第一模块 第5章 内存管理
内容概要
老师课件地址:
https://zhuanlan.zhihu.com/p/108683483
day05:(全为重点)
1. 垃圾回收机制详解(****)
引用计数
标记清除
分代回收
2. 与用户交互
接收用户输入
python3中
input
python2中
input
raw_input
格式化输出
%
str.format(python2.6以上版本支持)
f'' (python3.5以上版本支持)
3. 基本运算符
算数运算符
赋值运算符
=
增量赋值
链式赋值
交叉赋值
解压赋值
比较运算符
5.1 垃圾回收机制(了解)
什么是垃圾回收机制?
垃圾回收机制(简称GC)是python解释器自带的一种机制,专门用来回收不可用的变量值所占用的内存空间。
为什么要用垃圾回收机制?
程序运行过程中会申请大量的内存空间,而对于一些无用的内存空间,如果不及时清理的话,会导致内存使用殆尽(内存溢出),导致程序崩溃,因此管理内存是一件重要且繁琐的事情,而python解释器自带的垃圾回收机制会把程序员从繁杂的内存管理中解放出来。
垃圾回收机制原理分析
python的GC模块主要运用了“引用计数”(reference counting)来跟踪和回收垃圾。在引用计数的基础上,还可以通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用的问题。并且通过“分代回收”(generation collection)以空间换区时间的方式来进一步提高回收的效率。
程序在执行到变量定义语法的时候,会申请内存空间,把变量值存起来,并捆绑变量名,方便以后使用。如果变量值没有用了,就会进行回收。那么什么情况下,变量值才会没有用?
定义变量是为了使用,对变量值的引用方式包括以下几种:
1.直接引用
直接通过变量名来引用到变量值,例如:x = 10
2.间接引用
主要针对容器类型。例如:x = 10,lst = ['good', x],其中的x是一个变量。lst直接指向列表的内存地址,lst[1]可以访问到10。现在10身上的引用计数为2。
# 垃圾回收机制 # 1.直接引用 x = 10 y = x z = x # 2.间接引用 lst = ['good', x]
python解释器提供了垃圾回收机制,来帮助清理内存中不用的变量,它会在后台自动运行,自动帮助开辟内存空间,并在合适的时候回收内存空间。当一个值没有关联任何变量名时,就无法访问到该值,那么该值就是垃圾,会被回收。
什么是引用计数?
引用计数就是:变量值被变量名关联的次数
如:age = 18
变量值18被关联了一个变量名age,称之为引用计数为1
引用计数增加:
age = 18(此时,变量值18的引用计数为1)
m = age(把age的内存地址给了m,此时,m、age都关联了18,所以变量值18的引用计数为2)
引用计数减少:
age = 10(名字age先与值18接触关联,再与10建立关联,变量值的引用计数变为1)
