基于 Linux 调优(基于 centos7)
基于Linux调优(基于centos7)

|
版本标识 |
V1 |
|
编制单位 |
李斌(长沙卓应教育咨询有限公司) |
|
编制日期 |
2022年2月17日 |
第一节 cpu、内存篇
(i/O:磁盘有关。Page:内存有关。缓存:CPU有关。)
响应时间
吞吐量-懂软件
硬件
1、关于性能调优的效率和问题 2、了解硬件
3、CPU指标 4、缓存介绍
5、内存架构
cpu、内存、磁盘、网卡、其他
1、关于性能调优的效率和问题
第一个:Busness Level Tuning (业务调优)
第二个:Application Level Tuning (应用级调优,关掉不必要的服务)
第三个:kernel Level Tuning (内核调优)
------------------------------------------------------------------
vim /etc/rsyslog.conf
-:#让日志滞后写,不立即存盘
没有-:立即存盘
(1)、CPU介绍:
1、cpu-L1/L2/L3...缓存-内存-磁盘
2、cat /proc/cpuinfo | grep lm #64位指令集
3、cat /proc/cpuinfo | grep vmx #是否支持硬件虚拟化
4、cat /proc/cpuinfo | grep pam #是否支持64位操作系统
5、lscpu | grep Thread(s) per core: 1 #1不支持超线程
6、查看缓存
[root@libin4 ~]# lscpu | grep L
L1d #数据缓存
L1i #指定缓存
7、cat /proc/interrupts #查看CPU中断的频率
8、lshw -class memory
9、cat /proc/cpuinfo | grep sizes #查看cpu物理地址大小与虚拟地址大小
----------------------------------------------------------------
cat /proc/cpuinfo | grep "physical id" | sort | uniq 物理CPU个数:
cat /proc/cpuinfo | grep "cores" | uniq 每个物理CPU的逻辑核数:
cat /proc/cpuinfo | grep "processor" | wc -l 系统整个cpu线程数:
注:没开启超线程的情况下,系统的cpu线程数=物理CPU个数*每个物理CPU的逻辑核数*1,因为每个逻辑核只跑了1个cpu线程,
如果开启了超线程,那么cpu线程数=物理CPU个数*每个物理CPU的逻辑核数*N,因为每个逻辑核跑了2个cpu线程。所以,上面的24=2*6*2,可以判断当前开启了超线程。
------------------------------------------------------------------------------------------------------------------------
CPU(s): 4
Thread(s) per core: 1 #一个物理cpu 2核, 2核4线程
Core(s) per socket: 2
------------------------------------------------------------------------------------------------------------------------
#lscpu 查看硬件信息
参数选项:
-a, –all: 包含上线和下线的cpu的数量,此选项只能与选项e或-p一起指定
-b, –online: 只显示出上线的cpu数量,此选项只能与选项e或者-p一起指定
-c, –offline: 只显示出离线的cpu数量,此选项只能与选项e或者-p一起指定
-e, –extended [=list]: 以人性化的格式显示cpu信息,如果list参数省略,输出所有可用数据的列,在指定了list参数时,选项的字符串、等号(=)和列表必须不包含任何空格或其他空白。比如:’-e=cpu,node’ or ’–extended=cpu,node’
-h, –help:帮助
-p, –parse [=list]: 优化命令输出,便于分析.如果省略list,则命令的输出与早期版本的lscpu兼容,兼容格式以两个逗号用于分隔cpu缓存列,如果没有发现cpu缓存,则省略缓存列,如果使用list参数,则缓存列以冒号(:)分隔。在指定了list参数时,选项的字符串、等号(=)和列表必须不包含空格或者其它空白。比如:’-e=cpu,node’ or ’–extended=cpu,node’
-s, –sysroot directory: 为一个Linux实例收集CPU数据,而不是发出lscpu命令的实例。指定的目录是要检查Linux实例的系统根
-x, –hex:使用十六进制来表示cpu集合,默认情况是打印列表格式的集合(例如:0,1)
显示格式:
Architecture: #架构
CPU(s): #逻辑cpu颗数
Thread(s) per core: #每个核心线程
Core(s) per socket: #每个cpu插槽核数/每颗物理cpu核数
CPU socket(s): #cpu插槽数
Vendor ID: #cpu厂商ID
CPU family: #cpu系列
Model: #型号
Stepping: #步进
CPU MHz: #cpu主频
Virtualization: #cpu支持的虚拟化技术
L1d cache: #一级缓存(google了解下,这具体表示表示cpu的L1数据缓存)
L1i cache: #一级缓存(具体为L1指令缓存)
L2 cache: #二级缓存
L3 XXX:#三级缓存,共享缓存,也可以独立
(L:一级比一级大,一级比一级慢,但是比内存要快,缓存CPU与内存的中介)
----------------------------------------------------------------------------------------------------------------
(2)、X86架构 、AMD架构 #查看线程
[root@libin4 ~]# cat /proc/cpuinfo | grep CPU
[root@libin4 ~]# cat /proc/cpuinfo | grep AMD
X86架构特点:
1、X86:I/O address
2、IRQ 中断请求
3、DMA数字信号处理,用户数据交换
AMD,物理cpu,多CPU连接手段
FSB--NUMA(QPI) Hyper transport
关于NUMA架构链接:https://blog.csdn.net/qq_20817327/article/details/105925071
------------------------------------------------------------------------------------------------------------------
(3)、内存条
内存时钟频率*4*2*内存位数 bit/8=带宽
ECC校验
balloon KSM(kernel samepage merging) 内核同页合并,冒泡技术
[root@libin ~]# cat /proc/meminfo 配置文件
第二节 存储、网络篇
1、存储介绍 2、 存储表现形式
3、外部存储类型 4、磁盘的设计
5、硬盘的表现 6、SSD特点
7、SSD工作原理 8、SSD垃圾回收系统
9、块设备到接口的速度 10、网络调优
11、了解硬件
(4)、存储介绍
1、机械硬盘 #内存、转速、缓存(合并读写)、GB/s除8为传速、传输速率、对奇(物理扇区磁盘)。
2、固态硬盘(SSD)
3、存储表现形式
第一种:硬件raid
第二种:接口类型。直接接驳的这些存储有:IDE,SATA,SAS
SAN:存储区域网络(Storage Area Network
NAS:网络接入存储(Network-Attached Storage)
4、外部存储类型
第一种,SCSI与总线之间接驳
第二种,Fibre Channel。光纤接驳,这种见得比较多。
第三种,iSCSI。是基于互联网iscsi指令集的传输,主要用来做冗余。
(5)、磁盘的设计
1、CLV :早期磁盘,密度比较慢,较容易坏,过于复杂
2、CAV :密度增加,浪费大
3、ZCAV:现在机械硬盘结构,磁盘分为对为若干个区域
ssd(移动硬盘)--SLC(企业级,一个闪存单元存一个位)-MLC(性价比较好,容量大)--TLC--QLC
:闪存频率越小,使用寿命越长
(6)、SSD特点
1、第一点,首先ssd是个电子的,它是个电子磁盘,没有机械部件.
2、第二点,它的启动时间约等于0,它是电子的,走的是电路,没有起始时间记录。
3、第三点,它读写的时候反应速度非常的快,响应时间非常的低。
4、第四点,它非常的安静,不怕震动,也不怎么发烫,不怕磁铁,非常的轻,用电又少.
5、第五点,价格比较高。而且存储容量还没办法变得非常的巨大
(7)、SSD工作原理
( /etc/fstab discard 可以优化SSD垃圾回收系统)
1、第一种,多数是MLC结构。比较便宜,稍微慢一点,容量也比较多一点。原因就是一个闪存单元里面可以存若干位,如果说一个单元中存多位,那就说明这个数据更新的频率有可能变大,寿命会比较短。
2、第二种,SLC结构很贵,容量比较少,一个闪存单元中只存一位,说明闪的次数少。这种寿命比较长。
(8)、块设备到接口的速度
1、IDE已经退休了,每秒133M的峰值。
2、sata2比较普遍,每秒300M。已经满足传统磁盘的需求。
3、sata3台式机上很普遍。每秒峰值600M
4、SCSI接口磁盘的话,每秒峰值320M。以前都在服务器上都能见得到。
5、USB2和USB3相差十倍,不过这都是理论值。
6、ISCSI+Giga,它的带宽取决于网卡,一个千兆网卡除8之后,大概就得到了125M的峰值。
7、光纤通道,大概就530M。光纤有一个很大的优势,它可以距离很远,其他只能是近距离。
8、PCIE:高速串行计算机扩展总线标准
# lspci列出总线接口
# lspci -v/-vv/-vvv列举出详细信息
#lsusb列举总线设备
# lsusb -v/-vv/-vvv列举出详细信息,-v,-vv,-vvv
#smartctl -a /dev/sda1列举一个磁盘的详细信息
#lshw -short收集硬件的详细详细
#lshw -c disk列举虚拟磁盘的信息
# ras-mc-ctl --summary关于硬件内存控制器事例摘要
(9)、网络调优
1、以太网的速度取决于网卡到交换时候的链接速率。
2、做网络设计的时候,通常都要把网络隔离开来,尤其是虚拟化,毕竟存储是飘在网络上的;虚拟桌面(VDI)也是通过网络传输的,这是非常大的流量;管理数据的话可能是一个单独的网络;最重要的是用户数据,保证用户数据第一时间响应。所以性能调优的思想,就是把这些网络给拆开,每人有自己的冲突域。
3、网卡是否支持虚拟化。现在的高端网卡在新建虚拟机的时候,可以直接分配给每个虚拟机,或者把一个网卡共享分给某些虚拟机
# ethtool eth0 查看网卡信息
#ip link show 查看各网卡连接状态
#sosreport 用于收集系统配置并诊断信息后输出结论文档
#xz -d XXX.tar.xz 释压
#tar -xvf XXX.tar.xz 解压
#tar -xJf xxx.tar.xz -C /tmp 也可以指定解压到tmp下,man tar看用法
注:sosreport可以参考 https://www.ywnz.com/linux/sosreport/
#powertop 查看最耗电的进程
#pstree 查看进程树
#cd /etc/init.d/ redhat6的所有服务路径
#cd /usr/lib/systemd/system redhat7的所有服务路径
cat /boot/grub2/grub.cfg 系统引导文件

第三节 监测系统性能命令
1、vmstat 2、iostat 3、mpstat 4、sar 5、awk 6、gnuplot
7、PCP工具 8、ps使用
1、vmstat #调取系统的状态
#vmstat -t 1 #每秒循环一次

1、vmstat
这条命令执行的时候,可以x显示系统当前的状态
vmstat 1 #一秒钟都显示一次。
第一列,r代表着当前在cpu队列里面有几个正等待着被运行。
第二列,b代表着当前我们这一次系统的探索过程中,有哪一些进程已经进入到不可中断式睡眠里面。
第三列,与内存相关的。意思就是当前已经使用的交换分区的大小。
第四列,内存剩余量。
第五、六列,buffer里面存放的是用来描述某个文件的元数据,它就在buffer cache里面存着。
第七、八列,so io 写入swap磁盘,写出swap磁盘
第九列,bi就是block in。代表着读磁盘的量。
第十列,bo就是block out。代表着写磁盘,写优先于读。
第十一、十二 进入,进出系统
第十三us、第十四列sy, 运行非内核时间,运行内核时间
第十五列,闲置io等待时间
第十六列wa,io的等待时间
第十七列,虚拟机占用的大小,量化虚拟机
压力测试第一列:
#dd if=/dev/zero of=/dev/null 无限写入文件,vmstat -t 1 查看第一列变化
#killall -9 dd 另外一个终端kill掉vmstat查看r变化
压力测试第二列:
#dd if=/dev/sda of=/dev/null 无限写入文件到硬盘,vmstat -t 1 查看第一列变化
#killall -9 dd 另外一个终端kill掉vmstat查看d变化
#echo 3 > /proc/sys/vm/drop_caches 清除所有页缓存free会增加,操作会使某些在缓存中的数据丢失
#vmstat --unit M 1 以M的单位一直调取系统状态
2、iostat、iotop #io监测
# yum install -y sysstat-10.1.5-19.el7.x86_64
# yum install -y iotop-0.6-4.el7.noarc
iostat -x sda #显示提供每个存储设备的io统计的详细报告,磁盘信息
iostat -x sda 1 #每秒钟扫一次
iostat 1 3 #每秒扫一次,共扫3次
iostat -yz 1 4 #显示磁盘cpu的平均值,每秒执行一次,执行四次
man iotop
iotop -o #显示在运行的IO进程和线程
-c #仅显示CPU使用情况
-d #仅显示设备利用率
-k #显示状态以千字节每秒为单位,而不使用块每秒
-m #显示状态以兆字节每秒为单位
-p #仅显示块设备和所有被使用的其他分区的状态
-t #显示每个报告产生时的时间
-V #显示版号并退出
-x #显示扩展状态
第一列, 读和请求的合并数量。
第二列,第二列是写合并。
第三列,读请求数。
第四列,写请求数。
第五列,每秒钟能读多少个扇区
第六列,每秒钟能写多少个扇区
第七列,平均每次提交请求的一个大小值。
第八列,每秒钟平均的队列长度。
第九列, 平均的服务时间。
第十列,平均服务的等待时间
第十一,十二列,平均读与写的等待时间
第十四列,代表着磁盘的利用率。
Device #监测设备名称
rrqm/s #每秒需要读取需求的数量
wrqm/s #每秒需要写入需求的数量
r/s #每秒实际读取需求的数量
w/s #每秒实际写入需求的数量
rsec/s #每秒读取区段的数量
wsec/s #每秒写入区段的数量
rkB/s #每秒实际读取的大小,单位为KB
wkB/s #每秒实际写入的大小,单位为KB
avgrq-sz #需求的平均大小区段
avgqu-sz #需求的平均队列长度
await #等待I/O平均的时间(milliseconds)
svctm #I/O需求完成的平均时间
%util #被I/O需求消耗的CPU百分比
3、mpstat #返回cpu的详细信息
mpstat 这条命令也是可以返回cpu的详细信息,也可以给它带个时间mpstat 1
mpstat -P ALL 1 4 #监测所有CPU,1秒监测一次,监测4次

4、sar #企业级监控
以24小时制命令去执行:LANG=C sar -q/-b -t 1
#yum provides "sar"
# yum install -y "sysstat-10.1.5-19.el7.x86_64"
企业级监控。是从unix上开发过来的,这条命令对系统的影响非常的小。
sar需要提前安装sysstat这个软件包,然后它的基本工作原理就是每隔一段时间(默认十分钟)
#cat /etc/cron.d/sysstat #以超级用户的身份之下执行计划任务
*/10 * * * * root /usr/lib64/sa/sa1 1 1 #每隔十分钟以超级用户执行,每一秒钟取一次数据
53 23 * * * root /usr/lib64/sa/sa2 -A
#cat /etc/sysconfig/sysstat # sar的配置文件
HISTORY=28 存28份,大于28份会按月
COMPRESSAFTER=31 保存31天
SADC_OPTIONS="-S DISK" #给每个磁盘io进行检测
sar 命令按回车的时候,它拿的是当天的,而且是从开机的时候开始一直到最后一次收集数据时候的样式。所以sar取的是历史,mpstat取的是现状。
sar -q #查看cpu负载,可以查看整体的负载状况
Sar -q -t 1 #每隔一秒提取一次数据

