Python网络爬虫与信息提取-Requests库入门
1、安装
Win 平台:“以管理员身份运行” cmd,执行 pip install requests
小测:
>>>import requests
>>>r=requests.get("http://www.baidu.com")
>>>print(r.status_code)
200
>>>r.text
2、Requests库的7个主要方法

3、Response对象的属性


4、理解Requests库的异常
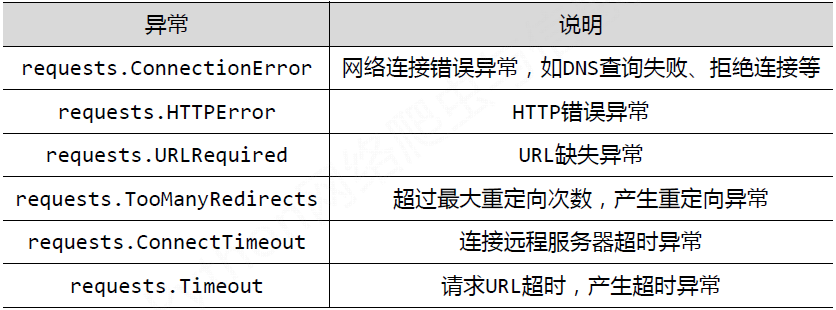

5、爬去网页的通用代码框架
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status() #如果状态不是200,引发HTMLError异常
r.encoding=r,apparent_encoding
return r.text
except:
return "产生异常"
if __name__=="__main__":
url="http://www.baidu.com"
print(getHTMLText(url))
6、HTTP协议
HTTP,Hypertext Transfer Protocol,超文本传输协议
HTTP是一个基于“请求与响应”模式的、无状态的应用层协议
HTTP URL的理解:URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源

 浙公网安备 33010602011771号
浙公网安备 33010602011771号