python学习第三天笔记
深浅拷贝
对于数字和字符串而言,赋值、浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址。
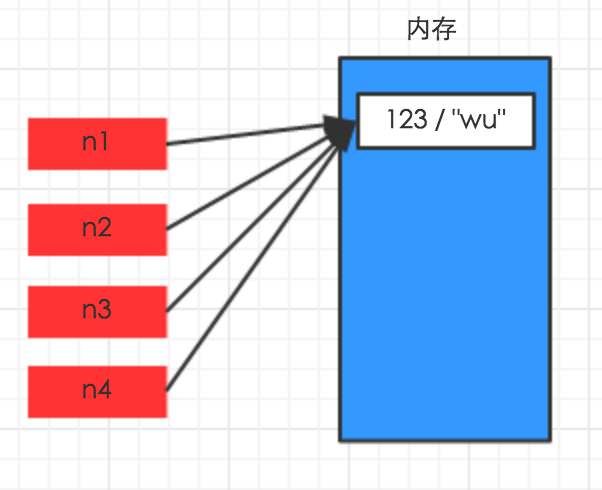
##字符串,数字## a1 =123123 a2 = 123123 print(id(a1)) print(id(a2)) 2201704552752 2201704552752 ##赋值## a1 =123123 a2 =a1 print(id(a1)) print(id(a2)) 2972676872496 2972676872496 ##浅拷贝## a1 =123123 a3 = copy.copy(a1) print(id(a1)) print(id(a3)) 1606903748912 1606903748912 ##深拷贝## a1 =123123 a3 = copy.deepcopy(a1) print(id(a1)) print(id(a3)) 2493814757680 2493814757680
由上面的运行结果可以看出,对于字符串和数字,不管是赋值,浅拷贝,深拷贝,它们的内存地址都是不变的。
对于字典、元祖、列表 而言,进行赋值、浅拷贝和深拷贝时,其内存地址的变化是不同的。
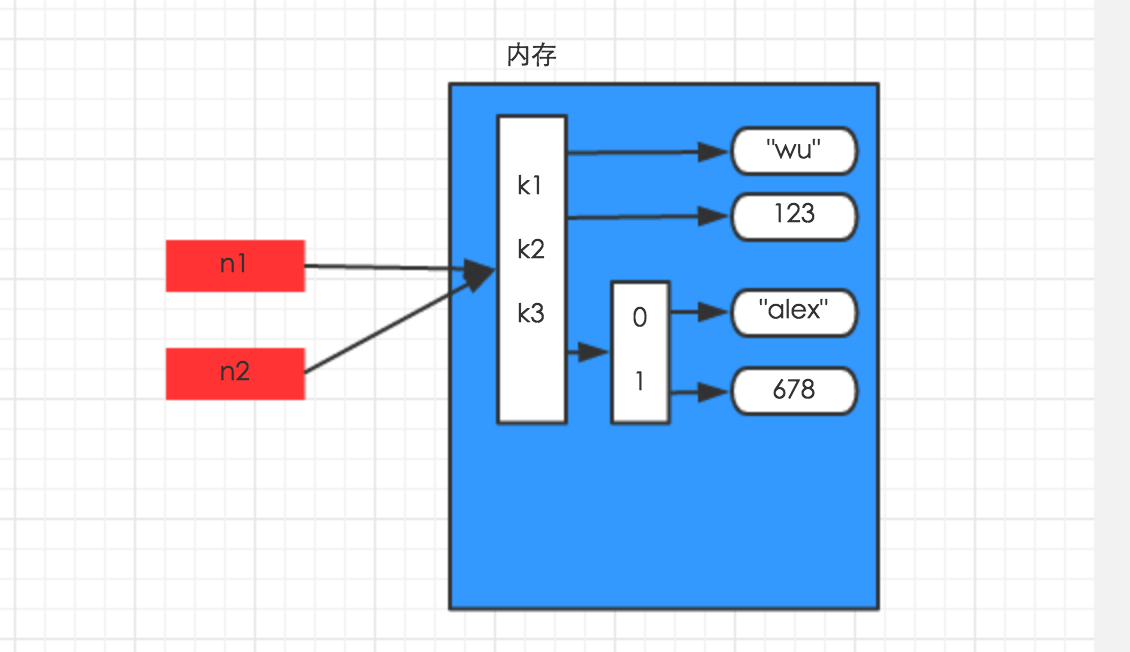
字典赋值:只是创建一个变量,该变量指向原来内存地址
n1 = {"k1": "wu", "k2": 123, "k3": ["jack", 456]}
n2 = n1
print(id(n1))
print(id(n2))
2115007113472
2115007113472
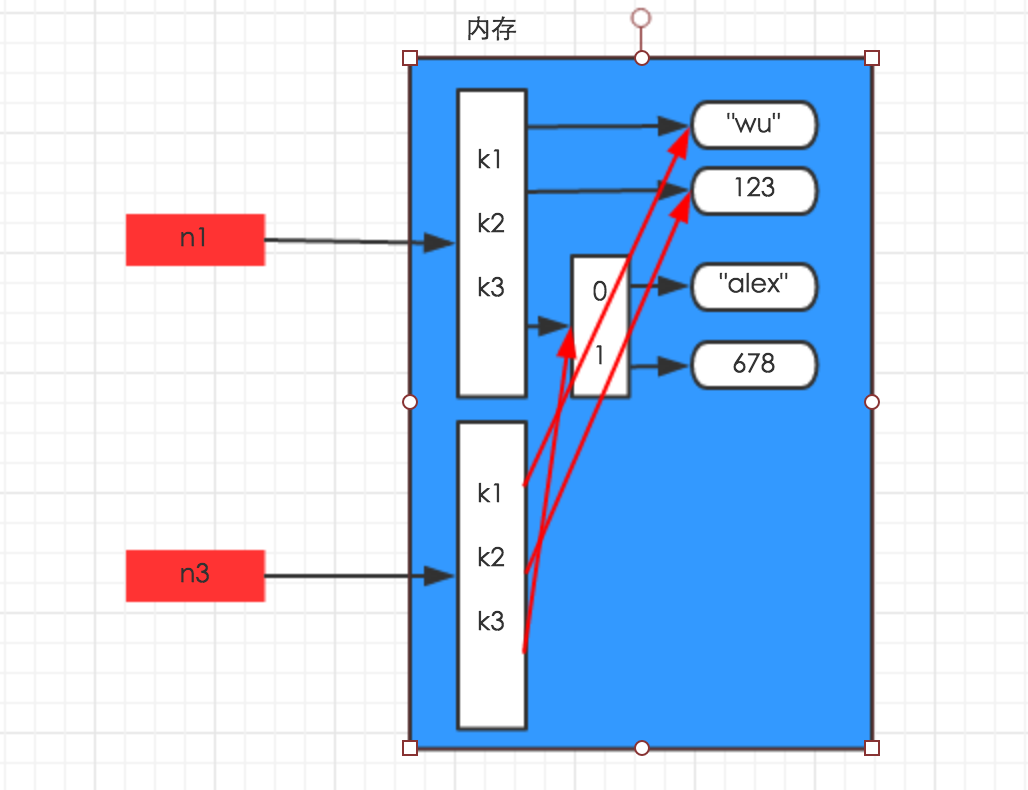
字典的浅拷贝:在内存中只额外创建第一层数据
import copy
n1 = {"k1": "wu", "k2": 123, "k3": ["jack", 456]}
n3 = copy.copy(n1)
print(id(n1))
print(id(n3))
print(id(n1['k3']))
print(id(n3['k3']))
print(id(n1['k3'][0]))
print(id(n3['k3'][0]))
1956545645376
