

LR多分类推广 - Softmax回归*
LR是一个传统的二分类模型,它也可以用于多分类任务,其基本思想是:将多分类任务拆分成若干个二分类任务,然后对每个二分类任务训练一个模型,最后将多个模型的结果进行集成以获得最终的分类结果。一般来说,可以采取的拆分策略有:
one vs one策略
假设我们有N个类别,该策略基本思想就是不同类别两两之间训练一个分类器,这时我们一共会训练出![]() 种不同的分类器。在预测时,我们将样本提交给所有的分类器,一共会获得N(N-1)个结果,最终结果通过投票产生。
种不同的分类器。在预测时,我们将样本提交给所有的分类器,一共会获得N(N-1)个结果,最终结果通过投票产生。
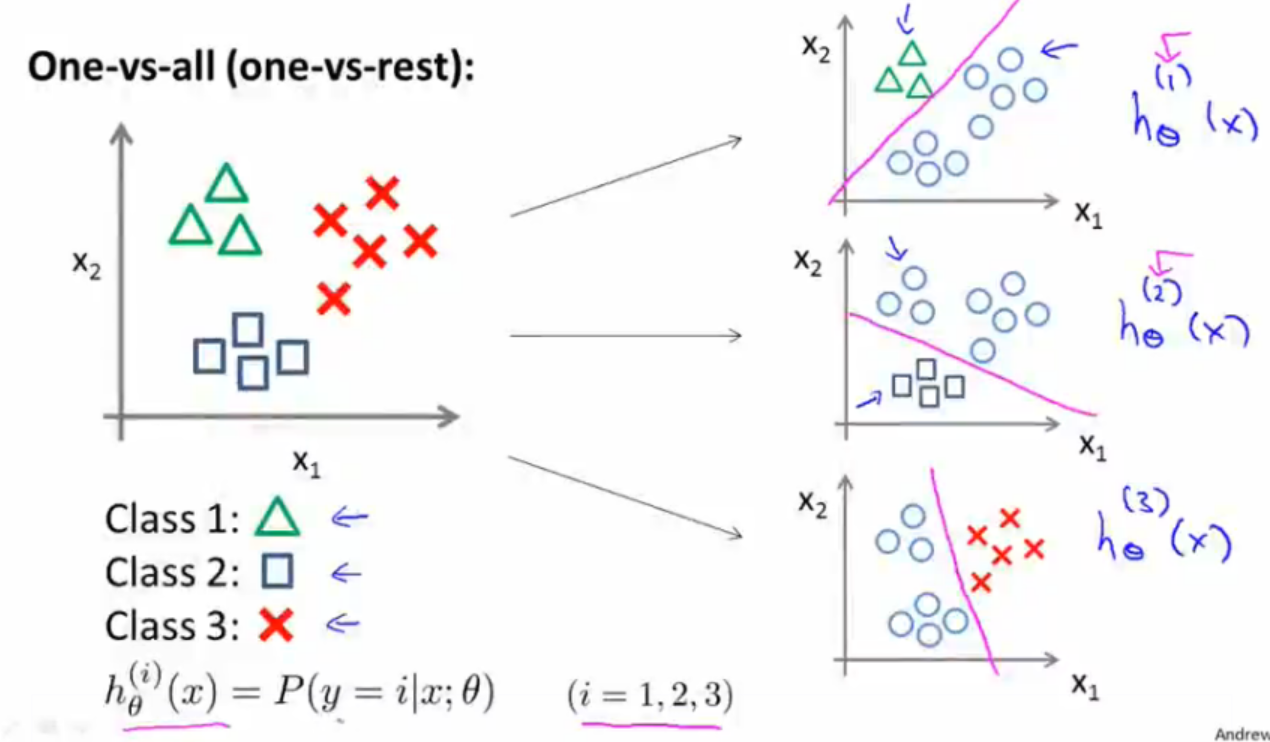
one vs all策略
该策略基本思想就是将第i种类型的所有样本作为正例,将剩下的所有样本作为负例,进行训练得到一个分类器。这样我们就一共可以得到N个分类器。在预测时,我们将样本提交给所有的分类器,一共会获得N个结果,我们选择其中概率值最大的那个作为最终分类结果。
softmax回归
softmax是LR在多分类的推广。与LR一样,同属于广义线性模型。什么是Softmax函数?假设我们有一个数组A,![]() 表示的是数组A中的第i个元素,那么这个元素的Softmax值就是
表示的是数组A中的第i个元素,那么这个元素的Softmax值就是
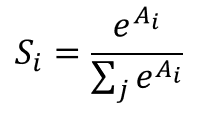
也就是说,是该元素的指数,与所有元素指数和的比值。那么 softmax回归模型的假设函数又是怎么样的呢?
