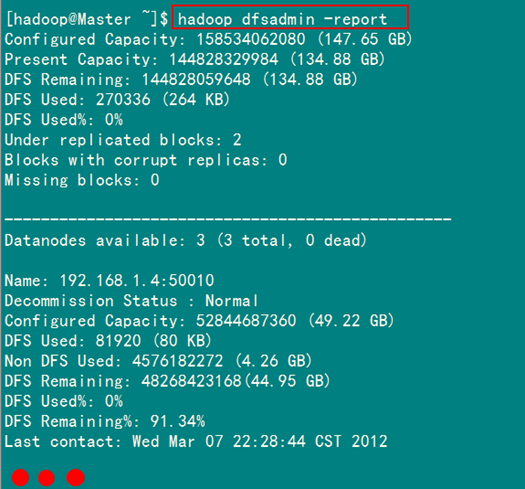
图5-2-1 HDFS基本统计信息
2)退出安全模式
NameNode在启动时会自动进入安全模式。安全模式是NameNode的一种状态,在这个阶段,文件系统不允许有任何修改。安全模式的目的是在系统启动时检查各个DataNode上数据块的有效性,同时根据策略对数据块进行必要的复制或删除,当数据块最小百分比数满足的最小副本数条件时,会自动退出安全模式。
系统显示"Name node is in safe mode",说明系统正处于安全模式,这时只需要等待17秒即可,也可以通过下面的命令退出安全模式:
hadoop dfsadmin –safemode enter
成功退出安全模式结果如图5-2-2所示。

图5-2-2 成功退出安全模式
3)进入安全模式
在必要情况下,可以通过以下命令把HDFS置于安全模式:
hadoop dfsadmin –safemode enter
执行结果如图5-2-3所示。

图5-2-3 进入HDFS安全模式
4)添加节点
可扩展性是HDFS的一个重要特性,向HDFS集群中添加节点是很容易实现的。添加一个新的DataNode节点,首先在新加节点上安装好Hadoop,要和NameNode使用相同的配置(可以直接从NameNode复制),修改"/usr/hadoop/conf/master"文件,加入NameNode主机名。然后在NameNode节点上修改"/usr/hadoop/conf/slaves"文件,加入新节点主机名,再建立到新加点无密码的SSH连接,运行启动命令:
start-all.sh
5)负载均衡
HDFS的数据在各个DataNode中的分布肯能很不均匀,尤其是在DataNode节点出现故障或新增DataNode节点时。新增数据块时NameNode对DataNode节点的选择策略也有可能导致数据块分布的不均匀。用户可以使用命令重新平衡DataNode上的数据块的分布:
start-balancer.sh
执行命令前,DataNode节点上数据分布情况如图5-2-4所示。
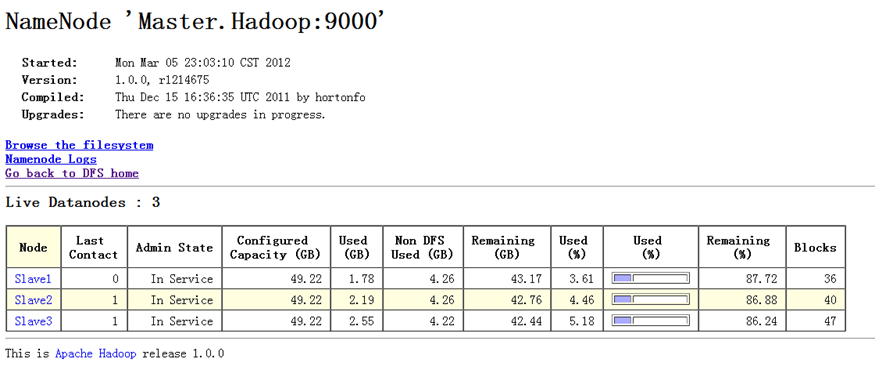
负载均衡完毕后,DataNode节点上数据的分布情况如图5-2-5所示。
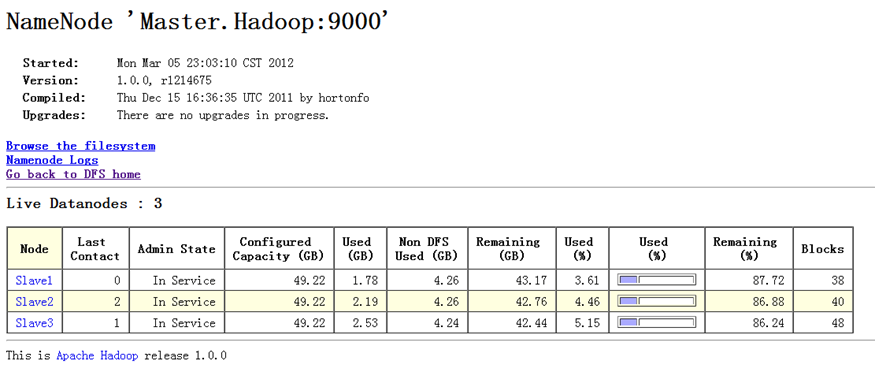
执行负载均衡命令如图5-2-6所示。

====================================================================
=============================================================
http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-common/FileSystemShell.html
- Overview
- appendToFile
- cat
- checksum
- chgrp
- chmod
- chown
- copyFromLocal
- copyToLocal
- count
- cp
- createSnapshot
- deleteSnapshot
- df
- du
- dus
- expunge
- find
- get
- getfacl
- getfattr
- getmerge
- help
- ls
- lsr
- mkdir
- moveFromLocal
- moveToLocal
- mv
- put
- renameSnapshot
- rm
- rmdir
- rmr
- setfacl
- setfattr
- setrep
- stat
- tail
- test
- text
- touchz
- truncate
- usage
Overview
The File System (FS) shell includes various shell-like commands that directly interact with the Hadoop Distributed File System (HDFS) as well as other file systems that Hadoop supports, such as Local FS, HFTP FS, S3 FS, and others. The FS shell is invoked by:
bin/hadoop fs <args>
All FS shell commands take path URIs as arguments. The URI format is scheme://authority/path. For HDFS the scheme is hdfs, and for the Local FS the scheme is file. The scheme and authority are optional. If not specified, the default scheme specified in the configuration is used. An HDFS file or directory such as /parent/child can be specified as hdfs://namenodehost/parent/child or simply as /parent/child (given that your configuration is set to point to hdfs://namenodehost).
Most of the commands in FS shell behave like corresponding Unix commands. Differences are described with each of the commands. Error information is sent to stderr and the output is sent to stdout.
If HDFS is being used, hdfs dfs is a synonym.
See the Commands Manual for generic shell options.
appendToFile
Usage: hadoop fs -appendToFile <localsrc> ... <dst>
Append single src, or multiple srcs from local file system to the destination file system. Also reads input from stdin and appends to destination file system.
- hadoop fs -appendToFile localfile /user/hadoop/hadoopfile
- hadoop fs -appendToFile localfile1 localfile2 /user/hadoop/hadoopfile
- hadoop fs -appendToFile localfile hdfs://nn.example.com/hadoop/hadoopfile
- hadoop fs -appendToFile - hdfs://nn.example.com/hadoop/hadoopfile Reads the input from stdin.
Exit Code:
Returns 0 on success and 1 on error.
cat
Usage: hadoop fs -cat URI [URI ...]
Copies source paths to stdout.
Example:
- hadoop fs -cat hdfs://nn1.example.com/file1 hdfs://nn2.example.com/file2
- hadoop fs -cat file:///file3 /user/hadoop/file4
Exit Code:
Returns 0 on success and -1 on error.
checksum
Usage: hadoop fs -checksum URI
Returns the checksum information of a file.
Example:
- hadoop fs -checksum hdfs://nn1.example.com/file1
- hadoop fs -checksum file:///etc/hosts
chgrp
Usage: hadoop fs -chgrp [-R] GROUP URI [URI ...]
Change group association of files. The user must be the owner of files, or else a super-user. Additional information is in the Permissions Guide.
