2-分词器
分词器的作用是什么?
ES在创建倒排索引时需要对文档分词;在用户搜索时,需要对用户输入内容分词。但默认的分词规则对中文处理并不友好。处理中文分词,一般会使用IK分词器。https://github.com/medcl/elasticsearch-analysis-ik
IK分词器有几种模式?
ik_smart:智能切分,粗粒度
ik_max_word:最细切分,细粒度
两种分词器示例


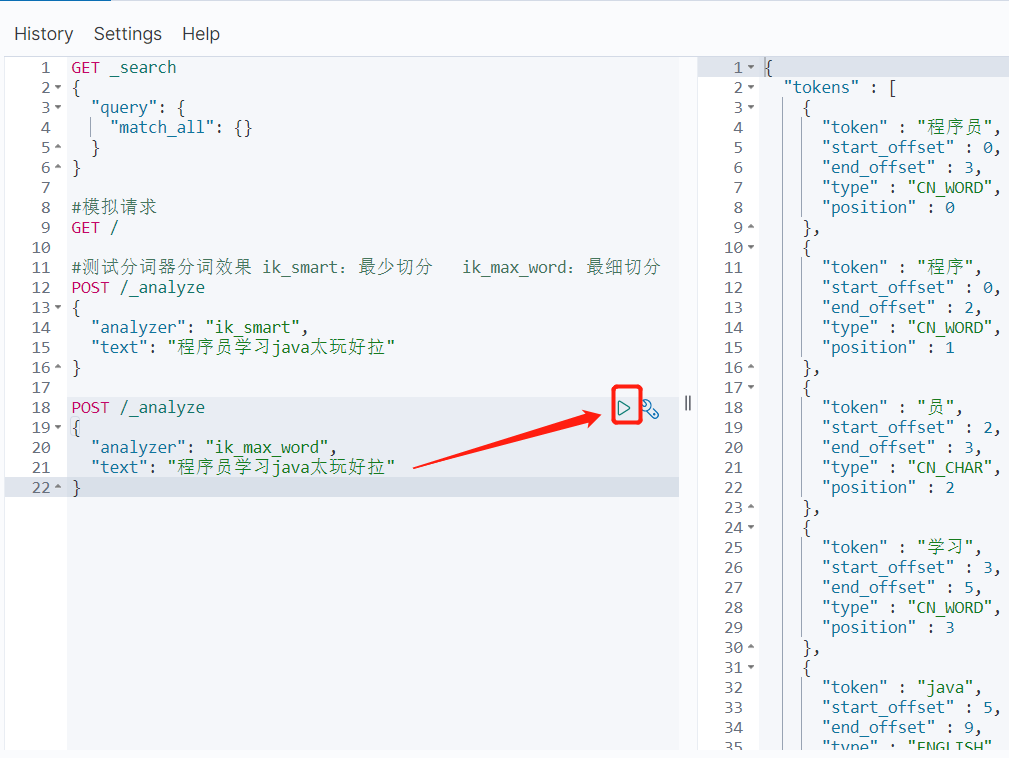
#测试分词器分词效果 ik_smart:最少切分 ik_max_word:最细切分 POST /_analyze { "analyzer": "ik_smart", "text": "程序员学习java太玩好拉" } POST /_analyze { "analyzer": "ik_max_word", "text": "程序员学习java太玩好拉" }

