

OHC Java堆外缓存详解与应用
1、背景
在当前微服务体系架构中,有很多服务例如,在 特征组装 与 排序等场景都需要有大量的数据支撑,快速读取这些数据对提升整个服务于的性能起着至关重要的作用。
缓存在各大系统中应用非常广泛。尤其是业务程序所依赖的数据可能在各种类型的数据库上(mysql、hive 等),那么如果想要获取到这些数据需要通过网络来访问。再加上往往数据量又很庞大,网络传输的耗时,自然会增加系统的相应时间。为了降低相应时间,业务程序可以将从数据库中读取到的部分数据,缓存在本地服务器可以很方便快速的直接使用。
缓存框架OHC基于Java语言实现,并以类库的形式供其他Java程序调用,是一种以单机模式运行的堆外缓存。
2、OHC 简介
缓存的分类与实现机制多种多样,包括单机缓存与分布式缓存等等。具体到JVM应用,又可以分为堆内缓存和堆外缓存。
OHC 全称为 off-heap-cache,即堆外缓存,是一款基于Java 的 key-value 堆外缓存框架。
OHC是2015年针对 Apache Cassandra 开发的缓存框架,后来从 Cassandra 项目中独立出来,成为单独的类库,其项目地址为:https://github.com/snazy/ohc
2.1、堆内和堆外
Java程序运行时,由Java虚拟机(JVM)管理的内存区域称为堆(heap)。垃圾收集器会扫描堆内空间,识别应用程序已经不再使用的对象,并释放其空间,这个过程称为GC。
堆内缓存,顾名思义,是指将数据缓存在堆内的机制,比如 HashMap 就可以用作简单的堆内缓存。由于垃圾收集器需要扫描堆,并且在扫描时需要暂停应用线程(stop-the-world,STW),因此,缓存数据过多会导致GC开销增大,从而影响应用程序性能。
与堆内空间不同,堆外空间不影响GC,由应用程序自身负责分配与释放内存。因此,当缓存数据量较大(达到G以上级别)时,可以使用堆外缓存来提升性能。

2.2、OHC 的特性
相对于持久化数据库,可用的内存空间更少、速度也更快,因此通常将访问频繁的数据放入堆外内存进行缓存,并保证缓存的时效性。OHC主要具有以下特性来满足需求:
- 数据存储在堆外,不影响GC
- 支持为每个缓存项设置过期时间
- 支持配置LRU、W-TinyLFU逐出策略
- 能够维护大量的缓存条目(百万量级以上)
- 支持异步加载缓存
- 读写速度在微秒级别
OHC具有低延迟、容量大、不影响GC的特性,并且支持使用方根据自身业务需求进行灵活配置。
2.3、使用示例
在Java项目中使用OHC,主要包括以下步骤:
1. 在项目中引入OHC。如果使用Maven来管理依赖,可以将OHC的坐标添加到到项目的POM文件中。
<dependency>
<groupId>org.caffinitas.ohc</groupId>
<artifactId>ohc-core</artifactId>
<version>0.7.0</version>
</dependency>
2. OHC是将Java对象序列化后存储在堆外,因此用户需要实现 org.caffinitas.ohc.CacheSerializer 类,OHC会运用其实现类来序列化和反序列化对象。例如,以下例子是对 string 进行的序列化实现:


public class StringSerializer implements CacheSerializer<String> { /** * 计算字符串序列化后占用的空间 * * @param value 需要序列化存储的字符串 * @return 序列化后的字节数 */ @Override public int serializedSize(String value) { byte[] bytes = value.getBytes(Charsets.UTF_8); // 设置字符串长度限制,2^16 = 65536 if (bytes.length > 65536) throw new RuntimeException("encoded string too long: " + bytes.length + " bytes"); // 设置字符串长度限制,2^16 = 65536 return bytes.length + 2; } /** * 将字符串对象序列化到 ByteBuffer 中,ByteBuffer是OHC管理的堆外内存区域的映射。 * * @param value 需要序列化的对象 * @param buf 序列化后的存储空间 */ @Override public void serialize(String value, ByteBuffer buf) { // 得到字符串对象UTF-8编码的字节数组 byte[] bytes = value.getBytes(Charsets.UTF_8); // 用前16位记录数组长度 buf.put((byte) ((bytes.length >>> 8) & 0xFF)); buf.put((byte) ((bytes.length) & 0xFF)); buf.put(bytes); } /** * 对堆外缓存的字符串进行反序列化 * * @param buf 字节数组所在的 ByteBuffer * @return 字符串对象. */ @Override public String deserialize(ByteBuffer buf) { // 判断字节数组的长度 int length = (((buf.get() & 0xff) << 8) + ((buf.get() & 0xff))); byte[] bytes = new byte[length]; // 读取字节数组 buf.get(bytes); // 返回字符串对象 return new String(bytes, Charsets.UTF_8); } }
3. 将CacheSerializer的实现类作为参数,传递给OHCache的构造函数来创建OHCache
import org.caffinitas.ohc.Eviction; import org.caffinitas.ohc.OHCache; import org.caffinitas.ohc.OHCacheBuilder; public class OffHeapCacheExample { public static void main(String[] args) { OHCache<String, String> ohCache = OHCacheBuilder.<String, String>newBuilder() .keySerializer(new StringSerializer()) .valueSerializer(new StringSerializer()) .eviction(Eviction.LRU) .build(); ohCache.put("hello", "world"); System.out.println(ohCache.get("hello")); // world } }
4. 使用OHCache的相关方法(get、put)来读写缓存。见第 3 点中的使用示例。
3、OHC 的底层原理
3.1、整体架构
OHC 以 API 的方式供其他 Java 程序调用,其 org.caffinitas.ohc.OHCache 接口定义了可调用的方法。对于缓存来说,最常用的是 get 和 put 方法。针对不同的使用场景,OHC提供了两种OHCache的实现:
org.caffinitas.ohc.chunked.OHCacheChunkedImpl
org.caffinitas.ohc.linked.OHCacheLinkedImpl
以上两种实现均把所有条目缓存在堆外,堆内通过指向堆外的地址指针对缓存条目进行管理。
