
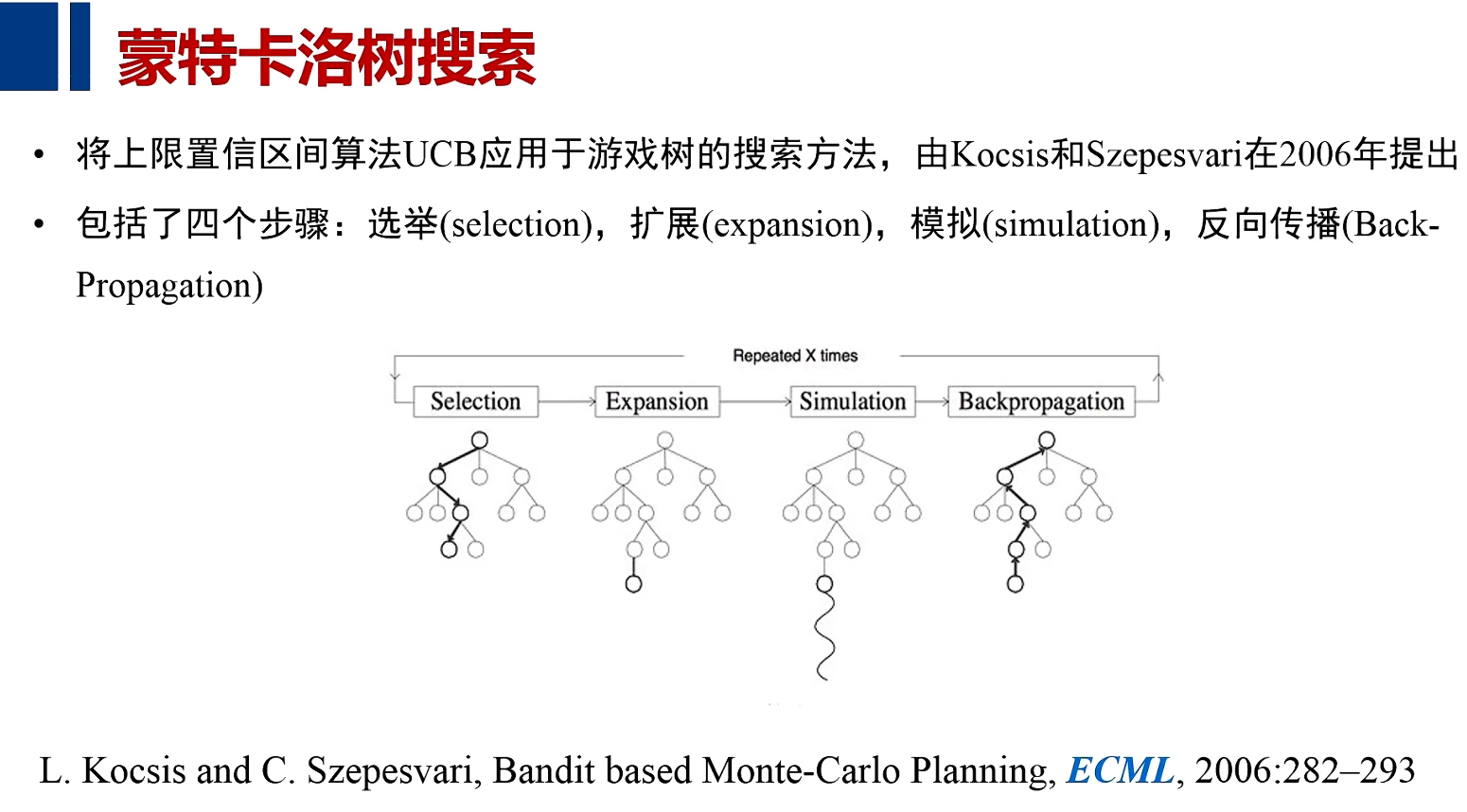
蒙特卡洛树搜索
蒙特卡洛树搜索
课程链接:人工智能导论:08搜索求解算法:蒙特卡洛树搜索|AI入门必学课程_哔哩哔哩_bilibili
参考材料:


单一状态蒙特卡洛规划:多臂赌博机(multi-armed bandits)


注:实际上悔值函数并不存在;
上限置信区间(Upper Confidence Bound,UCB)

注:
(1) s指在过去t-1时刻被摇动的臂膀的次数,即在过去t-1时刻某一个赌博机被选择了几次;
(2) t指在过去时刻总共选择了多少次赌博机;
