

前端面试更新
1:实现一个函数,判断输入是不是回文字符串。(回文:正读反读一样)

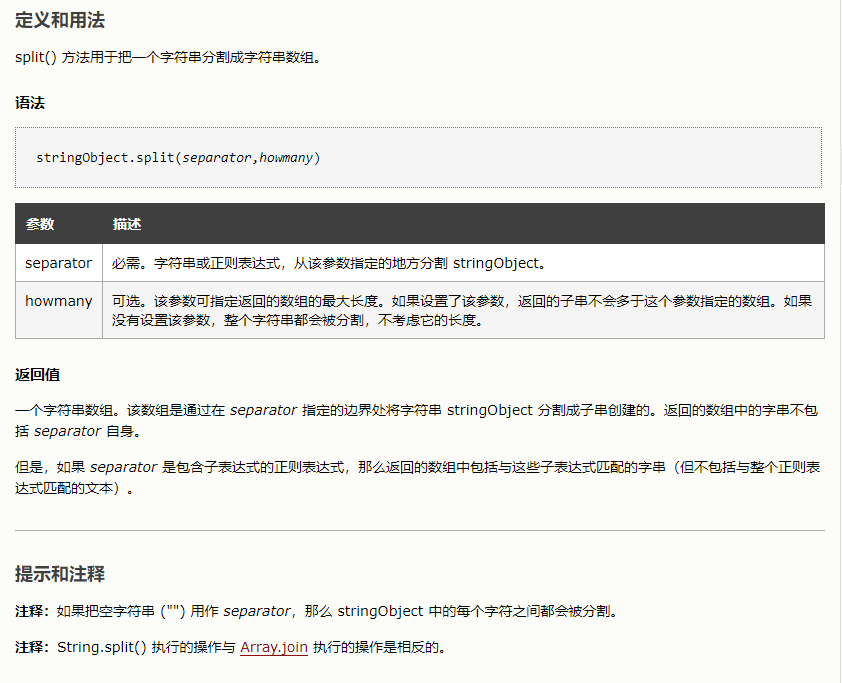
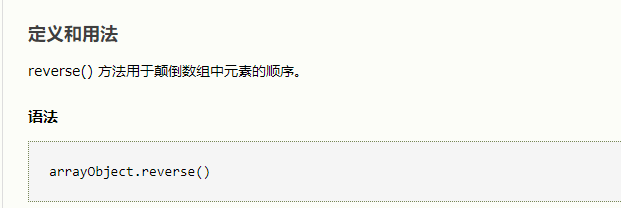
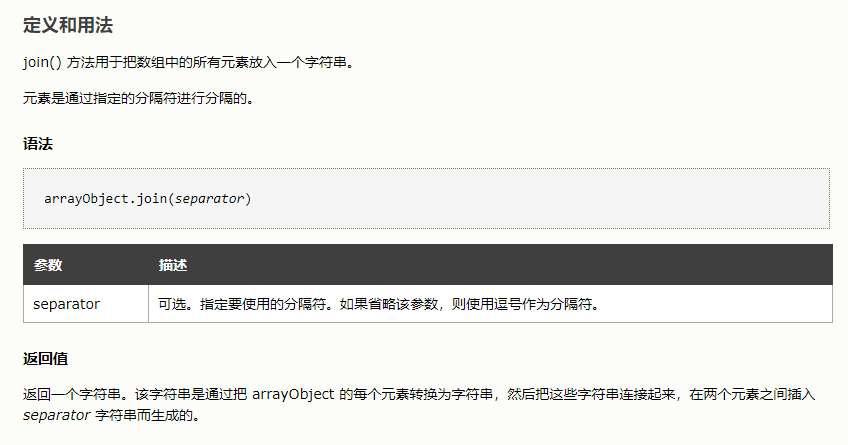
先用split将字符串分割成数组,之后用reverse将数组中元素的顺序颠倒过来,最用用join再将数组拼接成字符串,判断与输入值是否相等,相等则为回文。


2:两种以上方式实现已知或者未知宽度的垂直水平居中。
第一种方法:

top属性可以使得元素向下偏移的。但是,由于默认情况下,由于position的值为static(静止的、不可以移动的),元素在文档流里是从上往下、从左到右紧密的布局的,我们不可以直接通过top、left等属性改变它的偏移。所以,想要移动元素的位置,就要把position设置为不是static的其他值,如relative,absolute,fixed等。然后,就可以通过top、bottom、right、left等属性使它在文档中发生位置偏移(注意,relative是不会使元素脱离文档流的,absolute和fixed则会!也就是说,relative会占据着移动之前的位置,但是absolute和fixed就不会)
第二种方法:

有关flex布局可以链接到:http://www.ruanyifeng.com/blog/2015/07/flex-grammar.html
第三种方法(不推荐):
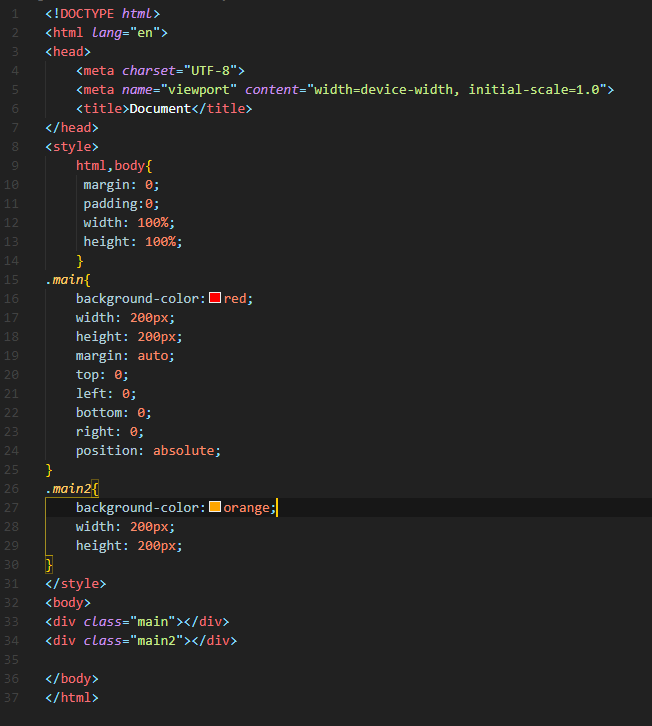
1.为块区域设置top: 0; left: 0; bottom: 0; right: 0;将给浏览器重新分配一个边界框,此时该块块将填充其父元素的所有可用空间,所以margin 垂直方向上有了可分配的空间,否则垂直方向无效。
因为在垂直方向上,块级元素不会自动扩充,它的外部尺寸没有自动充满父元素,也没有剩余空间可说。所以margin:auto不能实现垂直居中。通过position:absolute 和 top:0 bottom:0将元素设为流体特性的元素,这样该元素可自动填充父级元素的可用尺寸。
2.再设置margin 垂直方向上下为auto,即可实现垂直居中。(注意高度得设置)。
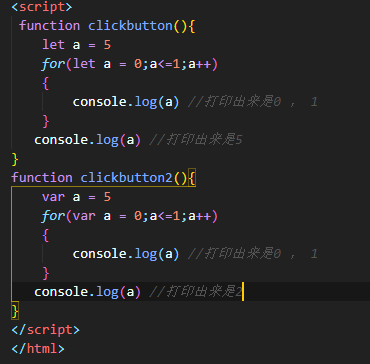
3:let和var的对比。
4:js防抖节流

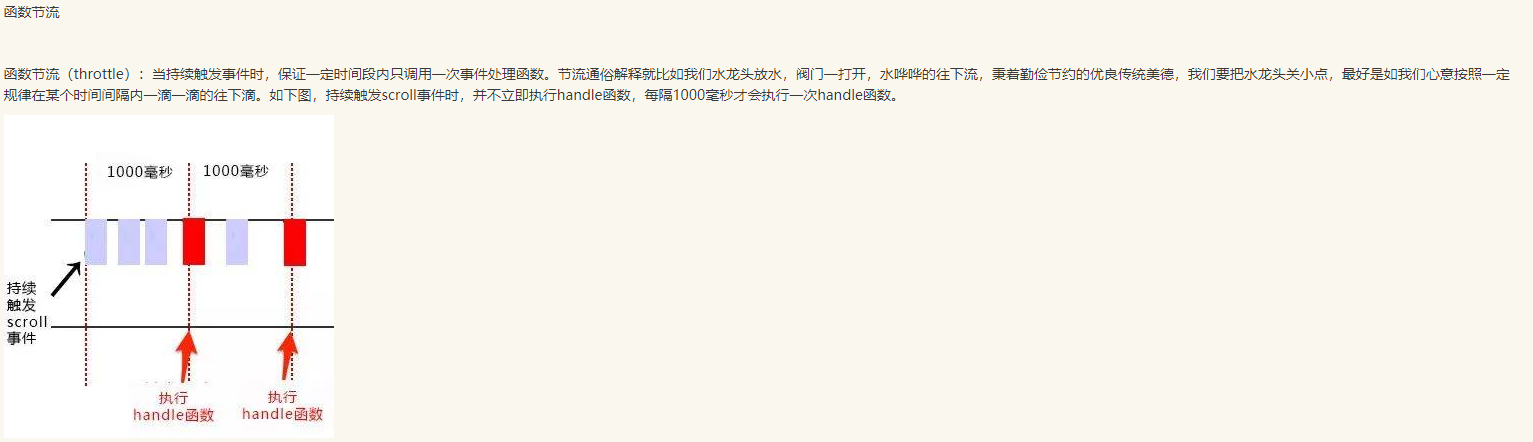
总结
