【kubernetes入门到精通】Kubernetes的健康监测机制以及常见ExitCode问题分析「探索篇」
kubernetes进行Killed我们服务的问题背景
无论是在微服务体系还是云原生体系的开发迭代过程中,通常都会以Kubernetes进行容器化部署,但是这也往往带来了很多意外的场景和情况。例如,虽然我们已经将JVM堆内存设置为小于Docker容器中内存及K8S的Pod的内存,但是还是会被K8s给无情的杀掉(Kill -9 / Kill -15)Killed。当发生了Killed的时候,我们该如何分析和判断呢?在此我们介绍一下K8s的Killed的Exit Code编码。
kubernetes健康检测体系之探针
K8s中的探针用来对pod中容器的状态进行检测,有3种探针,存活探针、就绪探针、启动探针。
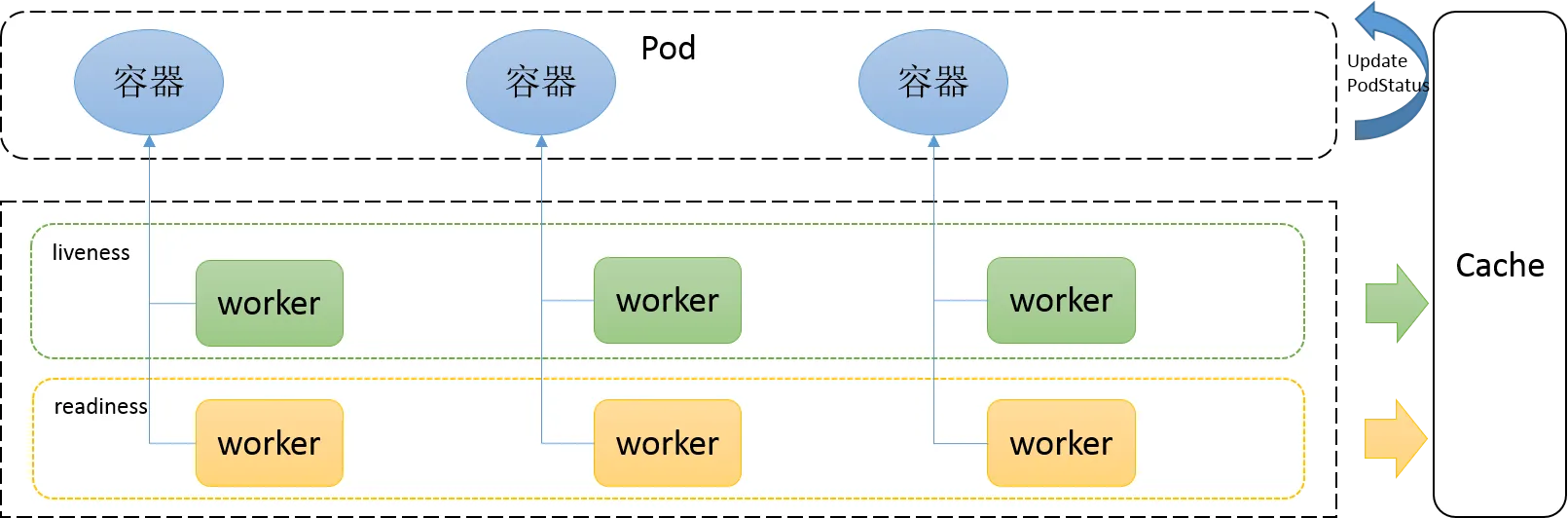
kubernetes如何监控和管理我们的Pod的运行状态
Kubernetes中的健康检查主要使用就绪性探针(readinessProbes) 和 存活性探针(livenessProbes) 来实现,service即为负载均衡,k8s保证service后面的pod都可用,是k8s中自愈能力的主要手段,主要基于这两种探测机制,可以实现如下需求:
- 异常实例自动剔除,并重启新实例
- 多种类型探针检测,保证异常pod不接入流量
- 不停机部署,更安全的滚动升级
存活探针 — livenessProbes
kubelet使用 存活探针 来确定什么时候要重启容器。 例如,存活探针可以探测到应用死锁(应用程序在运行,但是无法继续执行后面的步骤)情况,重启这种状态下的容器有助于提高应用的可用性,即使其中存在缺陷。
就绪探针 — readinessProbes
kubelet使用就绪探针可以知道容器何时准备好接受请求流量,当一个 Pod 内的所有容器都就绪时,才能认为该 Pod 就绪。 该指针用来指示容器是否准备好为请求提供服务。如果就绪态探测失败,kubelet将该Pod提供的所有服务的endpoint列表中删除该Pod的 IP地址。
与存活探针的区别
当容器未通过检查准备,则不会被终止或重新启动。存活探针通过杀死异常的容器并用新的容器去替代他们的工作,而就绪探针确保只有准备好处理请求的pod才能在服务集群中。
启动探针 — startupProbes( 1.17 版本新增)
kubelet使用启动探针来了解应用容器何时启动。 如果配置了这类探针,你就可以控制容器在启动成功后再进行存活性和就绪态检查, 确保这些存活、就绪探针不会影响应用的启动。
启动探针可以用于对慢启动容器进行存活性检测,避免它们在启动运行之前就被杀掉,如:使用了启动探针,则所有其他探针都会被禁用,直到此探针成功为止。如果启动探测失败,kubelet将杀死容器,而容器依其重启策略进行重启。
探针的3种机制
每种探测机制支持三种健康检查方法,分别是命令行exec,httpGet和tcpSocket,其中exec通用性最强,适用与大部分场景,tcpSocket适用于TCP业务,httpGet适用于web业务。