第一列,时间。
第二列, 有几个进程在那里等着没处理。
第三列, 进程列表数量。代表着有多少个进程在跑。
第四—六列, 操作系统中每一分,每五分,每十五分的负载状况
sar -b #汇报I/O状况。
LANG=C sar -b #设置为24小时制,否则会有上午AM,下午PM,可以写进别名

第一列,时间
第二列, 代表着每秒传送的数量。意思是每秒有多少个transfer,这个transfer是没有大小的。
第三列, 读的transfer
第四列, 写的transfer。
第五列, 每秒钟多少个读block。
第六列, 每秒钟多少个写block。
sar -P 0 #查看第一颗cpu的状态

sar -n DEV #统计所有的网卡包
sar -n DEV 2 10 #2秒钟查看一次,查看10次网卡包

第一列,时间
第二列,网卡
第三列,接收包
第四列,发送多少包
第五列,按k来算。接收多少k。
第六列,发送多少k。
第七、八列,有多少做了压缩了。
第九列,有多少个广播包
sar -n EDEV #错误的 网卡网络包

2:网卡
3:网络包错误
4:发出包的错误
5:多少次碰撞
6:发送包丢包情况
7:网卡产生的错误
8:帧上面产生的错误
sar -dp #查看块设备
sar -dp 2 #每隔2秒查看一次块设备

sar -u 1 5 #监控cpu,每1秒监控一次,共执行监控5次

3列:用户模式下占用cpu的百分率
4列:用户空间优先级的百分比
5列:系统模式下的百分比
6:io等待百分比
8:空闲百分比
测试:
dd if=/dev/zero of=/dev/null & #无限写入,查看cpu使用率
killall -9 dd #杀掉dd进程,再看使用率,明显减低
#Killall的提供包: #yum search "killall" yum install -y psmisc.x86_64

rm /tmp/* -fr && sar -u 1 20 -o /tmp/sar.data #删除 /tmp下的所有文件,并将sar 每秒执行一次 共执行20次文件导入(-o 二进制文件)保存到 /tmp/sar.data
cd /tmp/ && sar -f sar.data #查看写入的文件

sar -f /tmp/sar.data #监控文件cpu使用率

cd /var/log/sa/ && ls #sa所监控的日志目录sa的,数字代表日期
cd /var/log/sa/ && sar -f sa12 #-f为查看sar12号 监控的信息
cd /var/log/sa/ && sar -b -f sa12 #查看12号sar监控cpu负载信息
5、awk
1)、$1来表示哪一列,用$NF表示最后一列
2)、BEGIN。意思就是说在做格式化数据的时候,希望在开始显示一行标题。END,就是处
理完数据后写一个结束语。
示例1:把passwd文件第一列切出来
awk -F: '{print $1} ' /etc/passwd
awk -F: '{print $NF}' /etc/passwd #:把passwd文件最后一列切出来
#以“:”为分隔,‘ ’代表着永久不转义,$1就是取第一列。
示例2:df -h 把第一列和最后一列拼起来,然后加上一句描述语句。 (不能识别文件内容列数,需要-F,不是文件内容不需要-F)
df -hP | awk '{print $1 " is mounted on " $NF}'
df -HP | awk '{print $1 "======="$NF}'
lsblk | awk '{print $1 "libin is RHCA" $NF}' #只留下lsblk 的第1列和最后一列,中间组织一段话连接
awk -F: '($3==11){print $1}' /etc/passwd #切割/etc/passwd 的第三列匹配11的那一行,且切出那一行的第一列 ===============等于 awk -F: '($3= =11)' /etc/passwd | awk -F: '{print $1}'
awk -F: '($3==0)' /etc/passwd | awk -F: '{print $NF}' #切割/etc/passwd 的第1列匹配0的那一行,且切出那一行的最后一列
解释:
awk -F: '($3==11)' /etc/passwd #切割/etc/passwd 第三列为11的那行,局限:无法切处多列为 XX的那一行。
awk -F: '{print $1,$2,$NF}' /etc/passwd #切割/etc/passwd 的第一列,第二列,最后一列
例如:切取/etc/shadow 中最后一行的,最后一列
示例3:希望在起始的地方加一个标题,在结束的地方也加一个标题。
awk -F: 'BEGIN {print "User list:"} {print $1} END {print "done."}' /etc/passwd
df -h | awk -F: 'BEGIN {print "libin"}{print $1}END{print "libin"}'
示例4: 在前面、后面添加标题 ,且只要第1列和倒数第4列。(只能用于切割文件内容)
cat /etc/passwd | awk -F: 'BEGIN {print "file system status:"}{print $1,$(NF-3)} END{print "Done."}'
#NF-3 代表的是倒数第四列。
示例5:把passwd第一列打印出来的时候,希望把以r开头的用户打印出来
awk -F: '/^r/ {print $1} ' /etc/passwd
示例6:以字母开头,t结尾的找出来
awk -F: '/^[a-z]*t:.*/ {print $1} ' /etc/passwd
#以上:t结尾就是t: .*代表任意东西,代表一个或多个字符,^[a-z]*意思是用户名都是字母,以字母开始,*就是前面重复多少次,0次或多次,可能名字中也有t,所以前面的数量无所谓,只要你保证这个用户名最后有个t就行,:. 是保证为t结尾
示例7:sar -q 需要时间,1分的负载,5分的负载,15分的负载
sar -q | awk '/^[^a-z]+$/ {print $1,$4,$5,$6}' > /tmp/cpudata
#以上:显示时间,第一列,第四列,第五列,第六列,[^a-z]的意思是非字母,'/^[^a-z]就是非字母开头,+是重复了多次数字
示例8:统计历史数据中I/O的总量
sar -b | awk '{print $1,($5+$6)/2}'
> /tmp/diskdata
#以上:把第五列和第六列的数据相加集合起来,但是显示的是扇区数,如果想更加清楚点可以除 以2,代表着每秒钟多少k。
6、gnuplot #绘图工具(红帽6,rhel7也支持,可以自行实验)
sar -q | awk '/^[^a-z]+$/ {print $1,$4,$5,$6}' > /tmp/cpudata
查看一个数据“/tmp/cpudata”,可以把 时间当成x轴,y轴是系统的负载状态
yum provide "gnuplot"
yum install gnuplot -y
gnuplot
>set xdate time #设置x为时间轴
>set timefmt "%H:%M:%S" #时间的格式是小时,分,秒
>plot "/tmp/cpudata" using 1:2 with lines #第一列时间X轴:第二列数据Y轴,点跟点以线连接起来。
>plot "/tmp/cpudata" using 1:2 title "1 min" with lines #可以加上一个标题,1 min时候的负载。
>plot "/tmp/cpudata" using 1:2 title "1 min" with lines, "/tmp/cpudata" using 1:3 title "5 min" with lines, "/tmp/cpudata" using 1:4 title "15 min" with lines #可以把15min的加上。
下次使用时可以采取下列方式,可以将命令定义到一个文件中去/tmp/cpu.gnuplot。将以下命令写入文件中
vim /tmp/cpu.gnuplot
=>set xdata time
=>set timefmt "%H:%M:%S"
=>plot "/tmp/cpudata" using 1:2 title "1 min" with lines, "/tmp/cpudata" using 1:3 title "5 min" with lines, "/tmp/cpudata" using 1:4 title "15 min" with lines
#gnuplot -p /tmp/cpu.gnuplot 查看,查看的时候要加上"persist"的选项,不然会闪断
案例分析:大约在晚饭时间17:00-19:30,系统I/O总是很重,请监控一下每天到这个时候的I/O状况,让大家持续去监控。
sar -b -s 17:00:00 -e 19:30:00 | awk '/^[^a-z]+$/{print $1,($5+$6)/2}' >/tmp/dinner.data
vim /dinner.gnuplot
=>set xdata time #x轴时间
=>set timefmt "%H:%M:%S" #时间的格式是时,分,秒
=>set term png size 1024,768 #它支持输出成pdf文件或者是图形文件,这里举例输出成图形文件,分辨率。
=>set output "/var/www/html/stat/`date +%F`.png" #启动apache服务后可以自己点进去看图,以当天的日期为图片文件名称
=>plot "/tmp/dinner.data" using 1:2 with lines #使用这个文件中的第一列为x轴,第二列为y轴,并且把线画出来。
mkdir /var/www/html/stat ;service httpd restart
gnuplot -persist /tmp/dinner.gnuplot #可以测试一下,这是在firefox
#firefox http://localhost/stat #可以看到一个图片。
crontab -e #做个计划任务,让它每天重新收集数据,重新绘图
=>0 20 * * * sar -b -s 17:00:00 -e 19:30:00 | awk '/^[^a-z]+$/{print $1,($5+$6)/2}' >/tmp/dinner.data ;
gnuplot /tmp/dinner.gunplot
7、PCP #红帽7监控工具
# yum install -y pcp.x86_64 pcp-gui.x86_64
#mandb #更新man手册
#pmstat -s 5 -t 2 #2秒看一次,看5次
#pmval -s 10 disk.dev.read #搜集某块磁盘10次信息
若出现下面情况,因为红帽7 默认开机关掉pcmd服务,需要手动打开
参考:https://man7.org/linux/man-pages/man1/pmcd.1.html#COLOPHON
#systemctl start pmcd #开启pmcd服务,用来收集系统性能指标的收集器
#pminfo | grep mem.freemem #过滤内存
#pminfo -f mem.freemem #查看某块内存
#pminfo | grep disk | grep read_ #查看磁盘
#pminfo -f disk.dev.read_bytes #显示磁盘字节
#pminfo -dt disk.dev.read #-d 以读 t:以文本形式显示出
#pmval mem.freemem #不断查看内存的变化
#pmval disk.dev.aveq #不断查看某块磁盘的变化
#pmchart #打开图形监测工具
8、ps静态进程用法
(1)ps aux #是一个快照报表,所有用户进程状态,不是动态
1、用户
2、进程ID
3、Cpu
4、内存
5、虚拟内存
6、物理内存
7、终端 #?没有指定所属的终端
8、状态 #s代表启动
9、开始运行时间
(2)ps -ef
pid: #进程ID
ppid: #父进程ID
(3)ps -p `pidof 服务名` #查看一个服务的进程信息
(4)ps axo comm,pid,ppid,vsz,rss,psr,%cpu #指定查看所有进程的信息
10、# ps -o pid,vsz,rss,comm -C sshd #查看虚拟的地址,包括真实分配的内存
9、top进程用法
(1)按f,进入可选界面,”空格键”可以选择与取消,”ESC”返回到top界面
(2)shift+M 键 :按照物理内存进行排序
(3)shift+N 键:按照进程ID号排序,降序 ,升序shift+R
(4)shift+T 键:按照CPU消耗排序
(5)#top -n 1: 执行一秒退出
VIRT:进程已经请求的虚拟内存总量
RES:进程当前映射到物理内存总量
10、free 内存用法
swap:虚拟内存
(1)free -m :
(2)free -g :
(3)free -k :
(4)free -m -s 1 : 每隔1秒查看一次、以M为单位
Buff/cache:会显示内存不足,超过总内存20%表示内存已满
(5)free -h
11、lsblk 磁盘用法
# lsblk -fp #显示磁盘的UUID
#lsblk -f /dev/sda1 #列举一块磁盘的文件系统格式
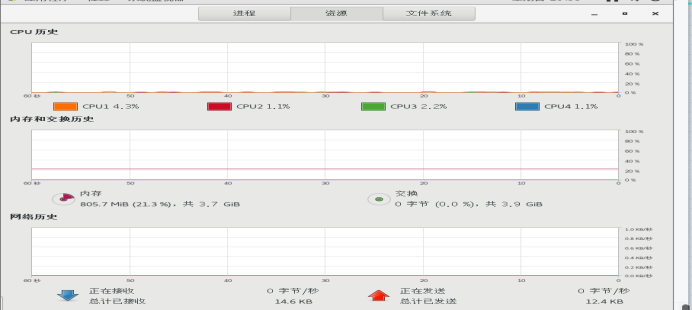
12、gnome-system-monitor图形监测
进程、资源、文件系统图形化监测工具
13、dmesg/journalctl/dmidecode 日志信息/硬件信息
proc、sys 都展现了运行的信息
#dmesg:从开机开始记录内核、硬件、系统的信息
#journalctl -e #与dmesg相同的效果
#dmesg | grep -i "dma" #-i忽略大小写,查找dma
#dmesg | grep -i "cpu" #查看cpu的信息
#dmesg | grep -i "mem" #查看内存的信息
#dmesg | grep -i "huge" #查看大页的信息
#dmesg | grep -i "io scheduler" #查看IO调度的信息
#dmesg -T #内核信息的输出
#dmesg -T | grep -i "selinux" #selinux 的信息
内核Kernel= vmlinux + initramfs +grub2引导文件,开机进入的过程
#tail /var/log/dmesg 系统启动的时候内核日志
#dmesg 内核的详细日志
#getconf -a 获取当前当前系统所有配置参数
#getconf PAGE_SIZE获取内存页面的大小
下面可以参考https://www.cnblogs.com/zhongguiyao/p/13940318.html理解
#lscpu 查看你cpu信息
#lscpu -p 优化命令输出
#getconf -a 可以获取全部系统信息
#x86infox86info -h
#dmidecode -t 0 从sysfs获取SMBIOS数据
#dmidecode 查看服务器硬件信息
#dmidecode | grep -i cache -A10 收集cache前10行的信息
#dmidecode -t memory收集内存的信息
#grep "" /sys/class/dmi/id/[pbs]* 收集电脑系统信息的管理系统信息
第四节 队列
1、队列理论 2、Little‘s Law
3、L 队列长度 4、W 等待时间
5、服务时间 6、带宽和吞吐量的问题
7、队列汇总 8、调优的基本思想
1、队列理论
(1)、队列的理论是由一个叫John Little在1961年的时候建立了一个数字化,可以将我们的性能量化的一个标准,主要是面向于性能管理,使得我们有数字来作为凭据来讲话。
(2)、Little‘s Law
核心部分:L = A*W
L:代表着队列的长度
A:代表着达到率。
W:代表着等待时间。
(3)、L 队列长度
一、通常我们说的队列长度指的就是内存中的buffer,buffer的主要作用就是给大家一个排队的空间。 buffer越大你的队列可以排的越长。
二、L可以是一个读写的参数,可以是调节,也可以是只读,只能看,你只看不能改。
三、针对排队的队列,可以进行分类。优先级高的先服务,优先级低的后服务。
举例思考:到底是读操作比较紧急,还是写操作比较紧急?
把队列长度放长,会牺牲更多的内存,但是它会有一个非常好的作用,就是在这里面排队的人你可以给它把优先级分规划的非常好,重要的操作先做。队列越长,排序的可能性越高。
(4)、W 等待时间
通常分为两种
第一种:排队时间。
第二种:服务时间。
W=Q+S 等待时间=排队时间+服务时间 ==> L = A * (Tq + Ts)
(5)、服务时间
对于我们的服务时间,我们用的是操作系统,当一个程序在运行的时候,它会花两种时间
第一种:系统时间(system time)
第二种:用户时间(user time)
L = A*W ==> L = A *(Tq+Tsys+Tuser)
还有一种时间,它既不是system time,也不是user time,我们在系统中也会把它归类在
system time里面。比如说这种长时间等待的操作。
示例1 :
time命令衡量一个程序到底花了多久的时间执行
time updatedb #此命令的意思是立即对整个磁盘进行索引,建立一个索引库
echo 3 > /proc/sys/vm/drop_caches #清理全部缓存
我们衡量一个程序是否写的优秀,在输入相等的情况下,输出的越快它的效率越高。一个程序在 运行的时候它占cpu,那它就要占cpu,谁最快把这个任务程序完成了,那么证明这个程序优秀, 而不是看谁占cpu占的瓦数少。
(6)、带宽和吞吐量
1、Bandwidth(带宽)数据+开销
2、Throughput (真正的吞吐量)真正的吞吐量只有数据
3、在带宽恒定的情况下,我们选择合适的协议,减少开销,可以帮助我们提升吞吐量。
4、一个系统的终极的吞吐量,是由整个系统全体环节中最慢的那个环节来决定的,但是我们要数字说法表达出来的话叫做“forced flow law”,意思就是说系统的瓶颈决定着你的总带宽。
(7)、队列汇总
L = A*W = A* (Q+S)= A*(Q+Tsys+Tuser)
L:队列长度
A:到达率 = C:完成率
W:等待时间
Q:排队时间
S:服务时间
Tsys:系统时间
Tuser:用户时间
队列长度 = 到达率 * 等待时间 = 到达率 * (排队时间 + 服务时间) = 达到率 * (排队时间 + 系统时间+用户时间)
(8)、调优的基本思想
我们要决定调L,buffer大小的时候,我们尽量保持队列的简短。L的长度也会有有一些优势,可以将重要的数据先进行处理。
调节A和C的时候,对互联网而言A基本上很难调。
你以前只有一台server,现在挂个两台做个负载均衡,把这个到达率平均到每台电脑上,使得它们有能力去处理,这就是调节A的基本思想。
对磁盘而言,一个磁盘不够,就上三个磁盘,可以让A平均到每个磁盘上,达到我的要求,使得C正好等于A,不使我的系统挂掉,这是调优的思想。
把你的吞吐量增高,提高你的完成率,可以换更加有效的协议,通常是指UDP或者TCP之间的选择。
调的最多的地方还有W,这其实是一个重点调优的对象——“等待时间”。
磁盘的服务时间是很长的,从用户层的系统调去要哪些数据直到你拿到手上的这个过程,其实花的时间是非常久的。整个这个过程可以称为整体的等待时间。如果换成固态盘,这个等待时间就大大的减小了;如果换成内存盘,这个等待时间会更小,所以你想等待时间降下来,可以换高速设备,这个是需要花钱的。
总结
1、队列核心部分:L = A*W
2、L = A*W = A* (Q+S)= A*(Q+Tsys+Tuser)
3、队列长度 = 到达率 * 等待时间 = 到达率 * (排队时间 + 服务时间) = 达到率 * (排队时间 + 服务时间+用户时间)
4、一个系统的终极的吞吐量,是由整个系统全体环节中最慢的那个环节来决定的。
5、L,A,W。去解决的这三问题都叫调优,都是我们可调的一个出发点。
第五节 模块与调度算法、内核开关
1、kernel模块管理 2、更改模块的参数
3、开机自动加载模块 4、磁盘I/O调度
5、I/O调度算法 6、设置I/O调度算法
1、kernel模块管理
lsmod #显示kernel模块 ,查看所有的内核模块名
modinfo 模块名 #查看kernel模块相关信息
modprobe #加载kernel模块到内核,临时性
rmmod #卸载kernel模块
#sysctl -a #查看内核开关
#sysctl -a | grep net. #查看网络内核开关,”.“代表路径结构
#sysctl -a | grep icmp #查看icmp协议