函数防抖:将几次操作合并为一此操作进行。原理是维护一个计时器,规定在delay时间后触发函数,但是在delay时间内再次触发的话,就会取消之前的计时器而重新设置。这样一来,只有最后一次操作能被触发。
函数节流:使得一定时间内只触发一次函数。原理是通过判断是否到达一定时间来触发函数。
区别: 函数节流不管事件触发有多频繁,都会保证在规定时间内一定会执行一次真正的事件处理函数,而函数防抖只是在最后一次事件后才触发一次函数。 比如在页面的无限加载场景下,我们需要用户在滚动页面时,每隔一段时间发一次 Ajax 请求,而不是在用户停下滚动页面操作时才去请求数据。这样的场景,就适合用节流技术来实现。
5.IE盒模型和标准盒模型的比较
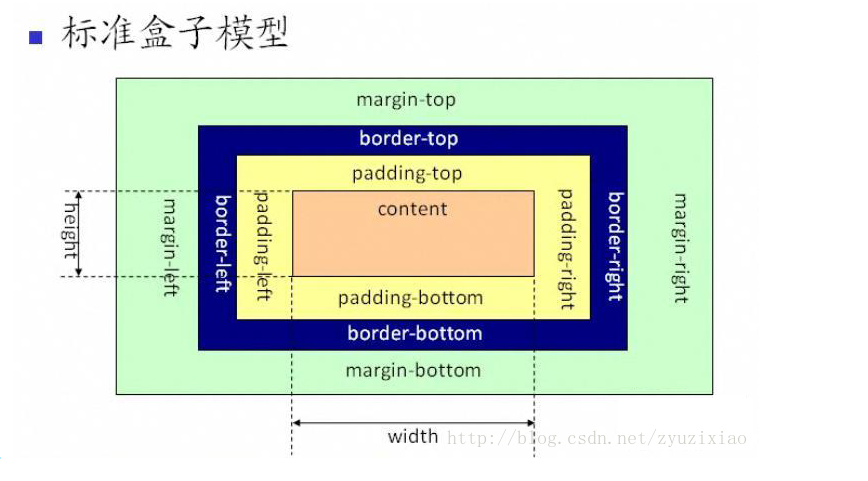
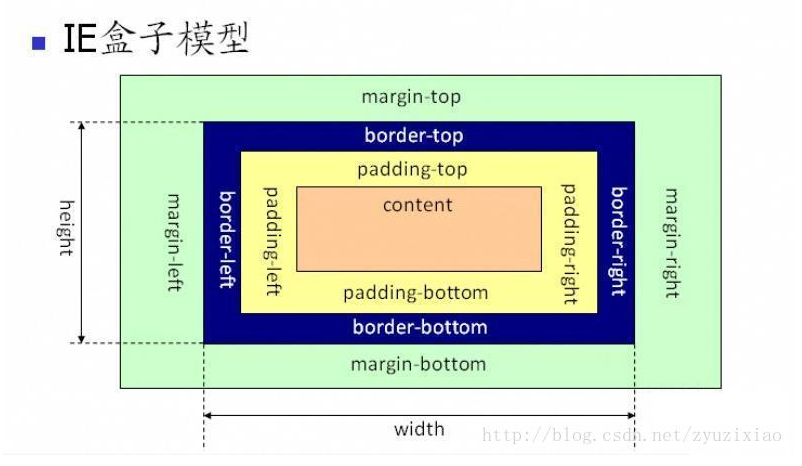
总结:从上图可以看到 IE 盒子模型的范围也包括 margin、border、padding、content,和标准 W3C 盒子模型不同的是:IE 盒子模型的 content 部分包含了 border 和 padding。
6.hash模式和history模式的不同
对于vue这类渐进式前端开发框架,为了构建 SPA(单页面应用),需要引入前端路由系统,这也就是 Vue-Router 存在的意义。前端路由的核心,就在于 —— 改变视图的同时不会向后端发出请求。
为了达到这一目的,浏览器当前提供了以下两种支持:
- hash —— 即地址栏 URL 中的 # 符号(此 hash 不是密码学里的散列运算)。比如这个 URL:http://www.abc.com/#/hello,hash 的值为 #/hello。它的特点在于:hash 虽然出现在 URL 中,但不会被包括在 HTTP 请求中,对后端完全没有影响,因此改变 hash 不会重新加载页面。
- history —— 利用了 HTML5 History Interface 中新增的 pushState() 和 replaceState() 方法。(需要特定浏览器支持)这两个方法应用于浏览器的历史记录栈,在当前已有的 back、forward、go 的基础之上,它们提供了对历史记录进行修改的功能。只是当它们执行修改时,虽然改变了当前的 URL,但浏览器不会立即向后端发送请求。
- 因此可以说,hash 模式和 history 模式都属于浏览器自身的特性,Vue-Router 只是利用了这两个特性(通过调用浏览器提供的接口)来实现前端路由.
-
