

任务 :1爬取每本书的标题 地址:http://books.toscrape.com/index.html
2爬取每本书的价格 涉及模块:import scrapy
3排列好每本书对应的内容 涉及知识:response下css的爬取
使用scrapy startproject select1来创建项目
使用scrapy genspider books http://books.toscrape.com/index.html 来创建工作
第一次尝试:
先使用css抓取到标题和价格:代码如下:name = response.css('article.product_pod a::attr(title)').extract()
price = response.css('article.product_pod div p.price_color ::text').extract()
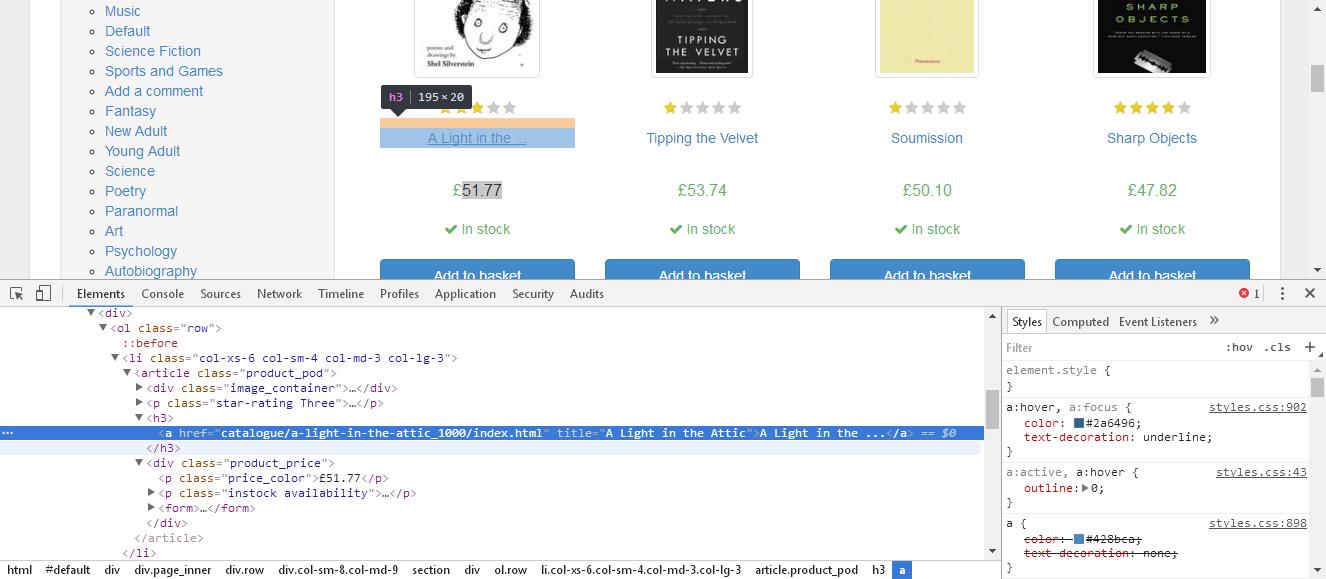
简单的就提取到了相关信息。于是提交yield {'name': name, 'price': price}
之后发现执行scrapy crawl books -o books.csv 之后没有保存到任何信息
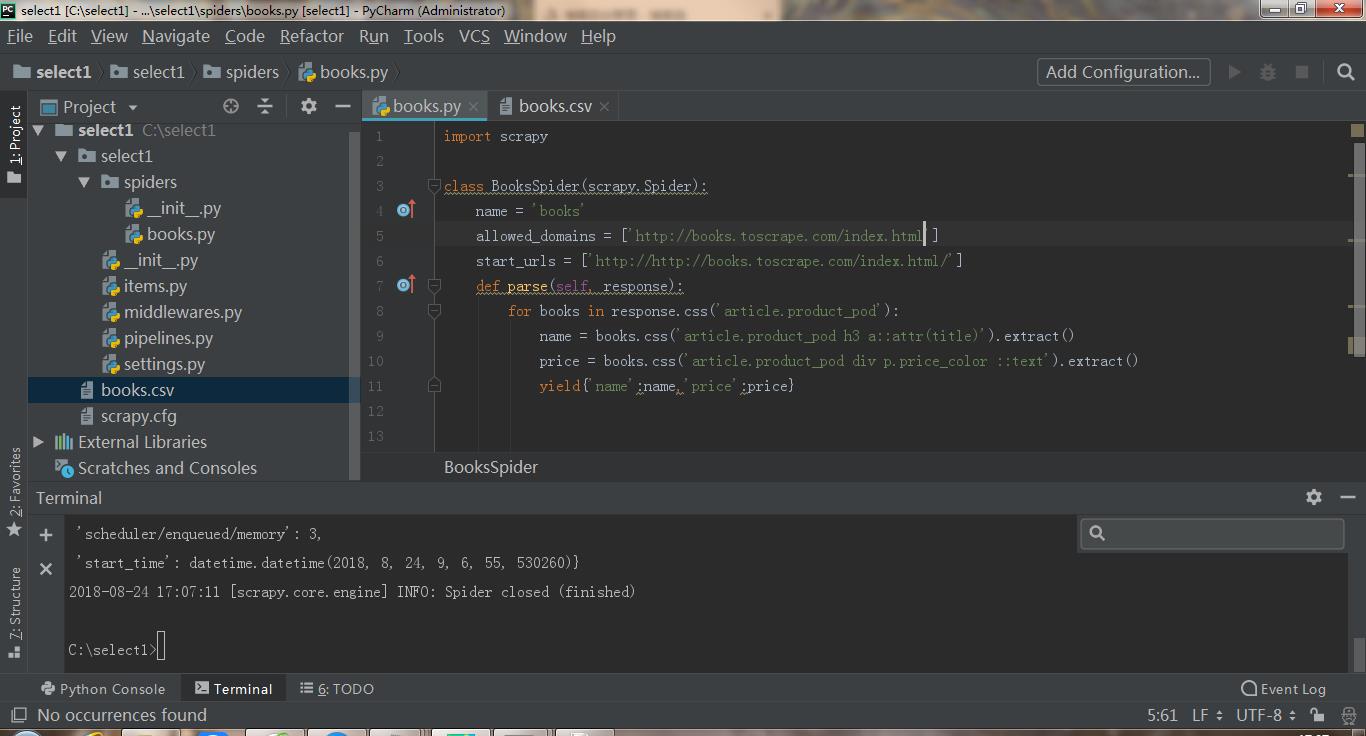
于是问题来了,为什么不行呢,我代码是非常正确的。
第二次尝试:
我仔细看了好久代码,发现只要把allowd删掉,再把start_url的前一个http删掉,继续执行scrapy crawl books -o books.csv 就可以把数据写入csv文件
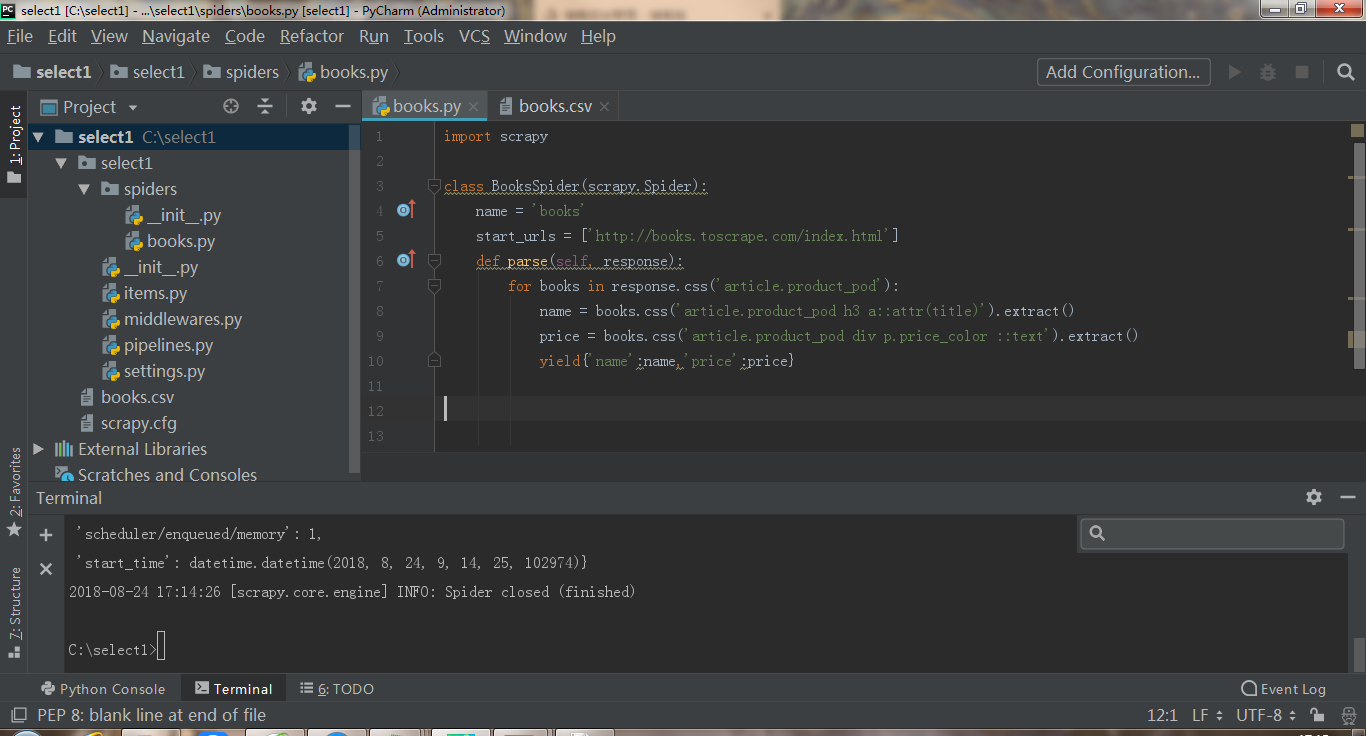
那么问题来了,是allowed的错还是start的错呢?
