《机器学习》第二次作业——第四章学习记录和心得
《第四章》笔记











4.11 线性判据多类分类
本质:非线性
(1) 实现非线性分类的途径
- 一个模型:能刻画非线性的决策边界。
- 多个模型:多个模型(线性/非线性)组合成非线性决策边界。
- 组合方式:并行组合、串行组合。
(2)线性判据实现多类分类的途径
- 对于线性判据:通过多个线性模型组合的途径实现多类分类。
思路一:One-to-all策略
(1) 基本思想
-
假设条件:每个类与剩余类线性可分。
-
针对每个类𝐶𝑖 ,单独训练一个线性分类器𝑓𝑖 (𝒙) = 𝒘𝑖𝑇𝒙 + 𝑤𝑖0。
-
每个分类器𝑓𝑖( 𝒙) 用来识别样本𝒙是属于𝐶𝑖类还是不属于𝐶𝑖类。
-
设类别个数为𝐾: 𝐾 > 2。
-
总共需要训练𝐾个分类器。
(2) 判别公式&决策边界
- 给定测试样本𝒙,其属于分类器输出值为正的那个类:

- 决策边界:
- 每个线性方程𝑓𝑖(𝒙)= 0表示𝐶𝑖类与剩余类的决策边界(记作𝐻𝑖)
- 每条决策边界𝐻𝑖垂直于𝒘𝑖
(3) 𝐾 − 1个分类器
有时也可以只训练𝐾 − 1 个分类器:针对某个测试样本𝒙,如果所有𝐾 − 1个分类器都输出为非正值,则代表该样本属于剩余的 第𝐾个类。
(4) 训练样本选择
- 对于每个分类器𝑓𝑖 𝒙 ,属于𝐶𝑖类的训练样本作为正样本,其余类别的训练样本作为负样本。
- 问题:每个分类器正负类样本个数不均衡。
(5) 混淆区域
- 拒绝选项(reject case):针对单个测试样本𝒙,所有分类器输出都不是正值。
- 重叠:针对单个测试样本 𝒙 ,出现多个分类器输出为正,形成多个类重叠的区域。
思路二:线性机
(1) 基本思想
-
假设条件:每个类与剩余类线性可分。
-
训练:基于one-to-all策略训练𝐾个线性分类器𝑓𝑖,每个分类器对应一个类𝐶𝑖。
-
决策:使用输出值投票法(max函数)
给定测试样本𝒙,其属于所有分类器中输出值最大的那个类。
(2) 为什么取输出值最大? -
输出值𝑓𝑖 (𝒙) 近似于𝒙 到分类边界(𝐶𝑖类与剩余类)的距离。
-
该值最大即表示属于该类的可能性大。
(3) 决策过程数学表达 -
线性机的决策过程相当于:将输入特征𝒙直接映射到类别标签𝑙。
-
可见:线性机 = 𝐾个线性模型 + 一个max函数。
-
max函数是非线性的,因此线性机可以实现非线性分类。
-