Options
- The -R option will make the change recursively through the directory structure.
chmod
Usage: hadoop fs -chmod [-R] <MODE[,MODE]... | OCTALMODE> URI [URI ...]
Change the permissions of files. With -R, make the change recursively through the directory structure. The user must be the owner of the file, or else a super-user. Additional information is in the Permissions Guide.
Options
- The -R option will make the change recursively through the directory structure.
chown
Usage: hadoop fs -chown [-R] [OWNER][:[GROUP]] URI [URI ]
Change the owner of files. The user must be a super-user. Additional information is in the Permissions Guide.
Options
- The -R option will make the change recursively through the directory structure.
copyFromLocal
Usage: hadoop fs -copyFromLocal <localsrc> URI
Similar to put command, except that the source is restricted to a local file reference.
Options:
- The -f option will overwrite the destination if it already exists.
copyToLocal
Usage: hadoop fs -copyToLocal [-ignorecrc] [-crc] URI <localdst>
Similar to get command, except that the destination is restricted to a local file reference.
count
Usage: hadoop fs -count [-q] [-h] [-v] <paths>
Count the number of directories, files and bytes under the paths that match the specified file pattern. The output columns with -count are: DIR_COUNT, FILE_COUNT, CONTENT_SIZE, PATHNAME
The output columns with -count -q are: QUOTA, REMAINING_QUATA, SPACE_QUOTA, REMAINING_SPACE_QUOTA, DIR_COUNT, FILE_COUNT, CONTENT_SIZE, PATHNAME
The -h option shows sizes in human readable format.
The -v option displays a header line.
Example:
- hadoop fs -count hdfs://nn1.example.com/file1 hdfs://nn2.example.com/file2
- hadoop fs -count -q hdfs://nn1.example.com/file1
- hadoop fs -count -q -h hdfs://nn1.example.com/file1
- hdfs dfs -count -q -h -v hdfs://nn1.example.com/file1
Exit Code:
Returns 0 on success and -1 on error.
cp
Usage: hadoop fs -cp [-f] [-p | -p[topax]] URI [URI ...] <dest>
Copy files from source to destination. This command allows multiple sources as well in which case the destination must be a directory.
‘raw.*’ namespace extended attributes are preserved if (1) the source and destination filesystems support them (HDFS only), and (2) all source and destination pathnames are in the /.reserved/raw hierarchy. Determination of whether raw.* namespace xattrs are preserved is independent of the -p (preserve) flag.
Options:
- The -f option will overwrite the destination if it already exists.
- The -p option will preserve file attributes [topx] (timestamps, ownership, permission, ACL, XAttr). If -p is specified with no arg, then preserves timestamps, ownership, permission. If -pa is specified, then preserves permission also because ACL is a super-set of permission. Determination of whether raw namespace extended attributes are preserved is independent of the -p flag.
Example:
- hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -cp /user/hadoop/file1 /user/hadoop/file2 /user/hadoop/dir
Exit Code:
Returns 0 on success and -1 on error.
createSnapshot
See HDFS Snapshots Guide.
deleteSnapshot
See HDFS Snapshots Guide.
df
Usage: hadoop fs -df [-h] URI [URI ...]
Displays free space.
Options:
- The -h option will format file sizes in a “human-readable” fashion (e.g 64.0m instead of 67108864)
Example:
- hadoop dfs -df /user/hadoop/dir1
du
Usage: hadoop fs -du [-s] [-h] URI [URI ...]
Displays sizes of files and directories contained in the given directory or the length of a file in case its just a file.
Options:
- The -s option will result in an aggregate summary of file lengths being displayed, rather than the individual files.
- The -h option will format file sizes in a “human-readable” fashion (e.g 64.0m instead of 67108864)
Example:
- hadoop fs -du /user/hadoop/dir1 /user/hadoop/file1 hdfs://nn.example.com/user/hadoop/dir1
Exit Code: Returns 0 on success and -1 on error.
dus
Usage: hadoop fs -dus <args>
Displays a summary of file lengths.
Note: This command is deprecated. Instead use hadoop fs -du -s.
expunge
Usage: hadoop fs -expunge
Permanently delete files in checkpoints older than the retention threshold from trash directory, and create new checkpoint.
When checkpoint is created, recently deleted files in trash are moved under the checkpoint. Files in checkpoints older than fs.trash.checkpoint.interval will be permanently deleted on the next invocation of -expunge command.
If the file system supports the feature, users can configure to create and delete checkpoints periodically by the parameter stored as fs.trash.checkpoint.interval (in core-site.xml). This value should be smaller or equal to fs.trash.interval.
Refer to the HDFS Architecture guide for more information about trash feature of HDFS.
find
Usage: hadoop fs -find <path> ... <expression> ...
Finds all files that match the specified expression and applies selected actions to them. If no path is specified then defaults to the current working directory. If no expression is specified then defaults to -print.
The following primary expressions are recognised:
-
-name pattern
-iname patternEvaluates as true if the basename of the file matches the pattern using standard file system globbing. If -iname is used then the match is case insensitive.
-
-print
-print0Alwaysevaluates to true. Causes the current pathname to be written to standard output. If the -print0 expression is used then an ASCII NULL character is appended.
The following operators are recognised:
-
expression -a expression
expression -and expression
expression expressionLogical AND operator for joining two expressions. Returns true if both child expressions return true. Implied by the juxtaposition of two expressions and so does not need to be explicitly specified. The second expression will not be applied if the first fails.
Example:
hadoop fs -find / -name test -print
Exit Code:
Returns 0 on success and -1 on error.
get
Usage: hadoop fs -get [-ignorecrc] [-crc] <src> <localdst>
Copy files to the local file system. Files that fail the CRC check may be copied with the -ignorecrc option. Files and CRCs may be copied using the -crc option.
Example:
- hadoop fs -get /user/hadoop/file localfile
- hadoop fs -get hdfs://nn.example.com/user/hadoop/file localfile
Exit Code:
Returns 0 on success and -1 on error.
getfacl
Usage: hadoop fs -getfacl [-R] <path>
Displays the Access Control Lists (ACLs) of files and directories. If a directory has a default ACL, then getfacl also displays the default ACL.
Options:
- -R: List the ACLs of all files and directories recursively.
- path: File or directory to list.
Examples:
- hadoop fs -getfacl /file
- hadoop fs -getfacl -R /dir
Exit Code:
Returns 0 on success and non-zero on error.
getfattr
Usage: hadoop fs -getfattr [-R] -n name | -d [-e en] <path>
Displays the extended attribute names and values (if any) for a file or directory.
Options:
- -R: Recursively list the attributes for all files and directories.
- -n name: Dump the named extended attribute value.
- -d: Dump all extended attribute values associated with pathname.
- -e encoding: Encode values after retrieving them. Valid encodings are “text”, “hex”, and “base64”. Values encoded as text strings are enclosed in double quotes ("), and values encoded as hexadecimal and base64 are prefixed with 0x and 0s, respectively.
- path: The file or directory.
Examples:
- hadoop fs -getfattr -d /file
- hadoop fs -getfattr -R -n user.myAttr /dir
Exit Code:
Returns 0 on success and non-zero on error.
getmerge
Usage: hadoop fs -getmerge [-nl] <src> <localdst>
Takes a source directory and a destination file as input and concatenates files in src into the destination local file. Optionally -nl can be set to enable adding a newline character (LF) at the end of each file.
Examples:
- hadoop fs -getmerge -nl /src /opt/output.txt
- hadoop fs -getmerge -nl /src/file1.txt /src/file2.txt /output.txt
Exit Code:
Returns 0 on success and non-zero on error.
ls
Usage: hadoop fs -ls [-d] [-h] [-R] <args>
Options:
- -d: Directories are listed as plain files.
- -h: Format file sizes in a human-readable fashion (eg 64.0m instead of 67108864).
- -R: Recursively list subdirectories encountered.
For a file ls returns stat on the file with the following format:
permissions number_of_replicas userid groupid filesize modification_date modification_time filename
For a directory it returns list of its direct children as in Unix. A directory is listed as:
permissions userid groupid modification_date modification_time dirname
Files within a directory are order by filename by default.