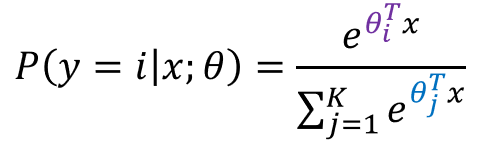
由上式很明显可以得出,假设函数的分母其实就是对概率分布进行了归一化,使得所有类别的概率之和为1;也可以看出LR其实就是K=2时的Softmax。在参数获得上,我们可以采用one vs all策略获得K个不同的训练数据集进行训练,进而针对每一类别都会得到一组参数向量![]() 。当测试样本特征向量
。当测试样本特征向量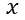 输入时,我们先用假设函数针对每一个类别
输入时,我们先用假设函数针对每一个类别![]() 估算出概率值
估算出概率值![]() 。因此我们的假设函数将要输出一个K维的向量(向量元素和为1)来表示K个类别的估计概率,我们选择其中得分最大的类别作为该输入的预测类别。Softmax看起来和one vs all 的LR很像,它们最大的不同在与Softmax得到的K个类别的得分和为1,而one vs all的LR并不是。
。因此我们的假设函数将要输出一个K维的向量(向量元素和为1)来表示K个类别的估计概率,我们选择其中得分最大的类别作为该输入的预测类别。Softmax看起来和one vs all 的LR很像,它们最大的不同在与Softmax得到的K个类别的得分和为1,而one vs all的LR并不是。
softmax的代价函数
类似于LR,其似然函数我们采用对数似然,故:
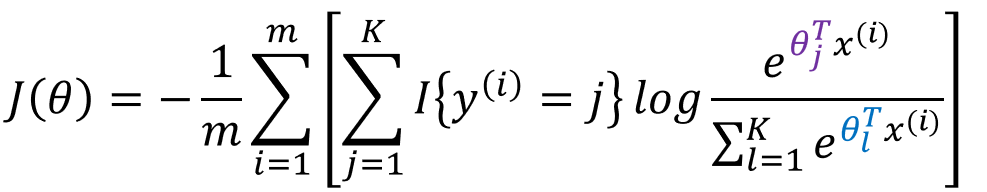