(3) Ct,s取值的意义在于如果某一个赌博机被摇动的次数越少(s值越小),这Ct,s的取值越大;这说明我们希望去摇动那些在过去时刻没有产生任何回报,但是在未来可能带来比现在的某个赌博机带来更大的回报的一个赌博机;
(4) UCB算法体现了探索和利用的平衡;
(5) 利用指的是在t时刻,我们尽可能去选择t-1时刻已经发生的那些摇动赌博机里已经给我们带来平均回报的最大的那个赌博机;
(6) 探索指的是要尽量去选择那些现在带来的回报值很小或没有的那些赌博机,因为他在未来可能带来比现在的某个赌博机更大的回报;


假设有k个赌博机,初始化时,每个赌博机都拉动依次臂膀,于是每个赌博机都产生了本次的回报,当每个赌博机依次拉动依次臂膀之后,下一时刻当拉动具有最大的UCB值的赌博机。
蒙特卡洛树搜索
步骤
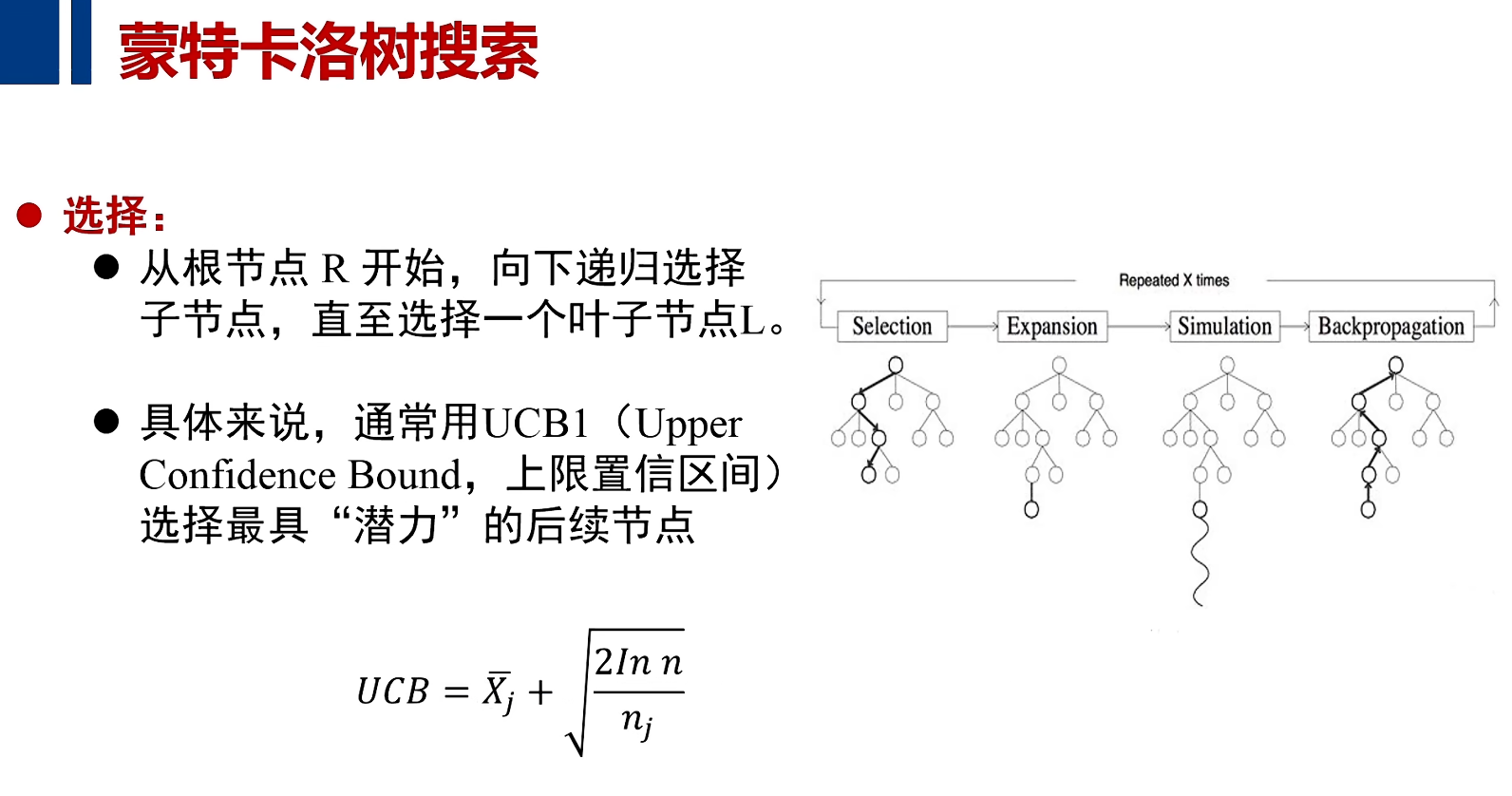
注:UCB是一种序列学习的选择机制
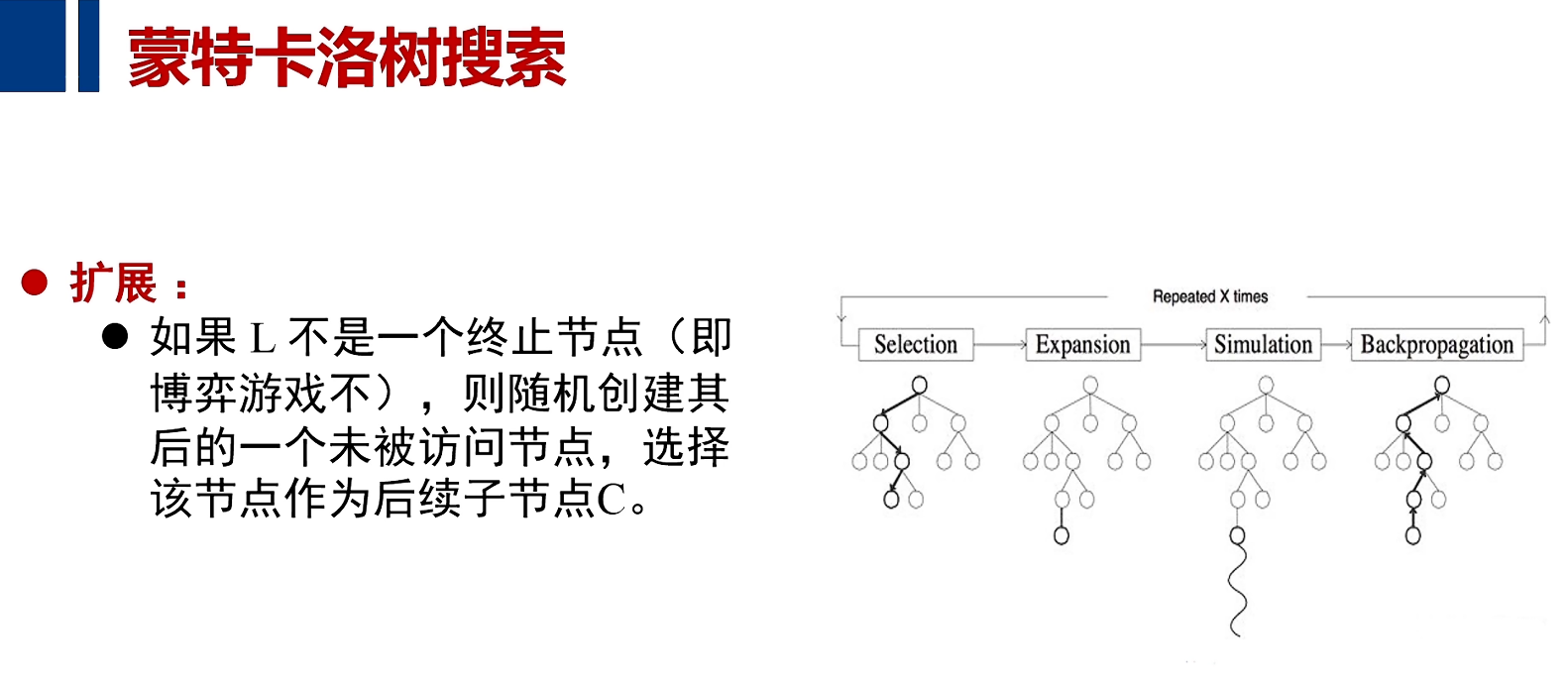

一旦选择随机产生了某个未被扩展的节点后,从该节点出发,对游戏进行模拟,直到博弈结束,之后我们就会知道这样博弈的路径到底是胜利还是失败,然后我们记录下模拟胜利或失败的结果,并选择这个胜利和失败路径上的所