测试1:
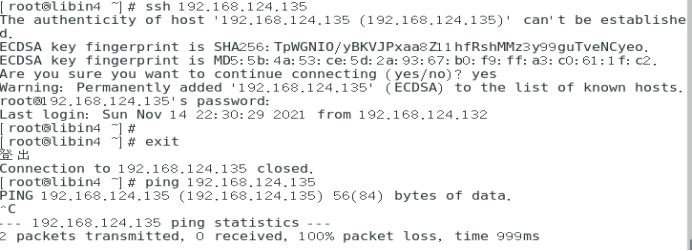
关掉内核icmp协议(临时性)
#echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all #0开启,1关闭

#进行 ping 测试 与ssh 测试
测试2:编辑swap模块主配置文件(永久)
#sysctl -a | grep swap #加载swap模块,修改vm.swappiness 值
vm.swappiness = 30
#vim /etc/sysctl.conf #修改swap值,删除重启会恢复之前值
vm.swappiness = 10
#sysctl -p #生效,直读主配置文件
测试3:增加一个swap模块子配置文件
#vim /etc/sysctl.conf #将之前的swap值还原
vm.swappiness = 30
#vim 90-sysctl.conf #90代表优先级,比99要高
vm.swappiness = 10
# sysctl -f /etc/sysctl.d/90-sysctl.conf #指向一个规定的文件
#sysctl -w vm.swappiness = 30 #-w临时修改
lsmod 加载模块名
(1)kernel模块名称。(每一个kernel模块都对应着装kernel rpm包时候,所附带的kernel模块的文件的前半部分。)
find /lib/modules/内核版本号/ -name "*.ko" 。其中存放着非常多的kernel的模块,其中几乎以.ko 结尾的,这些都被称为kernel模块。
kernel模块。指的是每台机器都不一样,因为每台机器硬件配置是不一样的,比如说我们的网卡,声卡,显卡不一样等等,这些外设通常都是变化多端的。
(2)、kernel。(/boot/vmlinux……)kernel本身是非常常用的,里面包括所有的几乎每个机器都用到的功能,比如内存管理,计算机和新硬件的驱动,进程管理,防火墙等等,每台电机器都可能用到的功能都集成在核心里面。
modinfo :查看kernel模块相关信息
#modinfo st #查看st模块信息
#modinfo -p st #只看kernel参数
#modinfo usb_storage #查看usb存储模块信息
测试1(临时):
#modprobe #将一个模块加载到kernel之中
# modprobe st #临时加载st的模块到内核
#lsmod | grep st #查看kernel内核模块,会多了一个st模块
#rmmod st #临时移除st模块,再查看就没有st模块了
测试2(临时):
#modprobe usb_storage
#modprobe sx8
#rmmod usb_storage
#rmmod sx8
注意:如果模块正在使用中是卸载不掉的。kernel中有个开关可以强行卸载模块,但是极度危险, 强制卸载的结果系统可能就会kernel pannic
2、更改模块的参数
测试:
#vim /etc/modprobe.d/*.conf (只有增加.conf文件,开机模块才生效,可以在一个文件写多个模块,下面有测试)
测试1:使参数生效
vim /etc/modprobe.d/libin.conf
=>options st buffer_kbs=256 #将队列长度增长到265k。
=>options sx8 max_queue=15 #可以用modinfo -p mx8来查看相关参数
=>options usb_storage delay_use=3 #usb是属于慢速设备,让它插入的时候延迟一会(插上U盘3秒后识别)
#chmod +x libin.conf
#modprobe st #添加模块,临时生效 (rhel7没有临时生效)
#modprobe sx8
#modprobe usb_storage
不需要检查是否生效:(参数无法看到)
modinfo st -p | grep buffer_kbs
modinfo sx8 -p | grep max_queue
modinfo usb_storage -p | grep delay_use
测试1:使模块生效
#cd /etc/sysconfig/modules/
#vim libin.modules #必须是”modules“结尾的文件
==>modprobe st
==>modprobe sx8
==>modprobe usb_storage
#chmod +x libin.modules #给与执行权限,开机生效
#reboot #重启,再使用modinfo 就生效
检查有加载:
#lsmod | grep st
#lsmod | grep sx8
#lsmod | grep usb_storage
3、开机自动加载模块 (modprobe )
#less /etc/rc.sysinit #搜索modules (rhel6方法,rhel7不能生效)
#cat /etc/rc.local#RHEL7(系统引导记录路径)
# cd /boot/grub2/ && cat grub.cfg#系统引导表 && 引导表配置文件
逻辑扇区,一个扇区大小512,第一个扇区的前面446个字节为引导记录。
红帽的操作系统在启动的过程中,它的初始化脚本叫/etc/rc.sysinit ,这里面做了相当多 的动作。它会遍历 /etc/sysconfig/modules/*.modules,将所有的以后缀为.modules的文件全部执行一遍。
#vim /etc/sysconfig/modules/libin.modules
=>modprobe st
=>modprobe sx8
=>modprobe usb_storage
#chmod o+x /etc/sysconfig/modules/libin.modules
4、磁盘I/O调度
linux下做了两件事情来提速的
第一种,做caching。对这个磁盘可以做缓存。
第二种,使用了非常优秀的硬盘调度算法,这就是I/O调度。它是尽量的把临近的操作合并成一个I/O请求。
linux如何访问磁盘是的?
1、其实在底层有一个disk device driver,说明它是一个驱动程序,驱动程序再往下就是赤裸裸的硬件。
2、在内存中它把I/O的读写分为两种,一种叫page cache,这指的是文件内容的缓存;另一种叫buffer cache是文件原数据的缓存。
3、读写内存之后,这是用户层发生的事情,那么交给kernel的时候,它会选择一个当前的I/O调度算法,然后按照这个算法将这些请求排队。
4、然后把队列里面的东西一把扔给disk device dirver的驱动程序,而驱动程序只做一件事情,把这些队列里面的数值交给了磁盘管理,紧接着磁盘就开始机械臂动作。
5、所以我们平时读写数据的时候其实是内存,我们从来都不会去直接的访问硬盘。
5、I/O调度算法
第一种:cfq(completely fair queuing),意思是完全公平队列。
第二种:deadline,意思是到期就到期了,别再给我等,还有一个更高优先级来我不管。
第三种:anticipatory,意思等待一段时间后,重新读
第四种:noop,意思是只拥有一个等待队列,每当来一个新的请求,仅仅是按先来先处理的思路将请求插入到等待队列的尾部。
cfg(completely fair queuing) 负载
1、默认的调度算法。既然算法公平,它比较适合于各种工作负载,基本上是个负载它都可以挺住。
2、cfq的设计非常复杂,它花费大量的cpu时间。主要的对象就是针对这些在读读写写的进程,它特别适合于用cfq。
deadline 实时
1、简而言之就是你给我预期的时间必须给我做出来。所以用一个英文单词表达它是最合适
的——predictable(可预知的),它这种行为是可预知的,比较有保障。尤其是在实时系统里面,这个非常重要。
anticipatory 按序
1、这种算法适合于大量的顺序读操作。比如说那种大文件,有人要下载一个大文件,它那个读文件的时候都是按顺序走的。所以这种在生产环境里比较适合那种进程数很多,但是有大量的顺序读操作。
noop 插队
1、它是适合于虚拟机,我们知道所有的文件读写都要经过buffer,如果你虚拟机本来就是磁盘文件,你虚拟机过了一道缓存,到真机的时候又过一道缓存,这样做不但浪费的cpu,而且你上下又没配合起来,说不定还慢。虚拟机就用noop就不需要再排序了,这些交给上层排序,因为最终写盘的是上层,真正的虚拟机管理器来写盘,并不是由虚拟机本身写盘的。这样可以提高效率。
6、设置I/O调度算法 (不同算法有不同的配置文件)
#cat /sys/block/sda/queue/scheduler #可查看sda盘的调度算法,默认看cfq的。
#cd /sys/block/sda/queue
#cat nr_requests #默认值的意思就是在磁盘最前面那个排队的长度是128个默认请求
#cat read_ahead_kb #如果kernel 发现你是随机读,那么它会预先读128k的数据
#cat /sys/block/sda/queue/scheduler #查看当前电梯算法
#ll /sys/block/sda/queue/iosched #当前可调的电梯算法是cfq,那这些就是cfq的可调的参数
#echo deadline > /sys/block/sda/queue/scheduler #改变电梯算法,当前可调的电梯算法是deadline,那这些就是cfq的可调的参数
#cd /sys/block/sda/queue/
#cat scheduler #[]中代表当前调度算法,rhel7支持3种
noop
deadline
cfg
针对deadline,有两个重要的参数
read_exprie #保障读的时间。默认500毫秒
write_exprie #保障写的时间。默认5000毫秒


# echo cfq > scheduler #改变调度算法
#cat scheduler

#红帽7中已经不支持按序anticipatory 的I/O调度算法,下面可以rhel6实验
echo anticipatory > /sys/block/sda/queue/scheduler
cat /sys/block/sda/queue/iosched/quantum
cat /sys/block/sda/queue/iosched/antic_expire #另一个要等待多久,附近的读。默认6毫秒
echo cfq > /sys/block/sda/queue/scheduler
cfq分类分了三个等级
第一个等级:real-time,实时的。为了满足实时系统的程序,会沾满磁盘。
第二个等级:best-effort,以最好的效果访问。代表着大家都能访问的意思。这是默认值。
第三个等级:idle,等计算机磁盘没在用的时候你再用。
ionice:只适合于cfq。它用来在执行命令的时候指定某个PID已经运行的程序更改其运行的分类, time 可以输出运算时间,方便观察,也可以不加
time ionice -n0 -c1 -p [pid] -c1,意思是用等一个等级。
time ionice -n7 -c2 [cmd] -c2,是默认值等级,可以不写。
time ionice -c3 [cmd] -c3,就相+当于很低调
iotop监控指令,磁盘监控。
be:默认值c2
rt:c1
idle:c3
测试1:
# echo 3 >/proc/sys/vm/drop_caches #先清空缓存
#dd if=/dev/zero of=/bigfile1 bs=1M count=1024 #写入1M字节 ,数量为1G的文件输出到/bigfile1
#iotop #查看变化
测试2,普通用户执行:
再建立3个bigfile1,bigfile2 ,bigfile3
#dd if=/dev/zero of=/bigfile1 bs=1M count=1024
#dd if=/dev/zero of=/bigfile2 bs=1M count=1024
#dd if=/dev/zero of=/bigfile3 bs=1M count=1024
3个终端执行,对比执行的结果
#time inoice -c1 dd if=/bigfile1 of=/dev/null
#time inoice -c2 dd if=/bigfile2 of=/dev/null
#time inoice -c3 dd if=/bigfile3 of=/dev/null
终端4超级用户执行
ionice -c3 -p [pid]
7、红帽8 Block I/O 调梯算法(Blk-mq)
四种设置:mq-deadline(rhel8默认)、kyber(支持读写)、bfq(完成公平队列)、none(适用NVMe磁盘,基于单队列)
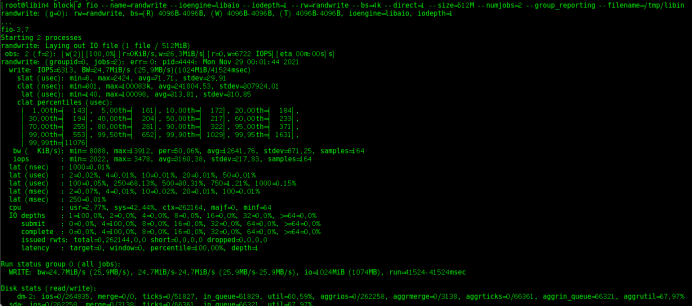
测试1:降低(clat avg微秒平均)延迟
#yum search "fio"
#yum install -y fio.x86_64 #fio测试磁盘的工具
# fio --name=randwrite --ioengine=libaio --iodepth=1 --rw=randwrite --bs=4k --direct=1 --size=512M --numjobs=2 --group_reporting --filename=/tmp/libin
randwrite: (g=0): rw=randwrite, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=1 #随机读写
#mkdir /etc/tuned/reduce-libin
#cd /etc/tuned/reduce-libin && cp /usr/lib/tuned/virtual-guest /tuned.conf /etc/tuned/reduce-libin
==>[main]
==>include=latency-performance
==>[sysfs]
==>/sys/block/sda/queue/iosched/fifo_batch=1
#tuned-adm profile reduce-libin #更改模式
#rm -fr /tmp/libin #删掉重新测试,查看ctla的avg
#fio --name=randwrite --ioengine=libaio --iodepth=1 --rw=randwrite --bs=4k --direct=1 --size=512M --numjobs=2 --group_reporting --filename=/tmp/libin
randwrite: (g=0): rw=randwrite, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=1 #由于/fifo_batch 红帽7没有 变化不大
8、RAID 磁盘阵列
raid0:条带化工作机制,读写快,磁盘容量大,缺点无冗余(至少2块)
raid1:数据存储2份,具有冗余,读快,写慢,数据总量为磁盘1/2
raid4:条带化工作机制,具有奇偶校验,校验在固定的一个盘上,校验盘损坏无法恢复。其他盘坏了,可以做数据恢复,但降级处理,但性能会降低
raid5:每块盘都有奇偶校验,每块盘都可以恢复,但降级处理,但性能会降低
raid6:奇偶校验为二种,可以同时坏二块盘进行修复,但降级处理,但性能会降低
raid10:raid0与raid1的结合。


