
Mysql-自用技巧
Mysql查询某个字段(有时候想找某个字段在哪里,但是不知道表名等信息)
SELECT TABLE_SCHEMA, TABLE_NAME FROM information_schema.`COLUMNS` WHERE COLUMN_NAME = '要找的表名'
理解Left Join, Inner Join
Table A aid adate 1 a1 2 a2 3 a3 TableB bid bdate 1 b1 2 b2 4 b4
两个表a,b相连接,要取出id相同的字段
select * from a inner join b on a.aid = b.bid这是仅取出匹配的数据.
此时的取出的是:
1 a1 b1
2 a2 b2
那么left join 指:
select * from a left join b on a.aid = b.bid
首先取出a表中所有数据,然后再加上与a,b匹配的的数据
此时的取出的是:
1 a1 b1
2 a2 b2
3 a3 空字符
同样的也有right join
指的是首先取出b表中所有数据,然后再加上与a,b匹配的的数据
此时的取出的是:
1 a1 b1
2 a2 b2
4 空字符 b4

count(*),count(1)与count(column)区别
count(*)返回组中的项数。包括 NULL 值和重复项。
count(1)指的并不是计算1的个数,而是指表的第一个字段,如果第一个字段没有建立索引,他的效率是很低的
count(column name)默认查询的是指定字段非空的个数,如果你想查询数据的所有行数,恰巧指定字段又是一个可存在空库数据的字段,那么得到的数据就不会是期望的值。
如果表没有主键,那么count(1)比count(*)快。
如果有主键,那么count(主键,联合主键)比count(*)快。
如果表只有一个字段,count(*)最快。
英文资料中:“ On MyISAM, doing a query that does SELECT COUNT(*) FROM {some_table}, is very fast, since MyISAM keeps the information in the index”
也就是说MyISAM中,表的总数缓存在索引中。而现在的Mysql引擎一般为InnoDB,执行count(*)就要全表查询,所以不推荐用count(*)。
查找mysql总数
SELECT COUNT(*) AS recordCount FROM ( " +你需要找的sql语句+") A
查找重复
SELECT name,age,sex FROM table1 UNION SELECT name,age,sex FROM table2
查找非重复
SELECT * FROM table1 as A, table2 as B WHERE A.createTime = B.createTime AND A.name= B.name AND A.sex = B.sex 条件若干~
查找表中某个字段是否有重复的快速方法
SELECT 字段名 from 表名 GROUP BY 字段名 出现的条数和统计的不一致就是有重复的,否则应该一样
查询日期(在数据库转换好)
DATE_FORMAT(now(),'%Y-%m-%d')