1956545787584
1956545787904
1956545787904
1956545614128
1956545614128
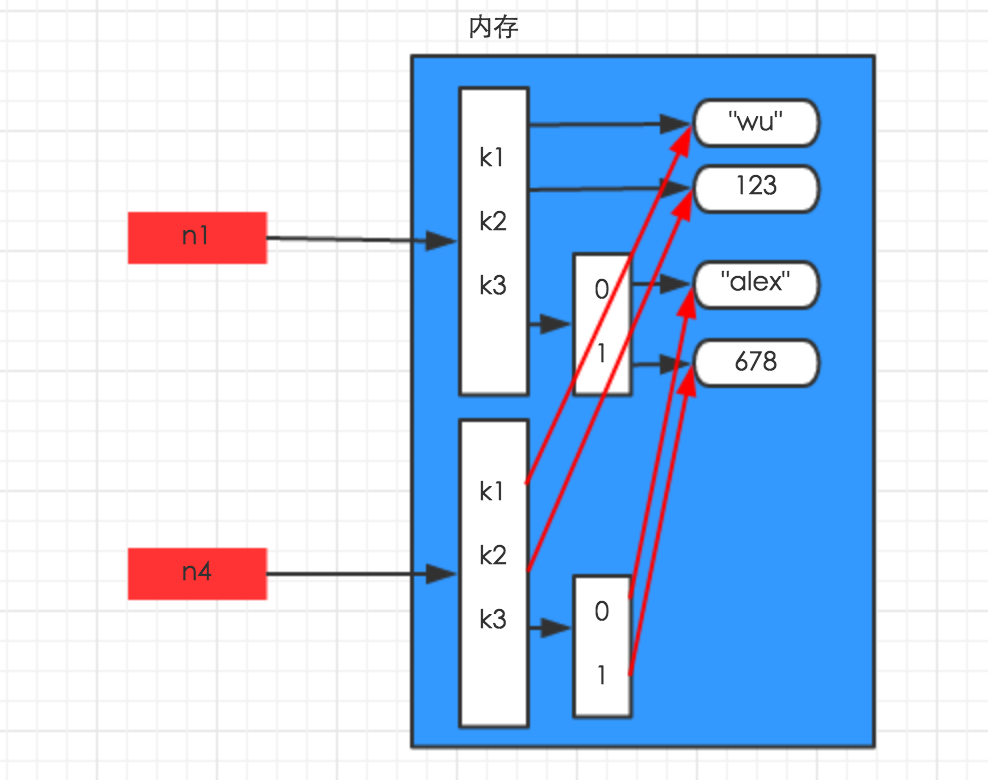
字典的深拷贝:在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)
import copy
n1 = {"k1": "wu", "k2": 123, "k3": ["jack", 456]}
n3 = copy.deepcopy(n1)
print(id(n1))
print(id(n3))
print(id(n1['k3']))
print(id(n3['k3']))
print(id(n1['k3'][0]))
print(id(n3['k3'][0]))
1956545787648
1956545542208
1956545892288
1956539254400
1956545614128
1956545614128
深拷贝的应用:
import copy
dic = {
"cpu":[80],
"mem":[80],
"disk":[80]
}
print('before:',dic)
new_dic = copy.deepcopy(dic)
new_dic['cpu'][0] = 50
print(dic)
print(new_dic)
before: {'cpu': [80], 'mem': [80], 'disk': [80]}
{'cpu': [80], 'mem': [80], 'disk': [80]}
{'cpu': [50], 'mem': [80], 'disk': [80]}
函数
一、背景
在学习函数之前,一直遵循:面向过程编程,即:根据业务逻辑从上到下实现功能,其往往用一长段代码来实现指定功能,开发过程中最常见的操作就是粘贴复制,也就是将之前实现的代码块复制到现需功能处,如下:
while True:
if cpu利用率 > 90%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
if 硬盘使用空间 > 90%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
if 内存占用 > 80%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
