集群批量管理-Ansible-剧本与变量
复盘:https://www.processon.com/view/link/61addd266376896056c1b1b2
1.剧本
- 剧本:
- playbook 文件,用于长久保存并且实现批量管理,维护,部署的文件. 类似于脚本存放命令和变量,剧本中存放的时候?模块
- 剧本yaml格式,yaml格式的文件:空格,冒号.
- 剧本未来我们批量管理,运维必会的内容.

- 剧本书写格式
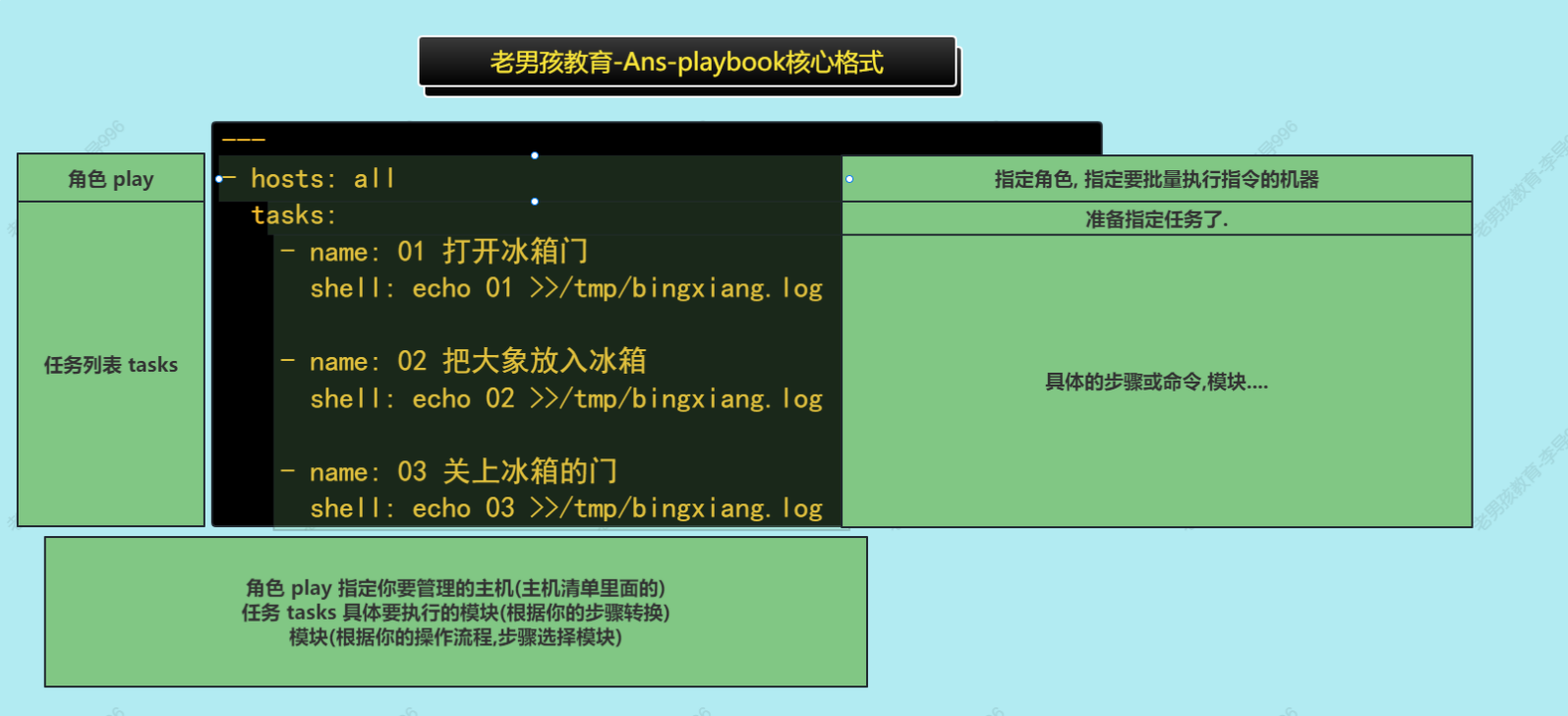
#1. 书写剧本 注意以.yml或.yaml结尾
#2. 执行剧本
ansible-playbook -i hosts 01.show.yml
[root@hadoop1 /server/srcipts/playbook]# cat 01.show.yml
---
- hosts: all
tasks:
- name: 01 打开冰箱门
shell: echo 01 >>/tmp/bingxiang.log
- name: 02 把大象放入冰箱
shell: echo 02 >>/tmp/bingxiang.log
- name: 03 关上冰箱的门
shell: echo 03 >>/tmp/bingxiang.log
执行的时候有奶牛:🐮
可以删除软件或修改ansible.cfg配置进行关闭 #nocows = 1去掉注释即可
- 书写Ans playbook注意事项:
- 同一个层级的内容对齐的.