其中,linked 实现为每个键值对分别分配堆外内存,适合中大型键值对。chunked 实现为每个段分配堆外内存,适用于存储小型键值对。由于 chunked 实现仍然处于实验阶段,所以我们选择 linked 实现在线上使用,后续介绍也以linked 实现为例,其整体架构及内存分布如下图所示,下文将分别介绍其功能。
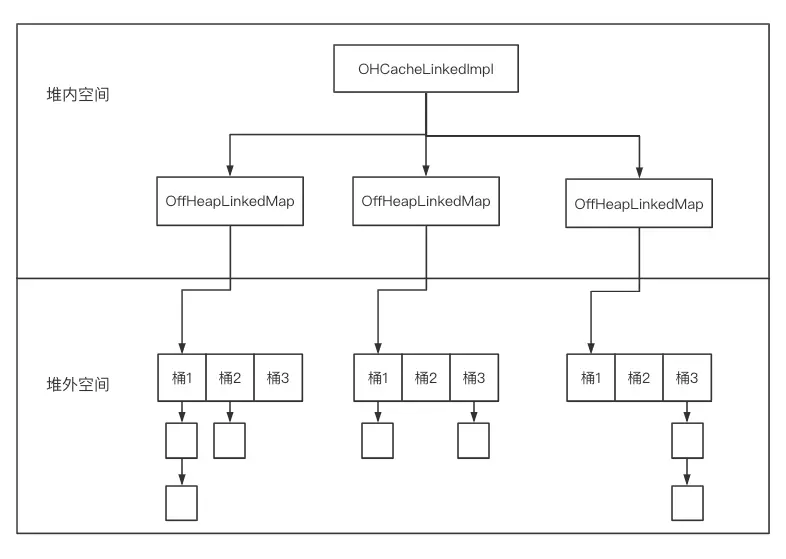
3.2、OHCacheLinkedImpl
OHCacheLinkedImpl是堆外缓存的具体实现类,其主要成员包括:
段数组:OffHeapLinkedMap[]
序列化器与反序列化器:CacheSerializer
OHCacheLinkedImpl 中包含多个段,每个段用 OffHeapLinkedMap 来表示。同时,OHCacheLinkedImpl 将Java对象序列化成字节数组存储在堆外,在该过程中需要使用用户自定义的 CacheSerializer。OHCacheLinkedImpl 的主要工作流程如下:
1、计算 key 的 hash值,根据 hash值 计算段号,确定其所处的 OffHeapLinkedMap
2、从 OffHeapLinkedMap 中获取该键值对的堆外内存指针
3、对于 get 操作,从指针所指向的堆外内存读取 byte[],把 byte[] 反序列化成对象
4、对于 put 操作,把对象序列化成 byte[],并写入指针所指向的堆外内存
3.3、段的实现:OffHeapLinkedMap
在OHC中,每个段用 OffHeapLinkedMap 来表示,段中包含多个分桶,每个桶是一个链表,链表中的元素即是缓存条目的堆外地址指针。OffHeapLinkedMap 的主要作用是根据 hash值 找到 键值对 的 堆外地址指针。在查找指针时,OffHeapLinkedMap 先根据 hash值 计算出 桶号,然后找到该桶的第一个元素,然后沿着第一个元素按顺序线性查找。
3.4、空间分配
OHC 的 linked 实现为每个键值对分别分配堆外内存,因此键值对实际是零散地分布在堆外。
OHC提供了JNANativeAllocator 和 UnsafeAllocator 这两个分配器,分别使用 Native.malloc(size) 和 Unsafe.allocateMemory(size) 分配堆外内存,用户可以通过配置来使用其中一种。
OHC 会把 key 和 value 序列化成 byte[] 存储到堆外,如2.3所述,用户需要通过实现 CacheSerializer 来自定义类完成 序列化 和 反序列化。因此,占用的空间实际取决于用户自定义的序列化方法。
除了 key 和 value 本身占用的空间,OHC 还会对 key 进行 8位 对齐。比如用户计算出 key 占用 3个字节,OHC会将其对齐到8个字节。另外,对于每个键值对,OHC需要额外的64个字节来维护偏移量等元数据。因此,对于每个键值对占用的堆外空间为:
每个条目占用堆外内存 = key占用内存(8位对齐) + value占用内存 + 64字节
4、方案选型与应用
4.1、适用于OHC存储的数据
针对我们线上常用的缓存:Redis 集群、OHC 和 Guava 来进行线上数据存储,这三种存储方式的特性分别如下:
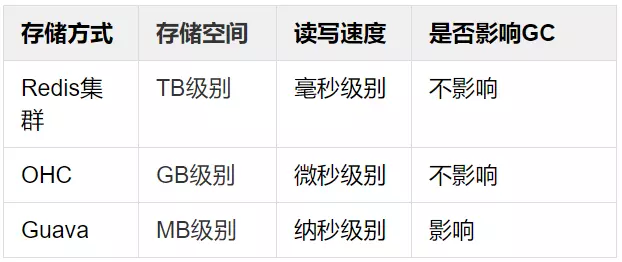
因为不同存储方式的特性差别较大,我们会根据具体场景来从中选择。特征组装与排序引擎所需的数据主要分为“离线数据” 和 “实时数据”,均使用Redis作为主库。离线数据由定时算法任务生成后写入HDFS,一般按照小时级或者天级进行更新,并通过 XXL Job 和 DataX 定时从 HDFS 同步到 Redis 供使用。实时数据则根据用户行为进行在线更新,通常使用 Flink 任务实时计算后直接写入 Redis。
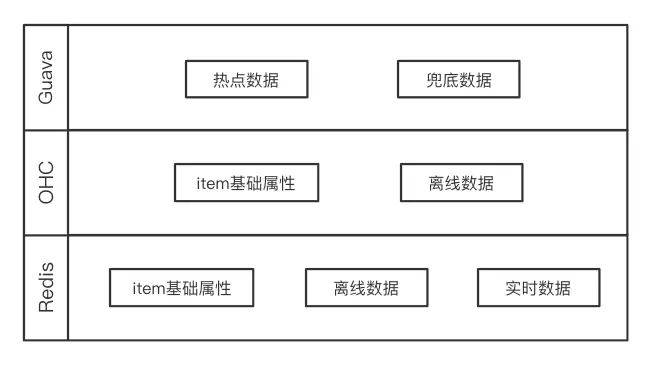
