
人工智能
一、人工智能
此篇是人工智能应用的重点,只用现成的技术不做底层算法,也是让初级程序员快速进入人工智能行业的捷径,目前市面上主流的AI技术提供公司有很多,比如百度、阿里、腾讯、主做语音的科大讯飞,做只能问答的图灵机器人等等,这些公司投入了很大一部分财力物力人力将底层封装,提供应用接口给我们,尤其是百度,完全免费的接口,既然百度这么仗义,咱们就不要浪费掉怎么好的资源,从百度AI入手,开启人工智能之旅!
开启人工智能技术的大门 : http://ai.baidu.com/
看看我们大百度的AI大法,这些技术全部都是封装好的接口,看着就爽,接下来咱们就一步一步的操作一下,首先进入控制台,注册一个百度的账号(百度账号通用),开通一下我们百度AI开放平台的授权。然后找到已开通服务中的百度语音,如下图:
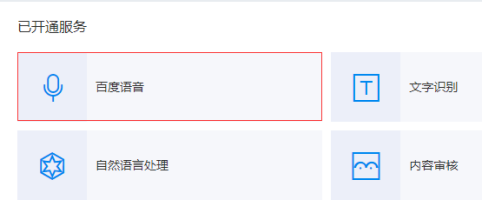
走到这里,想必已经知道咱们要从语音入手了,语音识别和语音合成,打开百度语音,进入语音应用管理界面,创建一个新的应用,如下图:

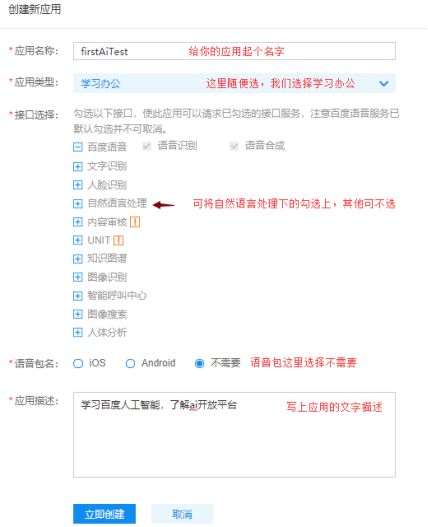
创建应用时可按照如下填写:
创建完成后,回到应用列表我们可以看到已创建的应用了,如下图:

这里面有三个值 AppID , API Key , Secret Key需要记住从这里看,之后的学习中我们会用到。
到此,百度语音的应用已经创建完成了,接下来,我们用Python 代码作为实例进行应用及学习。
使用pip安装百度人工智能的python SDK:
pip3 install baidu-aip
安装后就可以使用如下方式导入:
from aip import AipSpeech
一、语音合成
百度语音合成技术文档: https://ai.baidu.com/docs#/TTS-Online-Python-SDK/top
代码示例:
from aip import AipSpeech
""" 你的 APPID AK SK """
# 这里的三个参数,对应在百度语音创建的应用中的三个参数
APP_ID = '15421088'
API_KEY = 'YLhm87fm7q51a3LqBwG7g4xB'
SECRET_KEY = 'ojzQ40mGhyrzrH9zTkVkEdBbae0F7HyW'
# 这是与百度进行一次加密校验,认证你是合法用户,合法应用
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# AipSpeech 是百度语音的客户端,认证成功之后,客户端将被开启,这里的client 就是已经开启的百度语音的客户端了
# 用百度语音客户端的synthesis方法,并提供相关参数,成功得到音频文件流,否则返回错误信息
result = client.synthesis(
'你叫什么名字?', # text: 合成的文本,utf-8编码,注意长度须小于1024字节
'zh', # lang: 语言,zh代表中文,en代表英文
1, # ctp: 客户端信息,这里就写1,写别的不好使,原因后边解释
{
'vol':5, # 合成音频我呢见的准音量
'spd':3, # 语速,取值0-9,默认为5,中语速
'pit':7, # 语调音调,取值0-9,默认为5,中语调
'per':4 # 发音人选择,0为女声,1为男声,3为情感合成-度逍遥,4为情感合成度丫丫,默认为普通女
}
)
# 若上面三个参数APP_ID,API_KEY,SECRET_KEY填写正确,result就是音频文件的流
# 如果返回失败的话,result就是一个字典
print(result)
if not isinstance(result, dict):
with open('audio.mp3', 'wb') as f:
f.write(result)
二、语音识别
百度语音识别技术文档:http://ai.baidu.com/docs#/ASR-Online-Python-SDK/top
1、语音识别工具
我们一般不对mp3格式的音频文件进行识别,文档中明确指出支持的格式有:pcm(不压缩)、wav(不压缩,pcm编码)、amr(压缩格式),因此,要想让百度的SDK识别我们的音频文件,就要想办法转变成百度SDK可以识别的格式(我们一般用PCM格式)。下面为你介绍一个可以实现自动化转换格式并且屡试不爽的工具 : FFmpeg。
下载地址:https://pan.baidu.com/s/1jonSAa_TG2XuaJEy3iTmHg(提取码:w6hk)。
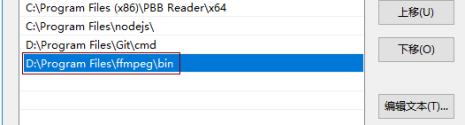
1)将FFmpeg工具压缩包下载后,解压缩,找到bin目录(例如我的目录是D:\Program Files\ffmpeg\bin),将bin目录加入到环境变量,如下图:
2)测试是否配置成功,下图表示成功:
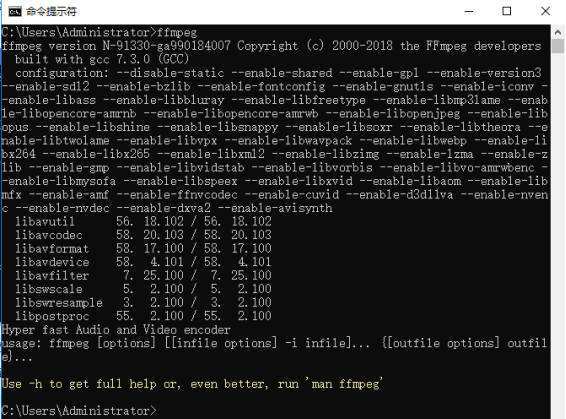
接下来你就可以使用该工具将wav、wma、mp3等音频文件转换为pcm无压缩音频文件了。
3)演示:现在我电脑D:\DragonFireAudio\目录下有个音频文件audio.wav,进行pcm格式的转换得到 audio.pcm,操作如下:
命令:ffmpeg -y -i audio.wav -acodec pcm_s16le -f s16le -ac 1 -ar 16000 audio.pcm