第三次尝试:
我多创建了一个book文件,除了allowed和start外,所有代码一样,我在原有的成功代码上加了一行代码 allowed_domains = ['http://books.toscrape.com/index.html']
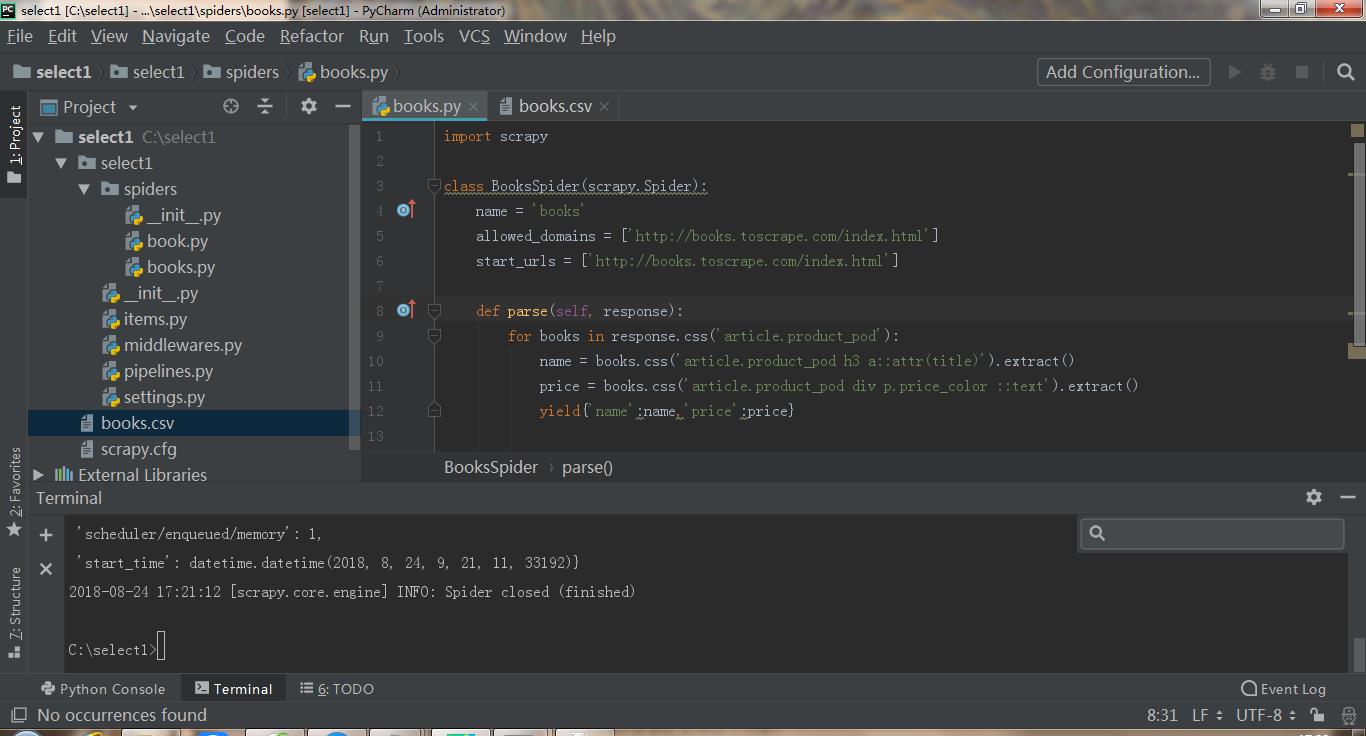
把原books文件删除后,执行scrapy crawl books -o books.csv之后一样成功!
于是我发现了问题就在于 这行代码的第一个http上,不知道为什么会创建这么多余的http。
这行代码的第一个http上,不知道为什么会创建这么多余的http。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号