不过history的这种模式需要后台配置支持。比如:当我们进行项目的主页的时候,一切正常,可以访问,但是当我们刷新页面或者直接访问路径的时候就会返回404,那是因为在history模式下,只是动态的通过js操作window.history来改变浏览器地址栏里的路径,并没有发起http请求,但是当我直接在浏览器里输入这个地址的时候,就一定要对服务器发起http请求,但是这个目标在服务器上又不存在,所以会返回404
怎么解决呢?我们现在可以把所有请求都转发到 http://localhost:8080/index.html上就可以了。
-
总结
1 hash 模式下,仅 hash 符号之前的内容会被包含在请求中,如 http://www.abc.com,因此对于后端来说,即使没有做到对路由的全覆盖,也不会返回 404 错误。
2 history 模式下,前端的 URL 必须和实际向后端发起请求的 URL 一致,如 http://www.abc.com/book/id。如果后端缺少对 /book/id 的路由处理,将返回 404 错误。Vue-Router 官网里如此描述:“不过这种模式要玩好,还需要后台配置支持……所以呢,你要在服务端增加一个覆盖所有情况的候选资源:如果 URL 匹配不到任何静态资源,则应该返回同一个 index.html 页面,这个页面就是你 app 依赖的页面。”
3 结合自身例子,对于一般的 Vue + Vue-Router + Webpack + XXX 形式的 Web 开发场景,用 history 模式即可,只需在后端(Apache 或 Nginx)进行简单的路由配置,同时搭配前端路由的 404 页面支持。
7.前端跨域主流方案
1.CORS(跨域资源共享)
CORS需要浏览器和服务器同时支持。目前,所有浏览器都支持该功能,IE浏览器不能低于IE10。
整个CORS通信过程,都是浏览器自动完成,不需要用户参与。对于开发者来说,CORS通信与同源的AJAX通信没有差别,代码完全一样。浏览器一旦发现AJAX请求跨源,就会自动添加一些附加的头信息,有时还会多出一次附加的请求,但用户不会有感觉。
因此,实现CORS通信的关键是服务器。只要服务器实现了CORS接口,就可以跨源通信。
在响应头上添加Access-Control-Allow-Origin属性,指定同源策略的地址。同源策略默认地址是网页的本身。只要浏览器检测到响应头带上了CORS,并且允许的源包括了本网站,那么就不会拦截请求响应。
8.回调地狱
1.后一次的请求需要用到前一次请求返回的结果时,由于是异步,不确定哪个先执行完成,导致后一次的代码逻辑需要嵌套在上一次的代码中,如果有大量的异步操作,会使得代码嵌套多层,及其混乱,产生“回调地狱”