加入![]() 正则项的损失函数为:
正则项的损失函数为:
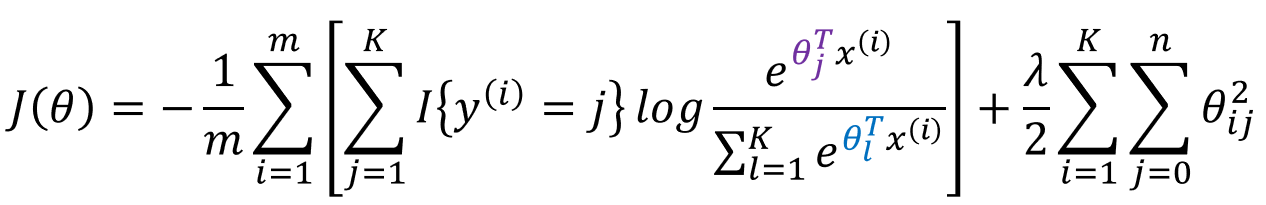
此处的![]() 为符号函数。对于其参数的求解过程,我们依然采用梯度下降法。
为符号函数。对于其参数的求解过程,我们依然采用梯度下降法。
softmax的梯度的求解
正则化项的求导很简单,就等于![]() ,下面我们主要讨论没有加正则项的损失函数的梯度求解,即
,下面我们主要讨论没有加正则项的损失函数的梯度求解,即
的导数(梯度)。为了使得求解过程看起来简便、易于理解,我们仅仅只对于一个样本(x,y)情况(SGD)进行讨论,
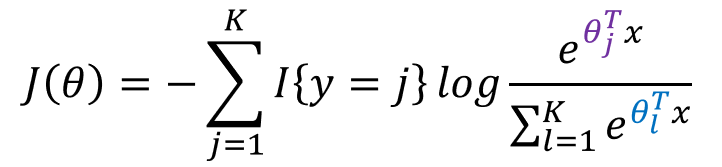
此时,我们令

可以得到
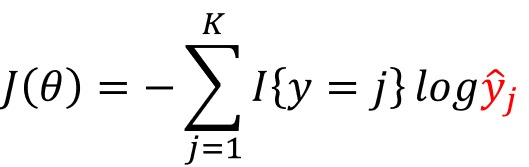
故:

所以,正则化之后的损失函数的梯度为
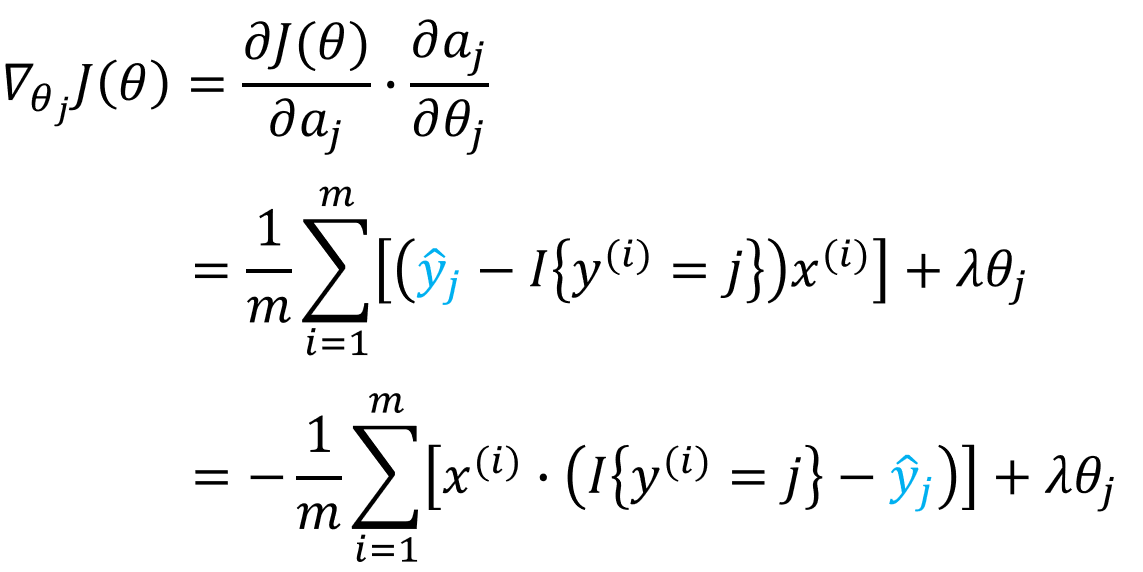
然后通过梯度下降法最小化  ,我们就能实现一个可用的 softmax 回归模型了。
,我们就能实现一个可用的 softmax 回归模型了。
多分类LR与Softmax回归
有了多分类的处理方法,那么我们什么时候该用多分类LR?什么时候要用softmax呢?
总的来说,若待分类的类别互斥,我们就使用Softmax方法;若待分类的类别有相交,我们则要选用多分类LR,然后投票表决。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号