
第四周作业-卷积神经网络(part2)
现代卷积神经网络
AlexNet
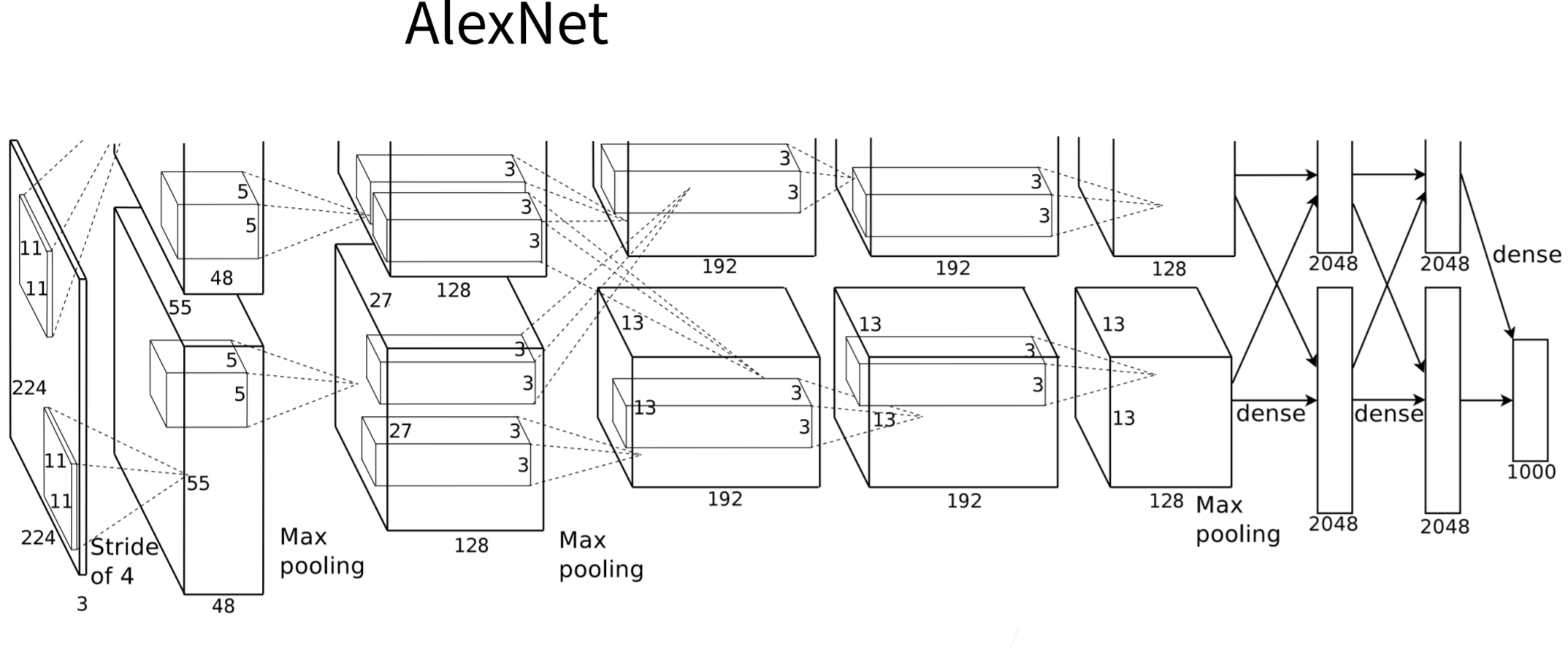
在AlexNet的第一层,卷积窗口的形状是 11×11。 由于ImageNet中大多数图像的宽和高比MNIST图像的多10倍以上,因此,需要一个更大的卷积窗口来捕获目标。 第二层中的卷积窗口形状被缩减为 5×5,然后是 3×3。 此外,在第一层、第二层和第五层卷积层之后,加入窗口形状为 3×3、步幅为2的最大汇聚层。 而且,AlexNet的卷积通道数目是LeNet的10倍。
AlexNet将sigmoid激活函数改为更简单的ReLU激活函数。 一方面,ReLU激活函数的计算更简单,它不需要如sigmoid激活函数那般复杂的求幂运算。 另一方面,当使用不同的参数初始化方法时,ReLU激活函数使训练模型更加容易。 当sigmoid激活函数的输出非常接近于0或1时,这些区域的梯度几乎为0,因此反向传播无法继续更新一些模型参数。 相反,ReLU激活函数在正区间的梯度总是1。 因此,如果模型参数没有正确初始化,sigmoid函数可能在正区间内得到几乎为0的梯度,从而使模型无法得到有效的训练。
VGG
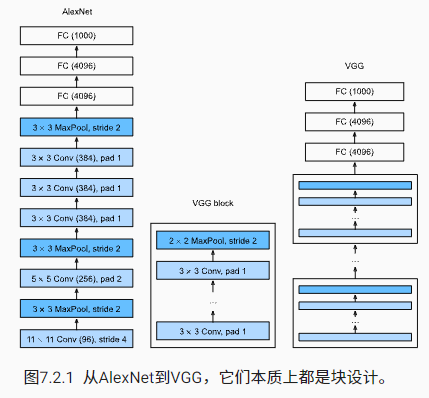
