![]()
import json
import re
from itertools import chain
import requests
from requests import RequestException
def get_page_index(url):
try:
response=requests.get(url)
# print(response.text)
if response.status_code==200:
return response.text
return None
except RequestException:
print('请求页不存在')
return None
# with open('猫途鹰.html','w+')as f:
# f.write(response.text)
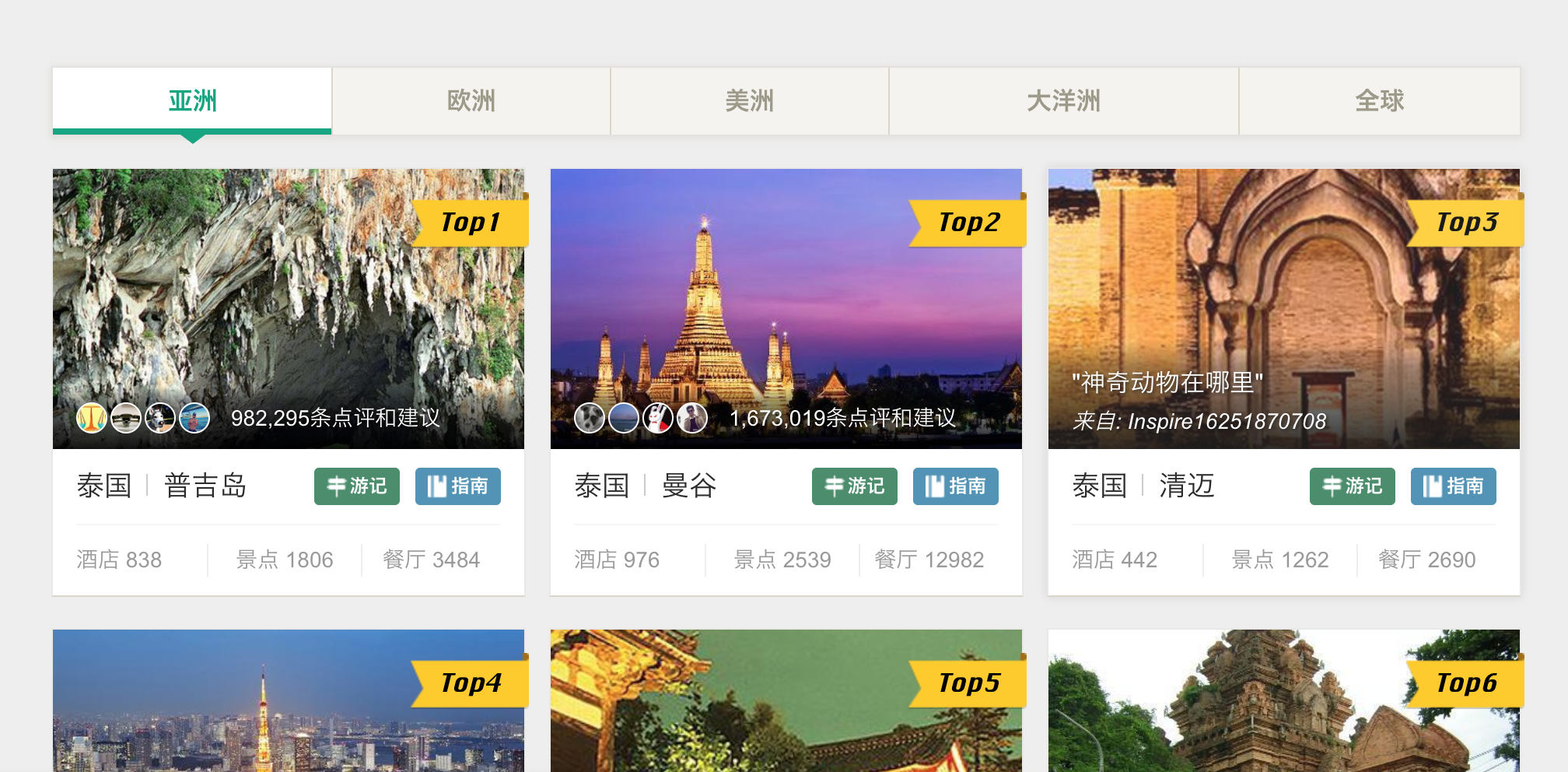
def parse_one_page(html):
# pattern=re.compile('<span\sclass="thumbCrop"><img\ssrc="(.*?)"')
pattern_img=re.compile('<span.*?"thumbCrop".*?src="(.*?)"',re.S)
imgs=re.findall(pattern_img,html)
pattern_url = re.compile('<a.*?countryName.*?>(.*?)</a>.*?cityName.*?>(.*?)'
'</a>.*?stb blockIcon">(.*?)</span.*?cityGuide blockIcon">(.*?)'