2.ES6中引入的promise,其本质就是为了解决回调地狱问题。 同时Promise常用的三种方法 then 表示异步成功执行后的数据状态变为reslove catch 表示异步失败后执行的数据状态变为reject all表示把多个没有关系的Promise封装成一个Promise对象使用then返回一个数组数据
3.ES7中引入的async 和 await 是目前解决异步回调地狱的终极解决方法。在异步函数前加async,表明这是一次异步操作。在调用需要等待返回数据的接口时,前面加上await,表明等待这个异步所返回的数据,这样写代码可以使异步看起来更像是同步。
9.web安全
1.token令牌
目前比较完善的解决方案是加入Anti-CSRF-Token。即发送请求时在HTTP 请求中以参数的形式加入一个随机产生的token,并在服务器建立一个拦截器来验证这个token。服务器读取浏览器当前域cookie中这个token值,会进行校验该请求当中的token和cookie当中的token值是否都存在且相等,才认为这是合法的请求。否则认为这次请求是违法的,拒绝该次服务。
这种方法相比Referer检查要安全很多,token可以在用户登陆后产生并放于session或cookie中,然后在每次请求时服务器把token从session或cookie中拿出,与本次请求中的token 进行比对。由于token的存在,攻击者无法再构造出一个完整的URL实施CSRF攻击。
2.验证码
应用程序和用户进行交互过程中,特别是账户交易这种核心步骤,强制用户输入验证码,才能完成最终请求。在通常情况下,验证码够很好地遏制CSRF攻击。但增加验证码降低了用户的体验,网站不能给所有的操作都加上验证码。所以只能将验证码作为一种辅助手段,在关键业务点设置验证码。
10.前端性能优化
1.尽量压缩css和js文件。开启gzip压缩
2.采用图片的懒加载(延迟加载)
目的为了,减少页面第一次加载过程中http的请求次数
具体步骤:
1、页面开始加载时不去发送http请求,而是放置一张占位图
2、当页面加载完时,并且图片在可视区域再去请求加载图片信息
3.能用css做的效果,不要用js做,能用原生js做的,不要轻易去使用第三方插件。
避免引入第三方大量的库。而自己却只是用里面的一个小功能
4.ui组件的按需引入。
5.图标等小型标志性的图片可以使用精灵图,只需要加载一张图片,选取不同的位置让图片展示,避免重复的加载。
6. 减少dom操作
操作dom会产生几种动作,极大的影响渲染的效率。其中layout(布局)和paint(绘制)是最大的。