综合𝐾个线性模型, 𝐾个权重向量𝒘𝑖写成矩阵𝑾,决策过程可以表达为:
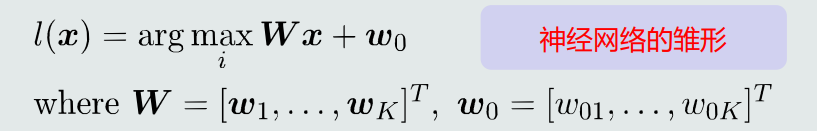
(4) 决策边界
-
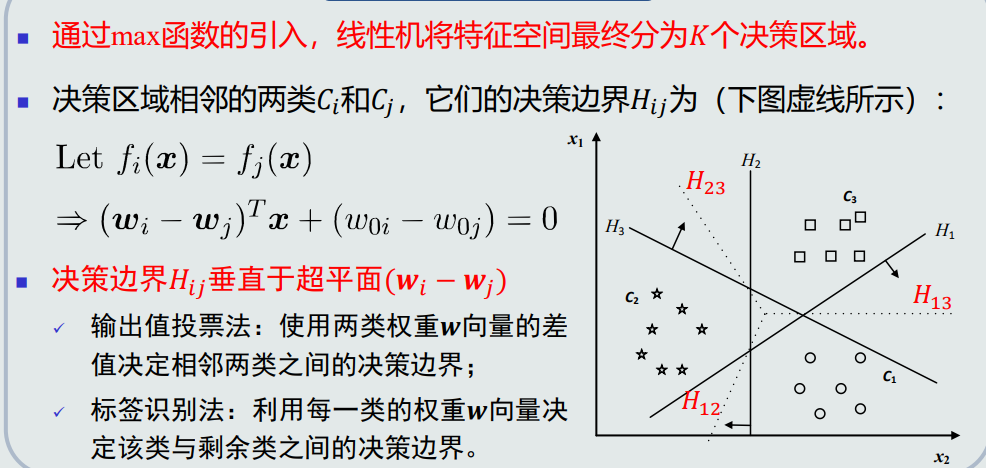
通过max函数的引入,线性机将特征空间最终分为𝐾个决策区域。
-
决策区域相邻的两类𝐶𝑖和𝐶𝑗,它们的决策边界𝐻𝑖𝑗为
-
决策边界𝐻𝑖𝑗垂直于超平面(𝒘𝑖 − 𝒘𝑗)
(5) 优势 -
由于使用max函数,不再有混淆区域(即拒绝区域和重叠区域)
(6) 问题
- 可能出现最大的𝑓𝑖(𝒙) ≤ 0,即测试样本𝒙出现在拒绝区域。
- 如果严格按照线性判据的定义,拒绝区域其实是线性机(基于one-to-all策略)无法正确判断的区域。
思路三:One-to-one策略
(1) 假设条件
- 任意两个类之间线性可分,但每个类与剩余类可能是线性不可分的。
(2) 基本思想
-
针对每两个类𝐶𝑖 和𝐶𝑗 ,训练一个线性分类器:𝑓𝑖𝑗 (𝒙) = 𝒘𝑖𝑗 𝑇𝒙 + 𝑤0𝑖𝑗。 𝐶𝑖类真值为正;𝐶𝑗类真值为负。
-
总共需要训练𝐾 (𝐾 − 1) /2个分类器。
(3) 训练样本选择
- 对于每个分类器𝑓𝑖𝑗 𝒙 ,属于𝐶𝑖类的训练样本作为正样本,属于𝐶𝑗类的训练样本作为负样本。
- 避免了one-to-all策略正负类样本个数不均衡的问题。
- 注意:𝑓𝑖𝑗 𝒙 = −𝑓𝑗𝑖 𝒙 。方程参数是一样的,只是输出值正负相反。分类边界是同一个。
(4) 判别公式&决策边界
- 给定测试样本𝒙,如果所有𝐶𝑖 相关的分类器输出都为正,则𝒙属于𝐶𝑖 :
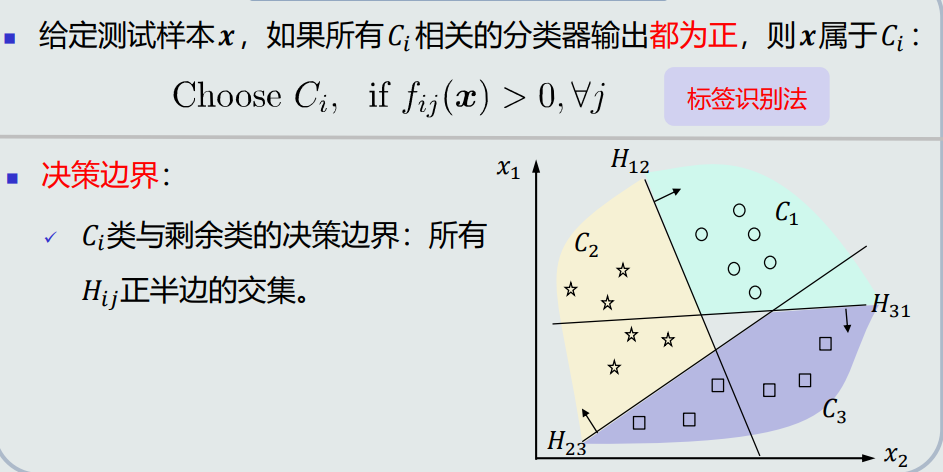
- 决策边界:𝐶𝑖类与剩余类的决策边界:所有𝐻𝑖𝑗正半边的交集。
(5) 优势
- 适用于一些线性不可分的情况,从而实现非线性分类。
- 与one-to-all策略相比,不再有重叠区域。
(6) 问题
会出现拒绝选项( reject case ),即样本不属于任何类的情况。
(7) 避免Reject Case
- 采用类似线性机的策略,在决策过程中采用max函数。
针对每一个类𝐶𝑖,计算跟其成对的所有分类器𝑓𝑖𝑗的输出值之和σ𝑗 𝑓𝑖𝑗,测试样本𝒙属于σ𝑗 𝑓𝑖𝑗最大的那个类𝐶𝑖。
4.12 线性回归
(1) 输出数据和输入数据
-
主要输出数据类型