再眼一看上述代码,if条件语句下的内容可以被提取出来公用,如下:
def 发送邮件(内容)
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
while True:
if cpu利用率 > 90%:
发送邮件('CPU报警')
if 硬盘使用空间 > 90%:
发送邮件('硬盘报警')
if 内存占用 > 80%:
发送邮件('内存报警')
对于上述的两种实现方式,第二次必然比第一次的重用性和可读性要好,其实这就是函数式编程和面向过程编程的区别:
- 函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可
- 面向对象:对函数进行分类和封装,让开发“更快更好更强...”
函数式编程最重要的是增强代码的重用性和可读性
二、定义和使用
def 函数名(参数):
...
函数体
...
函数的定义主要有如下要点:
- def:表示函数的关键字
- 函数名:函数的名称,日后根据函数名调用函数
- 函数体:函数中进行一系列的逻辑计算,如:发送邮件、计算出 [11,22,38,888,2]中的最大数等...
- 参数:为函数体提供数据
- 返回值:当函数执行完毕后,可以给调用者返回数据。
以上要点中,比较重要有参数和返回值:
1、返回值
函数是一个功能块,该功能到底执行成功与否,需要通过返回值来告知调用者。
def 发送短信():
发送短信的代码...
if 发送成功:
return True
else:
return False
while True:
# 每次执行发送短信函数,都会将返回值自动赋值给result
# 之后,可以根据result来写日志,或重发等操作
result = 发送短信()
if result == False:
记录日志,短信发送失败...
def show():
print('a')
return [11,22]
print('b')
ret = show()
print(ret)
a
[11, 22]
def show():
print('a')
if 1 == 2:
return [11,22]
print('b')
ret = show()
print(ret)
a
b
None
如果函数未定义return返回值,则函数的默认返回未None
2、参数
为什么要有参数?