1、layout就是布局变动造成重新计算(耗CPU,有时也很耗内存)。
2、paint就是调用浏览器UI引擎进行渲染展示页面(耗cpu和内存)。
解决:可以使用虚拟DOM不会进行排版与重绘操作。
1、虚拟DOM进行频繁修改,然后一次性比较并修改真实DOM中需要改的部分,最后并在真实DOM中进行排版与重绘,减少过多DOM节点排版与重绘,减少过多DOM节点排版与重绘损耗。
2、真实DOM频繁排版与重绘的效率是相当低的。
3、虚拟DOM有效降低大面积(真实DOM节点)的重绘与排版,因为最终与真实DOM比较差异,可以只渲染局部。
11.一个页面从输入url到页面加载完成究竟经历了些什么
1、浏览器向DNS服务器请求解析www.tsinghua.edu.cn的IP地址;
具体来说:
浏览器调用解析程序,并成为DNS服务器的一个客户,把待解析域名放在DNS请求报文中,以UDP用户数据报方式发给本地域名服务器,(使用UDP是为了减少开销)。本地域名服务器在查找域名后,把对应的IP地址放在响应报文中返回。如果本地域名服务器无法查找到对应域名,那么该域名服务器就成为DNS中的另一个客户,并向其他域名服务器发出查询请求。这种过程直到找到能够回答该请求的域名服务器为止。
2、DNS解析出清华大学服务器对应的IP地址为166.111.4.100并将查询结果告诉浏览器;
3、浏览器采用三次握手与服务器建立TCP连接(在服务器端IP地址是166.111.4.100,端口是80);
4、浏览器发出HTTP请求报文;
5、服务器发送HTTP响应报文;
无论请求报文和响应报文都分为三部分:起始行、头部、主体部分。请求报文的起始行说明了要做些什么,响应报文的起始行则说明发生了什么。首部字段向请求或者响应报文中添加一些附加信息,他们是一些名/值对的列表。主体部分可选,它是HTTP真正要传输的内容。
服务器在响应报文的主体部分携带了HTML代码,用于浏览器进行页面渲染。
6、释放TCP连接
7、浏览器依据服务器传来的响应报文(主体部分)数据从上到下解析HTML代码,在<head>部分获取到CSS,然后后开始渲染页面;
如果link标签引入的外部样式表放在<body>底部,由于从上到下解析,一开始不会显示元素样式,直到解析到link部分的CSS才会重新渲染页面;
如果网速较慢,html代码加载完成后而css还没加载完的话,这会导致页面没有样式而难以阅读,所以不推荐这种方式
8、当浏览器在HTML代码中发现对一些资源的引用时(如<img>标签引用了一张图片),浏览器向服务器发出异步请求获取这些资源。此时浏览器不会等到资源下载完,而是继续渲染后面的代码;
9、服务器返回浏览器需要的资源,浏览器回过头来重新渲染该部分代码;