-
输入样本:个数与特征维度的关系
- 每个输入样本特征为𝑃维。样本个数为𝑁。
- Tall数据:𝑁 ≫ 𝑃,所有训练样本的输入和真值输出 构成一个超定方程组。可以使用线性回归来学习。
- Wide数据:𝑁 ≪ 𝑃,所有训练样本的输入和真值输 出构成一个欠定方程组。
(2)线性回归模型表达
-
输出单维度

-
输出多维度

模型对比:线性回归vs线性判据 -
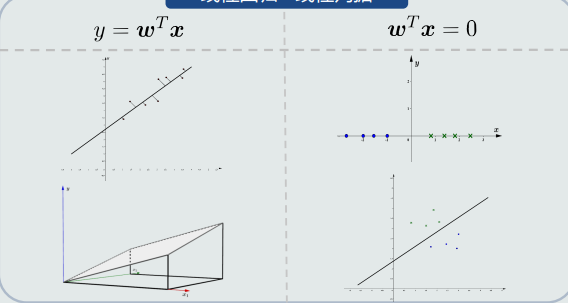
线性回归:y=wTx
- 线性回归关注输出值的具体数值(连续值),所以,将输入空间+输出空间放在一起研究其线性映射方程
-
线性判据:sign(wTx)
- 线性判据关注输出值的正负符号(离散二值),所以,在输入空间研究其决策边界方程(线性的):wTx=0
-
几何表示
(4)线性回归模型如何学习
-
待学习参数:W(y=WTx)
-
训练样本:

-
目标函数---最小化均方误差
-
如果参数w是最优的,意味着对于每个样本(xn,tn)而言,模型的输出值yn与标定的输出针织tn之间的差值最小(即误差最小)
-
因此,目标函数可以使用均方误差,即最小化均方误差
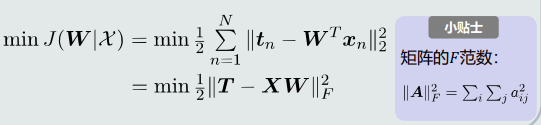
-
目标函数对比:线性回归vs线性判据
- 线性判据:主要判断预测的输出值与真值在符号上的差异。如感知机:被错误分类的样本的输出值之和
- 线性回归:比较预测的输出值和真值在树枝上的差异
-
-
目标优化:
- 展开目标函数
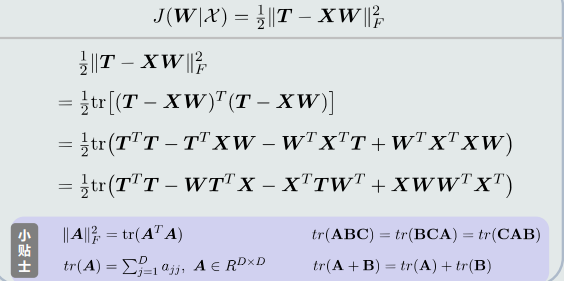
- 对参数w求偏导

-
梯度下降法

-
最小二乘法

XTX分析:非奇异矩阵
XXT分析:奇异矩阵
(4)线性回归模型的概率解释
-
模型的概率解释:

-
似然函数
-
针对每个训练样本,输出真值t的条件概率越大,说明改样本的模型输出值与输出真值越接近,则参数w越是接近最优的
-
因此,给定N个训练样本,似然函数为输出真值t的条件概率乘积。该似然函数即为目标函数。最大化该目标函数
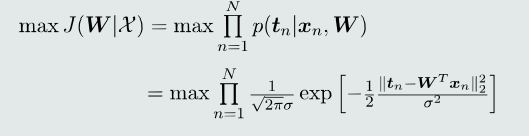
-
-
目标函数优化
- 最大似然估计

- 最大似然vsMSE(最小化均方误差)

4.13 逻辑回归的概念
(1)目前学过的分类器模型中,哪些模型是线性的,哪些是非线性的?