- 不同层级的通过2个空格对齐
- 不能使用tab键
2.剧本案例
2.1.案例01: 创建目录并分发文件
1. 创建目录/server/files/
2. /etc/hosts文件发送过去/server/files/
- 中间转换步骤: 任务的步骤----->模块(命令行)
1. 创建目录/server/files/
-m file -a 'path=/server/files/ state=directory'
2. 分发
-m copy -a 'src=/etc/hosts dest=/server/files/ '
- 书写剧本
[root@hadoop1 /server/srcipts/playbook]# cat 02.fenfa.yml
- hosts: all
tasks:
- name: 01 创建目录
file: path=/server/files/ state=directory # 修正 ptah → path,stae → state
- name: 02 分发文件
copy: src=/etc/hosts dst=/server/files/ # 修正 scr → src
#-----------------------------------------------------------专业格式的剧本
[root@hadoop1 /server/srcipts/playbook]# cat 02.fenfa.yml
- hosts: all
tasks:
- name: 01.创建目录
file:
path: /server/files/
state: directory
- name: 02.分发文件
copy:
src: /etc/hosts
dest: /server/files/
2.2.案例02: 分发软件包,安装软件包,启动服务
-
步骤:
- zabbix-agent软件包(下载)
- 安装软件包
- 配置(略)
- 启动开机自启动
-
第1个里程碑-找出每个步骤的命令
# 下载软件包
wget --no-check-certificate https://repo.zabbix.com/zabbix/6.0/rhel/7/x86_64/zabbix-agent-6.0.7-1.el7.x86_64.rpm
# 安装软件包
yum install -y zabbix-agent-6.0.7-1.el7.x86_64.rpm
# 启动
systemctl
- 书写剧本
[root@m01 /server/scripts/playbook]# cat 03.install-zabbix-agent.yml
- hosts: all
tasks:
- name: 01. 下载软件包到/tmp/
get_url:
url: "https://mirrors.tuna.tsinghua.edu.cn/zabbix/zabbix/6.0/rhel/7/x86_64/zabbix-agent-6.0.7-1.el7.x86_64.rpm"
validate_certs: no
dest: /tmp/
- name: 02. 安装软件包
yum:
name: /tmp/zabbix-agent-6.0.7-1.el7.x86_64.rpm
state: present
- name: 03. 配置
debug:
msg: "进行配置zabbix - agent"
- name: 04. 启动
systemd:
name: zabbix - agent
enabled: yes
state: started
2.3.案例03: nfs服务
-
nfs服务端:在backup上部署nfs服务,共享/backup-nfs目录,all_squash,匿名用户:nfsnobody
-
nfs客户端:web挂载 /ans-upload目录挂载nfs服务端共享的/backup-nfs(永久挂载)
-
第1个里程碑-列出流程
- 服务端流程:
- 部署nfs-utils,rpcbind
- 修改配置文件
- 创建共享目录并改所有者
- 启动服务rpcbind,nfs(注意顺序)
- 客户端流程:
- 安装nfs-utils
- 挂载与永久挂载
- 服务端流程:
-
第2个里程碑-根据步骤流程模块
-
第3个里程碑-书写剧本
服务端流程:
1. 部署nfs-utils
2. 修改配置文件 /etc/exports
/backup-nfs 172.16.1.0/24(rw,all_squash)
3. 创建共享目录,改所有者
4. 启动服务rpcbind,nfs
客户端:
1. 安装nfs-utils
2. 挂载与永久挂载
[root@m01 /server/scripts/playbook]# cat 04.deploynfs.yml
# nfs服务端部署
- name: nfs服务端部署
hosts: backup
tasks:
- name: 01. 部署nfs-utils,rpcbind
yum:
name: nfs-utils,rpcbind
state: present
- name: 02. 修改配置文件
lineinfile:
path: /etc/exports
line: "/backup-nfs 172.16.1.0/24(rw,all_squash)"
create: true
- name: 03. 创建共享目录并改所有者
file:
path: /backup-nfs
owner: nfsnobody
group: nfsnobody
state: directory
- name: 04-1. 启动服务rpcbind,nfs(注意顺序)
systemd:
name: rpcbind
enabled: yes
state: started
- name: 04-2. 启动服务rpcbind,nfs(注意顺序)
systemd:
name: nfs
enabled: yes
state: started
# nfs客户端部署
- name: nfs客户端部署
hosts: web
tasks:
- name: 01. 部署nfs-utils
yum:
name: nfs-utils
state: present
- name: 02. 挂载nfs
mount:
src: 172.16.1.41:/backup-nfs
path: /ans-upload
fstype: nfs
state: mounted
- 理清服务作用,服务使用流程.