Example:
- hadoop fs -ls /user/hadoop/file1
Exit Code:
Returns 0 on success and -1 on error.
lsr
Usage: hadoop fs -lsr <args>
Recursive version of ls.
Note: This command is deprecated. Instead use hadoop fs -ls -R
mkdir
Usage: hadoop fs -mkdir [-p] <paths>
Takes path uri’s as argument and creates directories.
Options:
- The -p option behavior is much like Unix mkdir -p, creating parent directories along the path.
Example:
- hadoop fs -mkdir /user/hadoop/dir1 /user/hadoop/dir2
- hadoop fs -mkdir hdfs://nn1.example.com/user/hadoop/dir hdfs://nn2.example.com/user/hadoop/dir
Exit Code:
Returns 0 on success and -1 on error.
moveFromLocal
Usage: hadoop fs -moveFromLocal <localsrc> <dst>
Similar to put command, except that the source localsrc is deleted after it’s copied.
moveToLocal
Usage: hadoop fs -moveToLocal [-crc] <src> <dst>
Displays a “Not implemented yet” message.
mv
Usage: hadoop fs -mv URI [URI ...] <dest>
Moves files from source to destination. This command allows multiple sources as well in which case the destination needs to be a directory. Moving files across file systems is not permitted.
Example:
- hadoop fs -mv /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -mv hdfs://nn.example.com/file1 hdfs://nn.example.com/file2 hdfs://nn.example.com/file3 hdfs://nn.example.com/dir1
Exit Code:
Returns 0 on success and -1 on error.
put
Usage: hadoop fs -put <localsrc> ... <dst>
Copy single src, or multiple srcs from local file system to the destination file system. Also reads input from stdin and writes to destination file system.
- hadoop fs -put localfile /user/hadoop/hadoopfile
- hadoop fs -put localfile1 localfile2 /user/hadoop/hadoopdir
- hadoop fs -put localfile hdfs://nn.example.com/hadoop/hadoopfile
- hadoop fs -put - hdfs://nn.example.com/hadoop/hadoopfile Reads the input from stdin.
Exit Code:
Returns 0 on success and -1 on error.
renameSnapshot
See HDFS Snapshots Guide.
rm
Usage: hadoop fs -rm [-f] [-r |-R] [-skipTrash] URI [URI ...]
Delete files specified as args.
If trash is enabled, file system instead moves the deleted file to a trash directory (given by FileSystem#getTrashRoot).
Currently, the trash feature is disabled by default. User can enable trash by setting a value greater than zero for parameter fs.trash.interval (in core-site.xml).
See expunge about deletion of files in trash.
Options:
- The -f option will not display a diagnostic message or modify the exit status to reflect an error if the file does not exist.
- The -R option deletes the directory and any content under it recursively.
- The -r option is equivalent to -R.
- The -skipTrash option will bypass trash, if enabled, and delete the specified file(s) immediately. This can be useful when it is necessary to delete files from an over-quota directory.
Example:
- hadoop fs -rm hdfs://nn.example.com/file /user/hadoop/emptydir
Exit Code:
Returns 0 on success and -1 on error.
rmdir
Usage: hadoop fs -rmdir [--ignore-fail-on-non-empty] URI [URI ...]
Delete a directory.
Options:
- --ignore-fail-on-non-empty: When using wildcards, do not fail if a directory still contains files.
Example:
- hadoop fs -rmdir /user/hadoop/emptydir
rmr
Usage: hadoop fs -rmr [-skipTrash] URI [URI ...]
Recursive version of delete.
Note: This command is deprecated. Instead use hadoop fs -rm -r
setfacl
Usage: hadoop fs -setfacl [-R] [-b |-k -m |-x <acl_spec> <path>] |[--set <acl_spec> <path>]
Sets Access Control Lists (ACLs) of files and directories.
Options:
- -b: Remove all but the base ACL entries. The entries for user, group and others are retained for compatibility with permission bits.
- -k: Remove the default ACL.
- -R: Apply operations to all files and directories recursively.
- -m: Modify ACL. New entries are added to the ACL, and existing entries are retained.
- -x: Remove specified ACL entries. Other ACL entries are retained.
- --set: Fully replace the ACL, discarding all existing entries. The acl_spec must include entries for user, group, and others for compatibility with permission bits.
- acl_spec: Comma separated list of ACL entries.
- path: File or directory to modify.
Examples:
- hadoop fs -setfacl -m user:hadoop:rw- /file
- hadoop fs -setfacl -x user:hadoop /file
- hadoop fs -setfacl -b /file
- hadoop fs -setfacl -k /dir
- hadoop fs -setfacl --set user::rw-,user:hadoop:rw-,group::r--,other::r-- /file
- hadoop fs -setfacl -R -m user:hadoop:r-x /dir
- hadoop fs -setfacl -m default:user:hadoop:r-x /dir
Exit Code:
Returns 0 on success and non-zero on error.
setfattr
Usage: hadoop fs -setfattr -n name [-v value] | -x name <path>
Sets an extended attribute name and value for a file or directory.
Options:
- -b: Remove all but the base ACL entries. The entries for user, group and others are retained for compatibility with permission bits.
- -n name: The extended attribute name.
- -v value: The extended attribute value. There are three different encoding methods for the value. If the argument is enclosed in double quotes, then the value is the string inside the quotes. If the argument is prefixed with 0x or 0X, then it is taken as a hexadecimal number. If the argument begins with 0s or 0S, then it is taken as a base64 encoding.
- -x name: Remove the extended attribute.
- path: The file or directory.
Examples:
- hadoop fs -setfattr -n user.myAttr -v myValue /file
- hadoop fs -setfattr -n user.noValue /file
- hadoop fs -setfattr -x user.myAttr /file
Exit Code:
Returns 0 on success and non-zero on error.
setrep
Usage: hadoop fs -setrep [-R] [-w] <numReplicas> <path>
Changes the replication factor of a file. If path is a directory then the command recursively changes the replication factor of all files under the directory tree rooted at path.
Options:
- The -w flag requests that the command wait for the replication to complete. This can potentially take a very long time.
- The -R flag is accepted for backwards compatibility. It has no effect.
Example:
- hadoop fs -setrep -w 3 /user/hadoop/dir1
Exit Code:
Returns 0 on success and -1 on error.
stat
Usage: hadoop fs -stat [format] <path> ...
Print statistics about the file/directory at <path> in the specified format. Format accepts filesize in blocks (%b), type (%F), group name of owner (%g), name (%n), block size (%o), replication (%r), user name of owner(%u), and modification date (%y, %Y). %y shows UTC date as “yyyy-MM-dd HH:mm:ss” and %Y shows milliseconds since January 1, 1970 UTC. If the format is not specified, %y is used by default.
Example:
- hadoop fs -stat "%F %u:%g %b %y %n" /file
Exit Code: Returns 0 on success and -1 on error.
tail
Usage: hadoop fs -tail [-f] URI
Displays last kilobyte of the file to stdout.
Options:
- The -f option will output appended data as the file grows, as in Unix.
Example:
- hadoop fs -tail pathname
Exit Code: Returns 0 on success and -1 on error.
test
Usage: hadoop fs -test -[defsz] URI
Options:
- -d: f the path is a directory, return 0.
- -e: if the path exists, return 0.
- -f: if the path is a file, return 0.
- -s: if the path is not empty, return 0.
- -z: if the file is zero length, return 0.
Example:
- hadoop fs -test -e filename
text
Usage: hadoop fs -text <src>
Takes a source file and outputs the file in text format. The allowed formats are zip and TextRecordInputStream.
touchz
Usage: hadoop fs -touchz URI [URI ...]
Create a file of zero length.
Example:
- hadoop fs -touchz pathname
Exit Code: Returns 0 on success and -1 on error.
truncate
Usage: hadoop fs -truncate [-w] <length> <paths>
Truncate all files that match the specified file pattern to the specified length.
Options:
- The -w flag requests that the command waits for block recovery to complete, if necessary. Without -w flag the file may remain unclosed for some time while the recovery is in progress. During this time file cannot be reopened for append.