1 def CPU报警邮件() 2 #发送邮件提醒 3 连接邮箱服务器 4 发送邮件 5 关闭连接 6 7 def 硬盘报警邮件() 8 #发送邮件提醒 9 连接邮箱服务器 10 发送邮件 11 关闭连接 12 13 def 内存报警邮件() 14 #发送邮件提醒 15 连接邮箱服务器 16 发送邮件 17 关闭连接 18 19 while True: 20 21 if cpu利用率 > 90%: 22 CPU报警邮件() 23 24 if 硬盘使用空间 > 90%: 25 硬盘报警邮件() 26 27 if 内存占用 > 80%: 28 内存报警邮件() 29 30 无参数实现
def mail():
n = 123
n += 1
print(n)
return 123
#将函数的返回值赋值给变量
ret = mail()
print(ret)
1 from email.mime.text import MIMEText 2 from email.utils import formataddr 3 import smtplib 4 5 def mail(): 6 ret =123 7 try: 8 msg = MIMEText('邮件内容', 'plain', 'utf-8') 9 msg['From'] = formataddr(["jack、",'发送邮件地址']) 10 msg['To'] = formataddr(["走人",'接收邮件地址]) 11 msg['Subject'] = "主题" 12 13 server = smtplib.SMTP("smtp.sohu.com", 25) 14 server.login("邮件密码", "邮箱密码") 15 server.sendmail('发送邮件地址', ['接收邮件地址,], msg.as_string()) 16 server.quit() 17 except Exception: 18 ret = 456 19 return ret 20 21 ret = mail() 22 print(ret) 23 24 25 123 26 27 结果为123,表示发送邮件成功。
1 from email.mime.text import MIMEText 2 from email.utils import formataddr 3 import smtplib 4 5 def mail(): 6 ret =123 7 try: 8 msg = MIMEText('邮件内容', 'plain', 'utf-8') 9 msg['From'] = formataddr(["jack、",'发送邮件地址']) 10 msg['To'] = formataddr(["走人",'接收邮件地址]) 11 msg['Subject'] = "主题" 12 13 server = smtplib.SMTP("smtp.sohu.com", 25) 14 server.login("邮件密码", "邮箱密码") 15 server.sendmail('发送邮件地址', ['接收邮件地址,], msg.as_string()) 16 server.quit() 17 except Exception: 18 ret = 456 19 return ret 20 21 ret = mail() 22 23 if ret: 24 print("发送成功") 25 else: 26 print("发送失败")
1 def 发送邮件(邮件内容) 2 3 #发送邮件提醒 4 连接邮箱服务器 5 发送邮件 6 关闭连接 7 8 9 while True: 10 11 if cpu利用率 > 90%: 12 发送邮件("CPU报警了。") 13 14 if 硬盘使用空间 > 90%: 15 发送邮件("硬盘报警了。") 16 17 if 内存占用 > 80%: 18 发送邮件("内存报警了。") 19 20 有参数实现
函数的有三中不同的参数:
- 普通参数
- 默认参数
- 动态参数
1 # ######### 定义函数 ######### 2 3 # name 叫做函数func的形式参数,简称:形参 4 def func(name): 5 print name 6 7 # ######### 执行函数 ######### 8 # 'jack 叫做函数func的实际参数,简称:实参 9 func('jack') 10 11 ######输出结果#####3 12 13 jack 14 15 普通参数
1 def func(name, age = 18): 2 3 print "%s:%s" %(name,age) 4 5 # 指定参数 6 func('jack', 19) 7 8 jack:19 9 10 # 使用默认参数 11 func('jack) 12 13 jack:18 14 15 注:默认参数必须要放在参数列表最后 16 17 默认参数
1 def func(*args): 2 print(args,type(args)) 3 4 ##一个*转换为元祖 5 # 执行方式一 6 >>> func(11,22,33,44) 7 (11, 22, 33, 44) <class 'tuple'> 8 9 10 # 执行方式二 11 >>> li = [11,2,2,3,3,4,54] 12 func(*li) 13 (11, 2, 2, 3, 3, 4, 54) <class 'tuple'> 14 15 动态参数-元祖