del m(del不是删除的意思,是解除变量名m与变量值18的关联关系,此时,变量值18的引用计数变为0)
变量值18的引用计数一旦变为0,其占用的内存地址就应该被解释器的垃圾回收机制回收。
注意:创建变量时,涉及变量名和变量值在栈区和堆区的存储和映射问题,所以执行del()的时候,删除的是哪部分?删除的是变量名和变量值内存地址的对应关系,至于堆区变量值的删除,是python解释器的任务了。
5.2 列表在内存中存储的方式
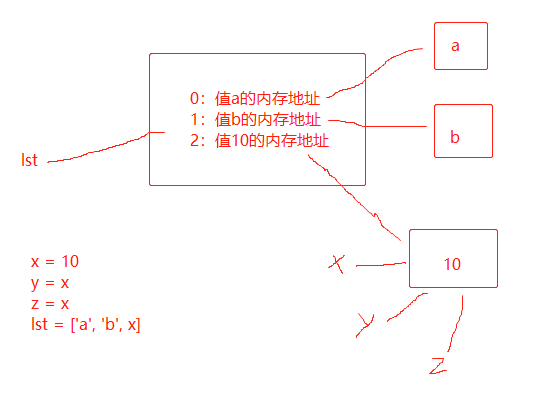
x = 10 lst = ['a', 'b', x] x = 123 print(lst[2]) # 结果是10
对于列表、字典等容器型的数据,可能会存在间接引用的情况。列表在内存中的存储方式和字典相似。
5.3 循环引用带来的内存泄露问题
其实,引用计数这种工作方式是存在缺陷的。
lst1 = [111,] lst2 = [222,] lst1.append(lst2) lst2.append(lst1) del lst1 # 解除lst1与列表值的直接关联 del lst2 # 解除lst2与列表值的直接关联 ''' 解除直接关联后,由于两个列表间存在间接引用,所以引用计数并不为0, 这就导致虽然这两个列表都成了垃圾,但是通过引用计数的机制并无法回收, 导致内存中对应的空间永远被占用,无法释放,这就是内存泄露。 为了解决这一问题,python中提出了标记清除机制。 '''
5.4 标记清除机制
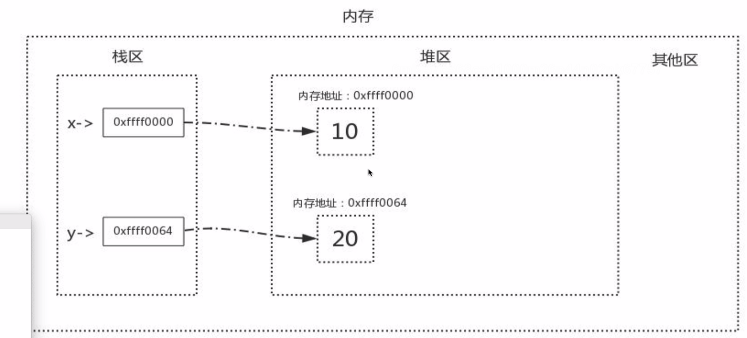
变量在内存中的存储:
变量值存储在堆区,对应一个内存地址,变量名和变量值的内存地址存在栈区。垃圾回收机制管理的实际上是堆区,当堆区的数据被回收后,栈区的数据自然就被清除掉了。
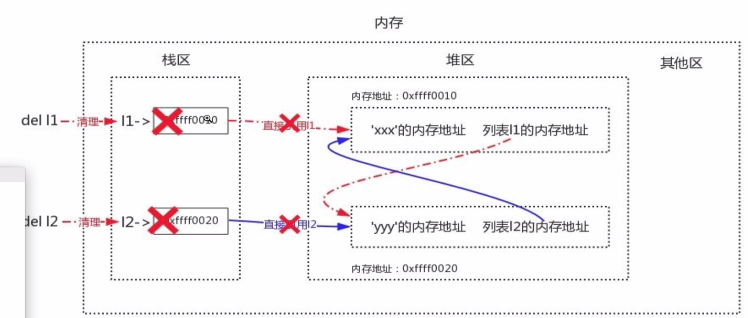
对于循环引用中出现的内存泄露问题,可以通过标记清除机制解决。不过标记清除机制不是时时刻刻启动运行的,会在python应用程序内存空间马上不够用的时候,会将整个程序停下来,扫描栈区,把所有栈区能引用到的值都标记为存活,其他未标记为存活会被清除。例如:从l1开始,沿着线从左往右,一直往下捋,凡是能引用到、用到的都标记为存活,最后剩下未标记为存活的会被清除。
5.5 分代回收
除了循环引用导致的内存泄露问题外,引用计数回收机制还存在效率方面的缺陷,为了解决效率方面的缺陷,即降低扫描频率,引入了分代回收的方案。
注意:垃圾回收机制中主要的是引用计数,标记清除和分代回收只是对其进一步完善。
分代回收的核心思想是:在历经多次扫描的情况下,都没有被回收的变量,gc机制就会认为,该变量是常用变量,gc对其扫描的频率会降低,具体实现原理如下:
分代指的是根据存活时间来为变量划分不同等级(也就是不同的代)
新定义的变量,放到新生代这个等级中,假设每隔1分钟扫描新生代一次,如果发现变量依然被引用,那么该对象的权重(权重本质就是个整数)加一,
