Guava之CaseFormat
com.google.common.base.CaseFormat是一种实用工具类,以提供不同的ASCII字符格式之间的转换。
其对应的枚举常量

从以上枚举中可以看出,java程序员最常用的转换类型为:UPPER_CAMEL,即我们常说的"驼峰式"编写方式;其次,我们常用的是:UPPER_UNDERSCORE,即我们常用的常量命名法,不同单词见使用下划线分割的书写方式。
对应有的方法
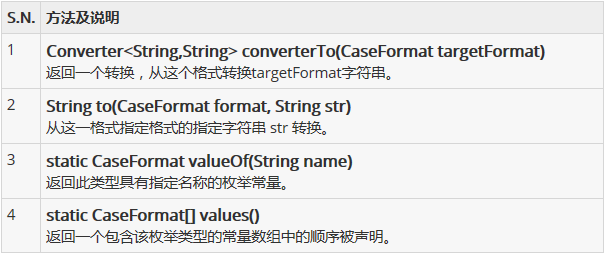
CaseFormat 示例
public static void main(String args[]) { CaseFormatTest tester = new CaseFormatTest(); tester.testCaseFormat(); } private void testCaseFormat() { System.out.println(CaseFormat.LOWER_HYPHEN.to(CaseFormat.LOWER_CAMEL, "test-data")); System.out.println(CaseFormat.LOWER_UNDERSCORE.to(CaseFormat.LOWER_CAMEL, "test_data")); System.out.println(CaseFormat.UPPER_UNDERSCORE.to(CaseFormat.UPPER_CAMEL, "test_data")); System.out.println(CaseFormat.LOWER_CAMEL.to(CaseFormat.LOWER_UNDERSCORE, "testdata")); System.out.println(CaseFormat.LOWER_CAMEL.to(CaseFormat.LOWER_UNDERSCORE, "TestData")); System.out.println(CaseFormat.LOWER_CAMEL.to(CaseFormat.LOWER_HYPHEN, "testData")); }
运行结果如下:
testData testData TestData
testdata
test_data
test-data
从以上结果我们可以分析,倒数第3个结果没有转换成功,将原字符串打印出来,推导出guava不可能做到那么智能,能够自动识别一个单词之后将两个单词用下划线分隔开(要想做也是可以的,需要将英文词库加载一遍,之后每次扫描给定的字符串进行单词分割,这样做就太复杂了),它只能通过给定字符串大小写的方式或者上面3个实例有分隔符的方式才能拆分开,故倒数第二个就能正确识别出来。所以在使用guava转换的时候一定要注意了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号