

solr6.4.2之webservice兼容升级
摘要:这次solr底层升级是一次比较大的升级。从底层搜索引擎 solr4.8 升级到 solr6.4.2,由于solr底层从6.x开始以来的jdk必须指定为1.8,而且很多内部实现类都已经废弃或者干脆被砍掉了,这样就导致了很多实现类都需要进行兼容性的处理,第三方依赖的库也需要跟着进行升级改造。例如IK词库加载,就需要手动编译修改源代码,具体可以参考我的另外一篇博客:http://www.cnblogs.com/liang1101/articles/6395016.html 本篇主要是从应用实现、兼容修改以及项目发布遇到的问题和对应解决办法进行详细的讲解。
应用项目:公司内部自己搭建的一套对外提供webservice服务,提供相应的接口为各个项目组调用使用。该webservice服务底层使用spring容器管理、hibernate数据库连接管理的方式,结合 solr、lucene 相关依赖包所实现的系统。
起始背景:原始版本使用:eclipse4.3 + JDK1.7 + solr-solrj-4.8.0 + lucene-core-4.8.0 + spring-core2.5.6 等主要相关依赖包。当然还有相应的 lucene-queryparser、lucene-highlighter、lucene-memory、hibernate-core-4.3.0 以及 spring 很多相关包等等。
开始升级:
1. eclipse4.6.2,即下载的2017年1月最新eclipse版本,因为 eclipse4.6 开始才能支持 jdk1.8 的编译。具体下载地址可以到我的百度云盘上下载:http://pan.baidu.com/s/1hsJs2De
当然,目前很多人已经使用了IntelliJ IDEA,目前我们也使用了该编辑器,这里提供我使用的版本 idea-15.0.6 下载地址: http://pan.baidu.com/s/1o7Ceyeu
2. jdk1.8.0_112,因为solr和lucene升级到当前6.4.0最高版本其底层依赖必须指定为jdk1.8,故需下载2017年1月最新jdk1.8稳定版本,具体下载地址可以到我的百度云盘上下载:
服务器版本的jdk下载地址: http://pan.baidu.com/s/1boOCea7
windows之64位系统的jdk下载地址: http://pan.baidu.com/s/1jIJoz4a
3. 用solr-solrj-6.4.2、lucene-core-6.4.2、lucene-highlighter-6.4.2、lucene-memory-6.4.2、lucene-queryparser-6.4.2,如果调用到solr核心类,则还需要引入:solr-core-6.4.2 这些包替换原有的 4.8.0 的包
4. 修改底层用到的方法新旧不兼容的代码(注意:这里只是我用到的方法和类,一定会有我没有遇到的,但是方法是相同的,查看对应的api都可以很easy的解决掉)
1. org.apache.solr.client.solrj.impl.HttpSolrServer 修改为:org.apache.solr.client.solrj.impl.HttpSolrClient 2. SolrClient solrClient = new CloudSolrClient(zkHost); new方式在新版已经被废弃,采用新版链式赋值法进行创建对象 SolrClient solrClient = new CloudSolrClient.Builder().withZkHost(Arrays.asList(zkHost.split(","))).build(); 3. solrClient = new ConcurrentUpdateSolrClient(url, queueSize, threadCount); 采用链式赋值法 solrClient = new ConcurrentUpdateSolrClient.Builder(url).withQueueSize(queueSize).withThreadCount(threadCount).build(); 4. solrClient = new HttpSolrClient(baseURL); 采用链式赋值法 solrClient = new HttpSolrClient.Builder(baseURL).build(); 5. ClusterState clusterState = zkStateReader.getClusterState(); Map<String, Slice> map = clusterState.getActiveSlicesMap(collection); api已经将getActiveSlicesMap废弃 map = clusterState.getCollection(collection).getActiveSlicesMap(); 6. List<String> collections = zkStateReader.getAllCollections(); api已经将getAllCollections()废弃掉 Map<String, DocCollection> map = zkStateReader.getClusterState().getCollectionsMap(); 7. Collection<Slice> slices = clusterState.getSlices(Collection); api已经将getSlices(collection)废弃,采用更加方便、安全的中间类DocCollection DocCollection docCollection = clusterState.getCollection(collection); Collection<Slice> slices = docCollection.getActiveSlices(); 8. CollectionAdminRequest.Create req = new CollectionAdminRequest.Create(); req.setCollectionName(name); req.setNumShards(numShards); req.setConfigName(cluster); req.setCreateNodeSet(getNodeSet(cluster)); req.setReplicationFactor(numReplicas); 修改为链式赋值法 CollectionAdminRequest.Create req = CollectionAdminRequest.createCollection(name, cluster, numShards, numReplicas); 9. CollectionAdminRequest.Delete req = new CollectionAdminRequest.Delete(); api已将这种创建方式废弃 