当变量的权重大于某个设定得值(假设为3),会将它移动到更高一级的青春代,青春代的gc扫描的频率低于新生代(扫描时间间隔更长),
假设5分钟扫描青春代一次,这样每次gc需要扫描的变量的总个数就变少了,节省了扫描的总时间,接下来,青春代中的对象,也会以同样的方式被移动到老年代中。
也就是等级(代)越高,被垃圾回收机制扫描的频率越低。5.6 用户交互之接收用户输入
老师课件网址:
https://zhuanlan.zhihu.com/p/108684774
# 接收用户的输入 # 在python3中,input会将用户输入的所有内容都存成字符串 username = input('请输入您的账号:') # 注意前面加变量名进行接收,否则会被清理 print(username, type(username)) # 如果要使用int类型的数据,则需要进行转化 age = input('请输入您的年龄:') age = int(age) # int只能将纯数字的字符串转化为整型 # 在python2中: # raw_input():用法与python3的input一模一样 # input():要求用户必须输入一个明确的数据类型,输入的是什么类型,就存储成什么类型。这会给用户带来诸多不便,所以到了python3就被砍掉了。
python2中的input示例:
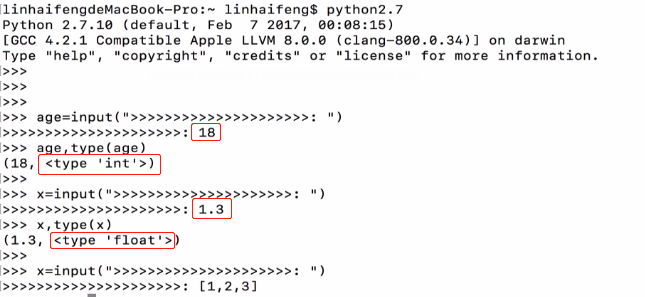
5.7 输出之格式化输出
老师课件网址:
https://zhuanlan.zhihu.com/p/110406030
# 字符串格式化输出 # 1.%,适用于所有版本 # 1.1 值按照位置与%s一一对应,少一个不行,多一个也不行 res1 = 'my name is %s, like %s'%('apple', 'eating') # 其中%s中的s指string,后面传的值必须是字符串类型的,且数目要对上。 res2 = 'I like %s'%'playing' # 如果只有一个值,可以不用加括号 print(res1) print(res2) # 1.2 如果记不住顺序就改成字典形式的 res3 = 'my name is %(name)s, my age is %(age)s' %{'name':'egon','age':'18'} print(res3) # 注意:虽然%s看似能接受的是字符串类型,实际上可以接收任意类型的数据 res4 = 'my age is %s' %18 print(res4) res5 = 'I like %s' %['playing','singing'] print(res5) res6 = 'My students include %s' %{'name1':'apple','name2':'orange'} print(res6) # 1.3 %d 表示接收整型数据,如果传的不是整型就会报错 