IK分词器如何拓展词条?如何停用词条?
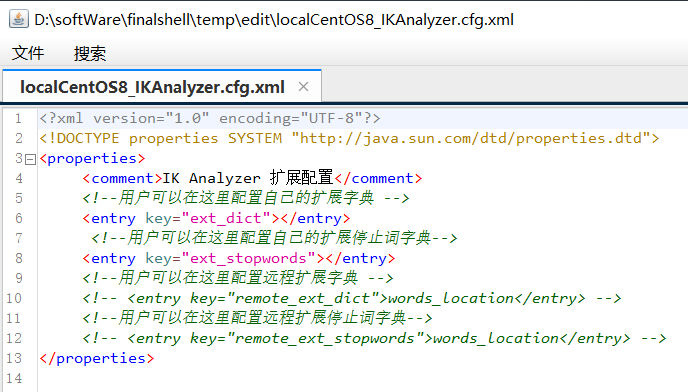
要拓展或者禁用ik分词器的词库,只需要修改一个ik分词器目录中的config目录中的IkAnalyzer.cfg.xml文件:
/var/lib/docker/volumes/es-plugins/_data/ik/config
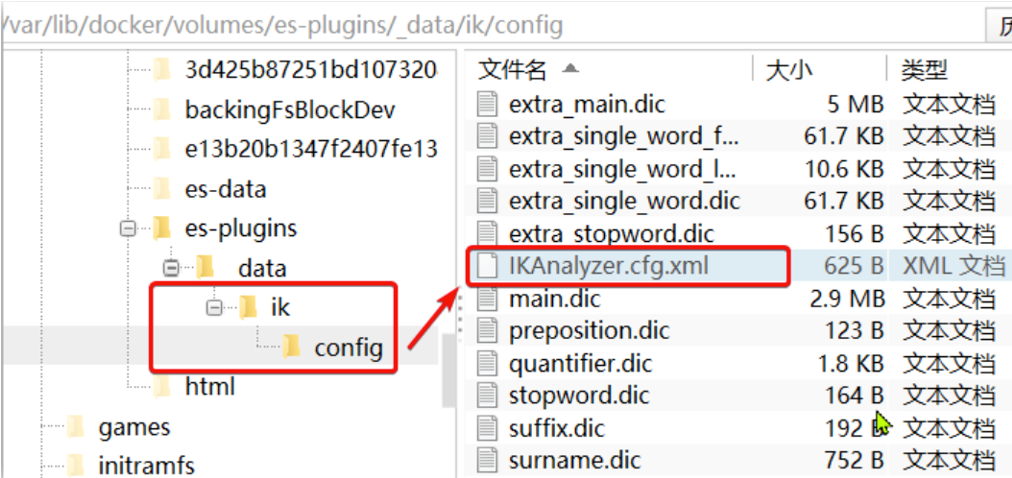
打开,修改前
修改,添加需要读取的文件
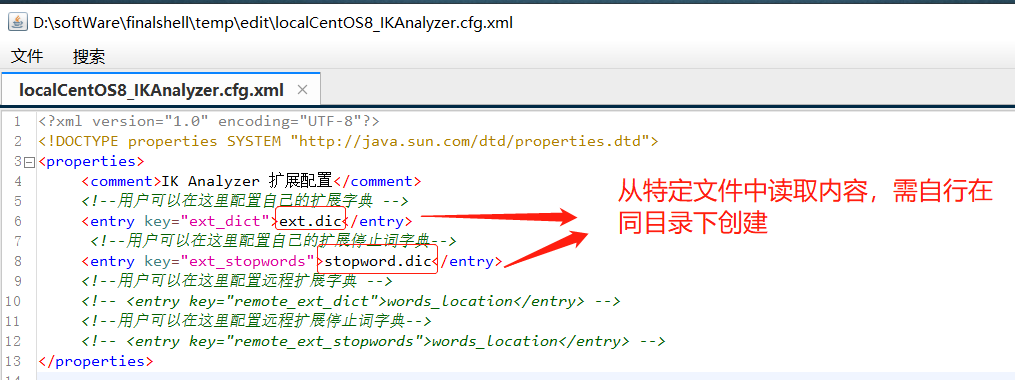
stopword.dic文件已存在,无需创建
注意,里面应该一个词一行
注意修改好后需要重启elasticsearch
docker restart es
# 查看 日志
docker logs -f es

日志中已经成功加载ext.dic配置文件
希望本文章对您有帮助,您的转发、点赞是我的创作动力,十分感谢。更多好文推荐,请关注我的微信公众号--JustJavaIt

 浙公网安备 33010602011771号
浙公网安备 33010602011771号