有的节点,把失败或胜利的信息向上反向传播回去,让每个节点记录下来(经过我这一节点所选择的路径,到底是导致了本次对决的胜利,还是导致本次对决的失败)
策略学习机制

搜索树策略:从根节点出发,用UCB算法,在已经展开的游戏树上向下递归寻找那些潜在的最有潜力的子节点直到到达本游戏树的叶子节点,然后随机产生一个未被访问的节点;
模拟策略指从拓展出来的节点出发,进行游戏的仿真,一直到游戏的结束,来判定按照这样的路径进行拓展之后,游戏的策略到底是赢还是输,然后再把赢和输的信息向上返溯,传递回去;
例子
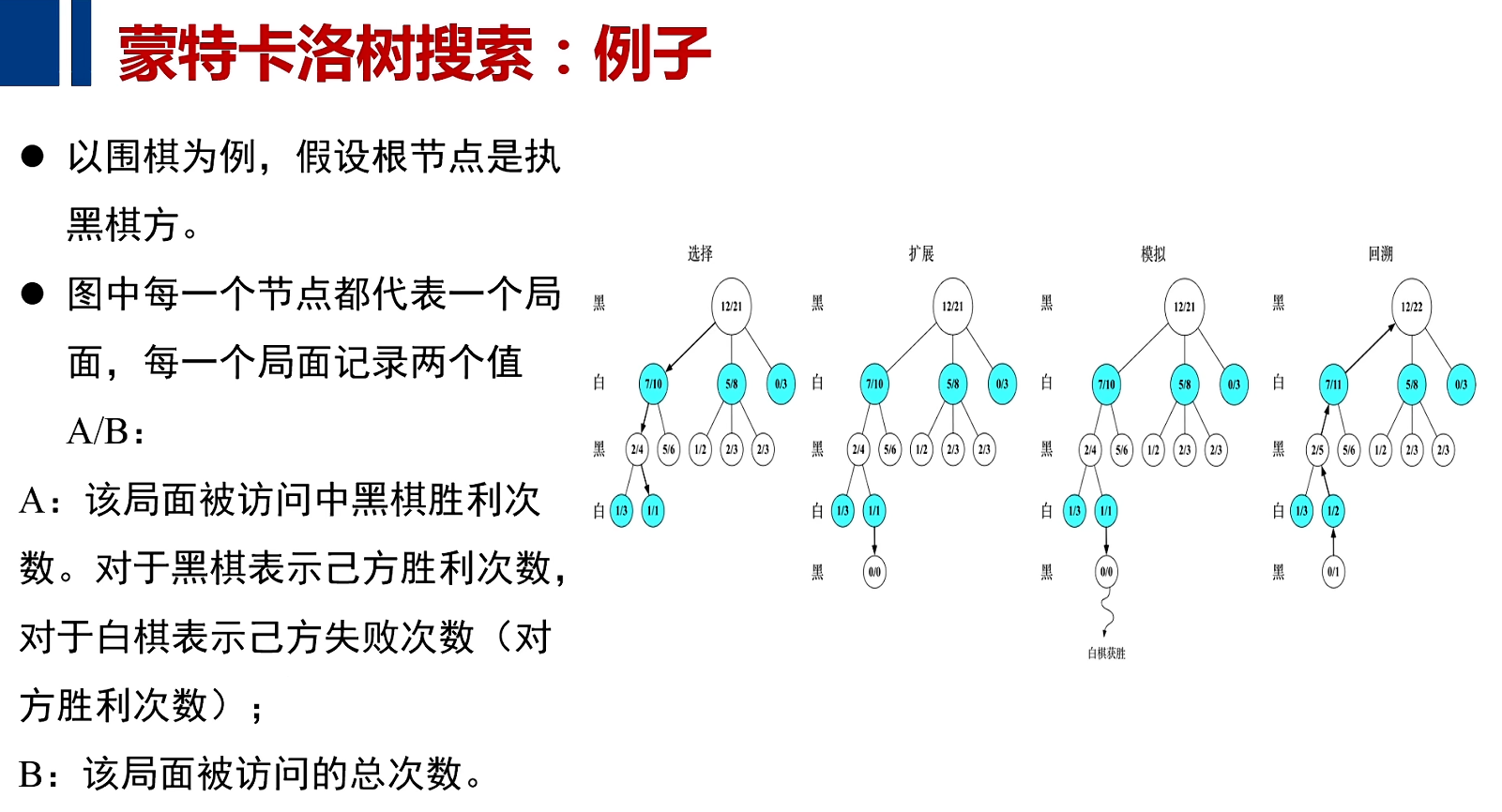