对于离线数据,其更新周期比较长,非常适合使用OHC缓存到服务所在服务器本地。比如,在进行排序时,item的历史点击率是非常重要的特征数据,特别是其最近几天的点击率。这种以天为单位更新的离线特征,如果使用OHC缓存到本地,则可以避免读取Redis的网络开销,节省排序阶段耗时。
对于实时数据,其更新受用户实时行为影响,下次更新时间是不确定的。比如用户对某个目的地的偏好程度,这种数据随着用户在App端不断进行点击而更新。这种实时数据不会使用OHC缓存到本地,否则可能会导致 本地缓存 和 主库的数据不一致。即使进行缓存,也应该设置较小的过期时间(比如秒级或者分钟级),尽量保证数据的实时性和准确性。
其他数据,比如站内的高热数据 和 兜底数据,其数据量较小且可能频繁使用,这种数据我们使用 Guava 缓存到堆内,以便于快速读取。
4.2、序列化工具的选择
如上文所说,OHC 是一款 key-value 形式的缓存框架,并且对 key 和 value 都提供了泛型支持。因此,使用方在创建 OHC对象时就需要确定 key 和 value 的类型。
一般使用场景中,使用OHC时 key 设置为 String 类型,value 则设置为 Object类型,从而可以存储各种类型的对象。由于 OHC 需要把 key 和 value 序列化成字节数组存储到堆外,因此需要选择合适的序列化工具。
对于String类型的key,其序列化过程比较简单,可以直接转换成UTF-8格式的字节数组来表示。对于Object类型的 value,则选用了开源的 Kyro 作为序列化工具。需要注意的是,由于Kyro不是线程安全的,可以搭配ThreadLocal一起使用。
在使用OHC时,通常有两个地方用到序列化。在存储每个键值对时,会调用 CacheSerializer#serializedSize 计算序列化后的内存空间占用,从而申请堆外内存。另外,在真正写入堆外时,会调用 CacheSerializer#serialize 真正进行序列化。因此,务必在这两个方法中使用相同的序列化方法。
也就是说,申请的堆外内存 (CacheSerializer#serializedSize 计算所得) 和 实际占用的堆外内存(CacheSerializer#serialize) 要保持一致。我们开始使用 OHC 时,在 CacheSerializer#serializedSize方法中使用com.twitter.common.objectsize.ObjectSizeCalculator 计算序列化后的空间占用,而在 CacheSerializer#serialize 中则使用了Kryo。结果发现 ObjectSizeCalculator 计算的内存远远大于Kyro计算出来的,导致为每个键值对申请了大量堆外内存却没有充分使用。
4.3、生产环境的配置
OHC支持大量配置选项,供使用方根据自身业务场景进行选择,这里介绍下在我们业务中相关参数的配置。

总容量
最开始使用OHC时,我们设置的上限为4G左右。随着业务的发展和数据量的增长,逐渐增大到10G,基本可以覆盖热点数据。
段数量
一方面,OHC使用了分段锁,多个线程访问同一个段时会导致竞争,所以段数量不宜设置过小。同时,当段内条目数量达到一定负载时 OHC 会自动 rehash,段数量过小则会允许段内存储的条目数量增加,从而可能导致段内频繁进行rehash,影响性能。另一方面,段的元数据是存储在堆内的,过大的段数量会占用堆内空间。因此,应该在尽量减少rehash的次数的前提下,结合业务的QPS等参数,将段数量设置为较小的值。
哈希算法
通过压测,我们发现使用 CRC32、CRC32C 和 MURMUR3 时,键值对的分布都比较均匀,而 CRC32C 的 CPU使用率相对较低,因此使用 CRC32C 作为哈希算法。
逐出算法
选用10G的总容量,基本已经覆盖了大部分热点数据,并且很少出现偶发性或者周期性的批量操作,因此选用了LRU。
4.4、线上表现
