

读SWING: Exploiting Category-Specific Information.docx
Posted on 2012-07-18 16:57 licg 阅读(196) 评论(0) 收藏 举报
针对TAC2011的数据集和要求,作者提出了自己的多文本摘要系统:SWING。
其中前三个为一般特征,作者的主要贡献引入了和类别相关的特征4、5,以及和实体识别相关的特征6、7:
1、Sentence Position:数据主要是新闻稿,一般第一句话最重要。
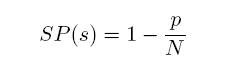
2、Sentence Length:避免短句产生的噪音,10这个数值由实验得出。
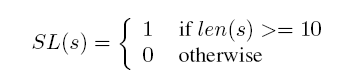
3、Bigram Document Frequency Score:
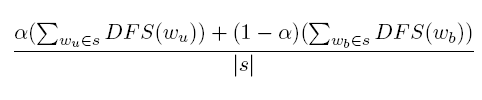
其中根据实验取0.3,是单个词(Unigram),是双词(Bigram),双词带有更多的信息,而单词则避免了数据集稀疏的问题。其中:
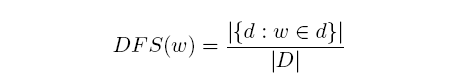
D表示相关主题的文档集合,即DFS(w)表示某个词在某个主题的文档中出现的概率。对TAC2011每个主题的相关文档为20。
4、CRS(Category Relevance Score):一个词和某一个类的相关性得分,与下一个特征相比,不考虑总体。
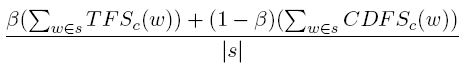
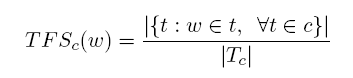
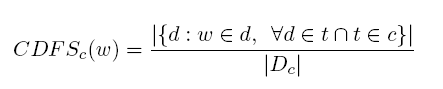
5、CKLD(Category KL Divergence):越大表示一个词的越容易出现在某一确定的类c中,与上一个特征相比考虑了总体C中各类c的分布。
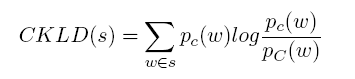
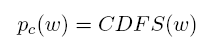
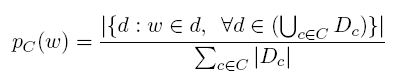
7、Top Entities for Corpus-Wide:语料中发现的一些Entities。赋值同上。
主要用MMR(Maximal marginal relevance)算法,具体定义如下:
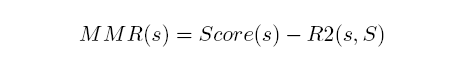
Score(s)是上面训练出来的模型给出的得分,S是已经选择的句子集合。R2即ROUGE-2。
去掉报社信息和文章发表时间等,如果去掉后摘要少于要求的100词,按照上面的选择句子的方式选择新的句子加入。
对更新文档摘要,作者重新定义了MMR,对和旧文档中的句子相似的句子进行惩罚,其他部分完全一样。具体如下:
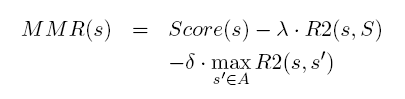
作者分别去掉某一个特征进行实验,实验结果显示特征BDFS很重要。图如下:

作者说可以看出在去掉特征BDFS后R2和RSU4都明显减小。结果还显示计算CKLD时将单词在文章中出现的频数计算进去能够使结果更好(原来只计算是否在某一文档中出现过),具体改变如下:
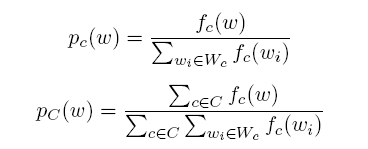

 浙公网安备 33010602011771号
浙公网安备 33010602011771号