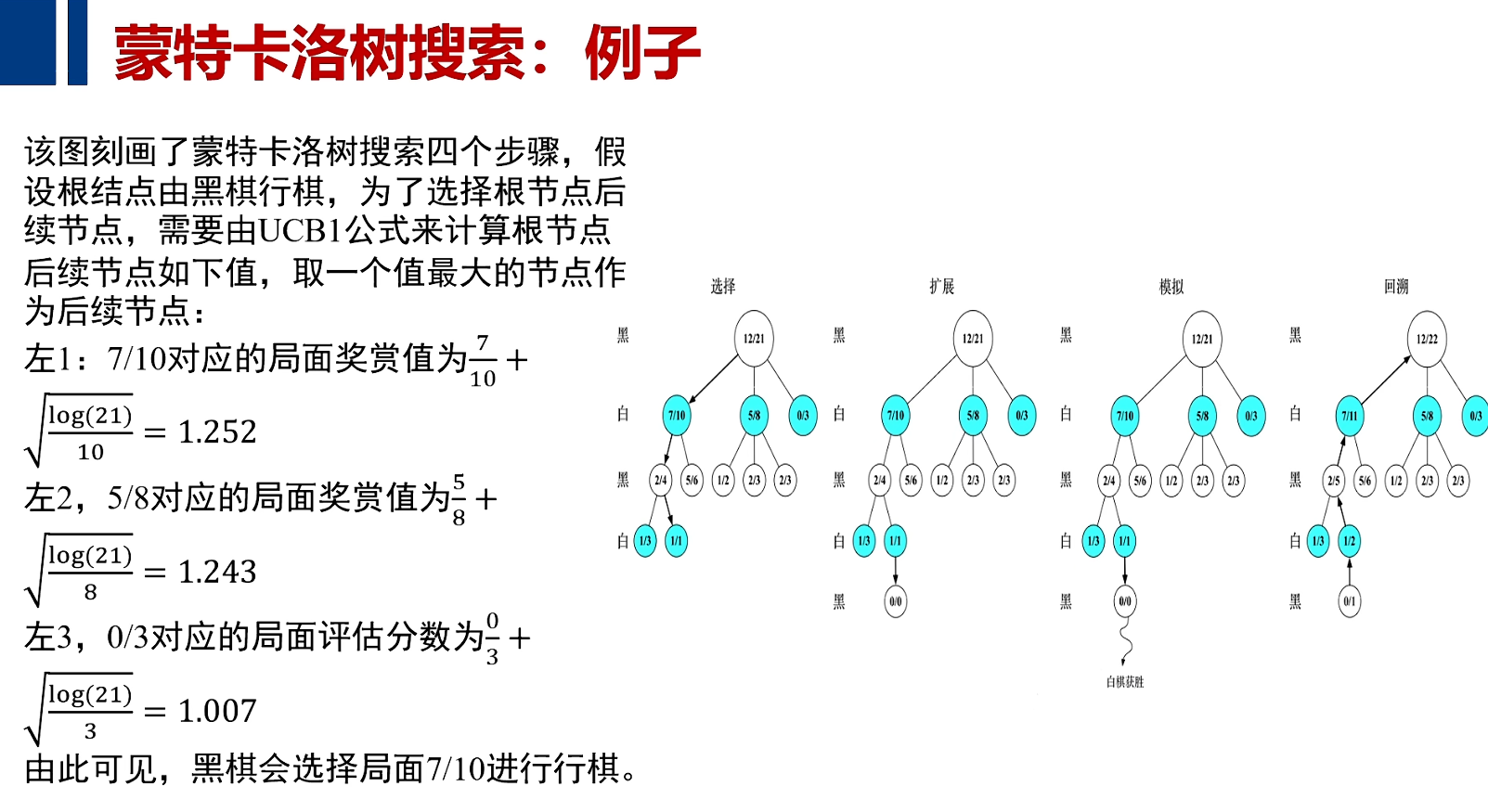
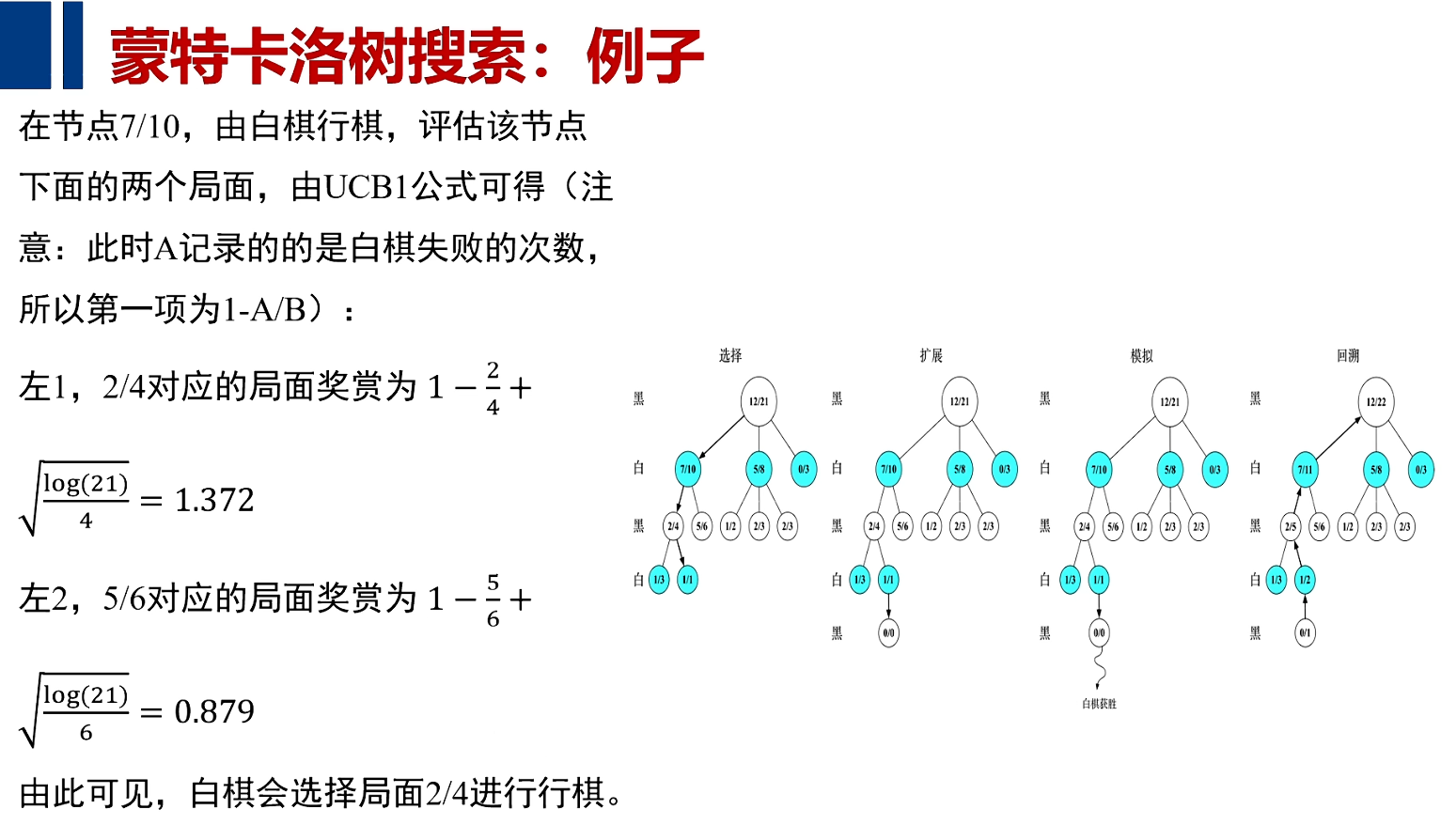
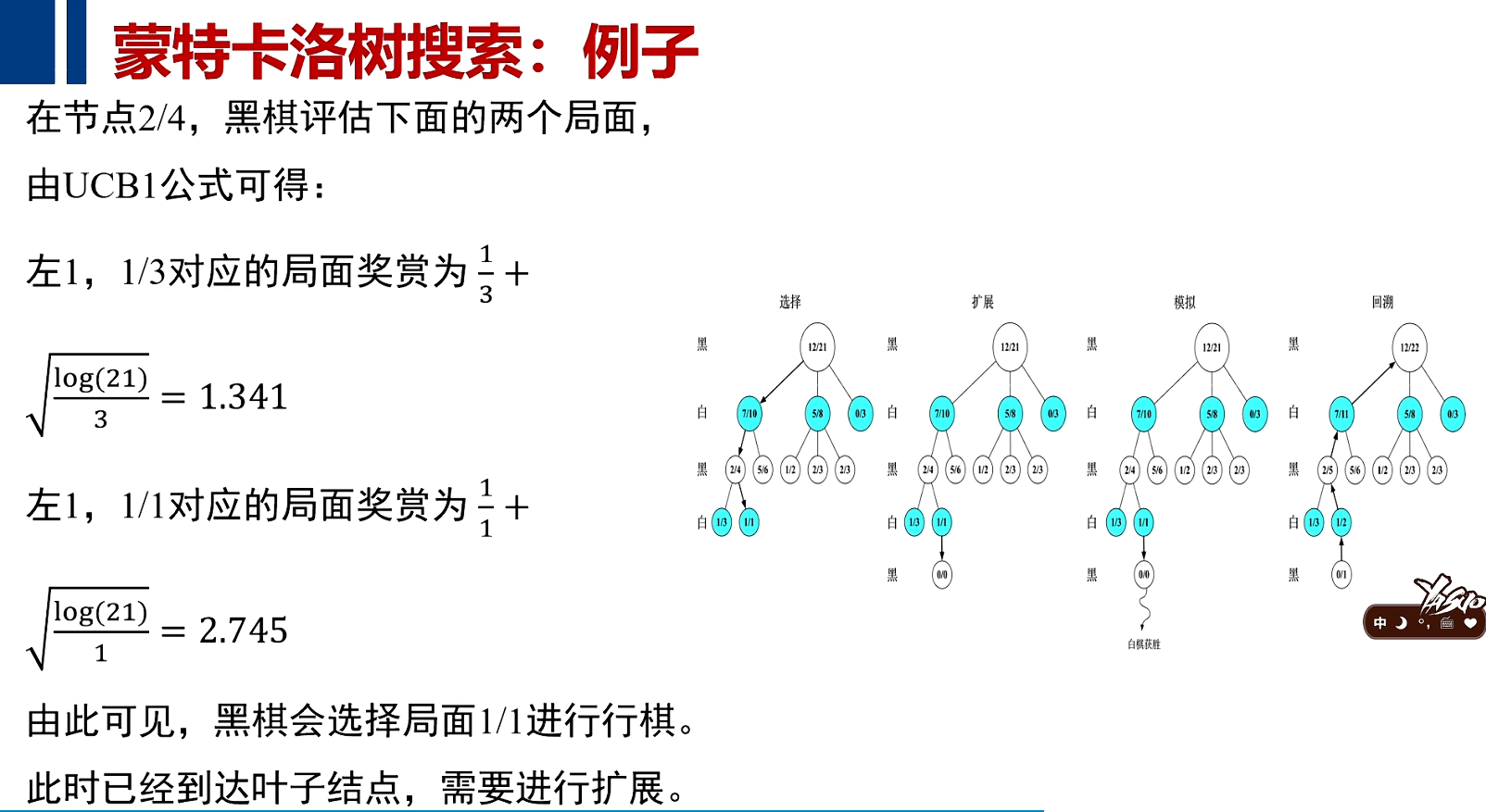
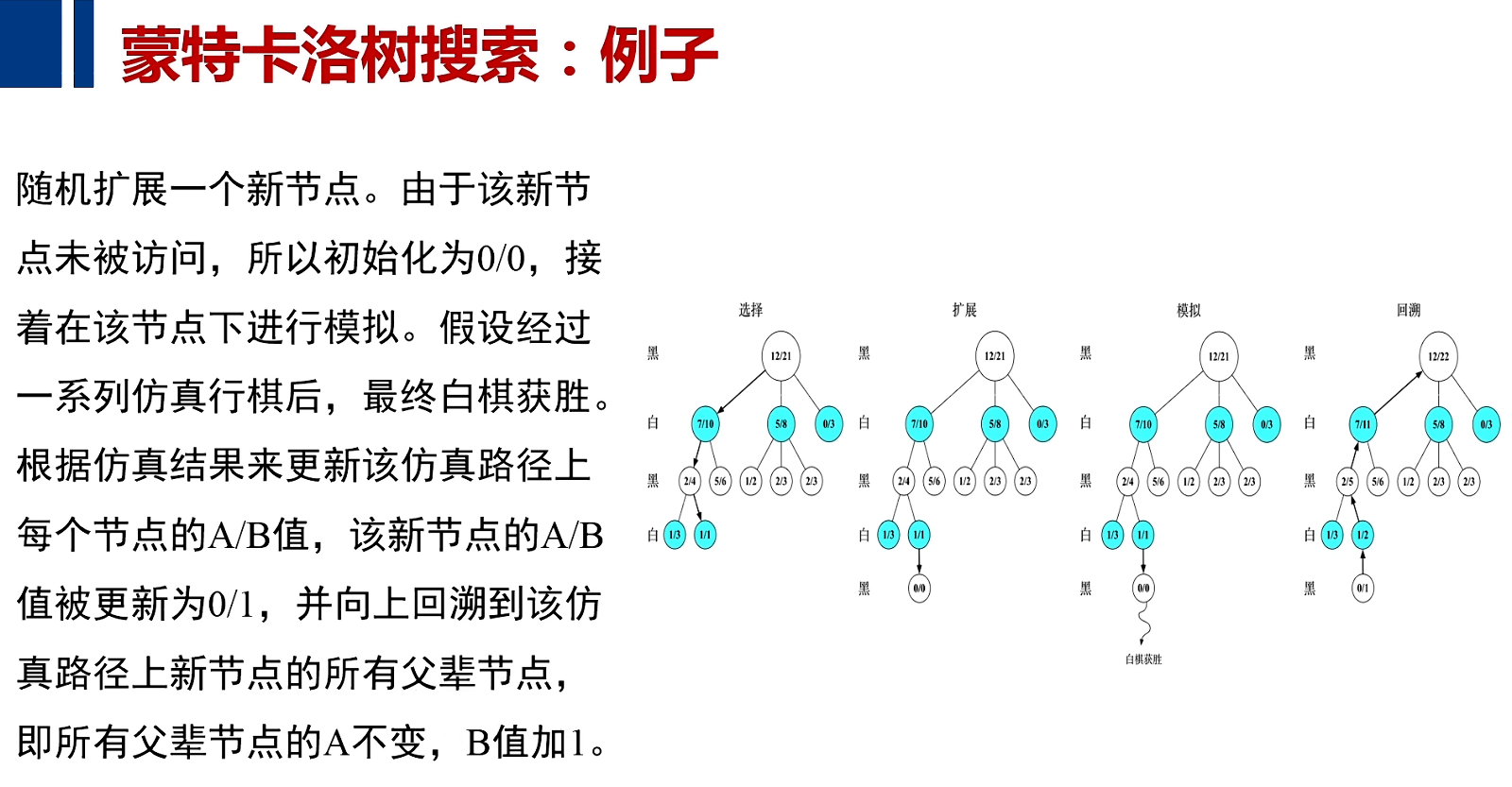
计算机通过大量的模拟算法,加以随机的运动,再加以UCB对过去回报的计算和对未来回报可期的复杂因素综合在一起,完成了游戏及围棋的对决。
使用蒙特卡洛树搜索的原因

