

软工第四次作业
结对编程
| 结对伙伴 | 张旭林(201831061425) |
|---|---|
| GitHub地址 | https://github.com/Dedicate-labors/201831061425.git |
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 120 |
| · Estimate | · 估计这个任务需要多少时间 | 2400 | 2625 |
| Development | 开发 | 300 | 200 |
| · Analysis | · 需求分析 (包括学习新技术) | 100 | 100 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 80 | 80 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 40 | 30 |
| · Design | · 具体设计 | 200 | 100 |
| · Coding | · 具体编码 | 800 | 900 |
| · Code Review | · 代码复审 | 100 | 200 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 100 | 50 |
| Reporting | 报告 | 60 | 50 |
| · Test Report | · 测试报告 | 60 | 40 |
| · Size Measurement | · 计算工作量 | 30 | 45 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 40 | 50 |
| 合计 | 1900 | 1995 |
二、需求分析和思路
分析
1、统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
2、统计文件的有效行数:任何包含非空白字符的行,都需要统计。
3、统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
4、按照字典序输出到文件txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
5、-i 参数设定读入的文件路径
6、-m 参数设定统计的词组长度
7、-n参数设定输出的单词数量
8、-o 参数设定生成文件的存储路径
思路
1、单词先用空格来读取,然后再根据题目要求进行筛选。行数可以通特定字符判断。
2、在统计单词数时已经存到了容量中,进行一次排序即可。可以利用sort函数对单词进行排序。
3、附加的功能可以通过调整已有函数来得到。
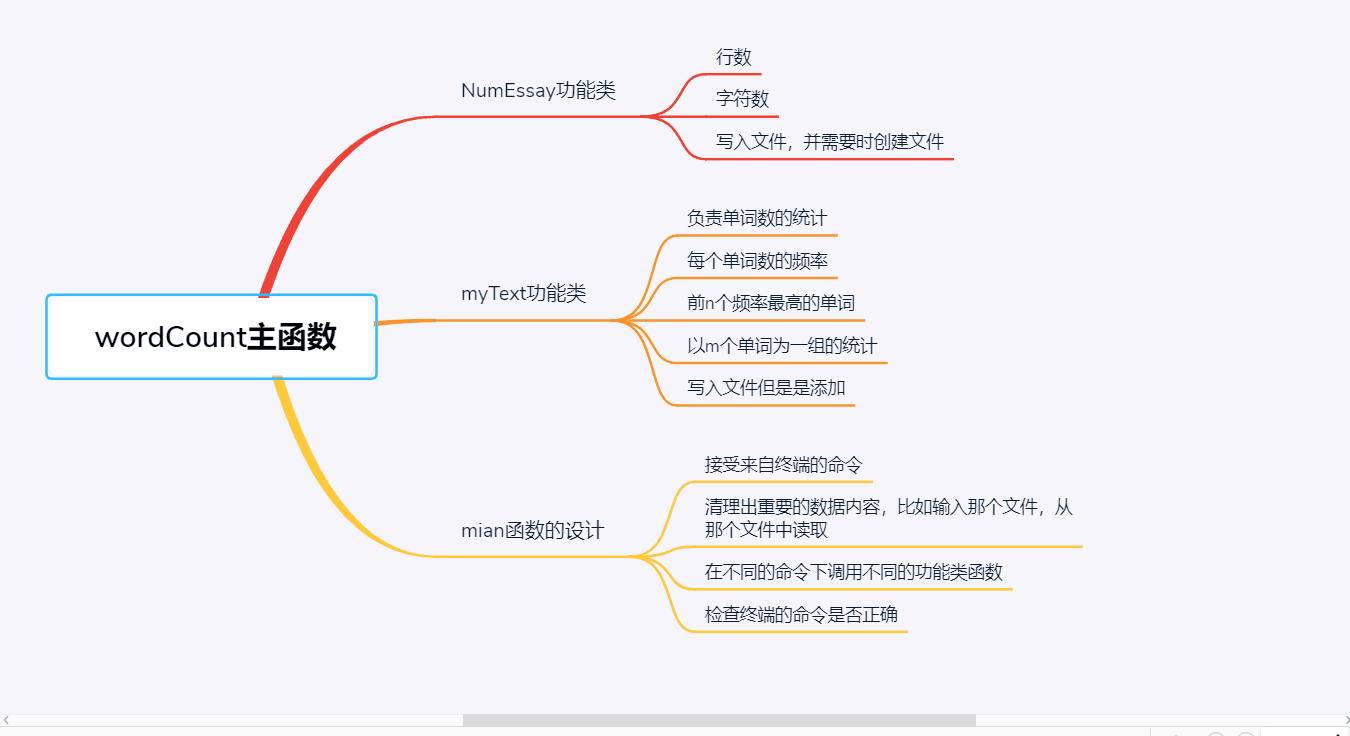
三、实现过程
我的核心代码
统计频率最高的前n个单词
//统计频率最高的前n个单词
void myText::frequency(int n)
{
ifile.open(path);
string str;
string sss;
while (getline(ifile, sss))
{
str += sss;
}
stringstream ss(str);