VGG-11 使用可复用的卷积块构造网络。不同的 VGG 模型可通过每个块中卷积层数量和输出通道数量的差异来定义。
块的使用导致网络定义的非常简洁。使用块可以有效地设计复杂的网络。
在VGG模型里,深层且窄的卷积(即3×33×3)比较浅层且宽的卷积更有效。
NiN
NiN 块以一个普通卷积层开始,后面是两个 1×1的卷积层。这两个1×1卷积层充当带有 ReLU 激活函数的逐像素全连接层。 第一层的卷积窗口形状通常由用户设置。 随后的卷积窗口形状固定为 1×1。
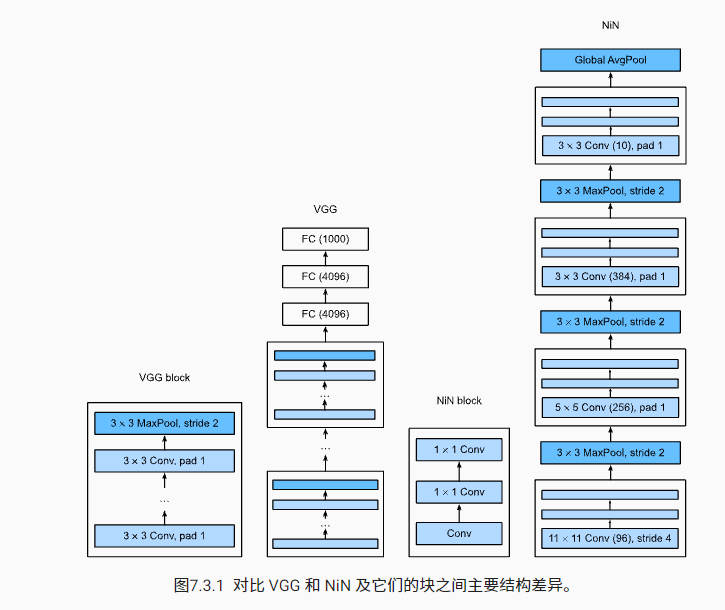
NiN使用由一个卷积层和多个 1×1卷积层组成的块。该块可以在卷积神经网络中使用,以允许更多的每像素非线性。
NiN去除了容易造成过拟合的全连接层,将它们替换为全局平均汇聚层(即在所有位置上进行求和)。该汇聚层通道数量为所需的输出数量(例如,Fashion-MNIST的输出为10)。
移除全连接层可减少过拟合,同时显著减少NiN的参数。
NiN的设计影响了许多后续卷积神经网络的设计。
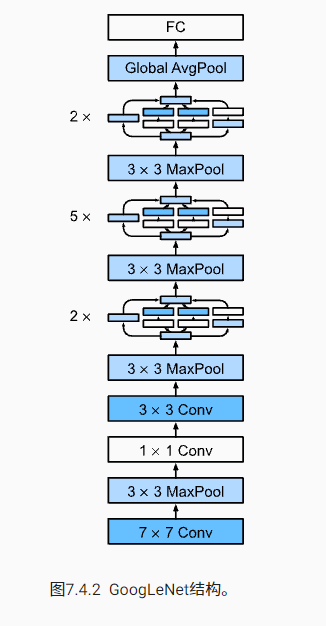
GoogLeNet
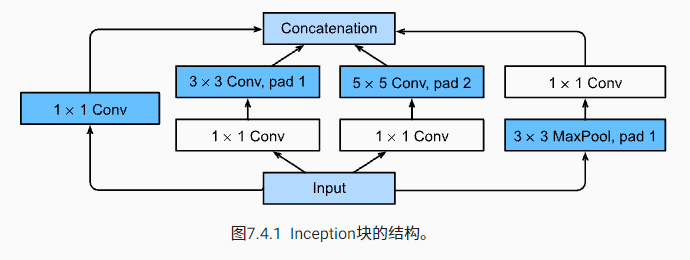
在GoogLeNet中,基本的卷积块被称为Inception块