注:MCTS并非穷举式算法,它不试图去访问所有的节点,二是加上UCB算法,随机创建未访问的节点,以及把mini-max思想融入,通过采样,非穷举式的方法完成游戏对决的任务
伪代码
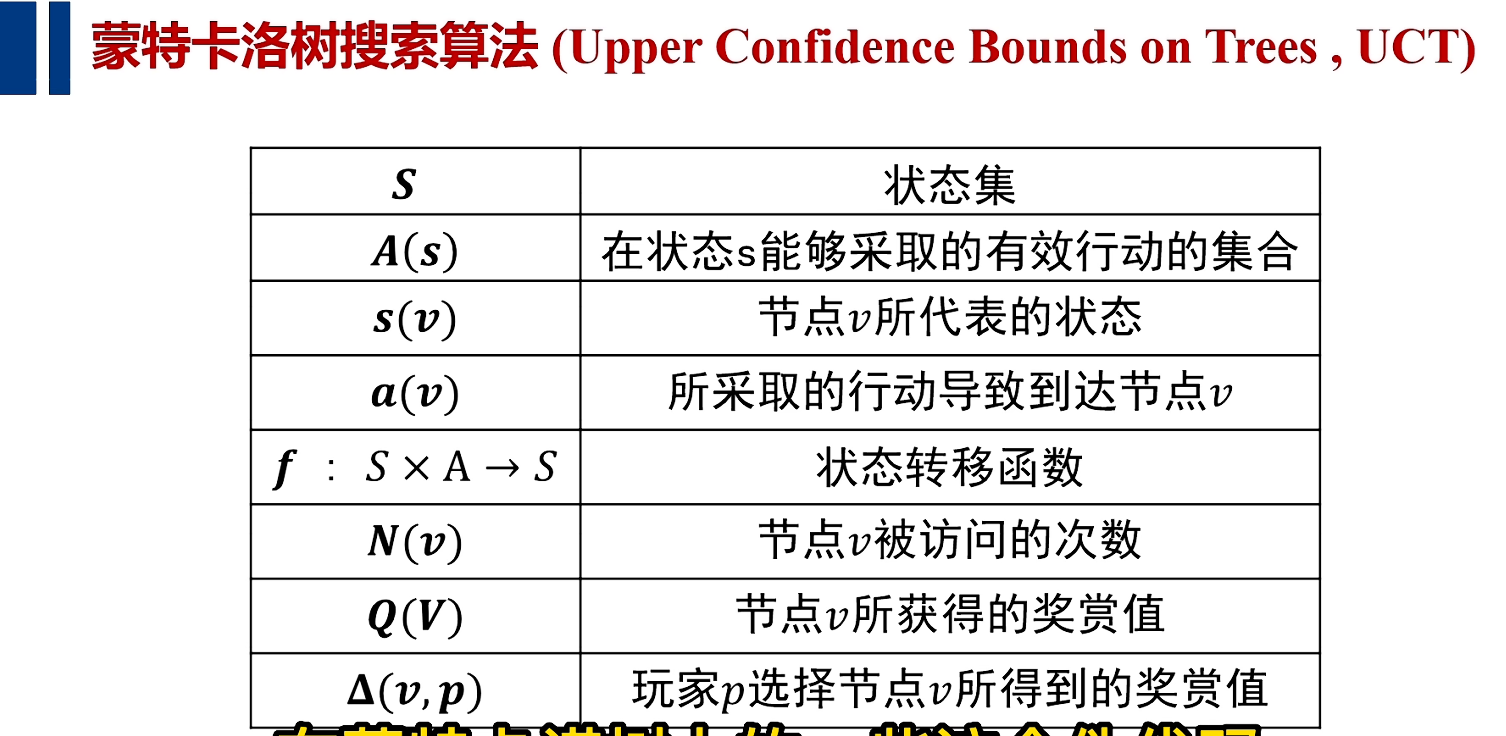
主代码程序:
(1) 创建根节点;
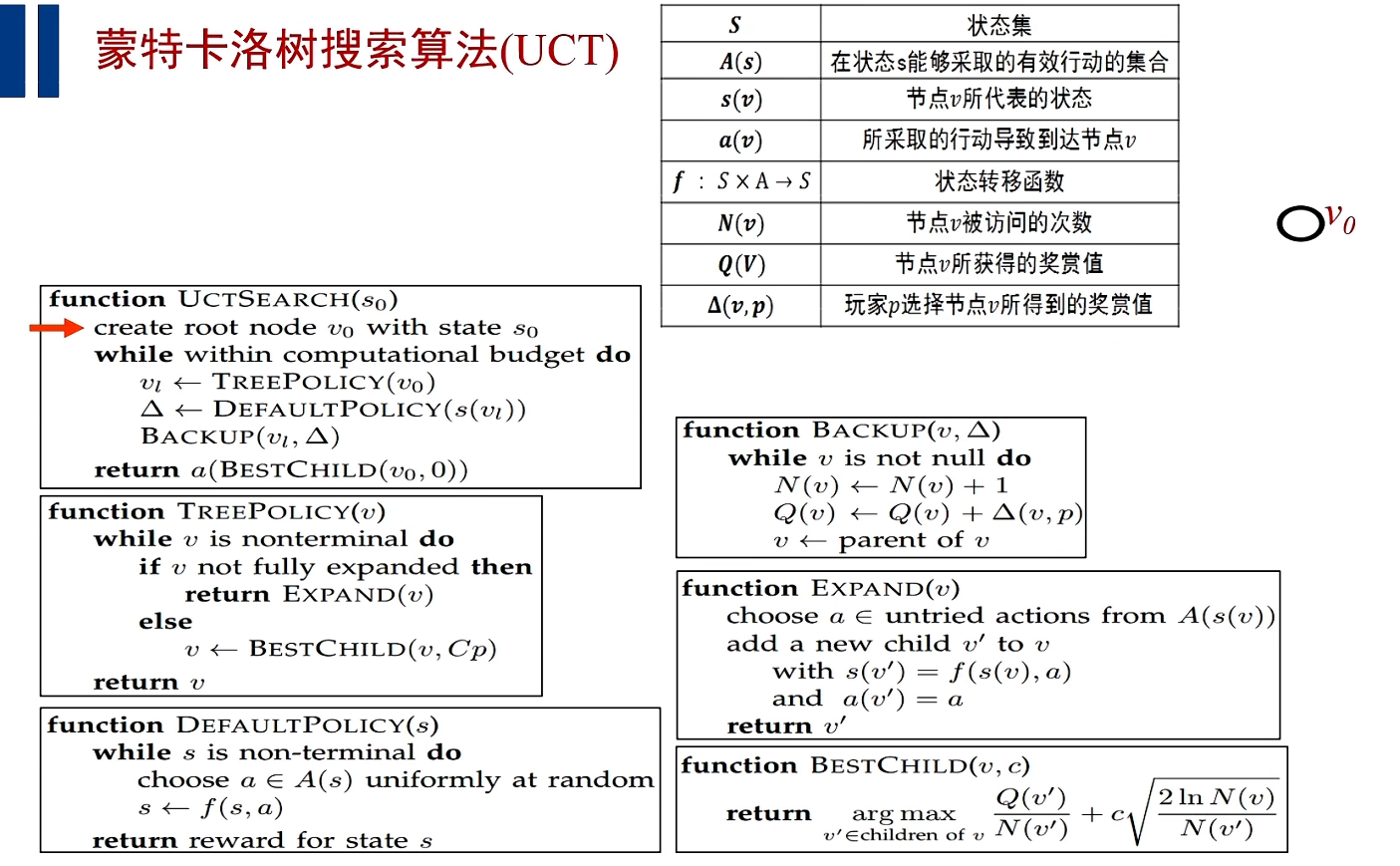
(2) 进行搜索树的搜索和仿真游戏的搜索,一旦仿真游戏结束之后,就快速把游戏的仿真结果向上回溯,改变每个节点的a,b的值;

(3) 从根节点v(0)出发,不断通过UCB算法,向下选择最具有潜力的子节点;