1 def func(**kwargs): 2 print(kwargs,type(kwargs)) 3 4 5 #两个*则转换为字典 6 # 执行方式一 7 >>> func(name='jack',age=18) 8 {'name': 'jack', 'age': 18} <class 'dict'> 9 10 11 # 执行方式二 12 >>> li = {'name':'jack', 'age':18, 'gender':'male'} 13 func(**li) 14 {'name': 'jack', 'age': 18, 'gender': 'male'} <class 'dict'> 15 16 动态参数-字典
1 def func(*args,**kwargs): 2 print(args,type(args)) 3 print(kwargs,type(kwargs)) 4 # 执行方式一 5 >>> func(11,22,33,44,n1=88,jack='super') 6 (11, 22, 33, 44) <class 'tuple'> 7 {'n1': 88, 'jack': 'super'} <class 'dict'> 8 # 执行方式二 9 >>> l = [11,22,33,44] 10 d = {'n1':'88','jack':'super'} 11 >>> func(*l,**d) 12 (11, 22, 33, 44) <class 'tuple'> 13 {'n1': '88', 'jack': 'super'} <class 'dict'>
使用函数动态参数,实现字符串格式化
def format(*args, **kwargs): # known special case of str.format
"""
S.format(*args, **kwargs) -> str
Return a formatted version of S, using substitutions from args and kwargs.
The substitutions are identified by braces ('{' and '}').
"""
pass
字符串方法format(*args, **kwargs)可以实现字符串格式化。
s = "{0} is {1}"
result = s.format('jack','super')
print(result)
jack is super
####其中的{0}和{1}表示的是索引位置
s1 = "{0} is {1}"
l = ['jack','super']
result = s1.format(*l)
print(result)
jack is super
#元组
s1 = "{name} is {acter}"
result = s1.format(name='jack',acter='super')
print(result)
jack is super
s1 = "{name} is {acter}"
d = {'name':'jack','acter':'super'}
result = s1.format(**d)
print(result)
jack is super
lambda表达式
学习条件运算时,对于简单的 if else 语句,可以使用三元运算来表示,即:
# 普通条件语句
if 1 == 1:
name = 'jack'
else:
name = 'alex'
# 三元运算
name = 'jack' if 1 == 1 else 'alex'
对于简单的函数,也存在一种简便的表示方式,即:lambda表达式
# ###################### 普通函数 ######################
# 定义函数(普通方式)
def func(arg):
return arg + 1
# 执行函数
result = func(99)
# ###################### lambda ######################
# 定义函数(lambda表达式)
my_lambda = lambda arg : arg + 1
# 执行函数
result = my_lambda(99)
lambda存在意义就是对简单函数的简洁表示
内置函数
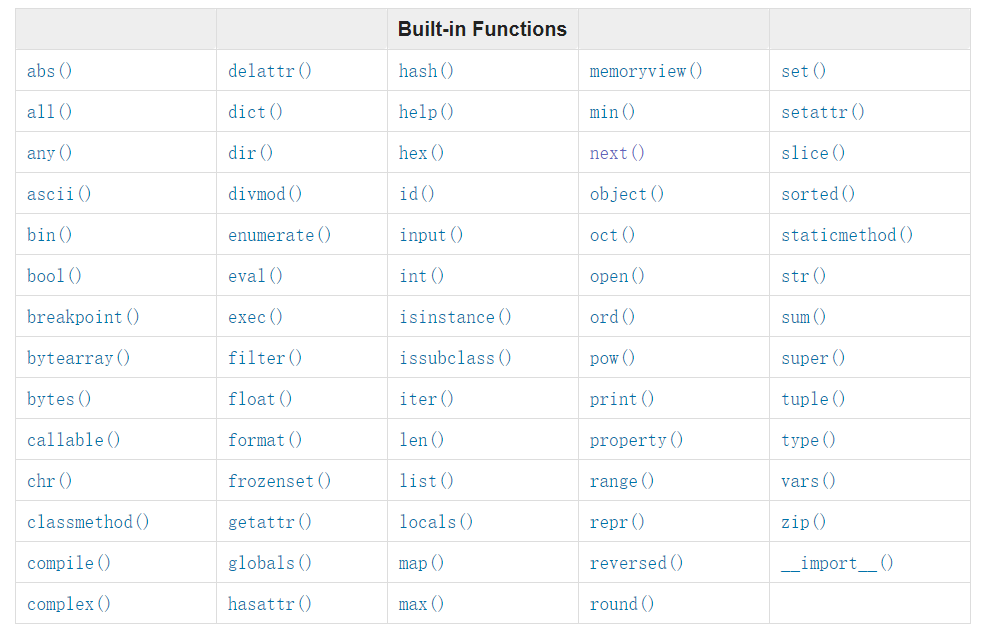
注:查看详细猛击这里
绝对值:abs()
a = -10 ret = abs(a) print(ret) b = 10 ret = abs(b) print(ret)
all()所有元素都为真时,才为真
all([1,2,3,4]) True all(['',]) False
any()所有元素只要有一个为真,就为真
any(["",[],(),{},None])
False
any(["",[],(),{},None,1])
True
ascii(),将字符转换为ascii码,相当于int.__repr__()
ascii('中')
"'\\u4e2d'"
ascii(8)
'8'
自定义类:
class Foo:
def __repr__(self):
return 'bbbb'
f = Foo()
ret = ascii(f)
print(ret)
bin(),Convert an integer number to a binary string prefixed with “0b”.