-------------------------------------------------------------------------------------------------------------------------------
总结 :
1、kernel模块的列出、查询、添加、卸载
lsmod 、modinfo 、modprobe、rmmod
2、更改模块参数、开机自动加载
/etc/modprobe.d/*.conf 、/etc/sysconfig/modules/*.modules
3、I/O调度算法
cfq、 dendline、anticipatory、noop
第六节tuned调优工具
1、tuned介绍 2、使用tuned的目的
3、如何使用tuned 4、tuned-profile
5、设置tuned
1、tuned 介绍
tuned是RHEL6推出的调优工具,可以简单、动态的调整系统。默认的tuned软件包包含9个调优配置文件,对laptop、desktop、server系统的省电策略、磁盘调度算法、缓存、内存脏页回写等等的调节。
tuned包安装后有两个服务,tuned和ktune,chkconfig查看默认是off状态,可以通过chkconfig
和service手动开启。在配置好profile后,执行tuned-adm profile xxx切换配置的时候也会自动的开启这两个服务。
tuned的配置文件保存在/etc/tuned-profiles目录,可以通过 tuned-adm list 查看可用配置文件列表,以及当前应用的配置文件。
2、使用tuned的目的
希望有个方案整个的省电达到极致。
可以以最高的可能性打开磁盘的吞吐量。
还能自定义设置自己的tuned (profile)配置。
3、如何使用tuned
yum install tuned -y #安装启动
systemctl enable tuned
systemctl start tuned
systemctl status tuned
chkconfig tuned | ktune on
service tuned | ktune restart
systemctl list-unit-files | grep nfs#查看已有的服务和状态
示例:计划任务
0 7 * * 1-5 /usr/bin/tuned-admin profile throughput-performanance
0 20 * * 1-5 /usr/bin/tuned-admin profile server-powersave
4、设置tuned 模式
#yum info tuned
关于tuned的描述,上面写着tuned是一个服务,可以让系统动态的发生变化。它可以监控若干个 系统组件,其实监控的是子系统。根据系统收集,它可以让系统工作在一个省电模式或者是高性能模式,目前只实现了基于网络的调优和基于磁盘的调优。
tuned-adm activc #查询当前profile(模式)
#tuned-adm list #列举系统中所有的profile ,9种,目前rhel7支持的9种模式,也可以自定义profile
Available profiles:
1、balanced
2、desktop
3、latency-performance
4、network-latency
5、network-throughput
6、powersave
7、throughput-performance
8、virtual-guest
9、virtual-host
Current active profile: virtual-guest
例1:
crontab -e#创建1个计时任务
0 7 * * * /usr/sbin/tuned-adm profile throughput-performance
#每天7天切换位 profile throughput-performance模式
0 20 * * 1-5 /usr/sbin/tuned-adm profile libin
#周一到周五20点为 libin模式
0 5 * * 0,6 /usr/sbin/tuned-adm profile throughput-performance
#周六,周日5点开启throughput-performance模式
例2:
#cd /usr/lib/tuned/;ll #tuned模式配置文件的存放路径
#tuned-adm profile server-powersave #切换profile (永久性的修改)
#tuned-adm recommend #推荐的值
tuned-adm profile default #切回默认模式(rhel7 default 为balanced)
#tuned-adm profile balanced
5、tuned-profile模式(不同模式有不同的配置文件)
1、default ===> balanced (rhel7)
默认设置,影响最小的省电设置,适用于少量的读写操作,比如邮件服务器
2、desktop-powersave ===>desktop (rhel7)
桌面系统的省电模式,启用SATA的ALPM省电设置,同时也会启用CPU、网络、磁盘的调节插件
3、server-powersave ===>powersave (rhel7)
服务器系统的省电模式,启用SATA的ALPM省电设置,关闭光驱实时监测,启用CPU和磁盘的调节插件
4、laptop-ac-powersave (rhel6)
笔记本电源模式,中等影响的省电设置,启用SATA的ALPM省电设置,启用CPU、WIFI省电模式,同时也会启用CPU、网络、磁盘的调节插件
5、laptop-battery-powersave (rhel6)
笔记本电池模式,最大化省电设置,关闭声卡、光驱等等,对wifi启用省电模式,磁盘和网络的性能受到影响,I/O延时变高
6、spindown-disk (rhel6)
用于传统机械磁盘,尽量减少磁盘旋转,增加writeback值,减少使用交换,关闭日志实时写入,所有分区以noatime(不更新最后访问时间)的方式重新挂载。关闭省电模式插件。是一个比较特殊的节电模式,适合于不经常使用的服务器,或磁盘负荷超过标准的服务器。
7、throughput-performance
==>throughput-performance (rhel7)
吞吐量优化。关闭省电模式;调节一些sysctl用来提高磁盘和网络的吞吐量;启用内存大页;调节CPU为性能模式;切换磁盘调度模式为deadline。适用于使用中低端存储的虚拟化主机。
8、latency-performance
==>latency-performance (rhel7)
延时优化。关闭省电模式;调节一些sysctl用来降低网络延时;切换磁盘调度模式为deadline;调节CPU为性能模式。适用于数据库服务器
9、enterprise-storage (rhel6)
极大提高I/O吞吐量的模式。切换磁盘调度模式为deadline;在非根和非boot分区上关闭I/O
barriers(极大的提高I/O吞吐量,但是掉电后会产生文件丢失);启用4倍readahead。
6、设置tuned 及修改配置,tuna图形化
tuned.conf #那些系统的子系统的需要做电池监控的调优。
sysctl.ktune #是用来在profile生效的时候,顺便将kernel参数进行修改。
ktune.sysconfig #是用来调节磁盘电梯算法。
ktune.sh #在profile生效的时候,你期待执行哪些脚本;或者引用哪些tuned自带的函数库。
创建自定义的配置文件 (RHEL6可以支持,RHEL7没有这些不支持)
建议基于 laptop-battery-powersave (省电目的) 或 throughput-performance (性能优化)
的拷贝,然后编辑。
/etc/tune-profile #查看tuned的各种模式
ls /etc/tune-profile/throughput-performance #可以看到里面可调的参数
cat /etc/tune-profile/throughput-performance/tuned.conf
cat /etc/tune-profile/throughput-performance/sysctl.ktune
cat /etc/tune-profile/throughput-performance/ktune.sysconfig #查看调度算法
cat /etc/tune-profile/throughput-performance/ktune.sh #cpu、内存调节
自定义tuned模式,以及修改配置,测试1(RHEL7):
#cd /usr/lib/tuned/;ll #tuned模式配置文件的存放路径
#cd /etc/tuned/;ll #tuned 的系统配置文件
#mkdir /etc/tuned/virt-guest-lab #自行增加一条tuned模式,为virt-guest-lab
#cp /usr/lib/tuned/virtual-guest /tuned.conf /etc/tuned/virt-guest-lab/
#cd /etc/tuned/virt-guest-lab
#tuned-adm list #查看tuned模式会多了一条virt-guest-lab
#cd /etc/tuned/virt-guest-lab && vim tuned.conf #修改
==> include=virtual-guest
==> [disk]
==> devices=!vda #除了vda设备,其他都进行调试(!取反)
==> readahead=4096 #启动预读机制
# tuned-adm profile virt-guest-lab #加载virt-guest-lab模式
#tuned-adm list #查看,变化,临时性
Current active profile: virt-guest-lab #之前为 virt-guest
#永久生效输出到开机脚本内(>会覆盖原文件,>>不会覆盖原文件),并给与执行权限
#echo tuned-adm profile virt-guest-lab >> /etc/rc.local
#chmod +x /etc/rc.local
cd /usr/lib/tuned/virtual-guest/ && cat tuned.conf #tuned模式 内核配置文件开关
(1)Tuna图形化
# yum install -y "tuna"
#cd /etc/tuna/ && cat example.conf #会出现一个example.conf 配置文件
#tuna
#cat /etc/tuned/tuned-main.conf #0关闭动态调节,1关闭动态调节
dynamic_tuning = 0
测试1:
#tuna -t httpd -P #列举httpd服务的进程和线程
# vim /etc/sysconfig/irqbalance
==>IRQBALANCE_BANNED_CPUS=00000002 #不会在cpu0上处理
#systemctl restart irqbalance.service
#watch -n1 cat /proc/interrupts #-n1每秒观察一次
#for IRQ in /proc/irq/*/smp_affinity;do echo 1 > ${IRQ} 2 >/dev/null ;done
会发现 有二个cpu在工作。
(2)cock 图形化应用系统设置 *
#systemctl list-unit-files | grep cock
#yum install -y cockpit.x86_64
#firewall-cmd --add--service=cockpit
#systemctl start cockpit.service
#firefox 打开访问 9090端口,cockpit服务为9090端口
账户密码为 系统用户密码
(3)blockdev 修改硬盘设备值
可用命令有:
--getsz # 获得 512-字节扇区的大小
--setro #设置只读
--setrw # 设置读写
--getro #获得只读
--getdiscardzeroes #获取 忽略零数据 支持状态
--getss #获得逻辑块(扇区)大小
--getpbsz #获得物理块(扇区)大小
--getiomin #获得最小 I/O 大小
--getioopt #获得最优 I/O 大小
--getalignoff #获得对齐偏移字节数
--getmaxsect #获得每次请求的最大扇区数
--getbsz #获得块大小
--setbsz <bytes> #set blocksize on file descriptor opening the block device
--getsize #获得 32-bit 扇区数量(已废弃,请使用 --getsz)
--getsize64 #获得字节大小
--setra <sectors> #设置 readahead
--getra #获取 readahead
--setfra <sectors> #设置文件系统 readahead
--getfra #获取文件系统 readahead
--flushbufs #刷新缓存
--rereadpt #重新读取分区表
----------------------------------------------------------------------------------------------------
测试2;延用自定义tuned模式,以及修改配置测试,修改扇区:
#mkdir /etc/tuned/libin
#cp /usr/lib/tuned/virtual-guest/tuned.conf /etc/tuned/libin/
#tuned-adm list #会多了一个tuned模式 libin,
#cd /etc/tuned/libin/
#vim tuned.conf
[main]
==>summary=libin is RHCA#修改摘要,摘要信息改变
测试3,设置块设备字节
手动设置:用blockdev命令
#blockdev --getr 512 /dev/sda2#修改/dev/sda2磁盘为512字节
#blockdev --getra /dev/sda2#查看/dev/sda2字节大小
测试4:通过tuned.conf文件修改块设备字节大小:
#cd /etc/tuned/libin/
#vim tuned.conf
[disk]
==>devices=sda
==>readahead=4096 sectors#sectors 代表扇
# tuned-adm profile libin #使tuned模式libin生效
#blockdev --getfra /dev/sda #查看sda扇区变化

如果不带扇区sectors单位变化:
#vim tuned.conf
[disk]
==>devices=sda
==>readahead=4096
#tuned-adm profile libin
#blockdev --getfra /dev/sda
#查看sda变化,不加单位显示是默认扇区;1Kb 为1024B (字节) ,1B=1b,1扇=512个字节,kb=总字节大小/1024,显示的单位为扇.
注:计算:
1、8192*512=总扇区字节大小
1、总扇区字节大小/512字节=总扇区大小
1G=1024M,1M=1024K,1K=1024B,1B=8bit ,1s(扇)=512B,1s=1/2B,1B=2扇

