

异常检测

那你怎么去建立这样一个数据集呢?
我们从一个很小的例子切入,如果让我来收集信用卡欺诈数据集,那我能拿到的数据都是正常的,怎么去判别不正常的数据集呢?可想而知,自己建立一个有标签的数据集是一个很困难的任务。
对异常检测案例训练数据集进行分类:
1.数据有标签,直接当成分类问题处理。我们希望机器遇到异常的样本能给出一个“unknow”的标签
可以看下:open-set recognition
2. 数据无标签,这个可以分为2类,第一类是数据全部是干净的数据(正常样本);第二类正常数据混杂有异常数据
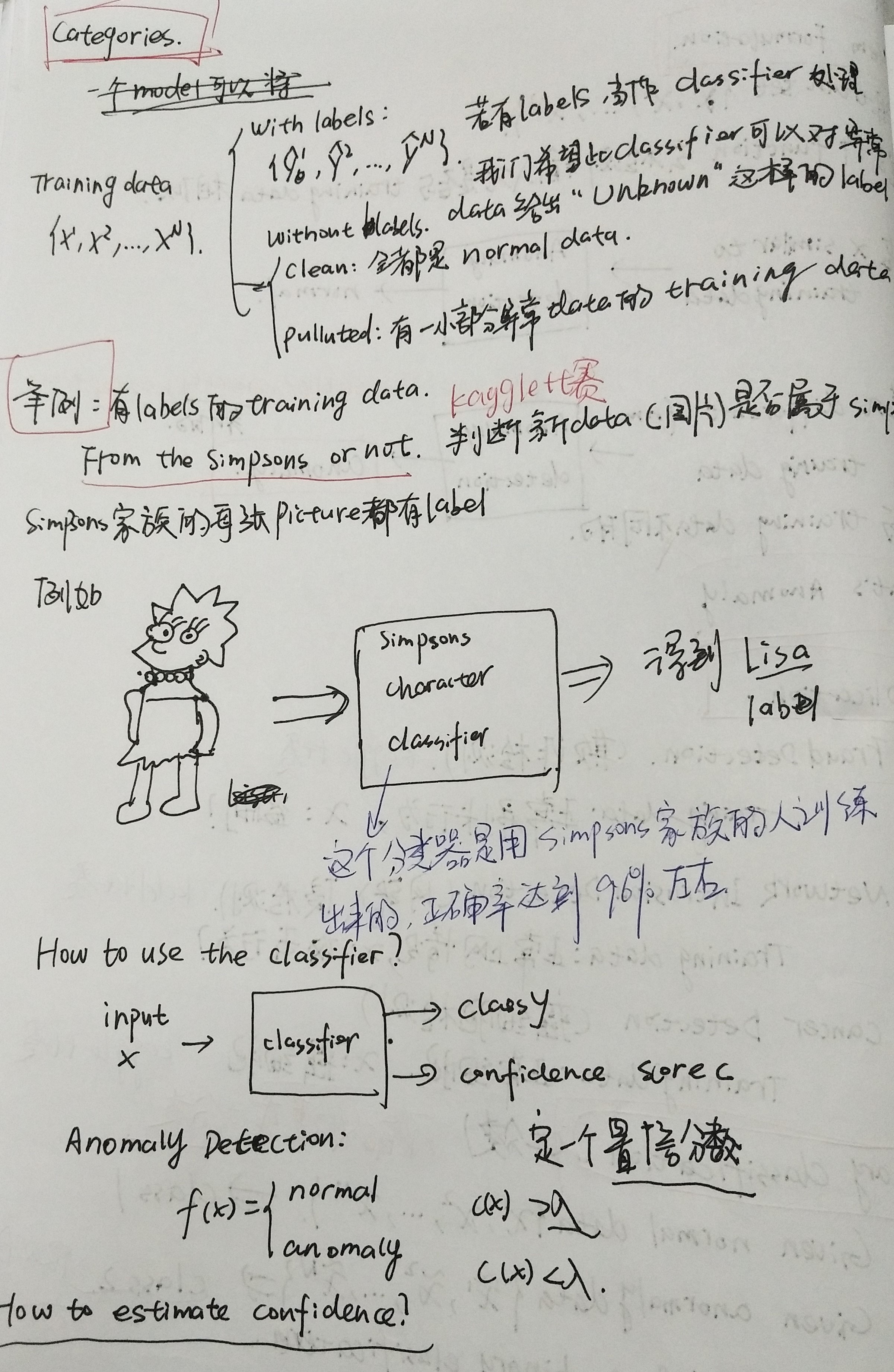
针对有标签的数据集:
我们有一个simpson家族的数据集(有图片和标签)
(1)训练了一个模型分类器(正确率还挺高96%)
(2)拿一个异常数据丢给机器,希望机器能判别出这个是异常数据。
(3)操作方法:模型最后都会通过一个softmax函数做分类,这里会返回一组置信分数,如果机器很有把握,有一个类别的分数就会很高;如果机器没啥把握,每个类别的分数就会很平均。
也就是根据信心分数来做异常检测,我们这里设置一个信心阈值,若信心分数大于阈值,说明是正常数据,否则是异常数据。
这个信心阈值怎么设置:通过验证集,我们确定阈值时,这个时候的标签为2分类(要么是simpson家族的人,要么不是)
上线:给出一张图像,让机器来判断这个人物是否是simpson家族的人。
如何评价一个异常检测系统的好坏?
我们不关注正常值,更多的是关注异常值。那么正确率就无法很好的衡量模型。
如果我们把正常的样本判别成异常样本的cost
把异常的样本判别成正常的样本的 cost
我们可以根据业务需求设置这样的cost table

异常数据的label可以通过GAN来完成

我这边拿信用卡欺诈案例做了个实验:
https://blog.csdn.net/sinat_41774213/article/details/88552652

 浙公网安备 33010602011771号
浙公网安备 33010602011771号