Example:
- hadoop fs -truncate 55 /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -truncate -w 127 hdfs://nn1.example.com/user/hadoop/file1
http://hadoop.apache.org/docs/r2.7.3/hadoop-project-dist/hadoop-hdfs/HDFSCommands.html
HDFS Commands Guide
Overview
All HDFS commands are invoked by the bin/hdfs script. Running the hdfs script without any arguments prints the description for all commands.
Usage: hdfs [SHELL_OPTIONS] COMMAND [GENERIC_OPTIONS] [COMMAND_OPTIONS]
Hadoop has an option parsing framework that employs parsing generic options as well as running classes.
| COMMAND_OPTIONS | Description |
|---|---|
| --config --loglevel |
The common set of shell options. These are documented on the Commands Manual page. |
| GENERIC_OPTIONS | The common set of options supported by multiple commands. See the Hadoop Commands Manual for more information. |
| COMMAND COMMAND_OPTIONS | Various commands with their options are described in the following sections. The commands have been grouped into User Commands and Administration Commands. |
User Commands
Commands useful for users of a hadoop cluster.
classpath
Usage: hdfs classpath
Prints the class path needed to get the Hadoop jar and the required libraries
dfs
Usage: hdfs dfs [COMMAND [COMMAND_OPTIONS]]
Run a filesystem command on the file system supported in Hadoop. The various COMMAND_OPTIONS can be found at File System Shell Guide.
fetchdt
Usage: hdfs fetchdt [--webservice <namenode_http_addr>] <path>
| COMMAND_OPTION | Description |
|---|---|
| --webservice https_address | use http protocol instead of RPC |
| fileName | File name to store the token into. |
Gets Delegation Token from a NameNode. See fetchdt for more info.
fsck
Usage:
hdfs fsck <path>
[-list-corruptfileblocks |
[-move | -delete | -openforwrite]
[-files [-blocks [-locations | -racks]]]
[-includeSnapshots]
[-storagepolicies] [-blockId <blk_Id>]
| COMMAND_OPTION | Description |
|---|---|
| path | Start checking from this path. |
| -delete | Delete corrupted files. |
| -files | Print out files being checked. |
| -files -blocks | Print out the block report |
| -files -blocks -locations | Print out locations for every block. |
| -files -blocks -racks | Print out network topology for data-node locations. |
| -includeSnapshots | Include snapshot data if the given path indicates a snapshottable directory or there are snapshottable directories under it. |
| -list-corruptfileblocks | Print out list of missing blocks and files they belong to. |
| -move | Move corrupted files to /lost+found. |
| -openforwrite | Print out files opened for write. |
| -storagepolicies | Print out storage policy summary for the blocks. |
| -blockId | Print out information about the block. |
Runs the HDFS filesystem checking utility. See fsck for more info.
getconf
Usage:
hdfs getconf -namenodes hdfs getconf -secondaryNameNodes hdfs getconf -backupNodes hdfs getconf -includeFile hdfs getconf -excludeFile hdfs getconf -nnRpcAddresses hdfs getconf -confKey [key]
| COMMAND_OPTION | Description |
|---|---|
| -namenodes | gets list of namenodes in the cluster. |
| -secondaryNameNodes | gets list of secondary namenodes in the cluster. |
| -backupNodes | gets list of backup nodes in the cluster. |
| -includeFile | gets the include file path that defines the datanodes that can join the cluster. |
| -excludeFile | gets the exclude file path that defines the datanodes that need to decommissioned. |
| -nnRpcAddresses | gets the namenode rpc addresses |
| -confKey [key] | gets a specific key from the configuration |
Gets configuration information from the configuration directory, post-processing.
lsSnapshottableDir
Usage: hdfs lsSnapshottableDir [-help]
| COMMAND_OPTION | Description |
|---|---|
| -help | print help |
Get the list of snapshottable directories. When this is run as a super user, it returns all snapshottable directories. Otherwise it returns those directories that are owned by the current user.
jmxget
Usage: hdfs jmxget [-localVM ConnectorURL | -port port | -server mbeanserver | -service service]
| COMMAND_OPTION | Description |
|---|---|
| -help | print help |
| -localVM ConnectorURL | connect to the VM on the same machine |
| -port mbean server port | specify mbean server port, if missing it will try to connect to MBean Server in the same VM |
| -service | specify jmx service, either DataNode or NameNode, the default |
Dump JMX information from a service.
oev
Usage: hdfs oev [OPTIONS] -i INPUT_FILE -o OUTPUT_FILE
Required command line arguments:
| COMMAND_OPTION | Description |
|---|---|
| -i,--inputFile arg | edits file to process, xml (case insensitive) extension means XML format, any other filename means binary format |
| -o,--outputFile arg | Name of output file. If the specified file exists, it will be overwritten, format of the file is determined by -p option |
Optional command line arguments:
| COMMAND_OPTION | Description |
|---|---|
| -f,--fix-txids | Renumber the transaction IDs in the input, so that there are no gaps or invalid transaction IDs. |
| -h,--help | Display usage information and exit |
| -r,--ecover | When reading binary edit logs, use recovery mode. This will give you the chance to skip corrupt parts of the edit log. |
| -p,--processor arg | Select which type of processor to apply against image file, currently supported processors are: binary (native binary format that Hadoop uses), xml (default, XML format), stats (prints statistics about edits file) |
| -v,--verbose | More verbose output, prints the input and output filenames, for processors that write to a file, also output to screen. On large image files this will dramatically increase processing time (default is false). |
Hadoop offline edits viewer.
oiv
Usage: hdfs oiv [OPTIONS] -i INPUT_FILE
Required command line arguments:
| COMMAND_OPTION | Description |
|---|---|
| -i,--inputFile arg | edits file to process, xml (case insensitive) extension means XML format, any other filename means binary format |
Optional command line arguments:
| COMMAND_OPTION | Description |
|---|---|
| -h,--help | Display usage information and exit |
| -o,--outputFile arg | Name of output file. If the specified file exists, it will be overwritten, format of the file is determined by -p option |
| -p,--processor arg | Select which type of processor to apply against image file, currently supported processors are: binary (native binary format that Hadoop uses), xml (default, XML format), stats (prints statistics about edits file) |
Hadoop Offline Image Viewer for newer image files.
oiv_legacy
Usage: hdfs oiv_legacy [OPTIONS] -i INPUT_FILE -o OUTPUT_FILE
| COMMAND_OPTION | Description |
|---|---|
| -h,--help | Display usage information and exit |
| -i,--inputFile arg | edits file to process, xml (case insensitive) extension means XML format, any other filename means binary format |
| -o,--outputFile arg | Name of output file. If the specified file exists, it will be overwritten, format of the file is determined by -p option |
Hadoop offline image viewer for older versions of Hadoop.
snapshotDiff
Usage: hdfs snapshotDiff <path> <fromSnapshot> <toSnapshot>
Determine the difference between HDFS snapshots. See the HDFS Snapshot Documentation for more information.
Administration Commands
Commands useful for administrators of a hadoop cluster.
balancer
Usage:
hdfs balancer
[-threshold <threshold>]
[-policy <policy>]
[-exclude [-f <hosts-file> | <comma-separated list of hosts>]]
[-include [-f <hosts-file> | <comma-separated list of hosts>]]
[-idleiterations <idleiterations>]
| COMMAND_OPTION | Description |
|---|---|
| -policy <policy> | datanode (default): Cluster is balanced if each datanode is balanced. blockpool: Cluster is balanced if each block pool in each datanode is balanced. |
| -threshold <threshold> | Percentage of disk capacity. This overwrites the default threshold. |
| -exclude -f <hosts-file> | <comma-separated list of hosts> | Excludes the specified datanodes from being balanced by the balancer. |
| -include -f <hosts-file> | <comma-separated list of hosts> | Includes only the specified datanodes to be balanced by the balancer. |
| -idleiterations <iterations> | Maximum number of idle iterations before exit. This overwrites the default idleiterations(5). |
Runs a cluster balancing utility. An administrator can simply press Ctrl-C to stop the rebalancing process. See Balancer for more details.