使用OHC管理的单机堆外内存在 10G 左右,可以缓存的条目为 百万量级。我们主要关注 命中率、读取 和 写入速度 这几个指标。
OHC#stats 方法会返回 OHCacheStats 对象,其中包含了命中率等指标。
当内存配置为10G时,在我们的业务场景下,缓存命中率可以稳定在95%以上。同时,我们在调用 get 和 put 方法时,进行了日志记录,get 的平均耗时稳定在 20微妙 左右,put 则需要 100微妙。
需要注意的是,get 和 put 的速度 和 缓存的键值对大小呈正相关趋势,因此不建议缓存过大的内容。可以通过org.caffinitas.ohc.maxEntrySize 配置项,来限制存储的最大键值对,OHC发现单个条目超过该值时不会将其放入堆外缓存。
4.5、实践优化
(1)异步移除过期数据
在 OffHeapLinkedMap 的原始实现中,读取键值对 时 会判断其是否过期,如果过期则立即将其移除。移除键值对是相对比较 “昂贵” 的操作,可能会阻塞当前读取线程,因此我们对其进行了异步改造。读取键值对时,如果发现其已经过期,则会将其存入一个队列。同时,在后台加入了一个清理线程,定期从队列里面读取过期内容并进行移除。
(2)加锁方式优化
OHC本身是线程安全的,因为每个段都有自己的锁,在读取 和 写入时都会加锁。其源代码中使用的是 CAS锁(compare-and-set),在更新失败时尝试挂起线程并重试:
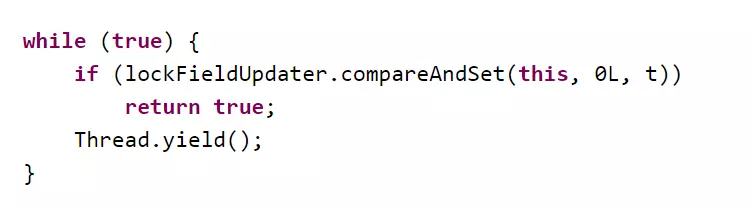
每个线程都有自己的缓存,当变量标记为脏时线程会更新缓存。但是,无论是否成功设置该值,CAS锁在每次调用变量时都会将其标记为脏数据,这会导致在线程竞争激烈时性能下降。使用 CASC(compare-and-set-compare)锁可以尽量减少 CAS 的次数,从而提高性能:

5、线上配置参数
-XX:MaxDirectMemorySize=9g -Dorg.caffinitas.ohc.capacity=9126805504 # 5G=5368709120 7G=7516192768 8.5G=9126805504 -Dorg.caffinitas.ohc.maxEntrySize=2621440 # 10M -Dorg.caffinitas.ohc.segmentCount=1024 -Dorg.caffinitas.ohc.hashAlgorighm=CRC32C -Dorg.caffinitas.ohc.eviction=W_TINY_LFU -Dorg.caffinitas.ohc.edenSize=0.1
相关的配置参数含义请参考 4.3 中的内容。这里只说一下:MaxDirectMemorySize
-XX:MaxDirectMemorySize=size 用于设置 New I/O(java.nio) direct-buffer allocations 的最大大小,size的单位可以使用 k/K、m/M、g/G;
如果没有设置该参数则默认值为0,意味着JVM自己自动给NIO direct-buffer allocations选择最大大小;
从代码java.base/jdk/internal/misc/VM.java中可以看到默认是取的Runtime.getRuntime().maxMemory()
6、总结
OHC是一款Java实现的堆外缓存框架,具有低时延、不影响GC的特点,适合存储大量缓存条目,同时支持配置过期时间、逐出算法等多个配置项。
同时我们注意到,相对于另一款开源的缓存框架 ehcache,OHC的中文资料相对较少。我们在框架选型时也对两者进行了压测,OHC在我们业务场景下性能表现更好,因此选择 OHC作为我们的主要缓存实现。
特别地,对于推荐引擎这种依赖大量 离线数据 和 实时数据的应用,OHC适合将离线数据进行本地缓存,从而节省访问远程数据库的时间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号