res7 = 'my age is %s' %20 print(res7)
# %的输出,%%才能输出一个%
print('成功概率为%s%%'%97) # 结果:成功概率为97% # 2. str.format,适用于2.6及以上版本,推荐使用这种方式 # 2.1 按照位置传值 res8 = 'my name is {}, my age is {}'.format('apple',18) print(res8) # 2.2 可以通过索引传值 res9 = 'my name is {0}{0}, my age is {1}'.format('apple',18) print(res9) # 2.3 按照key = value传值,打破位置的限制 res10 = 'my name is {name}, my age is {age}'.format(name='apple',age=18) print(res10)
# 2.4 format新增(填充与格式化)
print('{x:=<10}'.format(x='开始执行')) # <表示文本左对齐,10表示总长度为10,如果不够则用=填充,结果:开始执行======
print('{x:=>10}'.format(x='开始执行')) # >表示右对齐,结果:======开始执行
print('{x:=^10}'.format(x='开始执行')) # ^表示居中,结果:===开始执行===
# format来控制小数点精度,四舍五入
print('{salary:.3f}'.format(salary=12345.45657)) # 3f中f指float,结果:12345.457
# 3. f,适用于python3.5及以上版本
name = input('请输入你的名字:')
age = input('请输入你的年龄:')
res11 = f'my name is {name}, my age is {age}'
print(res11)
# 如果输出的格式化字符中含有{},需要进行如下处理:
name = 'apple'
print(f'名称为:{{{name}}}')
# f'{表达式}',{}内的内容可以被当作表达式运行
print(f'{10+3}') # 结果:13
print(f'10+3') # 结果:10+3
f'{print("aaa")}' # 结果:aaa
# 速度上的区别:f > str.format > % # 考虑到python版本的兼容性和速度,推荐使用str.format
注意:常用的场景是,使用输入值对应的变量名进行格式化输出,所以推荐使用str.format和f。
综合考虑到python版本的兼容性和速度,推荐使用str.format。
5.8 基本运算符之算数运算与比较运算
老师课件地址:
https://zhuanlan.zhihu.com/p/108684774
算数运算符:
+