Note that the blockpool policy is more strict than the datanode policy.
cacheadmin
Usage: hdfs cacheadmin -addDirective -path <path> -pool <pool-name> [-force] [-replication <replication>] [-ttl <time-to-live>]
See the HDFS Cache Administration Documentation for more information.
crypto
Usage:
hdfs crypto -createZone -keyName <keyName> -path <path> hdfs crypto -help <command-name> hdfs crypto -listZones
See the HDFS Transparent Encryption Documentation for more information.
datanode
Usage: hdfs datanode [-regular | -rollback | -rollingupgrace rollback]
| COMMAND_OPTION | Description |
|---|---|
| -regular | Normal datanode startup (default). |
| -rollback | Rollback the datanode to the previous version. This should be used after stopping the datanode and distributing the old hadoop version. |
| -rollingupgrade rollback | Rollback a rolling upgrade operation. |
Runs a HDFS datanode.
dfsadmin
Usage:
hdfs dfsadmin [GENERIC_OPTIONS]
[-report [-live] [-dead] [-decommissioning]]
[-safemode enter | leave | get | wait]
[-saveNamespace]
[-rollEdits]
[-restoreFailedStorage true |false |check]
[-refreshNodes]
[-setQuota <quota> <dirname>...<dirname>]
[-clrQuota <dirname>...<dirname>]
[-setSpaceQuota <quota> <dirname>...<dirname>]
[-clrSpaceQuota <dirname>...<dirname>]
[-setStoragePolicy <path> <policyName>]
[-getStoragePolicy <path>]
[-finalizeUpgrade]
[-rollingUpgrade [<query> |<prepare> |<finalize>]]
[-metasave filename]
[-refreshServiceAcl]
[-refreshUserToGroupsMappings]
[-refreshSuperUserGroupsConfiguration]
[-refreshCallQueue]
[-refresh <host:ipc_port> <key> [arg1..argn]]
[-reconfig <datanode |...> <host:ipc_port> <start |status>]
[-printTopology]
[-refreshNamenodes datanodehost:port]
[-deleteBlockPool datanode-host:port blockpoolId [force]]
[-setBalancerBandwidth <bandwidth in bytes per second>]
[-allowSnapshot <snapshotDir>]
[-disallowSnapshot <snapshotDir>]
[-fetchImage <local directory>]
[-shutdownDatanode <datanode_host:ipc_port> [upgrade]]
[-getDatanodeInfo <datanode_host:ipc_port>]
[-triggerBlockReport [-incremental] <datanode_host:ipc_port>]
[-help [cmd]]
| COMMAND_OPTION | Description |
|---|---|
| -report [-live] [-dead] [-decommissioning] | Reports basic filesystem information and statistics. Optional flags may be used to filter the list of displayed DataNodes. |
| -safemode enter|leave|get|wait | Safe mode maintenance command. Safe mode is a Namenode state in which it 1. does not accept changes to the name space (read-only) 2. does not replicate or delete blocks. Safe mode is entered automatically at Namenode startup, and leaves safe mode automatically when the configured minimum percentage of blocks satisfies the minimum replication condition. Safe mode can also be entered manually, but then it can only be turned off manually as well. |
| -saveNamespace | Save current namespace into storage directories and reset edits log. Requires safe mode. |
| -rollEdits | Rolls the edit log on the active NameNode. |
| -restoreFailedStorage true|false|check | This option will turn on/off automatic attempt to restore failed storage replicas. If a failed storage becomes available again the system will attempt to restore edits and/or fsimage during checkpoint. ‘check’ option will return current setting. |
| -refreshNodes | Re-read the hosts and exclude files to update the set of Datanodes that are allowed to connect to the Namenode and those that should be decommissioned or recommissioned. |
| -setQuota <quota> <dirname>…<dirname> | See HDFS Quotas Guide for the detail. |
| -clrQuota <dirname>…<dirname> | See HDFS Quotas Guide for the detail. |
| -setSpaceQuota <quota> <dirname>…<dirname> | See HDFS Quotas Guide for the detail. |
| -clrSpaceQuota <dirname>…<dirname> | See HDFS Quotas Guide for the detail. |
| -setStoragePolicy <path> <policyName> | Set a storage policy to a file or a directory. |
| -getStoragePolicy <path> | Get the storage policy of a file or a directory. |
| -finalizeUpgrade | Finalize upgrade of HDFS. Datanodes delete their previous version working directories, followed by Namenode doing the same. This completes the upgrade process. |
| -rollingUpgrade [<query>|<prepare>|<finalize>] | See Rolling Upgrade document for the detail. |
| -metasave filename | Save Namenode’s primary data structures to filename in the directory specified by hadoop.log.dir property. filename is overwritten if it exists. filename will contain one line for each of the following 1. Datanodes heart beating with Namenode 2. Blocks waiting to be replicated 3. Blocks currently being replicated 4. Blocks waiting to be deleted |
| -refreshServiceAcl | Reload the service-level authorization policy file. |
| -refreshUserToGroupsMappings | Refresh user-to-groups mappings. |
| -refreshSuperUserGroupsConfiguration | Refresh superuser proxy groups mappings |
| -refreshCallQueue | Reload the call queue from config. |
| -refresh <host:ipc_port> <key> [arg1..argn] | Triggers a runtime-refresh of the resource specified by <key> on <host:ipc_port>. All other args after are sent to the host. |
| -reconfig <datanode |…> <host:ipc_port> <start|status> | Start reconfiguration or get the status of an ongoing reconfiguration. The second parameter specifies the node type. Currently, only reloading DataNode’s configuration is supported. |
| -printTopology | Print a tree of the racks and their nodes as reported by the Namenode |
| -refreshNamenodes datanodehost:port | For the given datanode, reloads the configuration files, stops serving the removed block-pools and starts serving new block-pools. |
| -deleteBlockPool datanode-host:port blockpoolId [force] | If force is passed, block pool directory for the given blockpool id on the given datanode is deleted along with its contents, otherwise the directory is deleted only if it is empty. The command will fail if datanode is still serving the block pool. Refer to refreshNamenodes to shutdown a block pool service on a datanode. |
| -setBalancerBandwidth <bandwidth in bytes per second> | Changes the network bandwidth used by each datanode during HDFS block balancing. <bandwidth> is the maximum number of bytes per second that will be used by each datanode. This value overrides the dfs.balance.bandwidthPerSec parameter. NOTE: The new value is not persistent on the DataNode. |
| -allowSnapshot <snapshotDir> | Allowing snapshots of a directory to be created. If the operation completes successfully, the directory becomes snapshottable. See the HDFS Snapshot Documentation for more information. |
| -disallowSnapshot <snapshotDir> | Disallowing snapshots of a directory to be created. All snapshots of the directory must be deleted before disallowing snapshots. See the HDFS Snapshot Documentation for more information. |
| -fetchImage <local directory> | Downloads the most recent fsimage from the NameNode and saves it in the specified local directory. |
| -shutdownDatanode <datanode_host:ipc_port> [upgrade] | Submit a shutdown request for the given datanode. See Rolling Upgrade document for the detail. |
| -getDatanodeInfo <datanode_host:ipc_port> | Get the information about the given datanode. See Rolling Upgrade document for the detail. |
| -triggerBlockReport [-incremental] <datanode_host:ipc_port> | Trigger a block report for the given datanode. If ‘incremental’ is specified, it will be otherwise, it will be a full block report. |
| -help [cmd] | Displays help for the given command or all commands if none is specified. |
Runs a HDFS dfsadmin client.
haadmin
Usage:
hdfs haadmin -checkHealth <serviceId>
hdfs haadmin -failover [--forcefence] [--forceactive] <serviceId> <serviceId>
hdfs haadmin -getServiceState <serviceId>
hdfs haadmin -help <command>
hdfs haadmin -transitionToActive <serviceId> [--forceactive]
hdfs haadmin -transitionToStandby <serviceId>
| COMMAND_OPTION | Description |
|---|---|
| -checkHealth | check the health of the given NameNode |
| -failover | initiate a failover between two NameNodes |
| -getServiceState | determine whether the given NameNode is Active or Standby |
| -transitionToActive | transition the state of the given NameNode to Active (Warning: No fencing is done) |
| -transitionToStandby | transition the state of the given NameNode to Standby (Warning: No fencing is done) |
See HDFS HA with NFS or HDFS HA with QJM for more information on this command.
journalnode
Usage: hdfs journalnode
This comamnd starts a journalnode for use with HDFS HA with QJM.
mover
Usage: hdfs mover [-p <files/dirs> | -f <local file name>]
| COMMAND_OPTION | Description |
|---|---|
| -f <local file> | Specify a local file containing a list of HDFS files/dirs to migrate. |
| -p <files/dirs> | Specify a space separated list of HDFS files/dirs to migrate. |
Runs the data migration utility. See Mover for more details.