Inception块由四条并行路径组成。 前三条路径使用窗口大小为 1×1、3×3和 5×5 的卷积层,从不同空间大小中提取信息。 中间的两条路径在输入上执行 1×1卷积,以减少通道数,从而降低模型的复杂性。 第四条路径使用 3×3 最大汇聚层,然后使用 1×1 卷积层来改变通道数。 这四条路径都使用合适的填充来使输入与输出的高和宽一致,最后我们将每条线路的输出在通道维度上连结,并构成Inception块的输出。在Inception块中,通常调整的超参数是每层输出通道的数量。
GoogLeNet 一共使用 9 个Inception块和全局平均汇聚层的堆叠来生成其估计值。Inception块之间的最大汇聚层可降低维度。 第一个模块类似于 AlexNet 和 LeNet,Inception块的栈从VGG继承,全局平均汇聚层避免了在最后使用全连接层。
批量归一化
可学习的参数是λ和β,对于全连接层是作用在特征维,对于卷积层是作用在通道维。
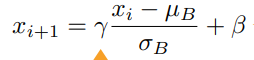
在模型训练过程中,批量归一化利用小批量的均值和标准差,不断调整神经网络的中间输出,使整个神经网络各层的中间输出值更加稳定。
批量归一化在全连接层和卷积层的使用略有不同。
批量归一化层和 dropout 层一样,在训练模式和预测模式下计算不同。