'</span>.*?hotelsCount.*?html">(.*?)</a>.*?attractionCount.*?html">(.*?)'
'</a>.*?eateryCount.*?html">(.*?)</a>', re.S)
a_url = re.findall(pattern_url, html)
items =list(chain.from_iterable(zip(imgs,a_url)))
items_list=[]
for i in items:
# print(i)
items_list.append(i)
return items_list
def write_to_file(content):
'''
写入文本
:param content:
:return:
'''
with open('猫途鹰.txt', 'a',encoding='utf-8')as f:#打开文件,如果没有就创建,encoding 指定编码方式
f.write(json.dumps(content,ensure_ascii=False)+'\n')#ensure_ascii=False以指定的方式编码
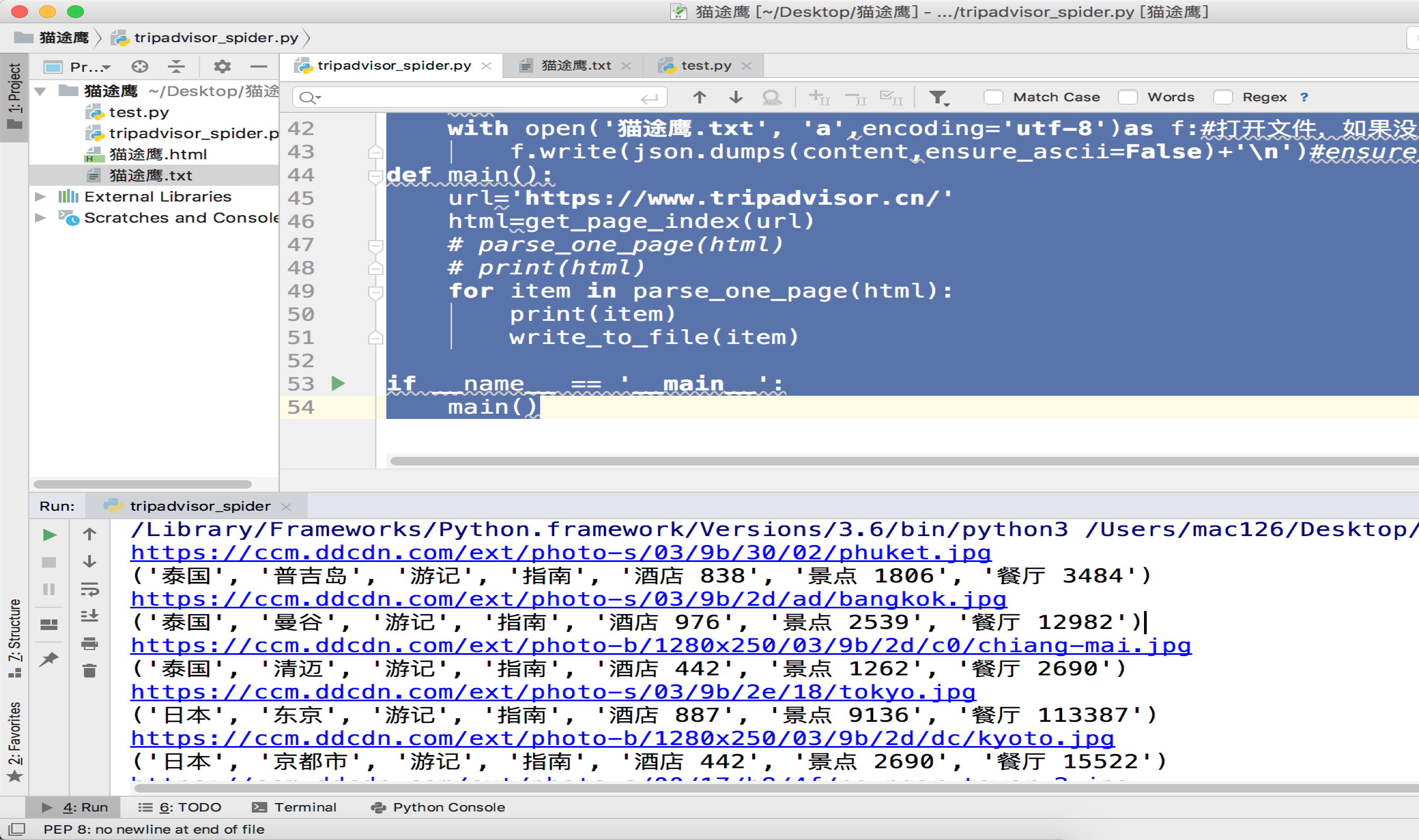
def main():
url='https://www.tripadvisor.cn/'
html=get_page_index(url)
# parse_one_page(html)
# print(html)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
main()
![]()




 浙公网安备 33010602011771号
浙公网安备 33010602011771号