Note that, when both -p and -f options are omitted, the default path is the root directory.
namenode
Usage:
hdfs namenode [-backup] |
[-checkpoint] |
[-format [-clusterid cid ] [-force] [-nonInteractive] ] |
[-upgrade [-clusterid cid] [-renameReserved<k-v pairs>] ] |
[-upgradeOnly [-clusterid cid] [-renameReserved<k-v pairs>] ] |
[-rollback] |
[-rollingUpgrade <downgrade |rollback> ] |
[-finalize] |
[-importCheckpoint] |
[-initializeSharedEdits] |
[-bootstrapStandby] |
[-recover [-force] ] |
[-metadataVersion ]
| COMMAND_OPTION | Description |
|---|---|
| -backup | Start backup node. |
| -checkpoint | Start checkpoint node. |
| -format [-clusterid cid] [-force] [-nonInteractive] | Formats the specified NameNode. It starts the NameNode, formats it and then shut it down. -force option formats if the name directory exists. -nonInteractive option aborts if the name directory exists, unless -force option is specified. |
| -upgrade [-clusterid cid] [-renameReserved <k-v pairs>] | Namenode should be started with upgrade option after the distribution of new Hadoop version. |
| -upgradeOnly [-clusterid cid] [-renameReserved <k-v pairs>] | Upgrade the specified NameNode and then shutdown it. |
| -rollback | Rollback the NameNode to the previous version. This should be used after stopping the cluster and distributing the old Hadoop version. |
| -rollingUpgrade <downgrade|rollback|started> | See Rolling Upgrade document for the detail. |
| -finalize | Finalize will remove the previous state of the files system. Recent upgrade will become permanent. Rollback option will not be available anymore. After finalization it shuts the NameNode down. |
| -importCheckpoint | Loads image from a checkpoint directory and save it into the current one. Checkpoint dir is read from property fs.checkpoint.dir |
| -initializeSharedEdits | Format a new shared edits dir and copy in enough edit log segments so that the standby NameNode can start up. |
| -bootstrapStandby | Allows the standby NameNode’s storage directories to be bootstrapped by copying the latest namespace snapshot from the active NameNode. This is used when first configuring an HA cluster. |
| -recover [-force] | Recover lost metadata on a corrupt filesystem. See HDFS User Guide for the detail. |
| -metadataVersion | Verify that configured directories exist, then print the metadata versions of the software and the image. |
Runs the namenode. More info about the upgrade, rollback and finalize is at Upgrade Rollback.
secondarynamenode
Usage: hdfs secondarynamenode [-checkpoint [force]] | [-format] | [-geteditsize]
| COMMAND_OPTION | Description |
|---|---|
| -checkpoint [force] | Checkpoints the SecondaryNameNode if EditLog size >= fs.checkpoint.size. If force is used, checkpoint irrespective of EditLog size. |
| -format | Format the local storage during startup. |
| -geteditsize | Prints the number of uncheckpointed transactions on the NameNode. |
Runs the HDFS secondary namenode. See Secondary Namenode for more info.
storagepolicies
Usage: hdfs storagepolicies
Lists out all storage policies. See the HDFS Storage Policy Documentation for more information.
zkfc
Usage: hdfs zkfc [-formatZK [-force] [-nonInteractive]]
| COMMAND_OPTION | Description |
|---|---|
| -formatZK | Format the Zookeeper instance |
| -h | Display help |
This comamnd starts a Zookeeper Failover Controller process for use with HDFS HA with QJM.
Debug Commands
Useful commands to help administrators debug HDFS issues, like validating block files and calling recoverLease.
verify
Usage: hdfs debug verify [-meta <metadata-file>] [-block <block-file>]
| COMMAND_OPTION | Description |
|---|---|
| -block block-file | Optional parameter to specify the absolute path for the block file on the local file system of the data node. |
| -meta metadata-file | Absolute path for the metadata file on the local file system of the data node. |
Verify HDFS metadata and block files. If a block file is specified, we will verify that the checksums in the metadata file match the block file.
recoverLease
Usage: hdfs debug recoverLease [-path <path>] [-retries <num-retries>]
| COMMAND_OPTION | Description |
|---|---|
| [-path path] | HDFS path for which to recover the lease. |
| [-retries num-retries] | Number of times the client will retry calling recoverLease. The default number of retries is 1. |