总结:
1、balanced 2、desktop
3、latency-performance 4、network-latency
5、network-throughput 6、powersave
7、throughput-performance 8、virtual-guest 9、virtual-host
第七节 CPU、CFS调度算法
1、了解CPU调度算法
2、异步复杂度
3、CFS调度算法介绍
4、CFS调度算法之下优先级的改变
5、CFS调度算法策略
1、了解cpu调度算法
CPU调度决策可在如下四种环境下发生 :
(1)当一个进程从运行状态切换到等待状态 例如,I/O请求或调用wait以等待一个子进程的终止
(2)当一个进程从运行状态切换到就需状态 例如,当出现中断
(3)当一个进程从等待状态切换到就需状态 例如,I/O完成
(4)当一个进程终止
当调度只能发生在第一和第四种种情况时,称调度方案是非抢占的,否则调度方案是可抢占的。
采用非抢占调度,一旦CPU被分配给一个进程,那么该进程会一直使用CPU直到进程终止或切换到等待状态时释放CPU
2、异步复杂度
(1)幂数级增长 :随着输入的增多,你耗费系统的资源或者等待时间的变化曲线。
(2)以平方式增长 :随着输出的量增加,其实耗系统资源很明显,越来越高。
(3)线性 随着资源的增加,所花的时间也非常平稳的增加。
(4)对数形式:对数形式会随着输入量增加,初期时间或者资源会有所增加,但是后期曲线是比较平稳的
(5)常量形式 :服务时间是同一个时间
3、CFS调度算法介绍
(1)企业级6,从kernel-2.6.23以后,引入了CFS调度算法。不是cfq,cfq是对磁盘的。cfs是针对kernel。它仍然引用了完全公平的调度算法。
(1)CFS(completely fair schedule)是最终被内核采纳的调度器。它从RSDL/SD中吸取了完全公平的思想,不再跟踪进程的睡眠时间,也不再企图区分交互式进程。它将所有的进程都统一对待,这就是公平的含义。CFS的算法和实现都相当简单,众多的测试表明其性能也非常优越。
(3)CFS 背后的主要想法是维护为任务提供处理器时间方面的平衡(公平性)。这意味着应给进程分配相当数量的处理器。分给某个任务的时间失去平衡时(意味着一个或多个任务相对于其他任务而言未被给予相当数量的时间),应给失去平衡的任务分配时间,让其执行。
(4)CFS抛弃了时间片,抛弃了复杂的算法,从一个新的起点开始了调度器的新时代,最开始的2.6.23版本,CFS提供一个虚拟的时钟,所有进程复用这个虚拟时钟的时间,CFS将时钟的概念从底层体系相关的硬件中抽象出来,进程调度模块直接和这个虚拟的时钟接口而不必再为硬件时钟操作而操心,如此一来,整个进程调度模块就完整了,从时钟到调度算法,到不同进程的不同策略,全部都由虚拟系统提供,也正是在这个新的内核,引入了调度类。因此新的调度器就是不同特性的进程在统一的虚拟时钟下按照不同的策略被调度。
(5)CFS在真实的硬件上模拟了完全理想的多任务处理器"。在“完全理想的多任务处理器 “下,每个进程都能同时获得CPU 的执行时间。当系统中有两个进程时,CPU的计算时间被分成两份,每个进程获得50%。然而在实际的硬件上,当一个进程占用CPU时,其它进程就必须等待。这就产生了不公平。
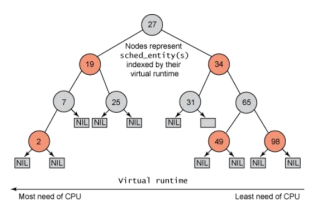
(1)CFS的实现是基于红黑树(red-black tree) 机制
与之前的 Linux 调度器不同,它没有将任务维护在运行队列中,CFS 维护了一个以时间为顺序的红黑树。 红黑树 是一个树,具有很多有趣、有用的属性。首先,它是自平衡的,这意味着树上没有路径比任何其他路径
长两倍以上。 第二,树上的运行按 O(log n) 时间发生(其中 n 是树中节点的数量)。这意味着您可以快速高效地插入或删除任务
(2)CFS的核心思想
全公平调度器(CFS)的设计思想是:在一个真实的硬件上模型化一个理想的、精确的多任务CPU。该理想CPU模型运行在100%的负荷、在精确平等速度下并行运行每个任务,每个任务运行在1/n速度下,即理想CPU有n个任务运行,每个任务的速度为CPU整个负荷的1/n。
由于真实硬件上,每次只能运行一个任务,这就得引入"虚拟运行时间"(virtual runtime)的概念,虚拟运行时间为一个任务在理想CPU模型上执行的下一个时间片(timeslice)。实际上,一个任务的虚拟运行时间为考虑到运行任务总数的实际运行时间。
虚拟运行时间"(virtual runtime)
CFS用的红黑树是建立在虚拟时间上的,它引入了一个新的概念,不是说你的优先级高就行的。虚拟时间有三个因素判断
1)等待时间。
2)特别需要被服务。
3)最后考虑进程的优先级。
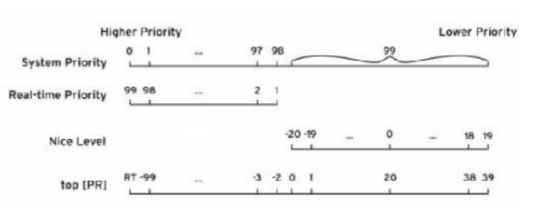
4、CFS调度算法之下优先级的改变
5、CFS调度算法策略
PS 命令对于优先级CLS(调度)所对应的进程:
pri:静态优先级
rtprio:实时优先级
cls:调度策略
Ts:非实时策略,可调节0-39,普通进程
FF=FIFO:先进先出,实时策略,先到先服务。
# ps axo comm,pid,cls,rtprio,pri
对于实时进程,有两种调度算法 :
SCHED-RR -r #轮询,时间片轮转。
SCHED-FIFO -f #先进先出,先到先服务。
SCHED-DEADLINE #rhel8内,保证进程在规定的时间内,允许足够长的时间片
非实时进程,策略有三个:
SCHED-NORMAL #正常程序执行的时候都是NORMAL。
SCHED-BATCH -b #代表你这个进程在不断做一个比较大的动作,通常需要花很多时间。
SCHED-IDLE -i #空闲时再执行。它的优先级都小于nice值19
------------------------------------------------------------------------------------------------------------------------
测试1:
chrt -f 10 top
lscpu #查看一下cpu,当前运行的cpu是2片,所以要运行两次,把cpu给占满了
chrt -f 1 md5sum /dev/zero & #切换终端执行,这里我们用的是-f 1,因为f1 的优先级要小于10。
chrt -f 1 md5sum /dev/zero #查看top,会发现两个cpu都已经满了。
chrt -r 1 sha1sum /dev/zero #这个进程是Round-robin的,top中,却看不到它的身影
killall md5sum #把md5sum杀死,在查看top的时候,发现了sha1sum
测试:
dd if=/dev/zero of=/dev/null &
dd if=/dev/zero of=/dev/null &
renice 19 [PID] #在用户层去干预一下,然后把其中一个优先级调到最低
nice -n 20 md5sun /dev/zore #再执行一个程序,优先级是-20,极限干预
测试2:(改变一个服务的调度策略和优先级)
这里用的服务为我之前创建的服务 第九节-测试3:(创建服务,自定义一个slice文件,被系统所调用)frontend.service 其实服务为调用了dd ,实验只为了改变调度策略

我们这里看到的dd调度策略默认为TS
# cd /etc/systemd/system
#vim frontend.service
==>CPUSchedulingPolicy=batch #将策略改为batch
==>PUSchedulingPriority=0 #将优先级改为0
#systemctl daemon-reload #重新加载服务配置
#systemctl restart frontend.service #重启服务
# ps axo comm,pid,cls,rtprio | grep dd #查看dd的策略已经改变为batch,优先级为0
#chrt -p 58752 #打印进程的调度策略和优先级
第八节CPU缓存分类、架构、机制
1、CPU缓存分类
2、缓存架构
3、缓存跟主存之间的过程
4、缓存的回写机制
5、缓存的三种设计思想
6、valgrind
7、perf
1、CPU缓存分类
(1)一级缓存是在cpu里面的,通常cpu缓存分为指令缓存和数据缓存,这一部分内存是用静态内存实现的。
(2)二级缓存也是在cpu里面,通常情况下它是在我们cpu的核心之间共享的,有些是私有的,有些是共享的。二级缓存是有高速动态内存制造。
(3)三级缓存通常在主板上,它在核心之间共享,三级缓存一般不会私有
(4)四级缓存比较罕见,通常是在物理cpu之间共享的
2、缓存架构
(1)缓存其实就是一行行的容器。
(2)每一行可以用来缓存内存某一个地方。平常cpu要访问内存的某一个地方,那么缓存控制器就会把那一行行读出来。其实就是把内存的一部分拷贝过来直接使用。
(3)几乎所的cpu都分指令缓存和数据缓存,尤其是对一级缓存而言。
(4)当cpu去访问内存的时候,闪存控制器就会去做一系列的检查。
cache-hit(缓存命中)
cache-miss
cache line fill
(5)cpu的每个核心是用自己独立的缓存控制器,其中一个核心把内存中一部分地址缓存在了共享区域,那么另外一个线程当它在访问同样数据的时候它通常都会去共享区做一个查询。如果有的话,就直接把缓存的东西就拿走了,这个直接从缓存中拿的过程叫snooping。
3、缓存跟主存之间的过程
4、缓存的回写机制
(1)核心1的线程1发生数据修改时候,它写到了一级缓存里面,如果用了缓存的回写技术(writethrough),意思就是说目标地址发生变化以后,一级缓存立即要把这数据做同步的。同步之后,一级缓存和二级缓存也必须做同步。二级缓存和三级缓存也必须做同步。三级缓存和主存也做了个同步。也就是说cpu每改一个地方,从上到下都要改一遍,这二个方法叫“write-through”。 好处在于数据绝对可靠,缺点在于效率低。尤其是去频繁的改同一个地方,不停的写。
(2)也就是linux这种方法——write-back Cache。这种技术也就是“不着急写”。当cpu去修改了一个数据之后,它把这个一级缓存里打了一个标签,叫做“Dirty”,代表这个地方被改动过了,这个地方呈现出一个“脏(dirty)”的状态,但不着急的往下级的缓存中写。假如一级缓存改了,它不会把二级缓存立即改,而是会等。它等什么?等万一cpu再有变化,就不需要再跑一趟了。 等多久?会一直等到我这个位置被拿掉之前,只要有位置在一级缓存里面存着,它就不着急。它会等到直到有另外的一批进程要读cpu,这个时候才会进行一个写动作到二级缓存中去。写到二级缓存它又不着急了,它接着等,因为二级缓存比较大,直到等到实在不给我位置了,它再去写。所以它会尽力延迟写,整体效率是提高的。这就是linux用的这种方法。
5、缓存的三种设计思想
(1)Direct Mapped Cache 直接镜像
这种方法非常的便宜,但是它的缺点就是内存中的一个区域只能够固定到缓存的某一个地方去找。
(2)Full Associative Cache 全关联式缓存
也就是说内存中任何一个点,任何一个地址都可以镜像到缓存的任何一个地方。
(3)n-Way Associative Cache n位关联式
也就是说内存中地址可以去缓存中N个地方缓存自己的数据。
6、valgrind 应用程序的检测工具
这个是在linux下非常有名的一个工具,用来做一个应用程序的检测。
示例1:测试缓存命中率 (由于没有提供应用程序,无法进行操作)
#yum install valgrind.x86_64
yum remove valgrind -y
yum install valgrind.i686 -y
//由于此版本是32位,所以需要卸载64位重新安装32位
gunzip application.tgz
tar xf application.tar
//提供了两个应用程序,解压缩出来。
valgrind --tool=cachegrind /root/server-v1 #miss率越低说明越好
valgrind --tool=cachegrind /root/server-v2
示例2:
valgrind --tool=memcheck /root/server-v1
valgrind --tool=memcheck /root/server-v2
7、perf(performance) rhel7已学
在企业版6又推出了一个工具,叫perf,基于内核的子系统(有些操作虚拟机不能),但是关于缓存,这个perf它使用了cpu里面硬件的计数器,监测Linux的性能事件。
#yum install -y perf.x86_64
#perf stat ls#可以查看系统内核相关计数
#perf list#查看所有事件
# perf list | grep minor#查看minor事件
#perf stat -e cycles,instructions,事件#以“,”号为分隔,搜集事件统计信息
#perf stat -a #搜集整个系统的cpu信息
#perf stat -a sleep 10#sleep 10:10秒后停止搜集
#perf record#记录事件样板进行报告,每秒4000的频率
#perf report --stdio#性能报告
--------------------------------------------------------------------------------------------------------------
测试1:
#uname -r
3.10.0-693.el7.x86_64
#yum search kernel | grep debug#搜索debug包
#yum info kernel-debug.x86_64#查看debug的版本与系统版本匹配
#yum install -y kernel-debug.x86_64#架构一样,就可以进行安装
#debuginfo-install perf -y#安装环境
#ls#多了一个perf.data文件
perf.data
#cp perf.data ./perf2.data #拷贝一个data二进制文件,由于没有实验环境,这里看不到明显数据对比
#perf report -i perf.data --stdio#1终端查看perf.data
#perf report -i perf2.data --stdio#2终端查看perf2.data,对比Samples值越小越好
--------------------------------------------------------------------------------------------------------------
第九节POSIX 限制资源、cgroup
1、POSIX 限制资源
cat /etc/security/limits.conf (此配置文件为限制内容<item>)
最传统的办法用POSIX标准下面的pam_limits来对用户的资源进行限制。
限制的对象是用户,如果没有用户,这套机制没法实现。
soft #用户自己能修改
hard #超级用户才能修改
#man 5 limits.conf #查看资源限制的内容
#ulimit -a #当前用户可以限制的板块
pam_limits.so
这是一个动态库,当一个用户成功登录完系统之后,会应用pam_limits.so里面的相关配置。也就 是用户登录以后,要对它设置限制。所以,这个用户不登录,这个限制不生效,因为必须走pam的安全机制才能保证它是生效的。
pam_limits.so
/etc/security/pam_limits.conf 主配置文件。所有子配置文件 /etc/security/limits.d下。两个地方都可以写。
用户登录控制
vim /etc/pam.d/systpm-auth
=>auth #在系统认证登录的时候,linux系统怎么控制你
=>password #你在改密码的时候它是怎么控制你
=>session #用户登录成功之后我在怎么控制你。
#cd /etc/security && vim limits.conf
#=> 1000: hard cpu 10 #uid后面带了“:”代表着大于或者等于的意思,使用5分钟。
#=> @root hard cpu 20 #@代表组
测试1:(让普通用户占用cpu一分钟退出)
用root用户进行资源限制编辑,设置libin用户占用cpu为1分钟,root2分钟)此为主配置文件,也可以定义副配置文件,但主配置文件资源限制内容要删掉或者注释
#cd /etc/security && vim limits.conf (资源限制主配置文件)
# End of file
==>libin soft cpu 1 #软限制一般后面会跟一个硬限制,软限制代表用户自己制可调,但是不能调出硬限制范围。
==>libin hard cpu 2 #硬限制用户最多用一个进程2分钟就没了
#su libin #使用普通用户
#dd if=/dev/zero of=/dev/null #无限写文件,观察只要不超过60秒,都是合法的
#top #会发现libin用户cpu占100%,一分钟后结束)
#ulitmits -t 300 #普通用户直接调到300,你会发现不让你调。超过硬限制了。但是60秒却可以做到
--------------------------------------------------------------------------------------------------------------------------
# cd /etc/security/limits.d/ && vim limits.conf #自定义副配置文件,必须以*.conf结尾
==>libin soft cpu 1
==>libin hard cpu 2
#su libin
#dd if=/dev/zero of=/dev/null
#top #查看效果,意思是到达1分钟

测试2:(用其他用户无法登录,可以限制用户登录)
#cd /etc/security && vim limits.conf
==>libin hard nofile 2 #设置libin用户最多打开2个文件(用户登录不止要打开4个文件)