10、当浏览器发现包含JavaScript代码的<script>标签时,立即执行它;如果JavaScript脚本命令改变前面的布局或者样式,浏览器不得不重新渲染这部分代码;
11、</html>页面渲染完毕。
12.TCP三次握手
第一次握手
客户主动(active open)去connect服务器,并且发送SYN 假设序列号为J,
服务器是被动打开(passive open)
第二次握手
服务器在收到SYN后,它会发送一个SYN以及一个ACK(应答)给客户,
ACK的序列号是 J+1表示是给SYN J的应答,新发送的SYN K 序列号是K
第三次握手
客户在收到新SYN K, ACK J+1 后,也回应ACK K+1 以表示收到了,
然后两边就可以开始数据发送数据了
目的:三次握手的目的是同步连接双方的序列号和确认号并交换 TCP 窗口大小信息。
13.cookie 与 localStorage ,SessionStorage的区别
- 大小区别
- cookie 支持的数据内容小,8k 左右。localStorage 目前能支持到 10M.
- cookie 不能跨域访问,作为 http 请求的一部分,无意中增加带宽。
- localStorage 本地持久化。
- 使用区别
- Web Storage 拥有 setItem,getItem,removeItem,clear 等方法
- 不像 cookie 需要前端开发者自己封装 setCookie,getCookie。
- localStorage 适用于长期存储数据,浏览器关闭后数据不丢失
- sessionStorage 存储的数据在浏览器关闭后自动删除
- cookie 数据始终在同源的 http 请求中携带(即使不需要),即 cookie 在浏览器和服务器间来回传递。
- 而 sessionStorage 和 localStorage 不会自动把数据发给服务器,仅在本地保存。
- cookie 数据还有路径(path)的概念,可以限制 cookie 只属于某个路径下。
-
- cookie 在浏览器和服务器间来回传递。
- sessionStorage 和 localStorage 不会
- sessionStorage 和 localStorage 的存储空间更大;
- sessionStorage 和 localStorage 有更多丰富易用的接口;
- sessionStorage 和 localStorage 各自独立的存储空间;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号