DATE_FORMAT(NOW(),'%b %d %Y %h:%i %p')
DATE_FORMAT(NOW(),'%m-%d-%Y')
DATE_FORMAT(NOW(),'%d %b %y')
DATE_FORMAT(NOW(),'%d %b %Y %T:%f')
结果类似:
Dec 29 2008 11:45 PM
12-29-2008
29 Dec 08
29 Dec 2008 16:25:46.635
Mysql连接创建时配置
| 参数名称 | 参数说明 | 缺省值 | 最低版本要求 |
| user | 数据库用户名(用于连接数据库) | 所有版本 | |
| password | 用户密码(用于连接数据库) | 所有版本 | |
| useUnicode | 是否使用Unicode字符集,如果参数characterEncoding设置为gb2312或gbk,本参数值必须设置为true | false | 1.1g |
| characterEncoding | 当useUnicode设置为true时,指定字符编码。比如可设置为gb2312或gbk | false | 1.1g |
| autoReconnect | 当数据库连接异常中断时,是否自动重新连接? | false | 1.1 |
| autoReconnectForPools | 是否使用针对数据库连接池的重连策略 | false | 3.1.3 |
| failOverReadOnly | 自动重连成功后,连接是否设置为只读? | true | 3.0.12 |
| maxReconnects | autoReconnect设置为true时,重试连接的次数 | 3 | 1.1 |
| initialTimeout | autoReconnect设置为true时,两次重连之间的时间间隔,单位:秒 | 2 | 1.1 |
| connectTimeout | 和数据库服务器建立socket连接时的超时,单位:毫秒。 0表示永不超时,适用于JDK 1.4及更高版本 | 0 | 3.0.1 |
| socketTimeout | socket操作(读写)超时,单位:毫秒。 0表示永不超时 | 0 | 3.0.1 |
通常mysql连接URL可以设置为:
jdbc:mysql://localhost:3306/test?characterEncoding=UTF-8&autoReconnect=true&failOverReadOnly=false
用户名和密码一般是配置在XML中
在使用数据库连接池的情况下,最好设置如下两个参数:
autoReconnect=true&failOverReadOnly=false
需要注意的是,在xml配置文件中,url中的&符号需要转义成&。比如在tomcat的server.xml中配置数据库连接池时,mysql jdbc url样例如下:
jdbc:mysql://localhost:3306/test?user=root&password=&useUnicode=true&characterEncoding=gbk
&autoReconnect=true&failOverReadOnly=false
合并结果
date flag
2015-12-12 23:48:54 1
2015-12-12 23:51:02 2
2015-12-12 23:52:16 4
2015-12-13 00:18:24 6
2015-12-13 00:21:16 7
SELECT DATE_FORMAT(date,'%Y-%m-%d'),GROUP_CONCAT(flag ORDER BY flag DESC) from grouptest GROUP BY DATE_FORMAT(date,'%Y-%m-%d');
2015-12-12 4,2,1
2015-12-13 7,6
MySQL事务隔离级别
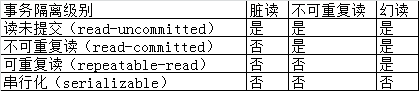
MySQL查询当天、昨天数据
SELECT * FROM 表名 WHERE DATEDIFF(字段,NOW())=0 -- 当天
SELECT * FROM 表名 WHERE DATEDIFF(字段,NOW())=-1 -- 昨天,如果now()在前面,则1为昨天
SELECT * FROM 表名 WHERE DATEDIFF(字段,NOW())<=0 AND DATEDIFF(字段,NOW())>=n -- 包含当天
SELECT * FROM 表名 WHERE DATEDIFF(字段,NOW())<0 AND DATEDIFF(字段,NOW())>=n --不包含当天
DATEDIFF() 函数用于返回两个日期之间的天数。 语法:DATEDIFF(date1,date2) date1 和 date2
参数是合法的日期或日期/时间表达式。 注释:
1. 只有值的日期部分参与计算。
2. 当日期date1<date2时函数返回值为正数,date1=date2时函数返回值为0,date1>date2 时函数返回值为负数。
3. Mysql的DATEDIFF只有两个参数。SQL Server有三个参数
日期处理
where DATE(createTime) = DATE(?)
WHERE DATE_FORMAT(createTime, '%Y-%m-%d') = DATE_FORMAT(CURDATE(), '%Y-%m-%d')
单独处理某个记录
比如我需要获取日志记录,其中启动时间按照创建时间获取,而其他字段按修改时间获取
SELECT code, name, status, CASE WHEN name= 'start' THEN createTime ELSE IFNULL(lastModifiedDatetime,createTime) END AS time FROM 表名 WHERE 条件
MYSQL日志
show engine innodb status;
exists和not exists的用法
EXISTS或者NOT EXISTS是把主查询的字段传到后边的查询中作为条件,返回值是TRUE或者FALSE。EXISTS TRUE,那么就是查询条件成立,结果会显示出来。NOT EXISTS TRUE,则为FALSE,查询连接条件不成立。
例子:A表中有个字段不为空。然后匹配不存在于B表的记录
SELECT * FROM (SELECT * FROM tableA WHERE createDate IS NOT NULL) a WHERE NOT EXISTS(SELECT * FROM tableB b WHERE b.id= a.id)
mark一种not exists的left join的写法
SELECT * FROM tableA a LEFT JOIN (SELECT * FROM tableB) b on a.id = b.id WHERE b.id IS NULL
关联更新
SELECT * FROM A; SELECT * FROM B; -- A和B都有customerID,需要将B的name赋值给A UPDATE A a LEFT JOIN B b on a.customerID= b.customerID SET a.name= b.name -- 后面可以补充条件,例如名字为空的,才赋值 WHERE a.name is null;
表结构输出
做设计时经常需要将数据库的结构对应成word或者excel,如果一个个手动敲,会很浪费时间,可以通过一个查询将其展示出来:
SELECT COLUMN_NAME 字段名, COLUMN_COMMENT 注释, COLUMN_TYPE 类型, CASE WHEN IS_NULLABLE ='NO' THEN '是' else '否' END 必传, COLUMN_COMMENT FROM INFORMATION_SCHEMA.COLUMNS where --table_schema 为数据库名称,到时候只需要修改成你要导出表结构的数据库即可 table_schema ='DB_NAME' AND -- table_name表名,到时候换成你要导出的表的名称 -- 如果不写的话,默认会查询出所有表中的数据,这样可能就分不清到底哪些字段是哪张表中的了,所以还是建议写上要导出的名名称 table_name = 'TABLE_NAME'


 浙公网安备 33010602011771号
浙公网安备 33010602011771号