批量归一化有许多有益的副作用,主要是正则化。另一方面,”减少内部协变量偏移“的原始动机似乎不是一个有效的解释。
残差网络(ResNet)
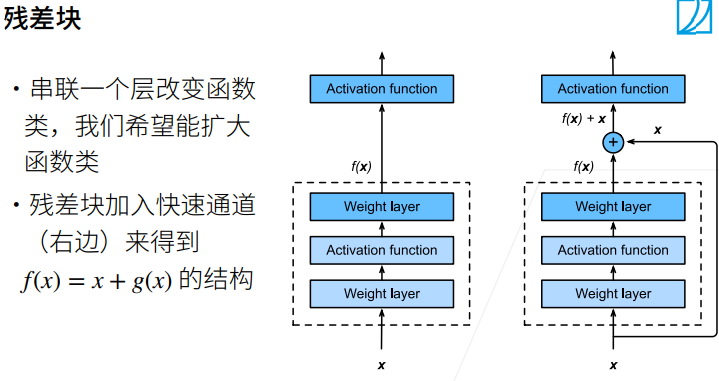
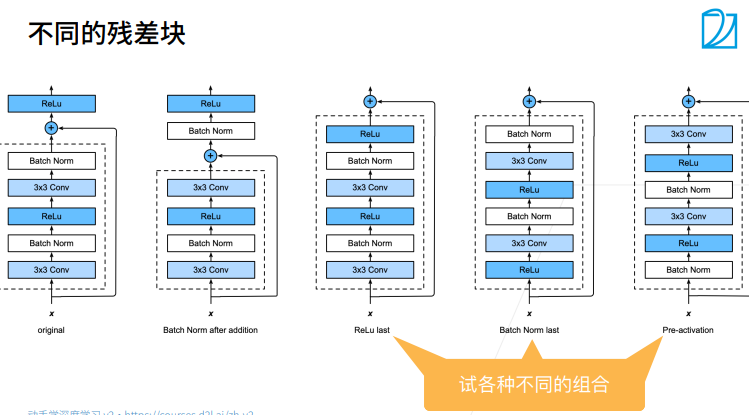
RestNet架构类似于VGG和GoogLeNet的总体架构,但替换成了RestNet块。
残差块使得很深的网络更加容易训练
残差网络对随后的深层神经网络设计产生了深远的影响。无论是卷积类神经网络还是全连接类神经网络。
猫狗大战
用的ResNet50并修改模型的全连接层
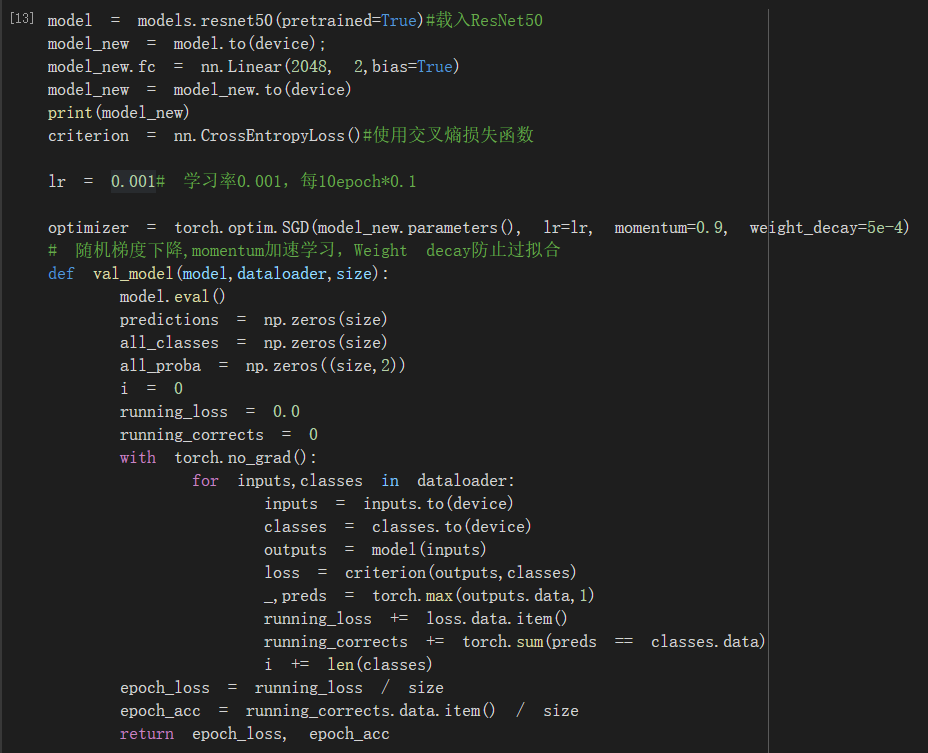
模型训练
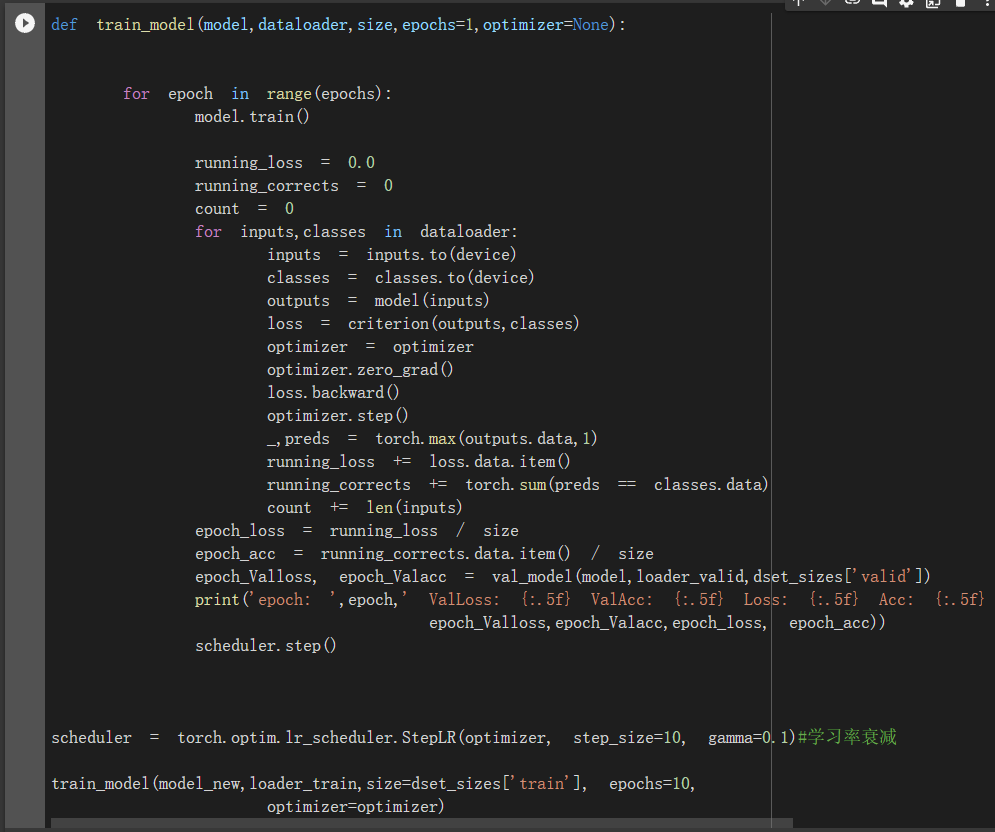
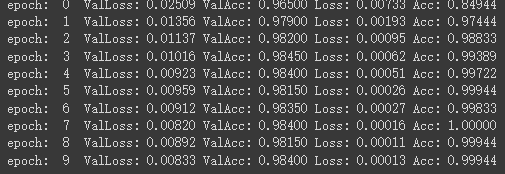
训练结果
总结
1.本周学习了很多经典的神经网络,但是很多东西只看一遍还是没什么印象,感觉还要多看多动手效果才会好一些
2.了解了迁移学习,完成了猫狗大战,但感觉还是有点困难,一点一点照葫芦画瓢完成的,对pytorch还是太不熟悉了,需要花更多时间来补课。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号