CollectionAdminRequest.Delete req = CollectionAdminRequest.deleteCollection(name); 10. CollectionAdminRequest.CreateAlias req = new CollectionAdminRequest.CreateAlias(); api已经将这种创建方式废弃 CollectionAdminRequest.CreateAlias req = CollectionAdminRequest.createAlias(name, collections); 11. CollectionAdminRequest.DeleteAlias req = new CollectionAdminRequest.deleteAlias(); api已经将这种创建方式废弃 CollectionAdminRequest.DeleteAlias req = CollectionAdminRequest.deleteAlias(name); 12. SolrInputDocument inputDocument = ClientUtils.toSolrInputDocument(solrDocument); 将SolrDocument 转换为 SolrInputDocument 的方法从ClientUtils中移除了.从solr-5.5之后就将此方法移除,代码中要想使用此类似功能,需要自己添加方法实现 /** * 将SolrDocument转换为SolrInputDocument,原底层提供的方法从solr5.5之后被废弃掉了 * add by liangyongxing * @param solrDocument * @createTime 2017-02-21 * @return */ public static SolrInputDocument toSolrInputDocument(SolrDocument solrDocument) { SolrInputDocument doc = new SolrInputDocument(); for (String name : solrDocument.getFieldNames()) { doc.addField(name, solrDocument.getFieldValue(name)); } return doc; }
<1. 以上步骤做完,都会认为万事大吉了,因为此时整个工程没有报任何错误了,包括自己在本地可能运行和测试也是OK的。那么,此时我们按照正常的逻辑打包发布到线上环境启动,会发现起不起来,报错内容可能大致如下:
Unsupported major.minor version 52.0
以上这个错误对于有点经验的程序员来说都是很easy的问题,就是服务器上的jdk和咱们打包程序所使用的jdk版本不一致,很明显,本地使用的是jdk1.8而服务器上的是jdk1.7,具体可以通过命令:java -version 进行查看jdk版本。那么就好办了,直接下载或者拷贝都可以,将当前环境的jdk升级为18的即可,这个是很easy的我就不在这里啰嗦了。
<2. 做好之后再进行重启服务,发现怎么还不好使,大概报错如下所示:
具体的错误我就不粘贴了,省得有些同学会对号入座。翻译后大致意思为:容器初始化的时候不能够初始化我们所需要的对象,其中的关键字为:org.springframework.init......
看到这个错误,很明显是spring加载的问题,自然而然想到我们引用的spring是否是版本的问题,我的第一反应可能就是jdk1.8和spring2.5.6不兼容了,之后通过google、stakoverflow等相关网站查看发现还真是这个问题,在jdk1.8之后的spring建议最好使用spring-core-3.x的包,建议先不要使用4.x的包,因为4.x的包还需要jdk1.8不同版本的要求(需要有针对性的要求),开始我偏不信,尝试了4.x的包,最后发现似乎还真是有问题(补充一下,当时可能和我操作顺序有关,后来3.x没有问题了我就没有再尝试一次,稳妥起见建议还是3.x),我引入的spring的包具体如下:
spring-aop-3.2.13-RELEASE.jar、spring-beans-3.2.13-RELEASE.jar、spring-context-3.2.13-RELEASE.jar、spring-context-support-3.2.13-RELEASE.jar、spring-core-3.2.13-RELEASE.jar、spring-jdbc-3.2.13-RELEASE.jar、spring-orm-3.2.13-RELEASE.jar、spring-tx-3.2.13-RELEASE.jar、spring-web-3.2.13-RELEASE.jar等
<3. 以上两小步做完之后,再在Linux中重启tomcat服务,我了个天啊,怎么还有问题,我都要快奔溃了,之后硬着头皮继续google,发现是服务器的tomcat版本太低导致的。oh my god!!!,一个jdk1.8的升级怎么会引入这么多问题呢?但是没有办法,继续解决吧,上面可能会抛出一下这样大致的错误:
unable to process jar entry [......] from Jar[......] for annotations.
先介绍一下如何在Linux中查看当前tomcat的版本,到对应tomcat的安装目录下,执行 sh ./bin/version.sh 命令,会打印出当前tomcat对应的版本是多少。而上面的这个错误的原因是因为服务器的tomcat版本低于 apache-tomcat-7.0.59,建议用户升级到 tomcat-7.0.61 以上(因为没有 tomcat-7.0.60 这个版本,当然 tomcat-7.0.59 开始就是好使的,如果你非要用 tomcat-7.0.59 也是可以的)。 最后升级为tomcat后重新启动服务,我的天啊,服务终于正常启动了。至此,这次搜索引擎底层webservice服务兼容升级完成
<4. 这里需要补充一点,当windows系统中spring包由2.5.6 —> 3.2.13版本后,对应的jdk版本由1.7升级到1.8后,对应ecllipse设置选项卡project Facets 右侧 Dynamic Web Module 级别默认会由原先的2.5自动升级到3.1了,如下图所示:
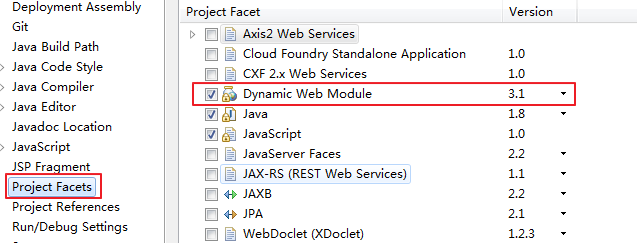
那么此时要求tomcat版本至少需要8.x,即需要从网上下载tomcat8.x版本方可在本地发布项目测试使用。或者使用我的百度云盘下载,下载tomcat-8.5.11地址为:http://pan.baidu.com/s/1pKBw23x
总结:此次升级,虽然过程有点艰辛,但总算是做到尽善尽美。希望此次的分享能够给有遇到相关问题的朋友们提供些许的帮助。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号