string s;
vector<string>vt;
map<string, int>m1;
while (getline(ss, s, ' '))
{
int flag = 0;
int i = 0;
int j = 0;
int k = 0;
while (i < s.size())
{
if (s[i] <= 'z'&& s[i] >= 'a' || s[i] <= 'Z'&& s[i] >= 'A')
{
j++;
if (s[i] <= 'Z'&& s[i] >= 'A')
{
s[i] += 32;
}
}
else
{
k++;
}
if (j < 4 && k>0)
{
i++;
flag = 0;
break;
}
else if (j >= 4)
{
i++;
flag = 1;
}
else
{
i++;
flag = 0;
}
}
if (flag == 1)
vt.push_back(s);
}
for (int i = 0; i < vt.size(); i++)
{
m1[vt[i]] += 1;
}
//cout << "字符串单词总个数 : " << vt.size() << endl;
//cout << "不同单词的个数 : " << m1.size() << endl;
cout << "前"<<n<<"个不同单词出现的频率 :" << endl;
vector<pair<string, int>>vt2(m1.begin(), m1.end());
sort(vt2.begin(), vt2.end(), cmp());
int k=0;
for (vector<pair<string, int>>::iterator it = vt2.begin(); it != vt2.end(); it++)
{
k++;
cout << it->first << " :" << it->second << endl;
if (k > n)
{
break;
}
}
ifile.close();
}
统计频率和单词数
void myText::frequency()
{
ifile.open(path);
string str;
string sss;
while (getline(ifile, sss))
{
str += sss;
}
stringstream ss(str);
string s;
vector<string>vt;
map<string, int>m1;
while (getline(ss, s, ' '))
{
int flag = 0;
int i = 0;
int j = 0;
int k = 0;
while (i < s.size())
{
if (s[i] <= 'z'&& s[i] >= 'a' || s[i] <= 'Z'&& s[i] >= 'A')
{
j++;
if (s[i] <= 'Z'&& s[i] >= 'A')
{
s[i] += 32;
}
}
else
{
k++;
}
if (j < 4 && k>0)
{
i++;
flag = 0;
break;
}
else if(j >= 4)
{
i++;
flag = 1;
}
else
{
i++;
flag = 0;
}
