pandas数据分析-读取文本格式的数据
因为其简单的文件交互语法、直观的数据结构,以及诸如元组打包解包之类的便利功能,python在文本和文件处理方面已经成为一门简单的语言。
pandas提供了一些用于将表格型数据读取为DataFrame对象的函数,以下对他们进行了总结,其中read_csv和read_table可能是你今后用的最多的。
函数 说明
read_csv 从文件、URL、文件型对象中加载带分隔符的数据,默认分隔符为逗号
read_table 从文件、URL、文件型对象中加载带分隔符的数据,默认分隔符为制表符('\t')
read_fwf 读取定宽列格式数据(也就是说,没有分隔符)
read_clipboard 读取剪贴板的数据,可以看做read_table的剪贴板版,在将网页转换为表格 时很有用
path文件:

由于该文件以逗号分割,我们可以使用read_csv将其读入一个DataFrame。
df = pd.read_csv('path')
print(df)
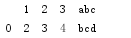
也可以使用read_table,只不过要指定分隔符而已。
df = pd.read_table('path',sep=',')
你可以让pandas为其分配默认的列名,也可以自己定义。
df = pd.read_table('path',header=None)
df = pd.read_table('path',names=['i','g','h','y'])
假设你希望将‘y’列作为DataFrame的索引,可以通过index_col函数指定列。
names=['i','g','h','y']
df = pd.read_table('path',names=names,index_col='y')
假设你希望将多个列做成一个层次化索引,只需传入由列编号或列名组成的编号即可。
names=['i','g','h','y']
df = pd.read_table('path',names=names,index_col=['y','h'])
有些表格可能不是用固定的分隔符去分隔字段的,比如空白符或其他模式,我们可以用一些正则表达式来作为read_table的分隔符,看看下面这个文本文件:

该文件由数量不定的分隔符分隔,我们可以通过正则表达\s+表示。
df = pd.read_table('path',sep='\s+')
print(df)
由于列名比数据行的数据少,所有read_table推断为索引。
![]()

这些解析器函数可以帮助你处理很多的异形文件格式,可以使用skiprows函数进行跳过。
df = pd.read_table('path',sep='\s+',skiprows=[1])
缺失值处理是pandas的一个重要组成部分,缺失值要么没有,要么用一个固定的字符串表示。

df = pd.read_csv('path')
print(df)

print(pd.isnull(df))
![]()
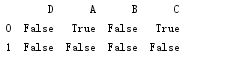
na_values可以接收一组用于表示缺失值的字符串。
df = pd.read_csv('path',na_values=['NULL'])
可以用一个字典为各列指定不同的NA值。
sent = {'C':[8],'B':[3]}
df2 = pd.read_csv('path',na_values=sent)
在处理大量文件时,你可能指向读取文件的一小部分或者逐块对文件进行迭代,如果你指向读取几行,通过nrows进行指定即可。
df2 = pd.read_csv('path',nrows=1)
要逐块读取文件,可以设置chunksize参数。
df2 = pd.read_csv('path',chunksize=1)
top = Series([])
for pi in df2:
top = top.add(pi['key'].value_counts(),fill_value=0)
print(top[:1])
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号