测试3:(最大登录次数限制,可以限制用户登录)
#cd /etc/security && vim limits.conf
==>libinca hard maxlogins 0 (0:拒绝登录libinca)
测试4:(fork炸弹的原理 ,操作有风险)
# .(){ .| . & };. #写法一
#bomb(){bomb|bomb &};bomb #写法二
#cd /etc/security && vim limits.conf #也可以写入配置文件
“.()”函数的调用,将里面的进程;”.| . &” 将里面的进程自己调用自己,自己执行的结果丢给另外一个程序,这个程序就是自己。自己又植入后台,”;.”反复的调用植入后台
如何限制进程数
cat /etc/security/limits.d/20-nproc.conf
#这里对所有用户能有多少个进程做了一个软限制1024
----------------------------------------------------------------------------------------------------------
fork()炸弹的原理 #如同测试4
vim bomb.sh
=>bomb() #先定义一个bomb的函数
=>{
=> bomb | bomb& #这里面的内容是我要执行bomb,等于自己调用自己,然后把执行结果扔给另外一个程序,也就是自己,并且植入后台
=>}
脚本一旦执行,就会启用这个定义的函数再次调用bomb,然后把输出结果再扔给自己,一直循环下去,永远没有终止,因为每次管道都会产生一次shell。
命令行中缩写:bomb(){ bomb|bomb& };bomb
#在普通用户中运行其实还是非常健康的,1024限制已经生效。root账户执行会卡死。
-------------------------------------------------------------------------------------------------------------------
测试5:如何限制内存
as:就是虚拟内存地址空间,代表着程序希望要多少内存。
rss:代表实时内存。代表程序要的内存,kernel给了多少。
cd /etc/security && vim limits.conf
=>alex hard as 262144 #单位是kb,这里也就是256M
su - alex
ulimits -a #查看alex虚拟内存地址空间位256M。
bigmem -v 200 #申请200M虚拟内存地址空间。当尝试300M的时候就报错。
--------------------------------------------------------------------------------------------------------------
1、cgroup (control group组限制)由企业版6推出来的应用程序的细化管理工具。
man systemd-system.conf#man手册
man systemd.exec #资源限制手册
man systemd.resource-control #审计手册
cgroup就是一种应用程序的质量管理。cgroup把所有的子系统,包括cpu,内存,磁盘,网络等等,然后把这些子系统拆开,把资源分类,分类完成之后给它起名叫controllers。
有了这些controllers之后,将带限制或者带管理的进程,把它分配到这些controllers其中的某些子目录之中,虽然是目录形式显示的,但是它是一种机制,它有一定的寄存性。
cgroup是一个树形结构,也就是分支。在一定程度上分支之会继承“父目录”的限制,
“父目录”的限制会递归下去,而且这些分支的限制会更加激烈一些。
存放路径:# cd /sys/fs/cgroup/
cpu、cpuacct(cpu审计功能)#组限制需要加上审计功能
若要自定义一个服务:
cd /lib/systemd/system && ll #系统服务存放的位置,默认的位置,不要修改
cd /etc/systemd/system/service #可以在路径下创建一个优先级高的服务,可以覆盖lib下
systemctl daemon-reload #重新启动服务
------------------------------------------------------------------------------------------------------------------
#systemd-cgls
#systemd-cgls#查看系统所有的cgroup
systemctl status sshd | grep slice #查看sshd调用了system.slice
# systemd-cgtop #查看系统所有占用system.slice的服务
#find / -name "system.slice”#system.slice存放路径
/sys/fs/cgroup/pids/system.slice
/sys/fs/cgroup/devices/system.slice
/sys/fs/cgroup/systemd/system.slice
/usr/lib/systemd/system/system.slice
---------------------------------------------------------------------------------------------------------------
测试1:(系统用户进程与内存限制)
#useradd -s /bin/nologin rhca#创建一个系统用户
#groupadd rhca1#创建一个组
# vim /etc/security/limits.conf
==>rhca hard nproc 16#限制最大进程数为16
==>@rhca1 hard as 131072#限制组的虚拟内存为128kb,128*1024为字节
测试2:(对服务进行资源限制)
# systemctl status cgconfig.service #开启cgconfig.service服务
#mkdir /etc/systemd/system/cgconfig.service.d
#cd /etc/systemd/system/cgconfig.service.d
#vim 10-libin.conf
==>[Service]
==>LimitNOFILE=32 #限制打开最大文件数32
==>MemoryAccounting=1#”1”就是true ,开启审计功能
==>MemoryLimit=1G#内存限制为1G
#systemctl daemon-reload #重新加载服务
#systemctl restart cgconfig.service#重启服务


------------------------------------------------------------------------------------------------------------------------------
测试3:(创建服务,自定义一个slice文件,被系统所调用)
前提有一个服务占用CPU 为100%,于是我自定义创建了一个服务,我写的较容易理解
不懂可以参考:https://cloud.tencent.com/developer/article/1797865?from=15425
# cd /etc/systemd/system ; vim frontend.service #服务组成的最基本架构
[Unit]
Description=frontend service
[Service]
Type=simple
ExecStart=/bin/sh /usr/local/bin/frontend/libin.sh
[Install]
WantedBy=multi-user.target
#cp frontend.service /usr/lib/systemd/system/ #拷贝到服务的执行主体,可以不用拷贝
#mkdir /usr/local/bin/frontend
#vim libin.sh
dd if=/dev/zero of=/dev/null
#chmod +x libin.sh #给与执行权限
#systemctl daemon-reload
#systemctl restart frontend.service
#systemctl status frontend.service
# cd /etc/systemd/system; vim frontend.slice
==>[slice]
==>CPUAccounting=yes #cpu审计
==>CPUQuota=50% #限制服务使用50%
==>CPUShares= #如果发生抢线的时候,lesscpu只能占父目录的十分之一。share的意思就是大家一起分
# cd /etc/systemd/system ; vim frontend.service
[Service]
==>Slice=frontend.slice #调用frontend.slice
注:由于我创建的服务是调用了dd 命令,所有在dd占用100%cpu的情况下,无法去限制cpu的使用率,需要将dd封装为 frontend服务才行
============================================================================
#在根下就会有一个目录叫cgroup,以下的每一个子目录就是一个控制器的描述常见的cpu,cpuset(cpu粘贴),内存,网络,磁盘I/O,freezer(冷冻)每个控制器在同一时刻只能属于一个结构体。也可以让cpu和内存合并起来,建立成一个子目录。
示例 1:
vim /etc/cgconfig.conf
=>#cpu = /cgroup/cpu;
=>#memory
= /cgroup/memory;
cpu = /cgroup/cpumem;
memory = /cgroup/cpumem; #先注释掉cpu和内存的controllers,然后自定一个,将两个参数合并成同一个controllers。
service cgconfig restart #不要在cgroup目录中启动,这样会启动失败。
ll /cgroup/cpumem #会发现cpu和memory的参数合并了
service cgconfig restart #cgconfig的主要作用是将控制器驱动起来,挂载起来。帮助你去建你自定义的cgroup组。
service cgred restart #cgred服务主要是把你期待的进程给它绑定到cgroup下,也就是说你设置好了一个非常好限制体系,是由cgconfig设计的。cgred就是把你管理的程序丢进去。这个服务仅仅只是一个长相,其实是在kernel层实现,有点像iptables。
lssubsys -m #查看当前挂载
示例2 :关于内存限制
vim /etc/cgconfig.conf
(1)memory.limit.in.bytes代表着未来cgroup里面的进程可以使用多少的物理内存。单位字节。256M
(2)memsw.limit.in.bytes是代表着物理内存加交换分区总值,也就是交换允许使用0字节。单位字节。256M
示例3: 磁盘I/O限制
vim /etc/cgconfig.conf
throttle就是卡口峰值,突然间转变的意思。read_bps是每秒的字节数,device就是针对哪个特定的物理设备,可以针对一个物理设备设置它的最高I/O吞吐量。1000000是1M字节。也就是说未来在dd命令在cgroup里面,它的峰值只能达到1M。8:0是主号和从号,
代表着系统的第一颗物理磁盘。
示例4 :关于冻结
vim /etc/cgconfig.conf
service cgconfig restart
测试1:将指定的程序分派。
注意:虚拟机是双核,最少要三个进程去做竞争,这样做起来过程有点麻烦,直接把其中一个核给屏蔽了,这样两个进程就可以去抢占cpu了。
lscpu #可以查看到当前有两个cpu,在线的是0,1
cat /sys/devices/system/cpu/cpu1/online #值是1就代表cpu1生效。
cat /sys/devices/system/cpu/cpu0/ #命令补全的时候发现没有online这个参数。cpu0被称为主cpu,或者base cpu。是不能掐断的。
echo 0 > /sys/devices/system/cpu/cpu1/online #暂时屏蔽cpu1cgexec -g cpu:lesscpu time
cgexec -g cpu:lesscpu time dd if=/dev/zero of=/dev/null bs=1M count=200000
cgexec -g cpu:morecpu time dd if=/dev/zero of=/dev/null bs=1M count=200000
注:两条条命令同时执行。top查看结果,morecpu先做完
测试2:做内存盘进行试验测试
mkdir /mnt/tmpfs #建立内存盘挂载点
mount -t tmpfs none /mnt/tmpfs #注意,没有源。假的文件系统,资源是不存在的。
df -h #查看挂载
cd /mnt/tmpfs #在这里面写东西直接占内存。与硬盘无关
cgexec -g memory:poormem dd if=/dev/zero of=/mnt/tmpfs/test bs=1M count=200
cgexec -g memory:poormem dd if=/dev/zero of=/mnt/tmpfs/test bs=1M count=300
注:超过256M内存限制的时候,发现还是能成功。free -m的时候,会发现swap虚拟内存竟然被使用。
在/etc/cgconfig.conf文件中,将memsw.limit.in.bytes= 258435456;反注释,然后重启继续测试。
cgexec -g memory:poormem dd if=/dev/zero of=/mnt/tmpfs/test bs=1M count=300 #进程被直接kill,但是已占的都是合法的。
测试3:关于I/O权重的
dd if=/dev/zero of=/bigfile1 bs=2M count=1024
dd if=/dev/zero of=/bigfile2 bs=2M count=1024
echo 3 > /proc/sys/vm/drop_caches #测试之前为了保证公平,把所有的缓存都丢掉
iotop #开新终端用命令进行监控
cgexec -g blkio:lowio time cat /bigfile1 > /dev/null #新开终端测试,bigfile1为2G大文件。
cgexec -g blkio:highio time cat /bigfile2 > /dev/null #再开新终端,bigfile2为2G大文件。
测试4:
vim /etc/cgrules.conf
=> alex:dd blkio ddio/ #当用户alex,运行这个命令的时候,我就把它的子系统绑定在ddio/,进行dd限制
=># *:dd blkio ddio/ #就是支持所有的用户,今后只有有人用dd命令,全部封锁。
=># alex:* blkio ddio/ #当alex用户执行任何命令的时候,都进行I/O封锁。尽量不要与其他条件去相互冲突。
service cgred restart #cgred重启
su - alex #切换普通用户
dd if=/bigfile1 of=/dev/null #从iotop中可以看到 值,不论如何读,都不会超过1M
dd if=/bigfile2 of=/dev/null #换root用户执行,可以看到 值非常的高,完全不受限制。
测试5:冻结
ps axu | grep top #将你想冷冻的进程PID号找到。
echo PID > /cgroup/freezer/stopit/tasks #对PID这个进程进行控制。
echo FROZEN > /cgroup/freezer/stopit/freezer.state #冻结这个进程。top命令立即冻结
echo THAWED > /cgroup/freezer/stopit/freezer.state #进程解冻。THAWED融化的意思
第十节
1、strace和 ltrace
2、systemtap
3、stap权限管理
4、物理内存与虚拟内存
5、page walk
6、TLB
7、Huge Page
8、如何使用大页
9、关于内存的分配
10、交换(swap space)
11、Buffer Cache 与 Page Cache
12、如何调节swappines
13、内存页状态
14、脏页回收(Reclaiming Inactive Dirty)
15、OOM (OUT OF MEMORY)
16、关于进程间通讯的参数
1、strace和 ltrace (函数调用)
strace #s对应着system call,代表kernel核心函数的调用。
ltrace #l对应着library call,代表着glibc的库函数调用。
测试1:查看updatedb命令到底在运行时候干了什么
#strace updatedb #每发起的一个system call都由strace把它抓出来,并且显示
#strace -e trace=network ping -c1 [ip] #尝试ping一下服务器。
#strace -e trace=file ls / #命令运行的时候具体打开了哪些文件
#strace -p [PID] #一个执行的程序,也可以去追踪。随意打点东西,就可以看到追踪情况。
测试2:
#yum install -y ltrace.x86_64
#ltrace updatedb #ltrace追踪的时候显示的是glibc库里面的函数调用。
#ltrace ls / #跟strace显示的不一样的原因是,它显示的是glibc库。
#ltrace -S updatedb #它就相当于strace ,这两条命令有重叠性。
#strace -c updatedb #-c之后就对整个程序执行的系统调用进行统计。
#ltrace -c updatedb #这条命令慢,但不论是ltrace还是strace,在执行的过程中都是监控本进程的,但是派送出来的子进程是不跟踪的。
2、systemtap (性能跟踪子系统)、stap权限管理
(1)可以帮助我们追踪,以及kernel的行为。它内部的结果用了kprobes(kernel子系统),
kprobes是非常要需要专业支持才能去编码的一个子系统,专门用来对kernel进行追踪,或者做性能调查等等。
(2)如果你的systemtap要工作在开发环境下,要对这个脚本进行开发,这需要一个环境,那么以下软件包是需要的
若
前内核版本 :
#yum search 'systemtap ' yum search systemtap | grep systemtap
# yum search 'kernel'| grep debuginfo
#yum install -y kernel-debuginfo, kernel-debuginfo-common, kernel-devel ,systemtap, gcc
#cd /usr/share/systemtap/examples/ #stp文件的路径
#/usr/share/systemtap/examples/io
#cat disktop.meta #查看磁盘的一些数据
#stap -p4 disktop.stp
#stap -v topsys.stp
#stap -v -p 4 -m topsys topsys.stp #到第四步停下,并且我自己指定一个kernel名称叫#topsys,然后指定脚本topsys.stp
#ll topsys.ko #可以看到这个模块
#modinfotopsys.ko #查到它的相关信息了
#staprun topsys.ko #用超级用户来执行它
通常情况下是超级用户来插入这个kernel模块的,但是生产里面,超级用户不是每时每刻都在身边,那么作为一个普通用户如何才能够做stap的一个基本的排错和调用?系统中留了个后门,所有在stapusr组的人可以去systemtap/*.ko中执行各种ko后缀的文件。
ll /usr/bin/staprun #看看这个命令的权限
示例
useradd -G stapusr alex
su - alex
mkdir /lib/modules/2.6.32.*/systemtap #root用户做
cp /topsys.ko /lib/modules/2.6.32.*/systemtap #root用户做
//只有把这个模块拷贝到systemtap目录下的时候才可以去访问topsys.ko这个模块。但是这个systemtap不存在,所以也只能root用户干预的情况下才能创建出来,如果没有root用户干预,这个模块是拷不过来的。
staprun /lib/modules/2.6.32.*/systemtap/topsys.ko #普通用户可以访问核心了
usermod -aG stapdev alex
su - alex
staprun /topsys.kpl
3、物理内存与虚拟内存
(1)所谓的物理内存就是安装在主板上面的,而且你看得见的内存。程序是不会直接访问物理内存的,一个物理内存页,它叫page frame(页帧)。
(2)虚拟内存叫page(单位 页)。程序分配的是虚拟内存。
(3)多个进程之间可以去共享同一片物理内存,这是由kernel来控制的。虚存这个是不同的,每个人都是由自己控制的,但有可能N个虚存地址指向了同个物理页面,这是有可能的。
这就是liunx分配内存的机制。尽量延迟分配,尽量共享,这样可以让内存放大。
1page=4K
X86虚拟内存空间有2^64,红帽虚拟内存空间支持128G
测试1:
#systemctl set-property sshd.service MemoryLimit=1G/K/M/T#对服务进行内存限制
#systemctl cat sshd.service #查看一个服务的内存限制
# systemctl daemon-reload#重新加载配置文件
4、page walk
(1)page walk这个动作是有硬件来支持的,但是很贵,因为内存慢。
(2)访问一次内存,如果缓存中有的话,从缓存中拿,如果没缓存,需要去内存中拿,所以这个时钟周期可能会是10-100个时钟周期,得看缓存的命中率。
(3)最好的办法就是把这些东西缓存起来。把这个虚拟内存到物理内存的这个指针,最好能缓存起来,今后再次使用的时候,就不需要再做一个page walk,所以有个地方可以缓存这个数据。
5、TLB(Translation look-aside buffer)
(1)TLB是一个cpu里面一个非常小的缓存,专门是用来镜像虚存到物理内存的。目的就是提速这个转换的过程。
(2)cpu首先是检查TLB里面的buffer有没有它,如果有就直接还回地址了,这样非常快就把内存抓出来了;如果没有,就得做page walk,这就是一个非常贵的一个过程,顺便把新翻译的东西缓存起来,以备下次使用。如果没有TLB,性能会有一个很大的损伤,大约有15%的性能都在用TLB。而且访问TLB的速度可以说小于一个时间周期。
(3)TLB的内存结构是CAM格式的,是一种设计思想。
(4)CAM这种内存首先它很贵,而且也很难生产,它主要面向的对象就是搜索起来非常快。
# yum install -y x86info-1.30-6.el7.x86_64
# x86info -c #查看cpu的tlb缓存(可看到1个大页可以到4M/2M)