bin(10) '0b1010'
bool(),判断为True,或False
>>> bool(None)
False
>>> bool('')
False
>>> bool(' ')
True
>>> bool([])
False
>>> bool(())
False
>>> bool({})
False
bytearray()返回字节序列
p = bytearray('dfdf',encoding='utf-8')
print(p)
p = bytearray('郭靖',encoding='utf-8')
print(p)
bytearray(b'dfdf')
bytearray(b'\xe9\x83\xad\xe9\x9d\x96')
p = bytearray([11,22])
print(p)
bytearray(b'\x0b\x16')
bytes(),返回字节对象
p = bytes('郭靖',encoding='utf-8')
print(p)
p = bytes('dfdf',encoding='utf-8')
print(p)
p = bytes([11,22])
print(p)
b'\xe9\x83\xad\xe9\x9d\x96'
b'dfdf'
b'\x0b\x16'
callable()是否可执行
f = lambda x:x+1 f(5) 6 callable(f) True >>> l = [] >>> l() Traceback (most recent call last): File "<input>", line 1, in <module> TypeError: 'list' object is not callable >>> callable(l) False
chr()将数字转换为ascii码对应的字符
>>> chr(99) 'c'
compile()字符串编译成python代码
https://www.cnblogs.com/wupeiqi/articles/4592637.html
complex()复数
dict()创建字典
dic = dict(name='jack',age=20)
print(dic)
{'name': 'jack', 'age': 20}
dir()当前变量所有的keys
dir(list)
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
divmod()相除,得到商和余数组成的元组
ret = divmod(10,3) print(ret,type(ret)) (3, 1) <class 'tuple'>
enumerate(),创建枚举类型
>>> li = ["alex",'eric','lily']
>>> for i in li:print(i)
alex
eric
lily
>>> list(enumerate(li))
[(0, 'alex'), (1, 'eric'), (2, 'lily')]
>>> for i,item in enumerate(li):print(i,item)
0 alex
1 eric
2 lily
>>> for i,item in enumerate(li,1):print(i,item)