- HTTP GEt:该类型的探针通过容器的IP地址、端口号及路径调用 HTTP Get请求,如果响应的状态码大于等于200且小于400,则认为容器 健康。
- TcpSocket:该类型的探针尝试与容器指定端口建立TCP连接,如果端口打开,则诊断被认为是成功的。
- Exec(自定义健康检查):该类型的探针在容器内执行任意的命令,如果命令退出时返回码为0,则认为诊断成功。
配置和设定livenessProbes探针
通过在yaml文件中pod的spec部分的containers里面添加一个字段livenessProbe来添加存活指针:
livenessProbe执行模式执行探针控制(httpGet)
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: registry.k8s.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3

Exec执行模式执行探针控制(exec)
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: registry.k8s.io/busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
livenessProbe执行模式执行探针控制(tcpSocket)
apiVersion: v1
kind: Pod
metadata:
name: goproxy
labels:
app: goproxy
spec:
containers:
- name: goproxy
image: registry.k8s.io/goproxy:0.1
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
每次探测都将获得以下三种结果之一:
- Success(成功):表示容器通过了诊断。
- Failure(失败):表示容器未通过诊断。
- Unknown(未知):表示没有正常进行且诊断失败,因此不会采取任何行动。
容器退出状态码的区间
Exit Codes的取值范围必须在0-255之间。可以参考: https://tldp.org/LDP/abs/html/exitcodes.html ,如下图所示。

- 0:表示正常退出
- 1-128:一般程序自身原因导致的异常退出状态区间在 1-128 (这只是一般约定,程序如果一定要用129-255的状态码也是可以的)
- 129-255:外界中断将程序退出的时候状态码区间在129-255,(操作系统给程序发送中断信号,比如 kill -9 是 SIGKILL)
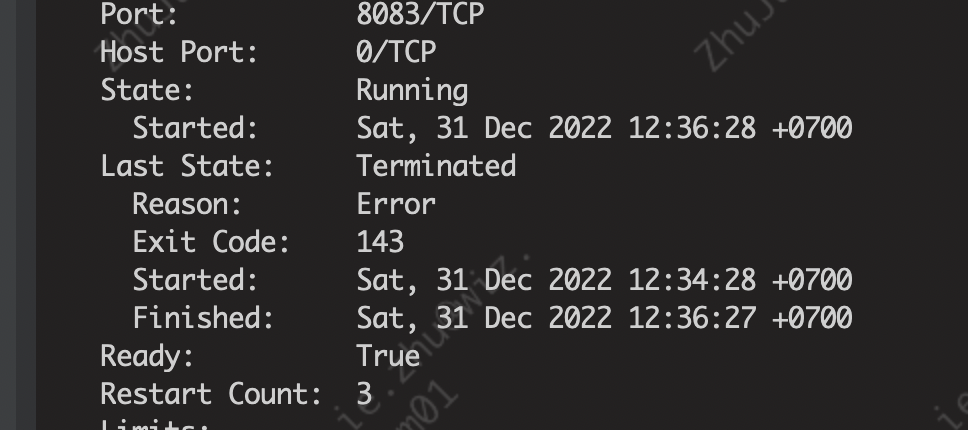
查看 Pod 退出状态码
$ kubectl describe pods ${pod-name}
如下图所示:
Exit Code 0
退出代码0表示特定容器没有附加前台进程,该退出代码是所有其他后续退出代码的例外,这不一定意味着发生了不好的事情。如果开发人员想要在容器完成其工作后自动停止其容器,则使用此退出代码。比如:kubernetes job在执行完任务后正常退出码为 0