6、Huge Page
(1)HugePage广泛启用开始于Kernal 2.6,一些版本下2.4内核也可以是用。在操作系统Linux环境中,内存是以页Page的方式进行分配,默认大小为4K。如果需要比较大的内存空间,则需要进行频繁的页分配和管理寻址动作。
(2)HugePage是传统4K Page的替代方案。顾名思义,是用HugePage可以让我们有更大的内存分页大小。无论是HugePage还是传统的正常Page,这个过程都涉及到OS内存寻址过程。
(3)当一个进程访问内存的时候,并不是直接进行内存位置访问,是需要通过Page Table进行转移变换。在使用HugePage的情况下,PageTable具有了额外的属性,就是判断该页记录是HugePage还是Regular Page。
7、如何使用大页
#cat /sys/kernel/mm/transparent_hugepage/enabled#查看大页是否启用
always:表示已经启用
madvise:
never:
#grep AnonHugePages /proc/meminfo#查看当前使用透明大页大小
相关测试可以用bigmem进行(RHEL7不支持)
#cat /proc/meminfo | grep -i hug #查看系统大页大小
#grep Huge /proc/meminfo
#sysctl -a | grep vm.nr_hugepages
# sysctl -a | grep -i huge #列举所有的大页
#sysctl -w vm.nr_hugepages=10 #临时分配大页 ,重启会失效
vim /etc/sysctl.d/10-hugepage.conf
==>vm.nr_hugepages=10 #写入配置文件,永久生效
# sysctl -f /etc/sysctl.d/10-hugepage.conf #生效
# mkdir /libin
mount -t hugetlbfs none /libin/
#yum install -y numactl-2.0.12-5.el7.x86_64
#numastat -cm #查看在哪个节点上使用了大页
# numactl --hardware #查看节点的cpu、内存大小
#lscpu | grep -i numa #查看NUMA节点个数
#numastat -c 进程 #查看进程在节点的大小
如果要使用大页,有两种手段,第一,就是建立一个叫“hugetlbfs”的伪文件系统,然后应用程序通过mmap这个函数调用,来使用这个挂载点。mount之后它用这种特殊的程序去访问挂载点。第二,就是使用共享内存,用shmget和shmat这两个系统调用的时候呢,把这个区域设置为共享内存,让进程间通讯的时候来使用,适合于甲骨文。
注:不要将透明大页用于数据库负载上,数据库会跳过内核去自行管理,透明大页无法使用。
COW(copy on write):写时复制 虚存空间功能,在可能的情况下,大家尽量的共享,其中一个进程要写,这时进行拷贝。
8、关于内存的分配
(1)进程在申请内存的时候,kernel给它的承诺是虚存地址空间,而不是真正的物理内存。只等进程真正需要物理内存的时候,才会发生一个page fault的页错,如果是个小错误的时候,那就是还没来得及分配,那就赶紧分配出来;如果发生大错误,直接给交换出去了,要从磁盘读取出来,这种代价是相当高的。
(2)使用完之后,内存直接回收掉。这就是一个进程从诞生一直到自己结束时候,通常会碰到内存的使用方法。内存分配就是这么一个原则。
9、交换(swap space)
(1)交换的思想就是可以增加机器的内存,把交换分区看成是内存的一部分。
那些页面没有被使用的,可以考虑交换到磁盘里面去。这样的话可以腾出更多的剩余内存出来,CPU就不用去忙着扫描有没有非活动页面,然后去回收了。
(2)直到这个页面真的被使用的时候,然后它去磁盘中把刚才导出的数据交换回来,但是代价很高。
(3)交换出去的内存,其实是会对性能不会有影响的,甚至对性能还有提升,因为机器还有更多的剩余内存使用。
(4)设置交换分区的时候,要抱着一个基本的思想,它从一定程度上来讲把我们硬盘给变大了,没事还小小交换一下,还提高系统的性能。而且从另外的程度上来讲,它可以防止out-ofmemory(OOM)。
#watch ps -o vsz,rss,comm -C bigmem #查看每秒钟 系统虚拟内存占用情况
10、Buffer Cache 与 Page Cache
buffer cache #主要是存放文件系统的元数据。
page cache #就是赤裸裸的在文件内容的一个在内存中的缓冲。
echo "N" > /proc/sys/vm/drop_caches
1 => block data #清空page cache
2 => meta data #清空buffer cache
3 => block data & meta data #内存中的缓存尽量的给丢弃掉
11、如何调节swappines
swap_tendency = 当前内存使用比率/2 + 系统渴望释放内存值(0-100)+ vm_swappines
12、内存页状态
(1)第一种,free,剩余内存。
(2)第二种,Active,说明这个进程现在正在访问这个内存
(3)第三种,Inactive Clean 。意思是说这个内存是被分出去了,有可能是当做文件系统为了提速用的cache,但是它从来没有发生过写操作,就算我这个时候把这个内存片从中间擦除,数据不会有任何的影响,只不过下次要读这个磁盘文件的时候,又得重读一遍而已。
(4)第四种,Inactive Dirty。就是如果要从磁盘中读出的文件被修改了,还没存盘。
13、脏页回收(Reclaiming Inactive Dirty)
进程不断在运行中,不断在写文件,到底什么时候把这个脏数据写到硬盘里面去。这个叫脏页回收
企业级6之后,现在针对与每一个块设备都有一个自主的“pre-BDI-flash”线程,在kernel里面表现出来就是“flash-主号:从号”(flush-MAJOR:MINOR),你I/O重的时候,ps会看见"flush
MAJOR:MINOR" ,说明现在这个磁盘正在flash。因为制造了太多的脏东西,kernel开始要写
东西了,会不停的把脏页往磁盘里面刷。
针对脏页回收可调的四个参数 (内核开关 sysctl -a 可以查看)
第一个:vm.dirty_exprie_centisecs #单位为1/100%秒,关于脏页过期时间
第二个:vm.dirty_writeback_centisecs #单位为1/100%秒,每隔多长刷新内核新线程数据
第三个:vm.dirty_background_ratio #内核在后台写数据,脏页在系统内存中的百分比,默认10%
第四个:vm.dirty_ratio #脏页占系统总内存的百分比,默认30%
14、OOM (OUT OF MEMORY) 内存溢出
这通常是因为某时刻应用程序大量请求内存导致系统内存不足造成的,这通常会触发 Linux 内核里的 Out of Memory (OOM) killer,OOM killer 会杀掉某个进程以腾出内存留给系统用,不致于让系统立刻崩溃。
vm.overcommit_memory #参数设置
vm.overcommit_memory=0
#0是默认值。那么既然会发生OOM,承诺的过多了,那怎么能让内存收敛一下?在默认情况下,kernel是会很大方,要内存就会给,除了一些非常疯狂的程序以外,kernel会自动去识别到底要不
vm.overcommit_memory=1
#就是完全不做任何检查,你要多少给你多少(最好不跑关键业务)
vm.overcommit_memory=2
#超过能力限制,绝对不会给你。
# sysctl -a | grep oom | grep panic
vm.panic_on_oom = 0
#”1“,kernel内核承诺过多,将系统挂起。进行保护,内存不足也会进行保护。
#cat /proc/meminfo | grep AS #查看虚存地址空间

测试:(每隔1秒在系统中查看脏页值)
[root@libin4 ~]# while :
> do
> grep Dirty /proc/meminfo
> sleep 1
> done
---------------------------------------------------------------------
#打开另外一个终端
# sysctl -a | grep vm.dirty_background_ratio #当系统的内存10%,代表数据已经脏掉,kernel会进行刷脏页,我这里的内存为4000M
#freem -m #为total的10%
# dd if=/dev/urandom of=/var/libin #写入磁盘,查看脏页变化,快到达10%脏页会回收
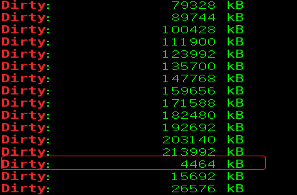
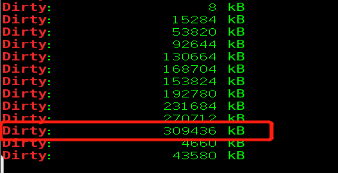
测试2:修改脏页比为20%
# sysctl -w vm.dirty_background_ratio=20
# dd if=/dev/urandom of=/dev/libin
它的算法是“当前交换分区大小+物理内存的百分比(默认是50)”,这两个值加起来作为你单个进程可申请的虚存最大值。要给多余的虚存空间,所以它的大方是给予它自己会测试的基础上,而不是疯狂的基础上,但基本上只要你要内存,它一般还是会给。
15、关于进程间通讯的参数
进程之间是独立的,为了让它们之间的通讯,kernel创造了一些手段,有sysv标准的进程间通讯手段,还有IPC进程之间的通讯手段。但它们都分为三类:
第一类:信号令。
第二类:消息队列。
第三类:共享内存。
信号令的4个参数
sysctl -a |grep kernel.sem 从左到右
① 系统中每个信号令数组的最大值
② 代表着整个系统,不管你申请了多少个信号令数组
③ 系统中最多信号令的个数
④ 代表着每个信号令,可以发出去最多的system call有几个
(1)关于消息队列有3个参数
sysctl -a | grep kernel.msg
① kernel.msgmnb。一个消息队列里面最多可以放多少个字节,一个消息队列的总长度64K
② kernel.msgmax。在这些消息里面,一个队列有多大,还是64k。也就是说一个消息可以把一个队列占满。
③ kernel.msqmni。消息队列在系统中的个数。这跟内存相关,可能是个随机数字。
(2)关于共享内存的参数
sysctl -a | grep shm
① kernel.shmmni #代表着全局可申请多少个共享内存段
② kernel.shmmax #是每个共享内存段的最大值,这里是64G,也就是基本上没有限制。
③ kernel.shmall #既然分了这么多个共享内存段,它全局最多能使用多少内存。
第十一节文件系统
1、RHEL6支持的文件系统
2、文件系统日志
3、日志在制作过程的三种模式
4、降低到达率
1、RHEL系统支持的文件系统
rhel5:ext3 ext4 xfs btrfs
xfs:可靠,高度可扩展高性能的文件系统,文件系统最大限制1PB。单个文件可以达到1PB,开机不会执行XFS文件完整性检测。不能压缩只能拉伸。
ext4:具有50TB的文件系统限制,超过50TB格式化不了,包含了ext3的所有功能。可以扩展与压缩。
( /etc/fstab batch discard:批量丢弃 schedule batch discard:计划批量丢弃 online diacard:在线丢弃 )
#fstrim /dev/mymountpoint 进行批量丢弃
# systemctl enable --now fstrim.timer 计划批量丢弃
#mount -o discard /dev/mydevice /mymountpoint 在线丢弃
#vim /etc/fstab
==>/dev/mydevice /mymountpoint xfs defaults,discard 0 0 #永久性丢弃
xfs文件系统格式选项:
#mkfs.xfs -i size=512 /dev/mydevice #”-i” 节点,默认1个节点大小为256字节
(1block=512字节,1节点=512字节,1block=2个节点)
#mkfs.xfs -n size=8192 /dev/mydevice #“-n”目录逻辑块大小
ext4文件系统格式选项:
#mkfs.ext4 -I 128 /dev/mydevice #“-I” 指定节点大小,默认为256k
文件系统的挂载选项:
default默认选项:rw, suid, dev, exec, auto, nouser, and async.
atime:授权与内核的一杆默认行为,仅用于目录
relatime:默认每天更新一次选项
nodiratime:仅用于目录
XFS的挂载选项:
inode64:rhel8默认开启,靠近数据的位置以最小的磁盘查找
logbsize:日志访问区大小,默认大小为32KB,也可以配置64kb,128kb,最大可以配256kb。
#mkfs.xfs -f -d su=512k,sw=2 -b size=4096 -n size=8192 -i size=512 /dev/md0 #-n:逻辑块,-i:节点,-b块大小
#lsblk #看到10G的RAID0
#blkid #文件系统为XFS格式
#mkdir /xfsraid #创建挂载点
#mount /dev/md0 /xfsraid #挂载
#umount /xfsraid #卸载
#vim /etc/fstab #进行永久挂载
/dev/md0 /xfsraid xfs nodiratime 0 0
#mount /dev/md0 #再挂载
#findmnt --target /xfsraid或者#mount | grep md0#查看挂载选线
2、文件系统日志 (journal placement)
文件系统日志有两个目: (norecovery:禁用日志恢复功能,只能以只读文件进行挂载)
① 第一个,让文件系统的恢复速度变快。
② 第二个,日志可以保证文件系统的一个可靠性。
3、日志在制作过程的三种模式
data=ordered #这是默认模式。意思就是说日志区是在记录着原数据。
data=writeback #无限制
data=journal #文件系统的原数据和数据块的数据,全部都进这个日志区
带有外部日志的XFS、EXT4文件系统:
mkfs.xfs -l logdev=/dev/sda1 /dev/sda3 #/dev/sda1为放日志,/dev/sd3为放数据,先创建
mount -o logdev=/dev/sda1 /dev/sda3 /mnt #进行挂载、/mnt 为日志位置
------------------------------------------------------------------------------------------
mkfs.ext4 -O journal_dev -b 4096 /dev/sda1 #-b:指定块大小
mkfs.ext4 -J device=/dev/sda1 -b 4096 /dev/sda3 #创建文件系统,指导数据盘符查看块大小
tun2fs -l /dev/sda3 #查看文件系统信息
4、降低到达率
(1)既然日志这么好使,那么有一个最好的办法,就是降低到达率L=A*W,就是降低A,降低A的方法,就是将日志区扔在其他的磁盘上,让达到率平均分配在若干磁盘上,甚至可以把日志做成raid,还可以是ssd,让它写数据的时候非常快,然后再往下下发,这可以大大的提高性能。
(2)日志的大小从标准上讲,假如你是4K的block size,那么它是4M-400M。ext4一出来后,这个block size 就不确定了,需要查相关的文档
示例1 :新建文件系统使用的外部日志(sda5的日志放sda6里)
#fdisk -c -u /dev/sda #以扇区的形式分区,分400M
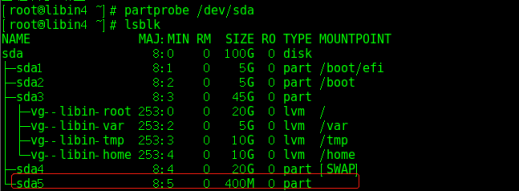
#partx /dev/sda5
#mkfs.ext4 -O journal_dev -b 4096 /dev/sda5 #用来当做未来日志文件系统来使用,是单独的,不能再做任何使用
#fdisk -c -u /dev/sda #在sda上新分一个区出来/dev/sda6
#partprobe /dev/sda
#mkfs.ext4 -J device=/dev/sda5 -b 4096 /dev/sda6 #做了一个新的文件系统,在sda6上, 并且拿sda5做为它的日志区
#echo “/dev/sda6 /mnt/libin ext4 defaults 0 0 ” >> /etc/fstab
#tune2fs -l /dev/sda6
已经存在的文件系统使用外部日志 :(centos7未测试成功)
#fdisk -c -u /dev/vdb #新建大小为100M
#partx -a /dev/vdb
#mkfs.ext4 -O journal_dev -b 1024 /dev/vdb2 #当做单独的日志文件系统使用
#umount /boot
#tune2fs -O ‘^has_journal’ /dev/vda1 #-O就是使用调节功能,^就是取反
#tune2fs -j -J device=/dev/vdb2 /dev/vda1 #-j 表达要调节添加日志,-J是来指定设备。
#mount -a
#tun2fs -l /dev/vda1
第十二节 网络方面的调优
# sysctl -a | grep net.ipv4.tcp_mem
# sysctl -a | grep net.ipv4.udp_mem
1、qperf
这是企业版6引入的一个非常好的工具。qperf是用来测网络的,它是运行在两个计算机之间的,它是c/s结构(服务器端/客户端)。它的思想是服务器端运行qperf,客户端执行qperf+主机名+ 具体想测什么
# yum install -y qperf.x86_64
示例 :
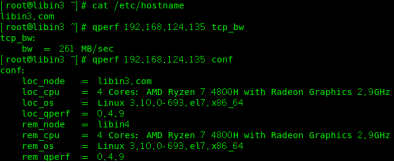
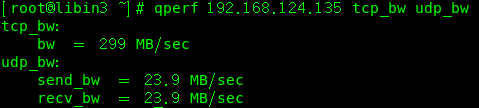
服务端libin: qperf
客户端libin2:qperf libin conf #conf这样可以查看一下配置文件
客户端libin3: qperf libin1 tcp_bw tcp_lat udp_bw udp_lat #查一下tcp和udp的带宽和延迟
客户端libin4:qperf -oo msg_size:1:32K:*2 libin1 tcp_bw tcp_lat udp_bw udp_lat
#-oo是选项,把msg_size包大小传输的这个字节数;由:1个字节提升到:32k ;
:*2就是每次提两倍,也就是每次乘以2
测试1:(这里拿(libin4 (192.168.124.135)当做服务端,libin3(192.168.124.133)为客户端)
(服务端要关闭防火墙 systemctl stop firewalld.service )