1 alex
2 eric
3 lily
#enumerate创造一个迭代器,iterable
li = ["alex",'eric','lily']
def enumerate(sequence, start=0):
n = start
for elem in sequence:
yield n, elem
n += 1
ret = enumerate(li)
# print(type(ret))
print(ret.__next__())
print(ret.__next__())
print(ret.__next__())
(0, 'alex')
(1, 'eric')
(2, 'lily')
eval()将括号内的字符串视为语句并运行
>>> eval("6*8")
48
float,创建一个浮点数字
a = float(10) print(a,type(a)) 10.0 <class 'float'>
内置函数 二
一、map()生成一个map类
遍历序列,对序列中每个元素进行操作,最终获取新的序列。
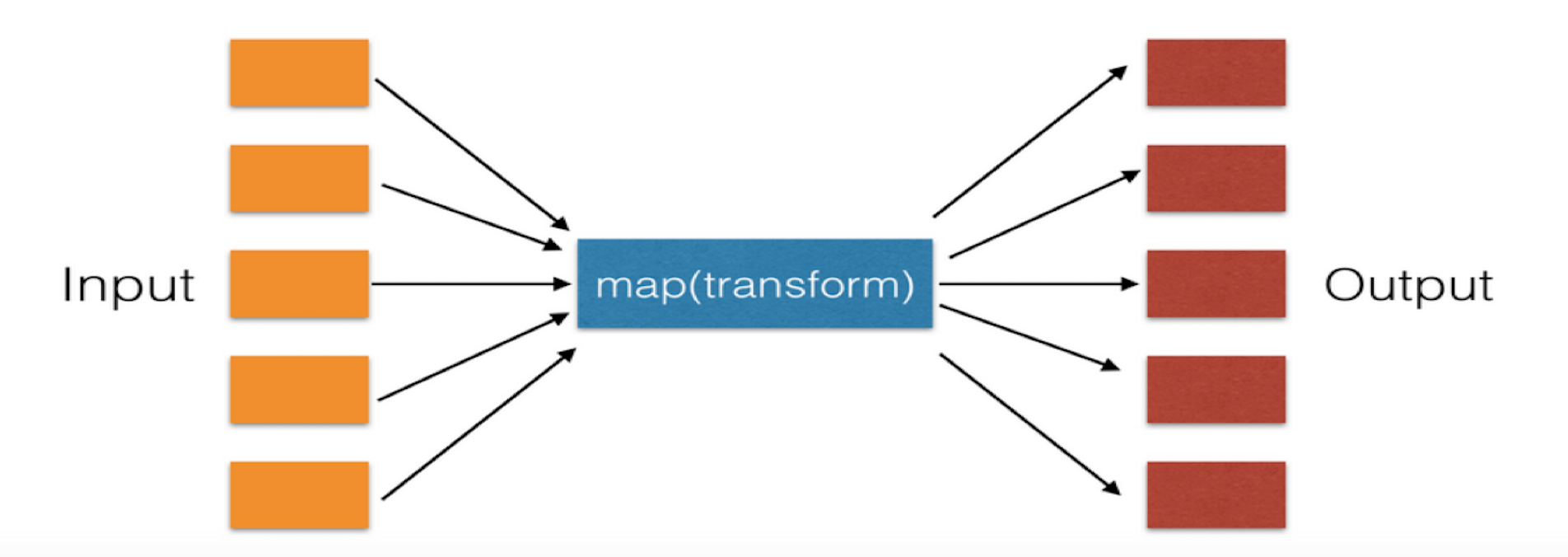
>>> li = [11,22,33,44]
>>> new_li = list(map(lambda x:x+100,li))
>>> new_li
[111, 122, 133, 144]
li = [11,22,33,44]
def func(x):
return x+1
new_li = map(func,li)
print(list(new_li))
二、filter
对于序列中的元素进行筛选,最终获取符合条件的序列
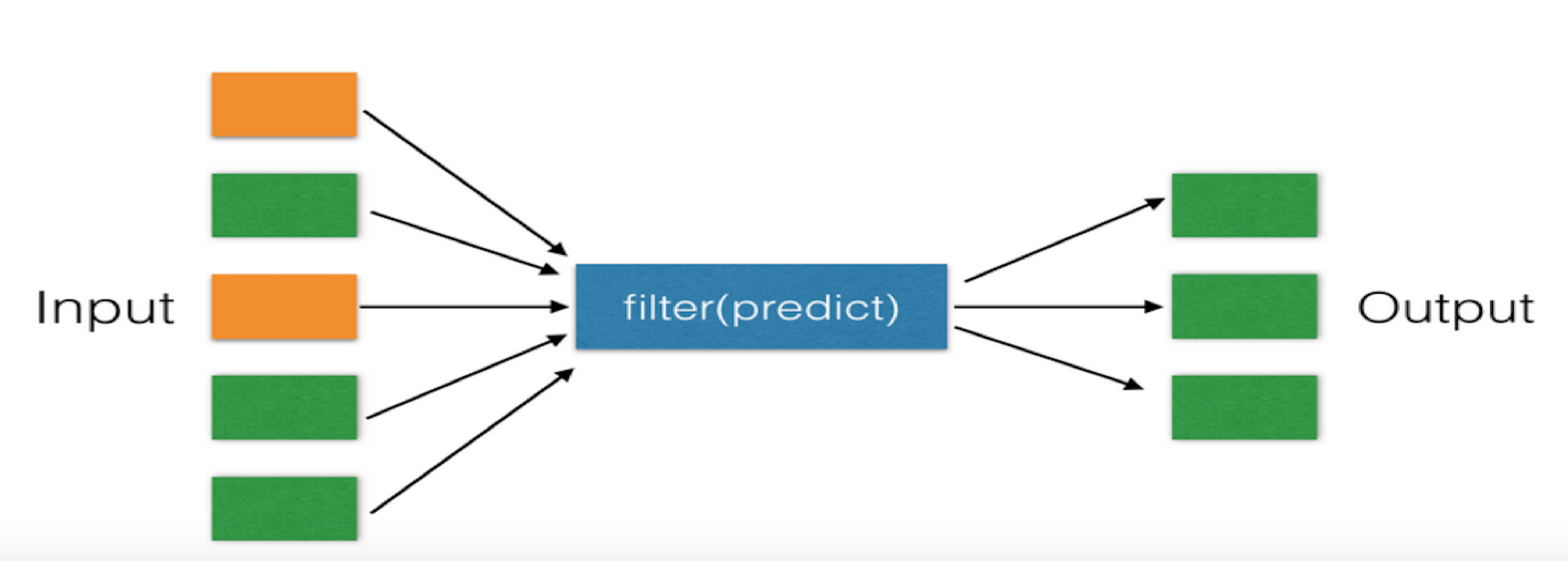
>>> def func(x): ... if x >33: ... return True ... else: ... return False ... >>> li [11, 22, 33, 44] >>> n = filter(func,li) >>> list(n) [44]
只有函数返回为True,才会获取列表
globals(),获取全局变量
help()查看帮助信息
>>> help(list.index)
Help on method_descriptor:
index(self, value, start=0, stop=9223372036854775807, /)
Return first index of value.
Raises ValueError if the value is not present.
hex()获取16进制
>>> hex(100) '0x64'
id()查看object的内存地址
a =10 print(id(a)) 140737042696128
int(),创建一个整型数字
a = int(10.1) print(a,type(a)) 10 <class 'int'>
input()读取用户输入的内容
>>> s = input('Pls input your num:')
print(s)
Pls input your num: 35
35
len()获取长度