Exit Code 1
程序错误,或者Dockerfile中引用不存在的文件,如 entrypoint中引用了错误的包程序错误可以很简单,例如 “除以0”,也可以很复杂,比如空引用或者其他程序 crash
Exit Code 139
Exit Code 139: Indicates failure as container received SIGSEGV
表明容器收到了 SIGSEGV 信号,无效的内存引用,对应kill -11,一般是代码有问题,或者 docker 的基础镜像有问题
Exit Code 143
Exit Code 143: Indicates failure as container received SIGTERM
表明容器收到了 SIGTERM 信号,终端关闭,对应kill -15,一般对应 docker stop 命令,有时docker stop也会导致Exit Code 137,发生在与代码无法处理SIGTERM的情况下,docker进程等待十秒钟然后发出 SIGKILL 强制退出。
Exit Code 137
Exit Code 137: Indicates failure as container received SIGKILL
表明容器收到了 SIGKILL 信号,进程被杀掉,对应kill -9,引发SIGKILL的是docker kill。这可以由用户或由docker守护程序来发起,手动执行:docker kill(Manual intervention or ‘oom-killer’ [OUT-OF-MEMORY]) 被手动干预杀死进程,或者违反系统限制被杀
137 比较常见,如果 pod 中的limit 资源设置较小,会运行内存不足导致 OOMKilled,此时state 中的 ”OOMKilled” 值为true,你可以在系统的 dmesg -T 中看到 oom 日志
内存溢出问题
此状态码一般是因为 pod 中容器内存达到了它的资源限制(resources.limits),一般是内存溢出(OOM),CPU达到限制只需要不分时间片给程序就可以。因为限制资源是通过 linux 的 cgroup 实现的,所以 cgroup 会将此容器强制杀掉,类似于 kill -9,此时在 describe pod 中可以看到 Reason 是 OOMKilled
还可能是宿主机本身资源不够用了(OOM),内核会选取一些进程杀掉来释放内存,不管是 cgroup 限制杀掉进程还是因为节点机器本身资源不够导致进程死掉,都可以从系统日志中找到记录:
ubuntu 的系统日志在 /var/log/syslog,centos的系统日志在 /var/log/messages,都可以用 journalctl -k 来查看系统日志。
本文来自博客园,作者:洛神灬殇,转载请注明原文链接:https://www.cnblogs.com/liboware/p/17017039.html,任何足够先进的科技,都与魔法无异。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号