}
if(flag == 1)
vt.push_back(s);
}
for (int i = 0; i < vt.size(); i++)
{
m1[vt[i]] += 1;
}
cout << "总的单词个数:"<< vt.size() << endl;
cout << "不同单词的个数 : " << m1.size() << endl;
cout << "不同单词出现的频率 :" << endl;
vector<pair<string, int>>vt2(m1.begin(), m1.end());
sort(vt2.begin(), vt2.end(), cmp());
int k = 0;
for (vector<pair<string, int>>::iterator it = vt2.begin(); it != vt2.end(); it++)
{
k++;
cout << it->first << " :" << it->second << endl;
if (k > 10)
{
break;
}
}
ifile.close();
}
字符长度为n的单词
void myText::nWords(int n)
{
ifile.open(path);
string str;
string sss;
while (getline(ifile, sss))
{
str += sss;
}
stringstream ss(str);
string s;
vector<string>vt;
map<string, int>m1;
while (getline(ss, s, ' '))
{
int flag = 0;
int i = 0;
int j = 0;
int k = 0;
while (i < s.size())
{
if (s[i] <= 'z'&& s[i] >= 'a' || s[i] <= 'Z'&& s[i] >= 'A')
{
j++;
if (s[i] <= 'Z'&& s[i] >= 'A')
{
s[i] += 32;
}
}
else
{
k++;
}
if (j < 1 && k>0)
{
i++;
flag = 0;
break;
}
else if (j+k == n)
{
i++;
flag = 1;
}
else
{
i++;
flag = 0;
}
}
if (flag == 1)
vt.push_back(s);
}
for (int i = 0; i < vt.size(); i++)
{
m1[vt[i]] += 1;
}
cout << "字符长度为 " <<n<<"的单词个数:"<< vt.size() << endl;
cout << "不同单词的个数 : " << m1.size() << endl;
cout << "不同单词出现的频率 :" << endl;
vector<pair<string, int>>vt2(m1.begin(), m1.end());
sort(vt2.begin(), vt2.end(), cmp());
int k = 0;
for (vector<pair<string, int>>::iterator it = vt2.begin(); it != vt2.end(); it++)