li = [11,22,33,44] print(len(li)) 4
list(),创建一个可变的序列,列表
li = list((11,22,33)) print(li,type(li)) [11, 22, 33] <class 'list'>
locals()获取局部变量
min(),获取最小值
>>> mi = min(11,22,67,23,99) >>> print(mi) 11
min(),获取最大值
>>> mx = max(11,22,67,23,99) >>> print(mx) 99
oct()获取八进制
>>> oct(100) '0o144'
pow()数字的幂
>>> print(pow(2,3)) 8
range()创建一个数字序列
>>> for i in range(5):print(i) 0 1 2 3 4
reversed(),创建一个对象的反方向迭代器
li = list((11,33,22,44)) new_li = reversed(li) print(new_li.__next__()) print(new_li.__next__()) print(new_li.__next__()) print(new_li.__next__()) 44 22 33 11
repr(),返回机器可以识别的字符串
round(),返回数字的整数部分
>>> round(8.2) 8 >>> round(8.5) 8
set(),是一个无序且不重复的元素集合
s1 = set()
s1.add('alex')
print(s1)
s1.add('alex')
print(s1)
# 访问速度快
# 天生解决了重复问题
sorted(),对序列进行排序
li = list((11,33,22,44)) new_li = sorted(li) print(new_li,type(new_li)) [11, 22, 33, 44] <class 'list'>
str(),创建一个字符串类对象
a = str(123) print(a,type(a)) 123 <class 'str'>
sum(),计算序列的总和
li = [1,2,3,4,5] ret = sum(li) print(ret) 15
tuple(),创建一个元组
tu = tuple((11,22,33,44)) print(tu,type(tu)) (11, 22, 33, 44) <class 'tuple'>
type(),查看对象的类型
dic = {'name':'jack','age':19}
print(type(dic))
<class 'dict'>
dir(),返回变量所有的key
vars()返回变量所有的key和value
zip()
>>> x = [1,2,3] >>> y = [4,5,6] >>> zipped = zip(x,y) >>> list(zipped) [(1, 4), (2, 5), (3, 6)] >>> x2,y2 = zip(*zip(x,y)) >>> x == list(x2) and y == list(y2) True

 浙公网安备 33010602011771号
浙公网安备 33010602011771号