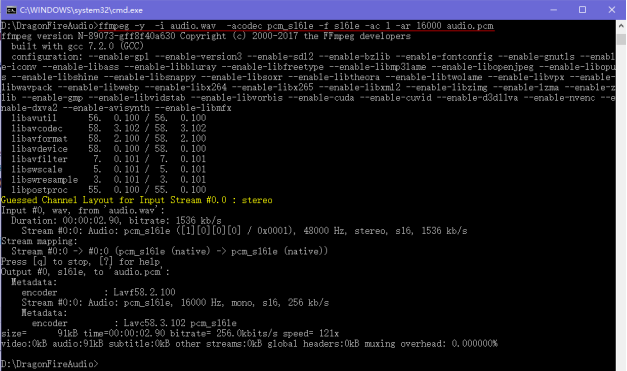
然后打开目录D:\DragonFireAudio\ 就可以看见生成的.pcm文件了。
2、语音识别示例
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '15421088'
API_KEY = 'YLhm87fm7q51a3LqBwG7g4xB'
SECRET_KEY = 'ojzQ40mGhyrzrH9zTkVkEdBbae0F7HyW'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 读取文件
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
# 识别本地文件
res = client.asr(get_file_content('audio.pcm'), 'pcm', 16000, {
'dev_pid': 1536,
})
print(res)
"""
{
'corpus_no': '6646725491143939609',
'err_msg': 'success.',
'err_no': 0,
'result': ['你叫什么名字'],
'sn': '493358299471547561374'
}
"""
print(res.get("result")[0])
# 你叫什么名字
三、图灵机器人
1、创建机器人
1)注册登录账号后,点击创建机器人,填写信息;
2)配置机器人各项参数,按照文档说明使用;
3)API V2.0接入文档地址:https://www.kancloud.cn/turing/www-tuling123-com/718227
2、机器人示例代码
from aip import AipSpeech, AipNlp
import requests
import time
import os
""" 你的 APPID AK SK """
APP_ID = ''
API_KEY = ''
SECRET_KEY = ''
nlp = AipNlp(APP_ID, API_KEY, SECRET_KEY)
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 读取文件
def get_file_content(filePath):
os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm")
with open(f"{filePath}.pcm", 'rb') as fp:
return fp.read()
def audio2text(filepath):
# 识别本地文件
res = client.asr(get_file_content(filepath), 'pcm', 16000, {
'dev_pid': 1536,
})
print(res.get("result")[0])
return res.get("result")[0]
def text2audio(text):
filename = f"{time.time()}.mp3"
result = client.synthesis(text, 'zh', 1, {
'vol': 5,
"spd": 3,
"pit": 7,
"per": 4
})
# 识别正确返回语音二进制 错误则返回dict 参照下面错误码
if not isinstance(result, dict):
with open(filename, 'wb') as f:
f.write(result)
return filename
def to_tuling(text):
args = {
"reqType": 0, # 选填,输入类型:0-文本(默认)、1-图片、2-音频
"perception": { # 必填项,输入信息
# inputText、inputImage、inputMedia三者至少有一个
"inputText": {
"text": text
}
},
"userInfo": { # 必填项,用户参数
"apiKey": "17cec68551c847c59ac48a5a9dd00327", # 必填项
"userId": "1111" # 必填项,用于上下文管理
}
}
# 接口地址
url = "http://openapi.tuling123.com/openapi/api/v2"
res = requests.post(url, json=args)
text = res.json().get("results")[0].get("values").get("text")
print("图灵答案", text)
return text
# 以上内容为web录音玩具中的baidu_ai.py中代码
text = audio2text("bjtq.wma")
if nlp.simnet("你叫什么名字",text).get("score") >= 0.68 :
text = "我的名字叫张三"
else:
text = to_tuling(text)
filename = text2audio(text)
os.system(filename)
四、web录音玩具
注意:以下示例请使用火狐浏览器演示!
manage.py文件:
from flask import Flask,render_template,request,jsonify,send_file
from uuid import uuid4
import baidu_ai # 上面机器人代码为baidu_ai.py文件
app = Flask(__name__)
@app.route("/")
def index():
return render_template("index.html")
@app.route("/ai",methods=["POST"])
def ai():
# 1.保存录音文件
audio = request.files.get("record")
filename = f"{uuid4()}.wav"
audio.save(filename)
# 2.将录音文件转换为PCM发送给百度进行语音识别
q_text = baidu_ai.audio2text(filename)
# 3.将识别的问题交给图灵或自主处理获取答案
a_text = baidu_ai.to_tuling(q_text)
# 4.将答案发送给百度语音合成,合成音频文件
a_file = baidu_ai.text2audio(a_text)
# 5.将音频文件发送给前端播放
return jsonify({"filename":a_file})
@app.route("/get_audio/<filename>")
def get_audio(filename):
return send_file(filename)
if __name__ == '__main__':
app.run("0.0.0.0",9527,debug=True)
index.html文件:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<audio controls autoplay id="player"></audio>
<p>
<button onclick="start_reco()" style="background-color: yellow">录制语音指令</button>
</p>
<p>
<button onclick="stop_reco_audio()" style="background-color: blue">发送语音指令</button>
</p>
</body>
<script type="text/javascript" src="/static/Recorder.js"></script>
<!--<script type="text/javascript" src="https://cdn.bootcss.com/recorderjs/0.1.0/recorder.js"></script>-->
<script type="text/javascript" src="/static/jQuery3.1.1.js"></script>
<script type="text/javascript">
var reco = null;
var audio_context = new AudioContext();
navigator.getUserMedia = (navigator.getUserMedia ||
navigator.webkitGetUserMedia ||
navigator.mozGetUserMedia ||
navigator.msGetUserMedia);
navigator.getUserMedia({audio: true}, create_stream, function (err) {
console.log(err)
});
function create_stream(user_media) {
var stream_input = audio_context.createMediaStreamSource(user_media);
reco = new Recorder(stream_input);
}
function start_reco() {
reco.record();
}
function stop_reco_audio() {
reco.stop();
send_audio();
reco.clear();
}
function send_audio() {
reco.exportWAV(function (wav_file) {
var formdata = new FormData();
formdata.append("record", wav_file);
console.log(formdata);
$.ajax({
url: "http://192.168.13.134:9527/ai",
type: 'post',
processData: false,
contentType: false,
data: formdata,
dataType: 'json',
success: function (data) {
document.getElementById("player").src ="http://192.168.13.134:9527/get_audio/" + data.filename
}
});
})
}
</script>
</html>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号