(4) 最终从最有潜力的子节点出发,扩展出一个未访问的节点,然后快速的进行仿真,把这个回报向上进行回溯;


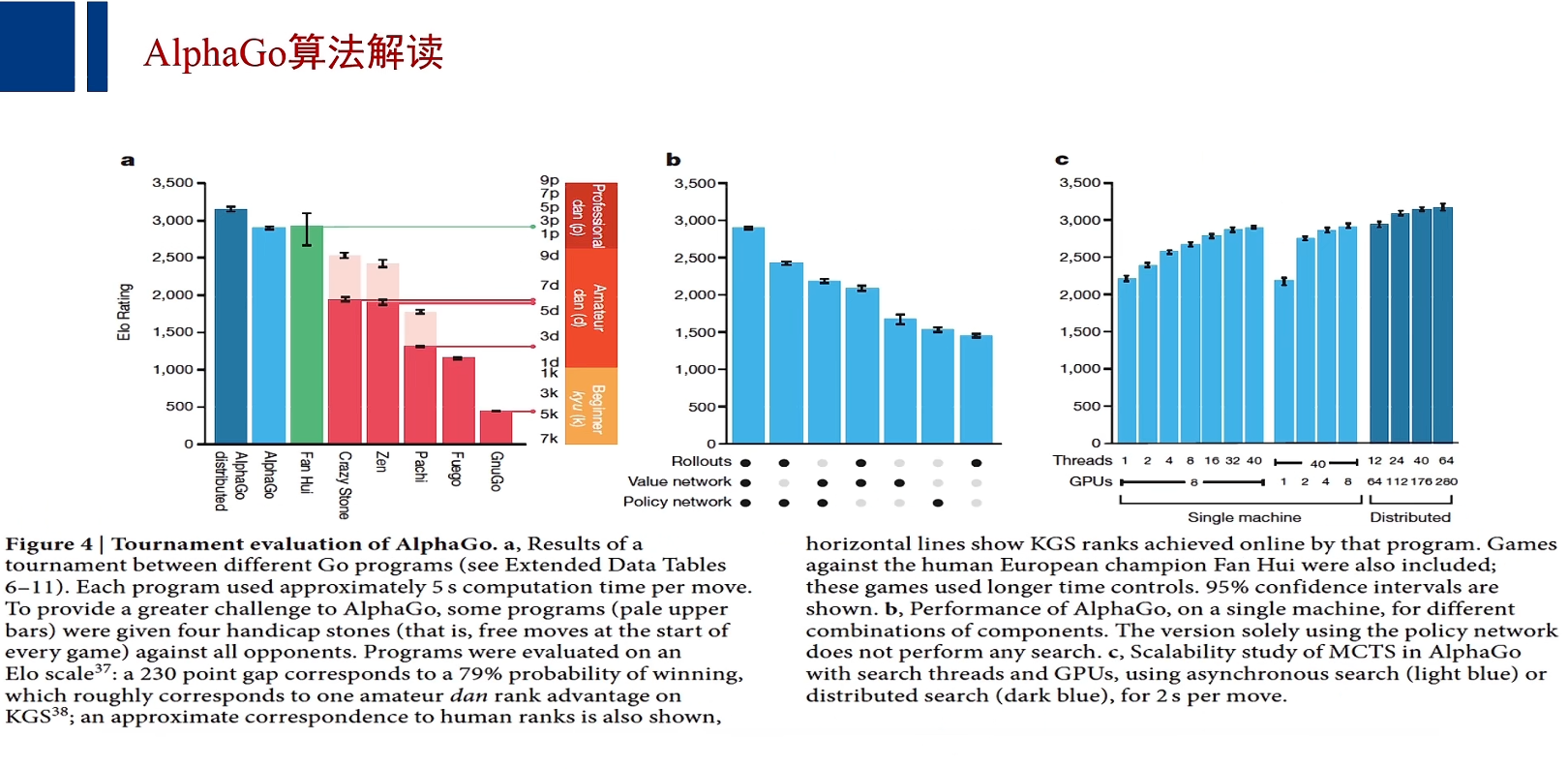
AlphaGo算法解读
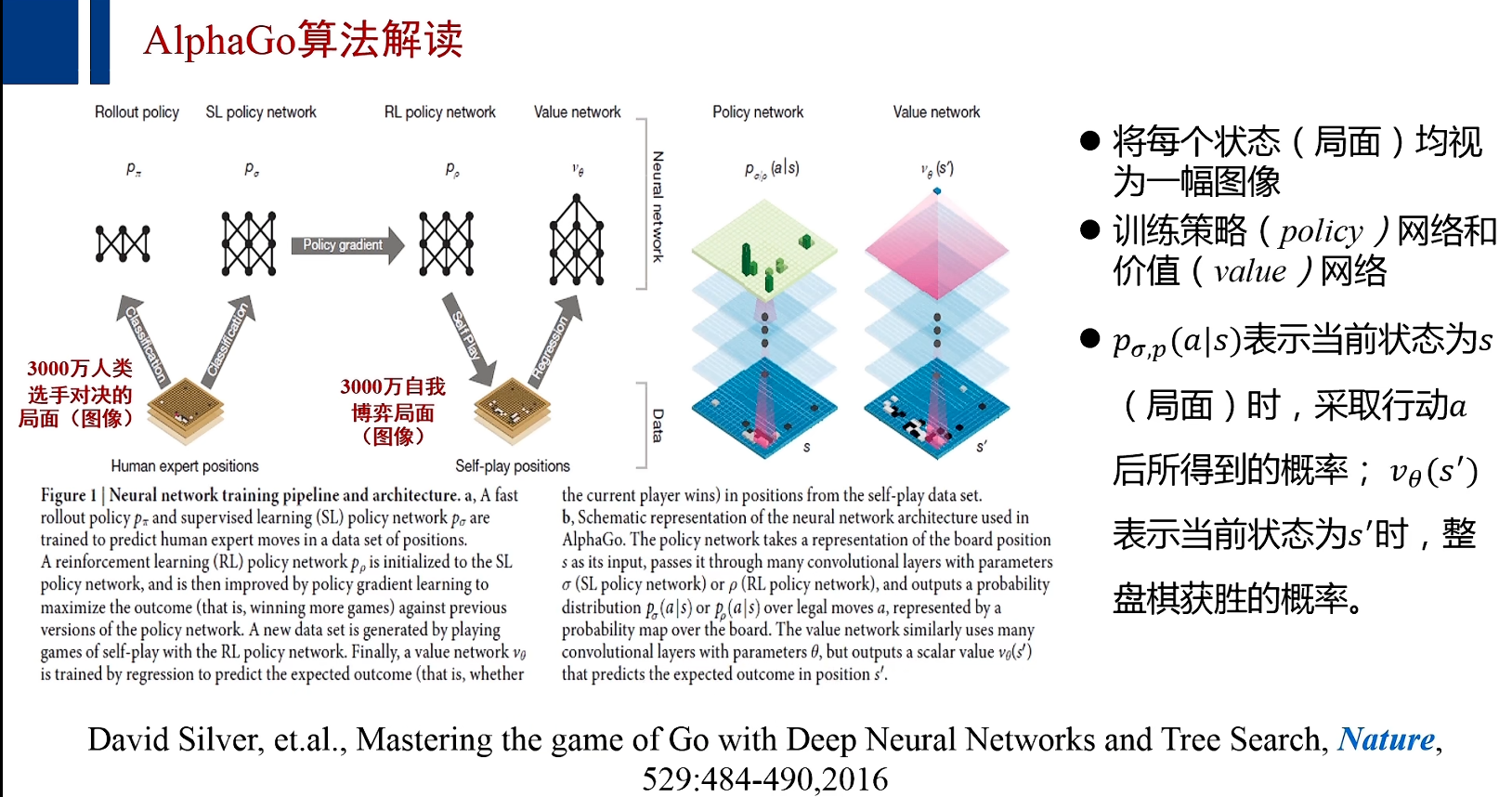


注:价值网络的训练——通过互相对决的算法程序产生的机器局面来进行训练成功;

在未来可期的回报中,AlphaGo引入了一个P函数,P函数就是由策略网络训练得到的;则AlphaGo在计算未来可期时,不仅仅依据于这个局面被访问的次数和所有局面被访问的总次数,还计算出,这个局面落子将产生怎样的胜算的计算结果。
