

第十二章 基于代理的估算
大多数的估算人员都无法只阅读特性的说明就准确地估算出,“那个特性正好需要253行代码。”与之相似,项目需要多少测试用例、预期会出现多少缺陷、最后会有多少个类等问题,都是难以直接估算的。
有一组被称为基于代理的估算方法有助于应对这些挑战。在基于代理的估算中,首先要确定一个与实际要估算的对象相关,但与最终要估算的量相比更容易估算或计数的(或在项目中可以更早获得的)代理(proxy)。例如,如果要估算许多的测试用例,可能就会发现需求的数量和测试用例的数量相关。如果要按照代码行(LOC)来估算规模,可能就会发现按照规模等级区分后的特性数量和代码行数量相关。
只要找到了代理,就可以对代理项的数目进行估算或计数,然后基于历史数据进行计算,将对代理的计数值转换成实际需要的估算值。
12.1 模糊逻辑
名为模糊逻辑(fuzzy logic)的方法可以用来按代码行数估算项目的规模(Putnam and Myers 1992; Humphrey 1995)。估算人员通常能够把特性划分为很小、小、中等、大和很大等不同的等级。然后就可以使用每个很小的特性平均有多少代码行、每个小的特性平均需要多少代码行,等等的历史数据来计算出总代码行数。
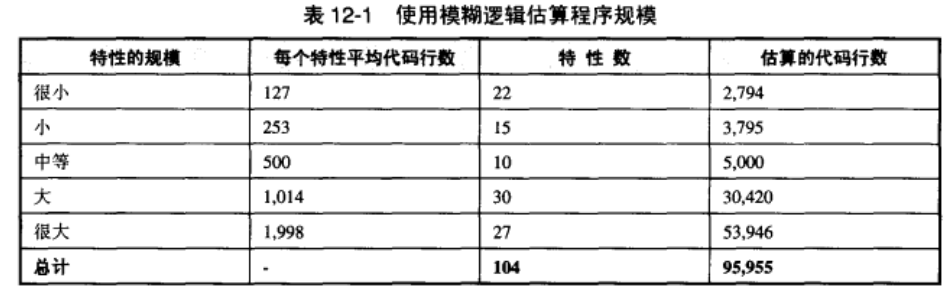
应该在开始估算之前便根据所在开发组织的历史数据,来确定表中 "每个特性平均代码行数" 一栏中的数值。"特性数" 一栏是属于特定规模等级的特性总数。
1)如何获得平均规模数值
模糊逻辑在基于开发组织历史数据进行校准后最有效。根据经验,相邻规模等级之间的差距至少应该是2倍以上。
2)如何对新功能进行分类
在把新功能划分为不同规模等级时,重要的是要保证估算时对功能属于很小、小、中等、大或很大的等级的假设,与先前计算平均规模时的假设保持一致。有三种方法可以达到这一目的:
- 让要进行估算的人进行最初的规模估算;
- 培训估算人员,使其能对特性进行准确的分类;
- 记录划分很小、小、中等、大和很大等规模等级的详细标准,让估算人员可以一致地应用各种规模等级。
3)模糊逻辑不能解决的问题
模糊逻辑方法在需要对20个以上的特性进行估算时很有效。如果要估算的特性总数少于20个,该方法的统计学原理就无法发挥特有的作用,就应该寻找其他方法。
12.2 标准组件
如果要开发很多在架构上相似的程序,就可以使用标准组件(standard component)方法来估算规模。首先要在以前的系统中找到可以计数的相关元素。根据要进行的工作类型的不同,细节会有很多区别。典型的系统中可能包括动态 Web 页面、静态 Web 页面、文件、数据库表、业务规则、图形、显示屏幕、对话框、报表,等等。在确定了哪些是标准组件以后,就可以计算过去的系统中每个组件的平均代码行数。
1)按照百分比使用标准组件
该方法的一个变体是使用百分点而不是组件数目估算值。这时,你还是需要基于足够的历史项目数据来计算出有意义的百分点(至少需要10个历史项目,最好要有接近20个)。如果有足够多的历史数据,就可以对各类组件与均值的偏离情况进行估算,而不只对每类组件估算出一个总数。下表给出了一个这样的参考表。

2)标准组件的局限
标准组件方法的优点在于它的工作量很低,只需要根据直觉来评估新系统中标准组件的规模,然后在参考表中查出相应的条目即可。不过,在建立和维护类似表12-4或12-6所示的参考表时会需要一些工作量的。
标准组件方法不是基于计数的,所以它违背了计数、计算和判断这一普遍原则。但是,它把估算值和某些熟悉的对象联系在一起,所以有些时候它还是有用的。
概括而言,虽然标准组件方法可能不是项目后期可以使用的最好方法,但它可以让创建项目早期估算所需的工作量最小化。由于不确定性锥的影响,项目早期估算结果的错误程度不管怎样做都是很高的。
12.3 故事点
使用故事点时,团队将评审正在考虑构建的用户故事(或者说需求或特性)清单,为每一个故事赋一个规模估算值。
在这个阶段,故事点还不是很有用,因为它们是没有度量单位的度量值,还不能转化为代码行数、人天数或日历时间等特定的数值。在故事点后面的主要思路是,团队将使用相同的尺度一次估算完所有的故事,而且使用的估算方法基本没有偏见。
接下来,团队将计划一次迭代,包括计划交付一定数量的故事点。可以基于将一个故事点换算为特定工作量的假设来进行计划,不过这只是项目早期的一种假设。
完成这次迭代后,团队将具有一些实在的估算能力。团队可以看到交付了多少故事点、花了多少工作量,以及花了多少日历时间。然后,团队可以对如何把故事点换算成工作量和日历时间进行初步的校准。这个换算比例通常被称为速率(velocity)。表 12-10 中给出了一个例子。

显然,表 12-11 中的计算假设项目团队在后续的迭代中将保持不变,而且也没有说明计划对节日、休假,等等的考虑。但是在迭代式项目中,该方法确实可以在很早的时候就根据取自项目本身的历史数据来对整个项目结果提供预测。
还应根据后续迭代的统计数据对最初的项目整体估算进行修正。每次迭代的时间越短,就可以越早获得能用于项目剩余部分估算的数据,并且这些估算的置信度也越高。
12.4 'T恤' 式规模估算
非技术领域的干系人通常不会要求获得用人时表示的估算值。他们只是希望能够知道某个特性所需工作量的规模是一只老鼠、一只兔子、一条狗还是一头大象(即估算特性的相对规模)。这一观测结论可以引出一种名为T恤衫式规模估算(T-shirt sizing)的很有用的估算方法。
在T恤衫式规模估算方法中,开发人员根据每个特性的规模相对其他特性的情况把它划分到低、中、高或超高的等级。同时,客户、营销人员、销售人员或其他非技术领域的干系人会同样根据每个特性的业务价值划分出这些等级。然后,按照表12-13那样组合这两组数值。

在业务价值和开发成本之间建立这样的联系让非技术领域的干系人可以说:“因为特性B的价值‘低’,所以如果它的成本‘高’,就不要这个特性。”因此在该特性的生命周期的早期就可以做出这种很有用的决策。如果继续对该特性进行详细需求分析、架构、设计等其他工作,可能最终会在成本不合算的特性上投入过多的工作。在软件开发中,能够迅速得到否定的答案具有很高的价值。T恤衫式规模估算的方法允许通过项目早期的决策排除一些特性,这样就不用让这些特性延续到不确定性锥中更远的地方,浪费更多的成本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号