{
k++;
cout << it->first << " :" << it->second << endl;
if (k > 10)
{
break;
}
}
ifile.close();
}
写到文件中
void myText::writeToFile(string path)
{
ifile.open(this->path);
ofstream outfile(path, ios::app);
string str;
string sss;
while (getline(ifile, sss))
{
str += sss;
}
stringstream ss(str);
string s;
vector<string>vt;
map<string, int>m1;
while (getline(ss, s, ' '))
{
int flag = 0;
int i = 0;
int j = 0;
int k = 0;
while (i < s.size())
{
if (s[i] <= 'z'&& s[i] >= 'a' || s[i] <= 'Z'&& s[i] >= 'A')
{
j++;
if (s[i] <= 'Z'&& s[i] >= 'A')
{
s[i] += 32;
}
}
else
{
k++;
}
if (j < 4 && k>0)
{
i++;
flag = 0;
break;
}
else if (j >= 4)
{
i++;
flag = 1;
}
else
{
i++;
flag = 0;
}
}
if (flag == 1)
vt.push_back(s);
}
for (int i = 0; i < vt.size(); i++)
{
m1[vt[i]] += 1;
}
outfile << "字符串单词总个数 : " << vt.size() << endl;
outfile << "不同单词的个数 : " << m1.size() << endl;
outfile << "不同单词出现的频率 :" << endl;
map<string, int>::iterator it;
for (it = m1.begin(); it != m1.end(); it++)
{
outfile << "<"<<it->first<<">" << ":" << it->second << endl;
}
outfile.close();
ifile.close();
}
运行结果

四、代码复审
将不同的功能合并到一起,我把.h和.cpp文件发给结对伙伴,运行并没有什么问题。
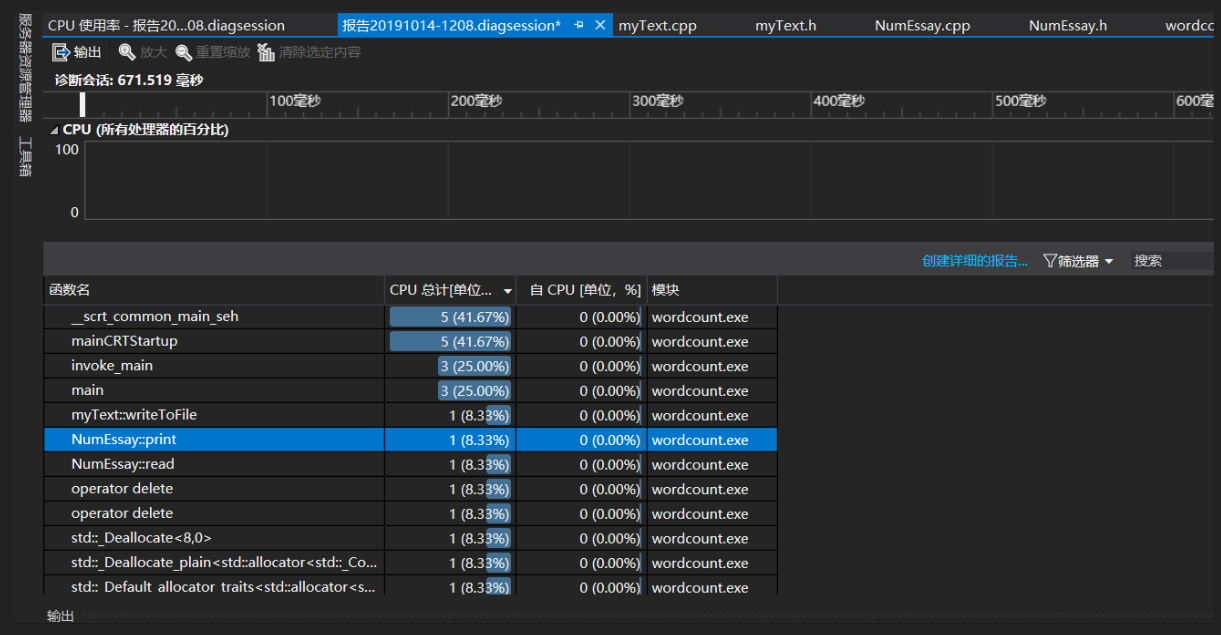
五、代码性能测试
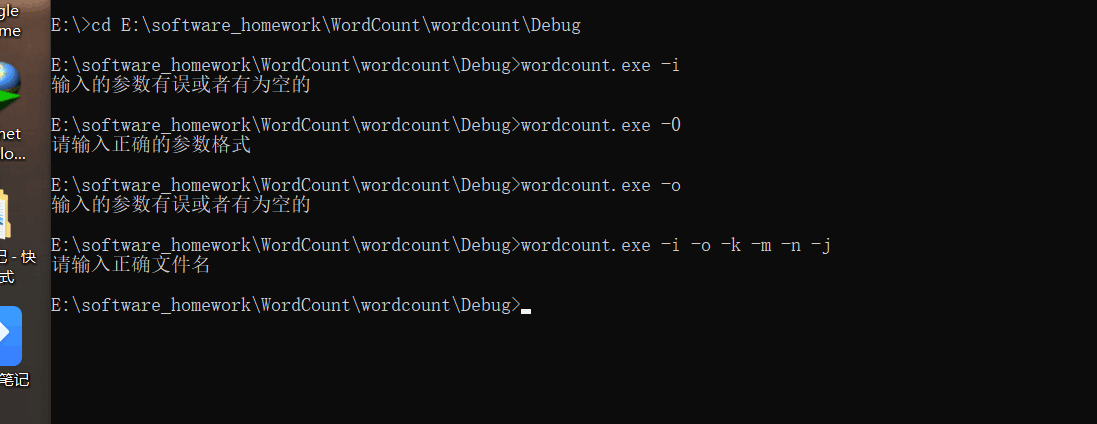
六、异常处理
当未创建一个input.txt文件,或其他参数错误等问题出现时会报错
七、结对过程
结对的人是十分熟悉,并且我们有很好的分工。在遇到问题时,进行有效的沟通,很好的解决了许多问题。
通过这次结对编程,深刻的体会到了合作的好处,不仅效率感觉更高了,而且负担有人分担让人感觉压力变小了。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号