(2)MAP分类器是如何在线性和非线性之间切换的
- logit变换
- 对于二类分类,MAP分类器通过比较后验概率的大小来决策。
- 在每类数据是高斯分布且协方差矩阵相同的情况下, 𝒙属于𝐶1类的后验概 率与属于𝐶2类的后验概率之间的对数比率就是线性模型𝑓(𝒙)的输出。
- Sigmoid函数:连接线性模型和后验概率的桥梁
- 线性模型𝑓(𝒙) + Sigmoid函数 = 后验概率
(3)逻辑回归
- 逻辑回归:线性模型𝑓(𝒙) + sigmoid函数,本身是一个非线性模型
- 决策边界:单个逻辑回归可以用于二类分类;给定两个类,逻辑回归的决策边界仍然是线性的超平面。
- 逻辑回归适用范围:
- 分类:当两类之间是线性可分时
- 回归:可以拟合sigmoid形式的非线性曲线
(4)模型对比
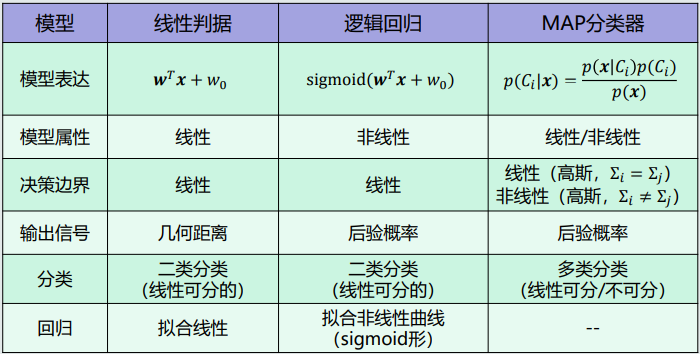
4.14 逻辑回归的学习
(1)训练样本:给定两个类别(正类和负类)共N个标定过的训练样本
- 正类(C1类)样本的输出真值tn=1
- 负类(C2类)样本的输出真值tn=0(与SVM不一样)
(2)如何设计目标函数
- 最大似然估计法

- 目标函数:交叉熵解释

(3)如何优化目标函数
- 梯度下降法:
- 分别对参数w和w0求导,然后更新参数
- 梯度下降法需要注意的问题:
- 梯度消失问题
- 参数初始化问题
- 迭代什么时候停止:如果迭代停止条件设置为训练误差为0,或者所有训练样本都正确分了的时候才停止,则会出现过拟合问题。所以,在达到一定训练精度后,提前停止迭代,可以避免过拟合
4.15 softmax判据的概念
(1)对于多类而言,每类的后验概率如何表达?

(2)softmax函数
- 如果一个类𝐶𝑖对应的𝑦𝑖(即线性模型的输出)远远大于其他类的, 经过exp函数和归一化操作,该类的后验概率𝑝(𝐶𝑖 |𝒙)接近于1,其 他类的后验概率接近于0,则softmax决策就像是一个max函数
- Softmax判据:𝐾个线性判据 + softmax函数。
- softmax判据的决策过程:给定测试样本𝒙,经由线性模型和softmax函数计算𝐾个类对应的 后验概率, 𝒙属于最大后验概率对应的类别。
- softmax判据的决策比边界:决策区域相邻两类Ci和Cj,它们的决策边界Hij为线性
(3)适用范围:
- 分类:每个类和剩余类之间是线性可分的
- 可以拟合指数函数(exp)形式的非线性曲线
4.16 Softmax判据的学习
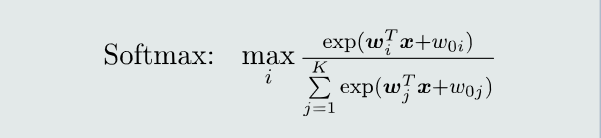
(1)训练样本:
- 输出真值采用one-hot方式:
- 假设xn属于Ci,则为了每一项概率分布表述方便,tn也表达为集合形式
(2)如何设计目标函数
- 最大似然估计法

- 目标函数:交叉熵解释

(3)如何优化目标函数
-
梯度下降法:

4.17 核支持向量机
(1)Kernel方法的基本思想: 如果样本在原始特征空间(𝑋空间)线性不可分,可以将这些样本 通过一个函数𝜑映射到一个高维的特征空间(Φ空间),使得在这 个高维空间,这些样本拥有一个线性分类边界。
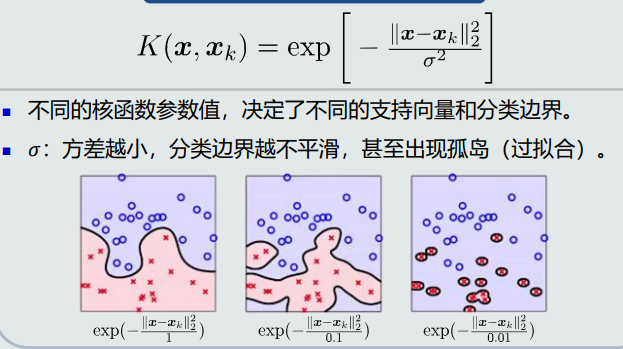
(2)常见的核函数:
-
多项式核函数

-
高斯核函数
机器学习第四章思维导图




 浙公网安备 33010602011771号
浙公网安备 33010602011771号