Recover the lease on the specified path. The path must reside on an HDFS filesystem. The default number of retries is 1.
6、HDFS API详解
Hadoop中关于文件操作类基本上全部是在"org.apache.hadoop.fs"包中,这些API能够支持的操作包含:打开文件,读写文件,删除文件等。
Hadoop类库中最终面向用户提供的接口类是FileSystem,该类是个抽象类,只能通过来类的get方法得到具体类。get方法存在几个重载版本,常用的是这个:
static FileSystem get(Configuration conf);
该类封装了几乎所有的文件操作,例如mkdir,delete等。综上基本上可以得出操作文件的程序库框架:
operator()
{
得到Configuration对象
得到FileSystem对象
进行文件操作
}
6.1 上传本地文件
通过"FileSystem.copyFromLocalFile(Path src,Patch dst)"可将本地文件上传到HDFS的制定位置上,其中src和dst均为文件的完整路径。具体事例如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CopyFile {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
//本地文件
Path src =new Path("D:\\HebutWinOS");
//HDFS为止
Path dst =new Path("/");
hdfs.copyFromLocalFile(src, dst);
System.out.println("Upload to"+conf.get("fs.default.name"));
FileStatus files[]=hdfs.listStatus(dst);
for(FileStatus file:files){
System.out.println(file.getPath());
}
}
}
运行结果可以通过控制台、项目浏览器和SecureCRT查看,如图6-1-1、图6-1-2、图6-1-3所示。
1)控制台结果

图6-1-1 运行结果(1)
2)项目浏览器
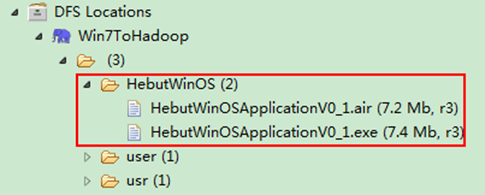
图6-1-2 运行结果(2)
3)SecureCRT结果
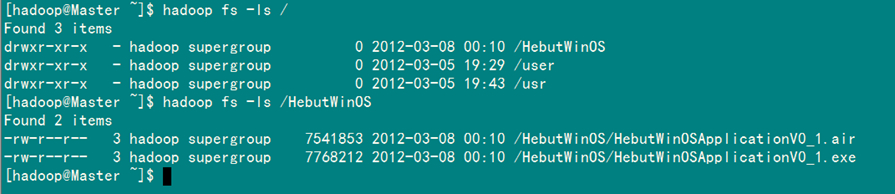
图6-1-3 运行结果(3)
6.2 创建HDFS文件
通过"FileSystem.create(Path f)"可在HDFS上创建文件,其中f为文件的完整路径。具体实现如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CreateFile {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
byte[] buff="hello hadoop world!\n".getBytes();
Path dfs=new Path("/test");
FSDataOutputStream outputStream=hdfs.create(dfs);
outputStream.write(buff,0,buff.length);
}
}
运行结果如图6-2-1和图6-2-2所示。
1)项目浏览器
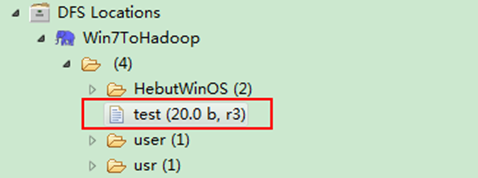
图6-2-1 运行结果(1)
2)SecureCRT结果
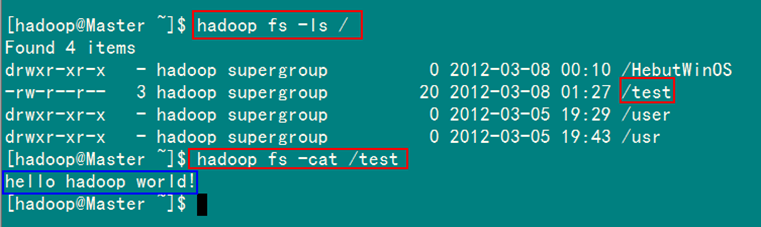
图6-2-2 运行结果(2)
6.3 创建HDFS目录
通过"FileSystem.mkdirs(Path f)"可在HDFS上创建文件夹,其中f为文件夹的完整路径。具体实现如下:
package com.hebut.dir;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CreateDir {
public static void main(String[] args) throws Exception{
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path dfs=new Path("/TestDir");
hdfs.mkdirs(dfs);
}
}
运行结果如图6-3-1和图6-3-2所示。
1)项目浏览器
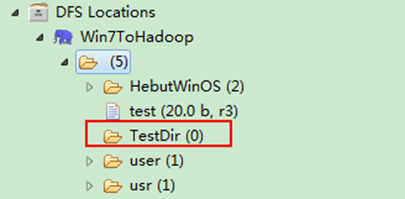
图6-3-1 运行结果(1)
2)SecureCRT结果
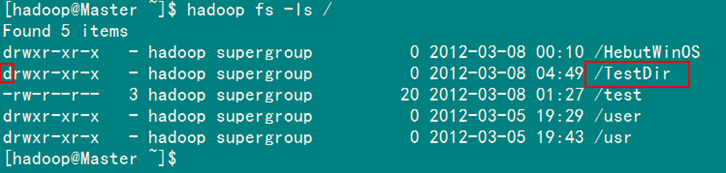
图6-3-2 运行结果(2)
6.4 重命名HDFS文件
通过"FileSystem.rename(Path src,Path dst)"可为指定的HDFS文件重命名,其中src和dst均为文件的完整路径。具体实现如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Rename{
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path frpaht=new Path("/test"); //旧的文件名
Path topath=new Path("/test1"); //新的文件名
boolean isRename=hdfs.rename(frpaht, topath);
String result=isRename?"成功":"失败";
System.out.println("文件重命名结果为:"+result);
}
}
运行结果如图6-4-1和图6-4-2所示。
1)项目浏览器
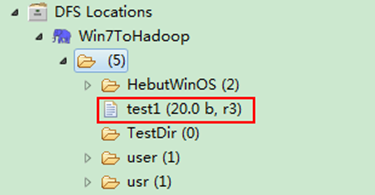
图6-4-1 运行结果(1)
2)SecureCRT结果
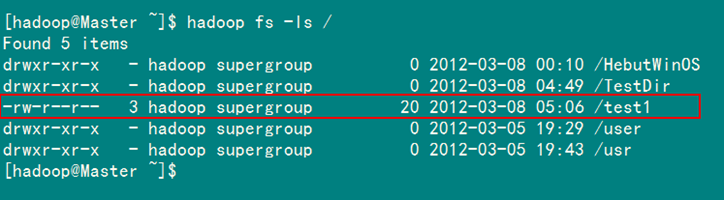
图6-4-2 运行结果(2)
6.5 删除HDFS上的文件
通过"FileSystem.delete(Path f,Boolean recursive)"可删除指定的HDFS文件,其中f为需要删除文件的完整路径,recuresive用来确定是否进行递归删除。具体实现如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class DeleteFile {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path delef=new Path("/test1");
boolean isDeleted=hdfs.delete(delef,false);
//递归删除
//boolean isDeleted=hdfs.delete(delef,true);
System.out.println("Delete?"+isDeleted);
}
}
运行结果如图6-5-1和图6-5-2所示。
1)控制台结果

图6-5-1 运行结果(1)
2)项目浏览器
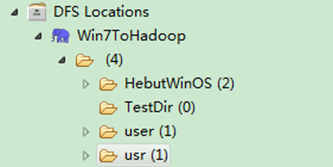
图6-5-2 运行结果(2)
6.6 删除HDFS上的目录
同删除文件代码一样,只是换成删除目录路径即可,如果目录下有文件,要进行递归删除。
6.7 查看某个HDFS文件是否存在
通过"FileSystem.exists(Path f)"可查看指定HDFS文件是否存在,其中f为文件的完整路径。具体实现如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CheckFile {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path findf=new Path("/test1");
boolean isExists=hdfs.exists(findf);
System.out.println("Exist?"+isExists);
}
}
运行结果如图6-7-1和图6-7-2所示。
1)控制台结果

图6-7-1 运行结果(1)
2)项目浏览器
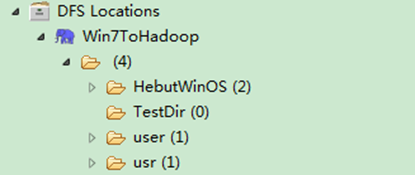
图6-7-2 运行结果(2)
6.8 查看HDFS文件的最后修改时间
通过"FileSystem.getModificationTime()"可查看指定HDFS文件的修改时间。具体实现如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class GetLTime {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path fpath =new Path("/user/hadoop/test/file1.txt");
FileStatus fileStatus=hdfs.getFileStatus(fpath);
long modiTime=fileStatus.getModificationTime();
System.out.println("file1.txt的修改时间是"+modiTime);
}
}
运行结果如图6-8-1所示。
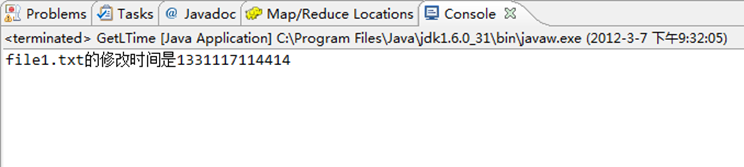
图6-8-1 控制台结果
6.9 读取HDFS某个目录下的所有文件