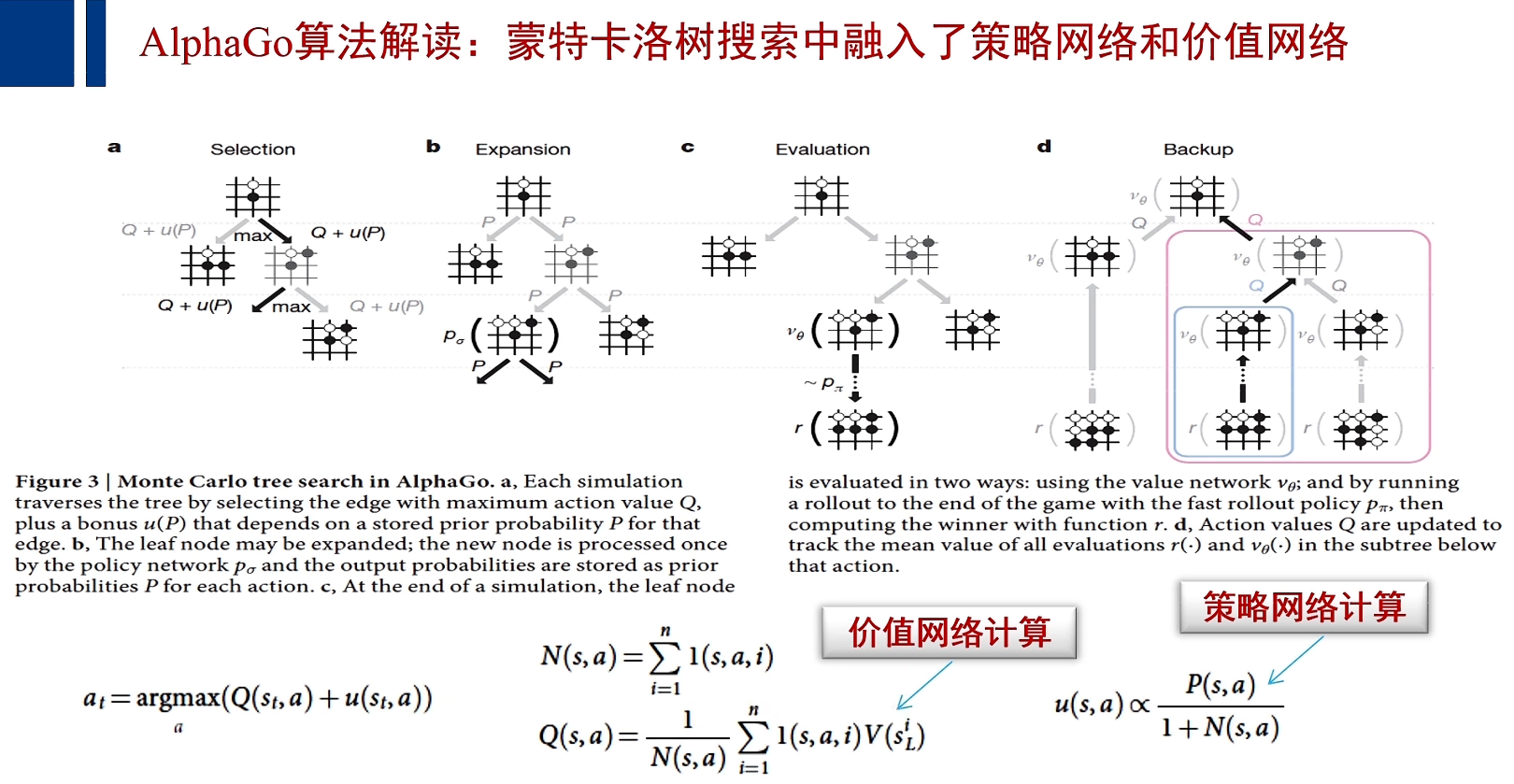
AlphaGo兼顾价值网络于策略网络;

(1) Zero去掉了通过监督学习来训练策略网络这一步,因为他没有用到人类选手对决的局面;
(2) 将策略网络与价值网络合并,于是一个网络输出两个值,一个是当前落子带来的胜算,另一个是当前落子带来的整盘围棋胜算的概率;
(3) 用性能更好的残差网络来捕捉围棋比赛所蕴含的黑白相见的模式;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号