- 书写剧本核心: 列出步骤根据步骤找出模块
- 书写剧本.
- 书写剧本前拍摄快照,边书写剧本边测试,最后测试完成,恢复快照,重新跑一次.(分步测试,联合测试)
3. Ansible中的变量

3.1. 剧本中使用变量⭐⭐⭐⭐⭐
批量创建/oldboy/lidao/upload/
vars : variable 变量的内容,变量.
dir就是变量,变量的内容:右边的内容.
cat 05.vars.yml
- hosts: all
vars:
dir: /oldboy/lidao/upload/
tasks:
- name: mkdir
file:
path: "{{ dir }}"
state: directory
⚠ 温馨提示:
使用变量的时候如果变量是某个选项的开头,则变量引用的时候需要加上双引号.
1 dir: /oldboy/lidao/upload/ 2 3 file: 4 path: "{{ dir }}" #这种要添加,变量是开头. 5 file: 6 path: /oldboy-new/{{ dir }} #这种可以不加引号,变量不是开头.
在剧本play中定义变量应用:
- 仅仅在当前play生效.
- 一般用来存放路径,用户名,ip地址,类似于之前使用的脚本.
- 注意引号使用.
3.2.共用变量-变量文件
# cat 05.vars.yml content
- hosts: all
vars_files: ./vars.yml
tasks:
- name: file
file:
path: "{{ dir }}/{{ user }}-{{ file }}"
state: touch
# cat vars.yml content
dir: /tmp/
file: lidao.txt
user: lidao996kkk
3.3. 共用变量-根据主机组使用变量 ⭐⭐⭐⭐⭐
- group_vars根据主机清单的分组去匹配.
- 变量文件.
- 主机组创建变量文件.
group_vars
xxxx-check.yml
group_vars/
lb/vars.yml #存放lb组的变量
web/vars.yml #存放web组的变量
data/vars.yml #存放xxx组的变量
all/vars.yml #所有主机共用的变量
未来一般使用all分组即可,把所有变量存放在一起,供剧本使用.
- 创建属于oldboy用户的文件
[root@m01 /server/scripts/playbook]# cat group_vasrs/all/vars.yml
user: www
nfs_dir: /nfs_backup
web_mount_dir: /web_nfs
nfs_server: 172.16.1.41
rsync_pass: 1
[root@m01 /server/scripts/playbook]# cat 07.group_vars.yml
- hosts: all
tasks:
- name: 测试group变量
debug:
msg: "变量内容 {{user}} {{rsync_pass}}"
- hosts: web
tasks:
- name: 测试web组是否识别group变量
debug:
msg: "web组识别的变量变量内容 {{user}} {{rsync_pass}}"
⚠ 温馨提示: group_vars应用提示
一般使用group_vars中的all分组即可
3.4.register变量注册变量 ⭐⭐
-
本质上就是用来实现脚本中的 反引号功能 . ip=
hostname -I -
用户通过命令获取的内容都存放到Register变量中.
-
某个Register变量的信息
{
'stderr_lines': [],
u'changed': True,
u'end': u'2022-08-24 16:38:27.887829',
'failed': False,
u'stdout': u'2022-08-24',
u'cmd': u'date +%F',
u'rc': 0,
u'start': u'2022-08-24 16:38:27.860574',
u'stderr': u'',
u'delta': u'0:00:00.027255',
'stdout_lines': [u'2022-08-24'],
'ansible_facts': {u'discovered_interpreter_python': u'/usr/bin/python'}
}
[root@m01 /server/scripts/playbook]# cat 08.regvars.yml
- hosts: all
tasks:
- name: get date
shell: date +%F
register: result
- name: print result 变量内容
debug:
msg: |
"register变量的全部内容是:{{ result.stderr }}"
"register变量的精确的内容是:{{ result.stdout }}"
register注册变量:
变量.stdout 获取输出即可.
json形式数据. key: value 键: 值 变量: 内容 date +%F stdout部分是我们想要的内容. register变量result. result.stdout #std standard output 标准输出符号说明 :
msg:中的 | 表示下面的内容是多行. | 也可以用于其他模块中
-
剧本:课堂案例
-
变量
- 书写nfs部署剧本:服务端,客户端
- 书写rsync部署剧本:服务端,客户端(定时任务 + 脚本)
- 书写sersy
-
尽量使用变量

 浙公网安备 33010602011771号
浙公网安备 33010602011771号