通过"FileStatus.getPath()"可查看指定HDFS中某个目录下所有文件。具体实现如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class ListAllFile {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path listf =new Path("/user/hadoop/test");
FileStatus stats[]=hdfs.listStatus(listf);
for(int i = 0; i < stats.length; ++i)
{
System.out.println(stats[i].getPath().toString());
}
hdfs.close();
}
}
运行结果如图6-9-1和图6-9-2所示。
1)控制台结果

图6-9-1 运行结果(1)
2)项目浏览器
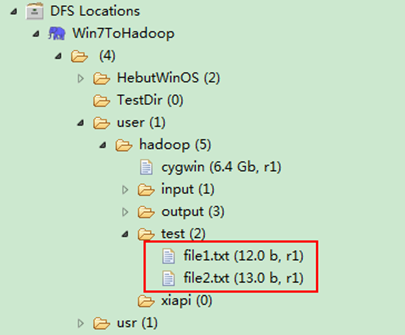
图6-9-2 运行结果(2)
6.10 查找某个文件在HDFS集群的位置
通过"FileSystem.getFileBlockLocation(FileStatus file,long start,long len)"可查找指定文件在HDFS集群上的位置,其中file为文件的完整路径,start和len来标识查找文件的路径。具体实现如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class FileLoc {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem hdfs=FileSystem.get(conf);
Path fpath=new Path("/user/hadoop/cygwin");
FileStatus filestatus = hdfs.getFileStatus(fpath);
BlockLocation[] blkLocations = hdfs.getFileBlockLocations(filestatus, 0, filestatus.getLen());
int blockLen = blkLocations.length;
for(int i=0;i<blockLen;i++){
String[] hosts = blkLocations[i].getHosts();
System.out.println("block_"+i+"_location:"+hosts[0]);
}
}
}
运行结果如图6-10-1和6.10.2所示。
1)控制台结果
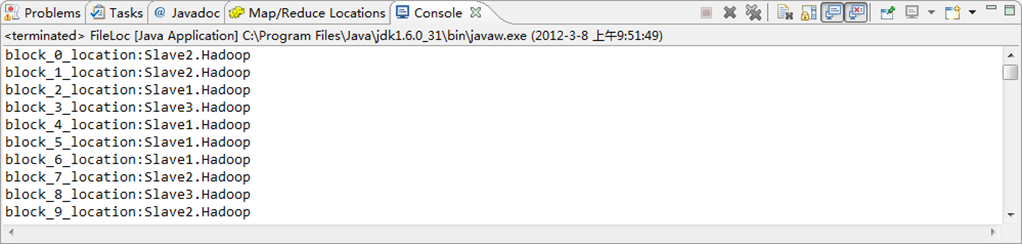
图6-10-1 运行结果(1)
2)项目浏览器
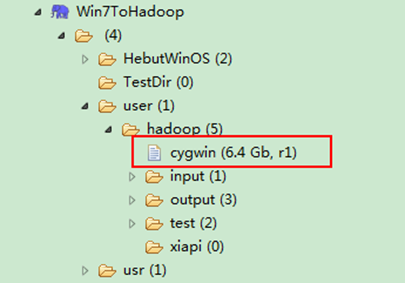
图6-10-2 运行结果(2)
6.11 获取HDFS集群上所有节点名称信息
通过"DatanodeInfo.getHostName()"可获取HDFS集群上的所有节点名称。具体实现如下:
package com.hebut.file;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.hdfs.DistributedFileSystem;
import org.apache.hadoop.hdfs.protocol.DatanodeInfo;
public class GetList {
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
DistributedFileSystem hdfs = (DistributedFileSystem)fs;
DatanodeInfo[] dataNodeStats = hdfs.getDataNodeStats();
for(int i=0;i<dataNodeStats.length;i++){
System.out.println("DataNode_"+i+"_Name:"+dataNodeStats[i].getHostName());
}
}
}
运行结果如图6-11-1所示。
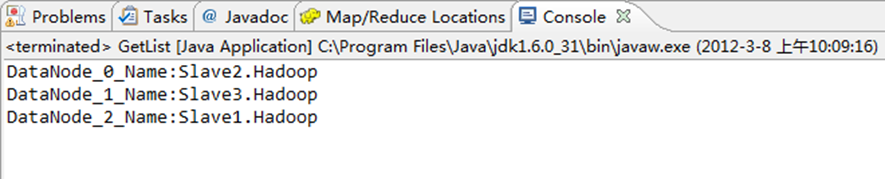
图6-11-1 控制台结果
7、HDFS的读写数据流
7.1 文件的读取剖析
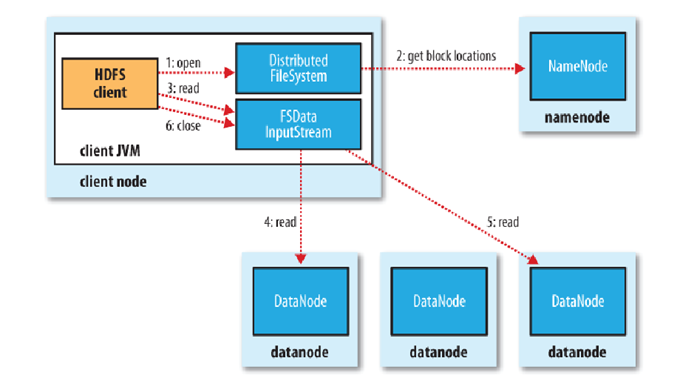
文件读取的过程如下:
1)解释一
- 客户端(client)用FileSystem的open()函数打开文件。
- DistributedFileSystem用RPC调用元数据节点,得到文件的数据块信息。
- 对于每一个数据块,元数据节点返回保存数据块的数据节点的地址。
- DistributedFileSystem返回FSDataInputStream给客户端,用来读取数据。
- 客户端调用stream的read()函数开始读取数据。
- DFSInputStream连接保存此文件第一个数据块的最近的数据节点。
- Data从数据节点读到客户端(client)。
- 当此数据块读取完毕时,DFSInputStream关闭和此数据节点的连接,然后连接此文件下一个数据块的最近的数据节点。
- 当客户端读取完毕数据的时候,调用FSDataInputStream的close函数。
- 在读取数据的过程中,如果客户端在与数据节点通信出现错误,则尝试连接包含此数据块的下一个数据节点。
- 失败的数据节点将被记录,以后不再连接。
2)解释二
- 使用HDFS提供的客户端开发库,向远程的Namenode发起RPC请求;
- Namenode会视情况返回文件的部分或者全部block列表,对于每个block,Namenode都会返回有该block拷贝的datanode地址;
- 客户端开发库会选取离客户端最接近的datanode来读取block;
- 读取完当前block的数据后,关闭与当前的datanode连接,并为读取下一个block寻找最佳的datanode;
- 当读完列表的block后,且文件读取还没有结束,客户端开发库会继续向Namenode获取下一批的block列表。
- 读取完一个block都会进行checksum验证,如果读取datanode时出现错误,客户端会通知Namenode,然后再从下一个拥有该block拷贝的datanode继续读。
7.2 文件的写入剖析

写入文件的过程比读取较为复杂:
1)解释一
- 客户端调用create()来创建文件
- DistributedFileSystem用RPC调用元数据节点,在文件系统的命名空间中创建一个新的文件。
- 元数据节点首先确定文件原来不存在,并且客户端有创建文件的权限,然后创建新文件。
- DistributedFileSystem返回DFSOutputStream,客户端用于写数据。
- 客户端开始写入数据,DFSOutputStream将数据分成块,写入data queue。
- Data queue由Data Streamer读取,并通知元数据节点分配数据节点,用来存储数据块(每块默认复制3块)。分配的数据节点放在一个pipeline里。
- Data Streamer将数据块写入pipeline中的第一个数据节点。第一个数据节点将数据块发送给第二个数据节点。第二个数据节点将数据发送给第三个数据节点。
- DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已经写入成功。
-
如果数据节点在写入的过程中失败:
- 关闭pipeline,将ack queue中的数据块放入data queue的开始。
- 当前的数据块在已经写入的数据节点中被元数据节点赋予新的标示,则错误节点重启后能够察觉其数据块是过时的,会被删除。
- 失败的数据节点从pipeline中移除,另外的数据块则写入pipeline中的另外两个数据节点。
- 元数据节点则被通知此数据块是复制块数不足,将来会再创建第三份备份。
- 当客户端结束写入数据,则调用stream的close函数。此操作将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功。最后通知元数据节点写入完毕。
2)解释二
- 使用HDFS提供的客户端开发库,向远程的Namenode发起RPC请求;
- Namenode会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会为文件创建一个记录,否则会让客户端抛出异常;
- 当客户端开始写入文件的时候,开发库会将文件切分成多个packets,并在内部以"data queue"的形式管理这些packets,并向Namenode申请新的blocks,获取用来存储replicas的合适的datanodes列表,列表的大小根据在Namenode中对replication的设置而定。
- 开始以pipeline(管道)的形式将packet写入所有的replicas中。开发库把packet以流的方式写入第一个datanode,该datanode把该packet存储之后,再将其传递给在此pipeline中的下一个datanode,直到最后一个datanode,这种写数据的方式呈流水线的形式。
- 最后一个datanode成功存储之后会返回一个ack packet,在pipeline里传递至客户端,在客户端的开发库内部维护着"ack queue",成功收到datanode返回的ack packet后会从"ack queue"移除相应的packet。
- 如果传输过程中,有某个datanode出现了故障,那么当前的pipeline会被关闭,出现故障的datanode会从当前的pipeline中移除,剩余的block会继续剩下的datanode中继续以pipeline的形式传输,同时Namenode会分配一个新的datanode,保持replicas设定的数量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号