注意:+不仅适用于数字之间相加,也适用于字符串之间的拼接,不过不建议使用+对字符串进行拼接操作。
-
*
/
//:又称地板除,只不留整数部分,不是四舍五入。
%:取余/取模
**:次幂
比较运算符:== != > >= < <=
5.9 基本运算符之赋值运算符
老师课件地址:
https://zhuanlan.zhihu.com/p/108684774
注意:*_表示匹配后面的所有元素,起着占位符的作用。_可以用在变量名中,但是不要将其用在变量名的开始和结尾处,这是约定俗成的。
# 解压赋值取前几个值 nums = [1,2,3,4,5,6] a,b,c,*_ = nums print(a,b,c) print(_) # 取后三个值 *_,a,b,c = nums print(a,b,c) # 不能取中间的两个值,以下代码会报错 # *_,a,b,*_ = nums # print(a,b) # 注意,解压字典默认解压出来的是key dic = {'a':1,'b':2,'c':3} x,y,z = dic print(x,y,z) # 结果是a,b,c
考试题目:
1.简单描述定义一个变量x=10,在内存中的栈区或堆区的存放情况
栈区存放的是变量名与内存地址的映射关系,所以可以简单地理解为变量名存内存地址
堆区存放的是变量值
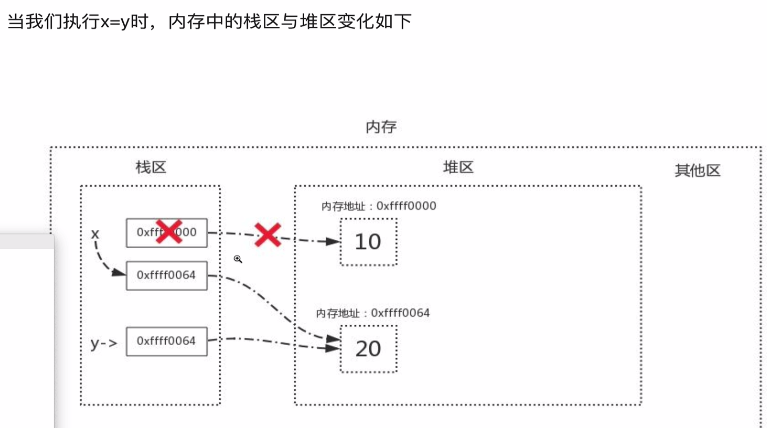
强调:变量名的赋值(x = y),变量名的传参(print(x)),传递的都是栈区的数据,而且栈区的数据是变量名与内存地址的对应关系,或者说是对值的引用
示例1:
x = 10
y = 20
y = x
以上 y = x 的赋值,不是将x对应的值10传递给y,而是将10对应的内存地址传递给y。所以,变量名之间的赋值操作,传递的不是变量值本身,而是变量值对应的内存地址。
示例2:
lst = [111, 222, 333]
lst1 = lst
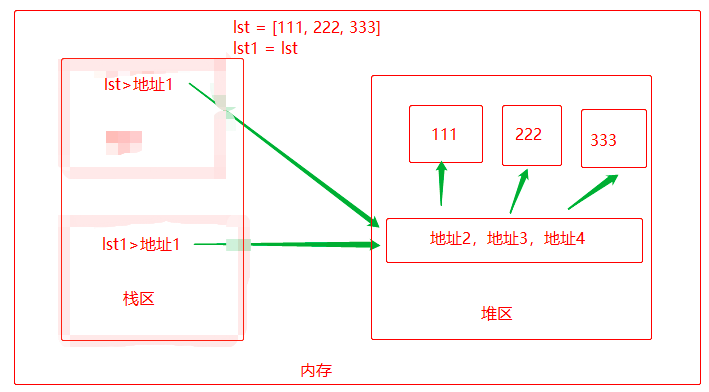
如果,lst1[2] = 'aaa',那么lst1 = [111, 222, 'aaa'],lst = [111, 222, 'aaa'],原理如下:
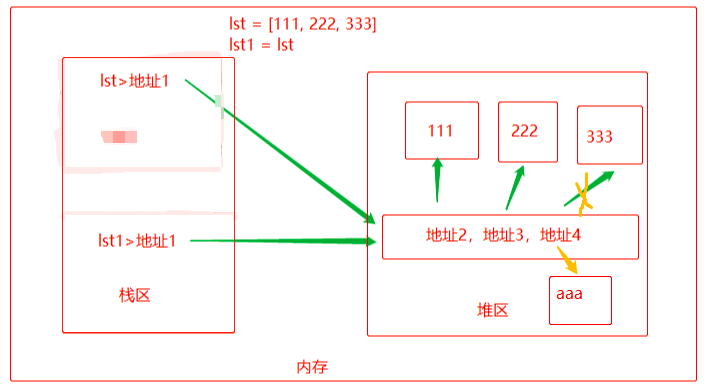
请注意以下问题:间接引用和直接引用,重新赋值后存在不同:
直接引用示例:
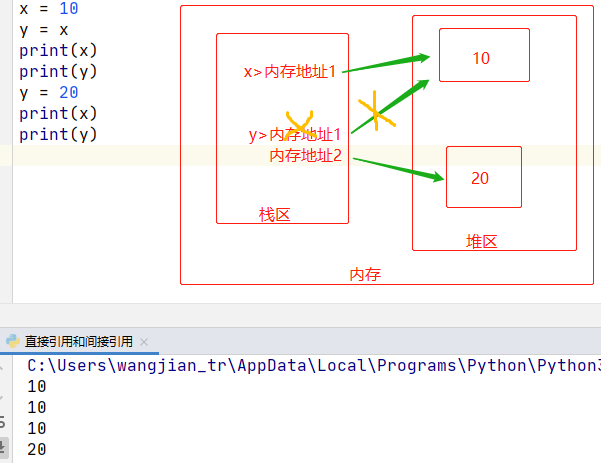
2.简述什么是直接引用、什么是间接引用
3.简单描述python解释器垃圾回收机制的引用计数、标记清除、分代回收
4.写一段程序
接收用户输入的用户名、年龄、性别,然后选取最优格式化字符串的方式,按照如下:
我的姓名是:xxx
我的年龄是:xxx
我的性别是:xxx
5.算数运算符相关
用示例演示
取模运算
增量赋值
交叉赋值
链式赋值
解压赋值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号