客户端测试
2、网络延迟
sysctl -a | grep net.core.rmem_max
net.core.rmem_max = #指出最大接收器窗口大小,硬限制
net.ipv4.tcp_low_latency
这里调的是tcp的一个延迟,才默认情况下低延迟是关闭的,也就是是说当前的这个企业版6的系统是面向高吞吐量设计的,如果想让它增加tcp反应速度,而不是吞吐量,这个值可以设置为“1”。这个东西测不出来,但是参数的确是存在的,kernel自己会对整个的网络策略做调整。注意,这里调节的时候是两边机器一起调。
3、TCP/UDP Buffer的调节
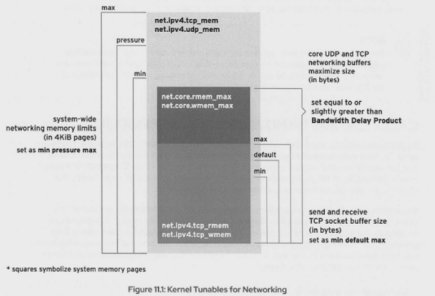
#sysctl -a | grep net.ipv4.tcp_mem
#sysctl -a | grep net.ipv4.udp_mem
这两个核心参数是针对全局的,占到内存总数的极限值,单位是page,也就是4096个字节。这两个值通常不需要大家去干预。这个值在企业版6下,开机之后是接近内存的。可以去看,一般不需要去调节。无论是tcp还是udp,它都有三个值:
min 最小值
pressure 压力值
Max 最大值
(1)UDP buffer如何调节
核心网络参数(既然你是核心,那就包括所有的网络行为,其中有udp和tcp。如果你想调upd)
① net.core.rmem_default #收包的时候,这边的buffer是多大(字节)
② net.core.wmem_default #发包时候的buffer(字节)
③ net.core.rmem_max #当一个用户在连链接的时候,可以指定链接的大小。但是不能超过这整个值。
④ net.core.wmem_max #同上一条。或者这个值,也是不能超过的,这是极限值
ipv4的网络参数
① net.ipv4.udp_rmem_min
② net.ipv4.udp_wmem_min #无论kernel怎么干预,这两个值是给你最小的保障,放的再小都不会逾越这个限制。如果一个buffer小于这个值呢,那么这个链接就已经慢得离谱了
(2)tcp buffer如何调节
net.core.rmem_default
net.core.wmem_default
net.ipv4.tcp_rmem_min
net.ipv4.tcp_wmem_min
//tcp专有的两个参数,一个收包,一个发包
(3)buffer大小的算法
1、如果buffer给大了,速度其实是会下来的。因为对那种非常小的包,要满足你的buffer是需要时间的,所以它会反应很慢,延迟增加。所以调大不是个好事。那么调的太小的话,你的缓存区一满,新进来的包得等待或者掉包。到底给多大,这里有一个针对这种特别需要buffer的连接,叫BDP (Bandwidth Delay Product)连接,BDP连接就是一种慢速网络,延迟比较大,经常需要针对这种情况去进行调优。
2、BDP = 带宽 * 延迟
示例:延迟为2秒,1M带宽需要多大的buffer才能满足BDP的链接?
1*2^30个字节/8 * 2s = 262144字节 = 256k
4、以太网卡绑定 (双网卡绑定,链路聚合)
bonding的工作模式
balance-rr: (轮询)。这种方法既可以提供一个容错,又可以进行负载均衡。
active-backup:(热备)。同时只有一块卡在工作,如果一块卡失败了,就切换到另外一块卡上继续使用。这种模式不带负载均衡,因为只有一块卡在工作。
802.3ad,4::标准用法,现在数字是4,动态链接协商。
示例 (1):
vim /etc/modprobe.d/bonding.conf
=>alias bond0 bonding
cp /etc/sysconfig/network-scripts/ifcfg-eth0 /etc/sysconfig/network-scripts/ifcfg-ifcfg-bond0
vim /etc/sysconfig/network-scripts/ifcfg-bond0
=>DEVICE=“bond0”
//注释掉mac地址。其他不需要改变
=>BONDING_OPTS="mode=0"
vim /etc/sysconfig/network-scripts/ifcfg-eth0
=>DEVICE=eth0
=>SLAVE=yes
=>MASTER=bond0
//注释掉mac地址。其他不改变
vim /etc/sysconfig/network-scripts/ifcfg-eth1
=>DEVICE=eth1
//注释掉mac地址。其他不改变
=>SLAVE=yes
=>MASTER=bond0
service network restart
cat /proc/net/bonding/bond0
#查看一下绑定状态
ifdown eth0
//其他网卡可以继续工作。
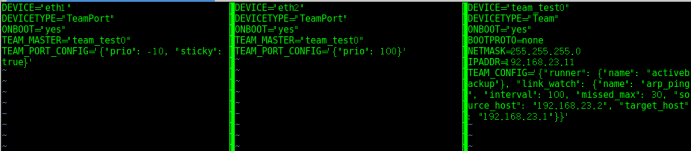
#cd /usr/share/doc/teamd-1.25/example_ifcfgs/3/ #双网卡绑定,系统示例
#vim -O ifcfg-eth1 ifcfg-eth2 ifcfg-team_test0
5、关于协议
(1)当数据在网络传输的过程中,那么有开销,其中包含了以太网的头信息、ip的头信息和tcp头信息。正对我们一个网络包而言,它一次发出去的size,就被称为MTU(最大传输单元),这些开销全部包含在MTU里面。
(2)对于一个tcp链接来说,它需要52个字节来描述这三种信息(以太网的头信息、ip的头信息和tcp头信息),52/1500=3.5%,这个3.5%就是开销。
(3)对于udp链接来说,它的头信息是28个字节,28/1500=1.9%做为开销。
(4)理论上来讲,在相对稳定的网络中,upd的效率要高于tcp
6、大帧(Jumbo Frames)
(1)如果能够把MTU这1500的限制给取消了,那这个开销的比例就大大的减小。MTU大于1500的,都被称为大帧,如果想开启这个功能,需要将网络中所有的设备,包括路由器一起,必须全部都支持大帧才可以。
(2)比如说大帧有9000字节。tcp连接下,52/9000=0.58%,这个开销就是0.58%,比起3.5%这个值就降下来了。也就是这个大帧到底能提高3%的性能
(3)echo “MTU=9000” >> /etc/sysconfig/network-scripts/ifcfg-eth0
第十三节 虚拟化环境主机性能调优
1、KVM 基于内核的虚拟化(libvirtd虚拟机服务)
安装KVM(环境安装)
#yum search 'kvm'
#yum install libvirt-daemon-kvm.x86_64 qemu-kvm.x86_64 qemu-kvm-common.x86_64 virt-p2v-maker.x86_64 virt-v2v.x86_64 qemu-kvm-tools.x86_64
#um install -y qemu-kvm* #安装virsh虚拟机环境
# yum install -y virt-manager* #安装虚拟机管理窗口
# yum install -y virt-install.noarch #安装创建虚拟机命令
示例:第一种创建池
#mkdir -p /data/virtual/dirpool
#cd /data/virtual/dirpool/
# virsh pool-define-as rhca dir --target '/data/virtual/dirpool'pool #定义池(rhca)
# virsh pool-build rhca #构建池
# virsh pool-start rhca #启动池
#virsh pool-autostart rhca #标记池自动启动
# virsh pool-list #列举池
# virsh pool-dumpxml rhca #以xml查看池信息
示例:创建卷
#virsh help vol-create-as #存储卷帮助
# virsh vol-create-as 池名 卷名 10GiB --format qcow2 #创建卷(rhcavol)
# virsh vol-list 池名 #查看卷名路径
# virsh vol-info 卷名 --pool 池名 #查看卷的信息
# virsh vol-dumpxml 卷名 --pool 池名 #以xml方式查看卷的信息
示例:创建domain虚拟机
#virt-install --help #查看创建虚拟机的帮助
# virt-manager #virt-manager创建虚拟机(rhel7.1)
# virsh dominfo rhel7.1 #查看虚拟机的信息
# virsh dumpxml --domain rhel7.1 #以归档xml形式查看虚拟机
# virsh numatune rhel7.1 #查看映射内存的num节点
# virsh vcpupin rhel7.1 #查看rhel7.1的vcpu在哪个物理cpu上运行
#cd /etc/libvirt/qemu #虚拟机的配置文件路径
基于intel 或 AMD-V(更多信息可以查看我的kvm文档)
qemu:内核进程,多平台的仿真程序,提供仿真平台,提供硬件辅助式虚拟化,逻辑上的。网络环境:网卡(网络控制器)、存储、内存、随机数字生成器、usb接口、网络驱动器、视频设备。
#Virsh: 虚拟机命令
#systemctl status libvirtd.service 虚拟机服务
#cd /etc/libvirt/qemu/ && ll 虚拟机配置文件

#cd /var/lib/libvirt/images/ && ll rhca.qcow2 虚拟机存在路径
# virsh list --all 列举虚拟机

# virsh dumpxml 虚拟机名称 #以xml格式查看虚拟机
# virsh dumpxml rhca | grep -i 'cpu' #查看虚拟机(rhca)的cpu信息
# virsh dumpxml rhca | grep cpu -A2 #查看你前2个cpu的详细详细
#virsh dumpxml rhca | grep memballoon -A2 #查看同页前2个信息
#kvm_stat #以主机角度显示虚拟机,实时状态
#Kvm_entry、kvm_exit 值 #代表 cpu的负载情况
按q退出,按x键切换整个系统内核、按g切换虚拟机界面
#ls /sys/kernel/mm/ksm/* #内存扫描,同页合并
#qemu-img info * #查看镜像的类型
==>raw(性能好,不能支持快照恢复) qcow2(支持快照,加密,压缩)
# qemu-img create -f qcow2 -o preallocation=metadata /var/lib/libvirt/images/dis.qcow2 1G
#创建1个1G的磁盘,preallocation=(可以选择metadata,falloc,full)
2、嵌套式虚拟化:虚拟机里面的虚拟机
前提:虚拟机关机情况下
cpu双绑定:
#virsh vcpupin 虚拟机名 --config 0 0 #将虚拟机进行cpu绑定
#virsh vcpupin 虚拟机名 #查看cpu绑定情况
#virsh dumpxml --domain 虚拟机名 | grep vcpupin #也可以看到2个cpu进行了绑定
更改qemu线程:
#virsh emulatorpin 虚拟机名 --config 1 #将虚拟机qemu线程绑定到1上
#virsh emulatorpin 虚拟机名 #查看线程绑定情况
更改cpu共享:
#virsh schedinfo 虚拟机名 --config #查看虚拟机的调度信息
#virsh schedinfo 虚拟机名 --config cpu_shares=2048 #更改虚拟机cpu共享大小
设置虚拟机内存限制:
# virsh memtune虚拟机名 #查看虚拟机的内存限制
# virsh dominfo 虚拟机名 #查看虚拟机的内存大小等信息
#virsh memtune虚拟机名 --config --soft-limit 512M #设置内存软限制512M
同页合并:
#systemctl stop ksmtuned.service
#systemctl stop ksm
#virsh edit 虚拟机名 #不共享大页
#qemu-img create -f qcow2 -o preallocation=metadata /var/lib/libvirt/images/dis.qcow2 1G #创建1G的磁盘
#virsh edit 虚拟机名 #再添加一块磁盘,更改格式,PCi,磁盘路径,磁盘名
#virsh blkdeviotune rhel7.1 vdb --config --total-iops-sec 1000 #设置磁盘io为1000
# virsh domrename 旧虚拟机名 新虚拟机名 #更改虚拟机名称

#cd /etc/libvirt/qemu #虚拟机的主配置文件路径
#virsh dumpxml rhca > /var/lib/libvirt/images/rhca.xml #备份更改的虚拟机文件到创建的磁盘路径,任意路径都行
# virsh undefine rhca #取消定义虚拟机主配置文件就没了
#virsh define /var/lib/libvirt/images/rhca.xml #重新定义

#virsh start rhca #开启虚拟机,此虚拟机为重新定义的虚拟机

# virsh domifaddr rhca #查看虚拟机的MAC地址,IP地址
3、监控虚拟化环境的性能指标(监控工具:普罗米修斯、格拉法纳grafana)
基于9090端口
https://grafana.com/docs/grafana/latest/installation/rpm/ #官网地址,grafana
https://www.cnblogs.com/imyalost/p/9873641.html #参考搭建
Alerting:报警级别
Export:导出器
PushGateway:网络推送网关
1、创建1个开机启动的服务
2、./node_exporter提取二进制文件
Centos7安装grafana:
#wget wget https://dl.grafana.com/oss/release/grafana-6.4.4-1.x86_64.rpm
#yum install -y grafana-6.4.4-1.x86_64.rpm
#yum clean all
#systemctl status grafana-server.service
#systemctl daemon-reload
#systemctl status grafana-server.service
#netstat -tnlp | grep grafana
==>firefox==>http://192.168.124.135:3000/login--admin:admin
普罗米修斯安装参考:
https://www.jianshu.com/p/0f91a140e545
https://blog.csdn.net/heian_99/article/details/103952955
https://prometheus.io/download/ #官网

 浙公网安备 33010602011771号
浙公网安备 33010602011771号