
有代表性的大数据技术Hadoop,Spark,Flink,Beam
1. Hadoop
2005---2015最主流
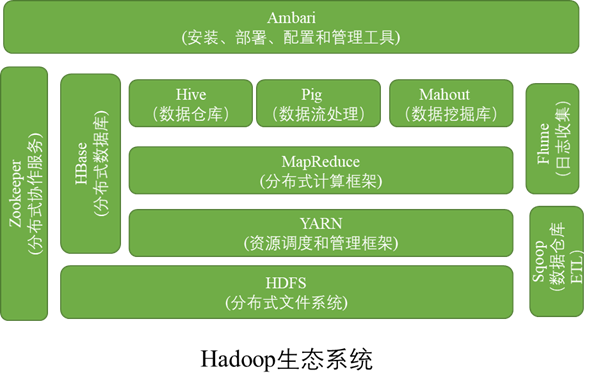
数据仓库和数据库有啥区别
数据库是存储某一时刻的数据信息
而数据仓库是存储连续时间段的数据信息(反映了时间维度)
因此,数据仓库可以做很多决策分析,例如OLAP分析,可以对多维数据分析,可以分析商品销量的走势之类,销量变化情况
Hive的数据保存在底层的HDFS中,查询的时候用sql语句,可以将Hive看成编程接口
Pig可以对数据进行清洗和转换,然后保存在Hive中
Mahout是数据挖掘算法,你只需要简单的调接口、传参数,这样可以减少工作量。
MapReduce分为两个主要函数:map()和reduce()
分而治之
YARN在一个集群之内对多个框架进行底层资源的分配和调度,可以实现多框架的共存,提高集群资源的利用率。
2. Spark
2009年开发,2015年走红
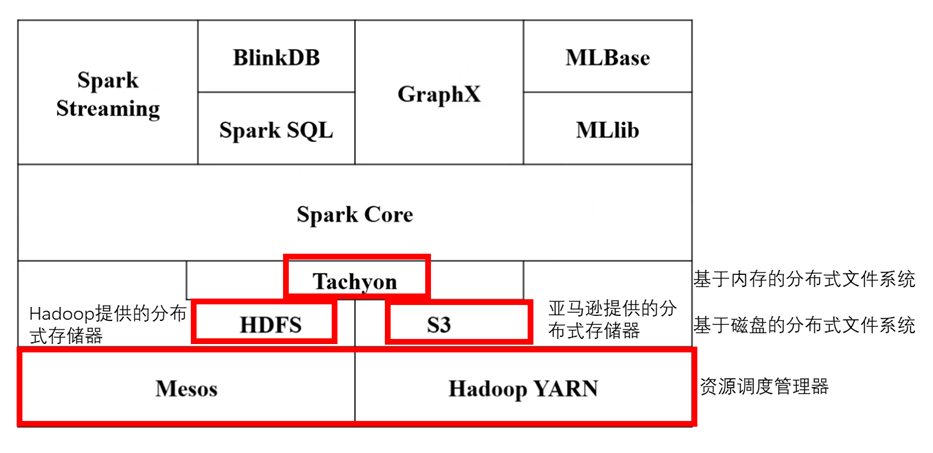
hadoop与spark的区别
与其说hadoop与saprk的区别,倒不如说hadoop中mapreduce与spark的区别
mapreduce的缺点:(1)表达能力有限
(2)磁盘IO开销大
(3)延迟高
spark的优点: (1)多种数据集的操作类型,如map,filter等
(2)编程模型更灵活
(3)提供了内存计算
(4)基于DAG(有向无环图)的任务调度执行机制
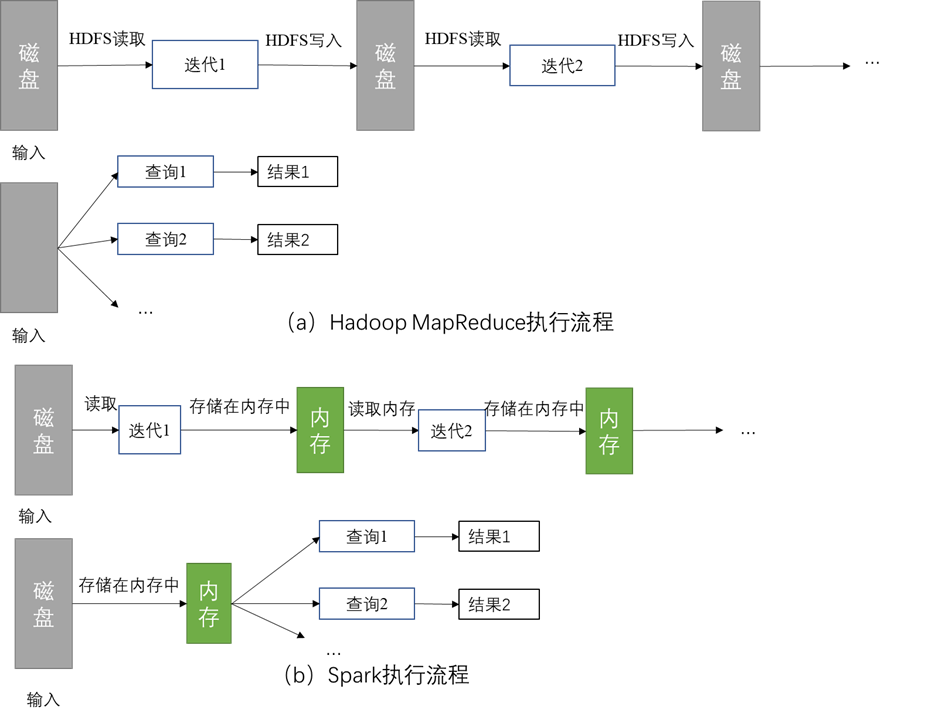
spark在迭代运算的过程中,效率远高于hadoop mapreduce.
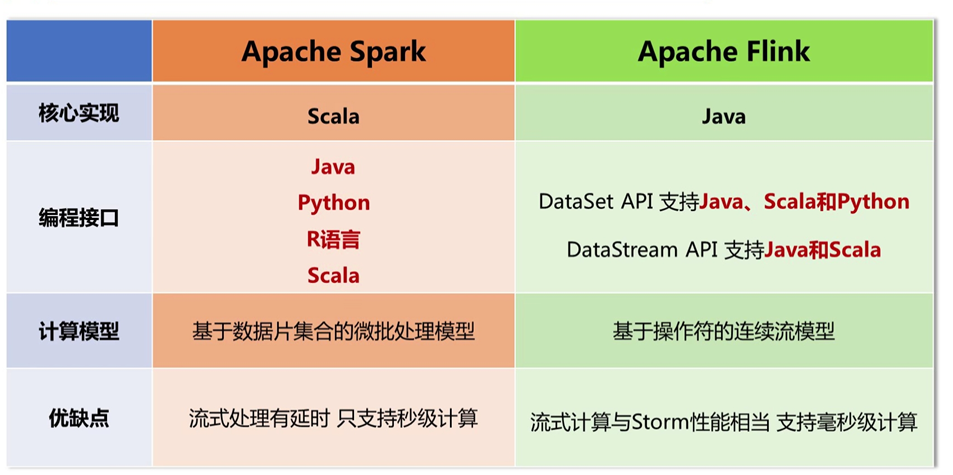
3. apache Flink
Flink的开发语言是java
4. Beam
能不能将所有框架统一?只需要学习Beam这套编程接口,就可以在不同平台上完成各种任务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号